
Maison >Périphériques technologiques >IA >ICCV 2023 annoncé : des articles populaires tels que ControlNet et SAM ont remporté des prix
ICCV 2023 annoncé : des articles populaires tels que ControlNet et SAM ont remporté des prix

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-10-04 21:37:011384parcourir
La Conférence internationale sur la vision par ordinateur (ICCV) s'est ouverte cette semaine à Paris, en France
En tant que conférence universitaire la plus importante au monde dans le domaine de la vision par ordinateur, l'ICCV se tient tous les deux ans.
La popularité de l'ICCV a toujours été comparable à celle du CVPR, établissant de nouveaux sommets à plusieurs reprises
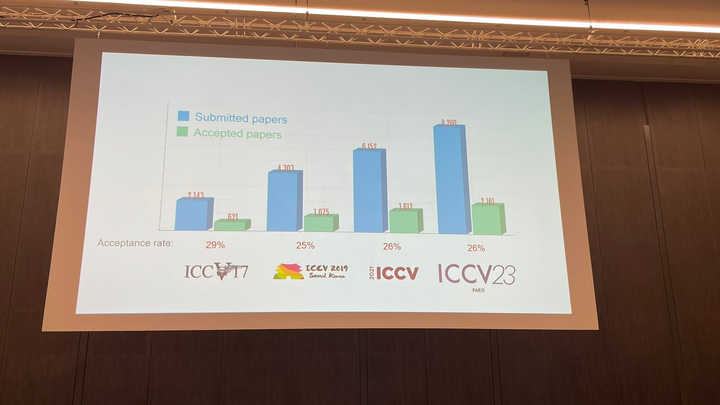
Lors de la cérémonie d'ouverture d'aujourd'hui, l'ICCV a officiellement annoncé les données papier de cette année : un total de 8 068 soumissions ont été soumises à l'ICCV de cette année, dont 2 160 ont été acceptées. le taux d'acceptation est de 26,8%, ce qui est légèrement supérieur au taux d'acceptation du précédent ICCV 2021 de 25,9%
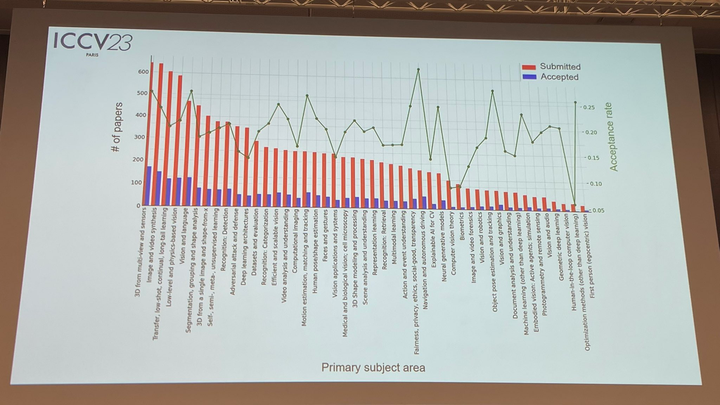
En termes de sujets de papier, le responsable a également annoncé des données pertinentes : la technologie 3D avec de multiples perspectives et capteurs est la plus populaire
La partie la plus importante de la cérémonie d'ouverture d'aujourd'hui est sans aucun doute la remise des prix. Ensuite, nous annoncerons un par un les gagnants du meilleur article, de la meilleure nomination d'article et du meilleur article étudiant
Best Paper-Marr Award
Le meilleur article de cette année (Marr Award) compte deux articles qui ont remporté le prix
La première étude a été menée par des chercheurs de l'Université de Toronto. Wei, Sotiris Nousias, Rahul Gulve, David B. Lindell, Kiriakos N. Kutulakos

Le contenu qui doit être réécrit est : Le deuxième article est ce que nous connaissons sous le nom de ControNet
Adresse papier :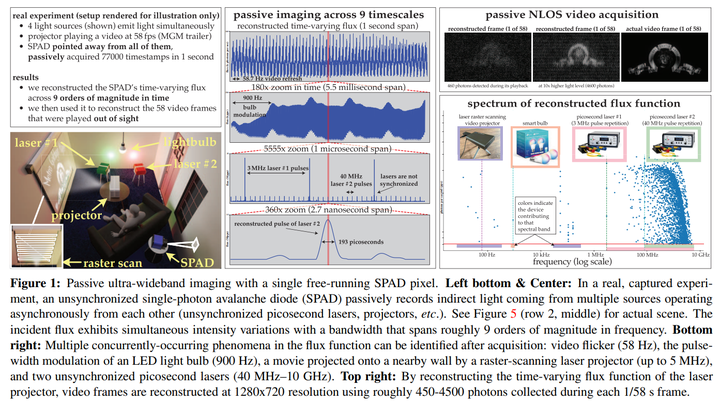
Écrivains : Zhang Lumin, Rao Anyi, Maneesh Agrawala

L'idée principale de ControlNet est d'ajouter des conditions supplémentaires à la description du texte pour contrôler le modèle de diffusion (comme la diffusion stable), contrôlant ainsi mieux la pose du personnage, la profondeur, la structure de l'image et d'autres informations de l'image générée.
Réécrit comme : Nous pouvons saisir des conditions supplémentaires sous forme d'images pour permettre au modèle d'effectuer la détection des bords Canny, la détection de profondeur, la segmentation sémantique, la détection de ligne de transformation de Hough, la détection globale des bords imbriqués (HED), la reconnaissance de la posture humaine, etc. opérations et conserver ces informations dans l’image résultante. En utilisant ce modèle, nous pouvons convertir directement des dessins au trait ou des graffitis en images en couleur et générer des images avec la même structure de profondeur. En même temps, nous pouvons également optimiser la génération de mains de personnages à travers les points clés des mains
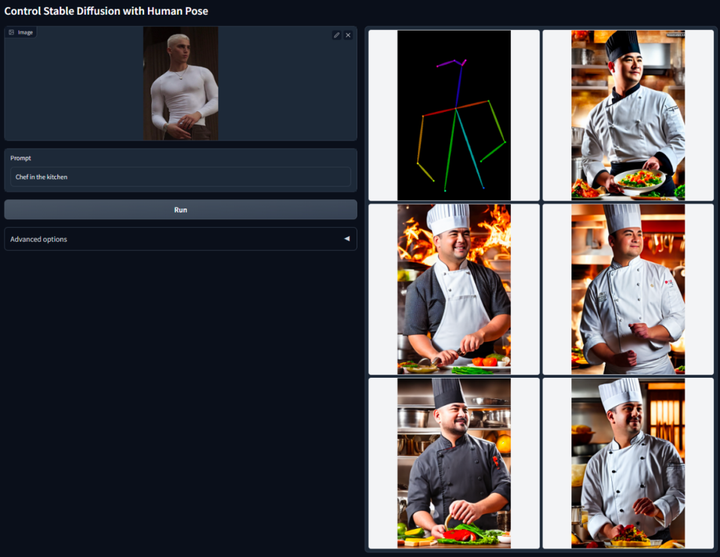
Veuillez vous référer au rapport d'introduction détaillé sur ce site : La réduction de la dimensionnalité de l'IA frappe les peintres humains, les graphiques vincentiens sont introduits dans ControlNet et les informations de profondeur et de bord sont entièrement réutilisables
Nomination pour le meilleur article : SAM
En avril prochain L'année dernière, Meta a publié un article intitulé « Le modèle d'IA de Separate Everything (SAM), qui peut générer des masques pour les objets dans n'importe quelle image ou vidéo. Cette technologie a choqué les chercheurs dans le domaine de la vision par ordinateur, et certains l'ont même qualifié de "Le CV n'existe plus"
Maintenant, cet article très médiatisé a été nominé pour le meilleur article.

Adresse papier : https://arxiv.org/abs/2304.02643
Contenu réécrit : Institution : Meta AI
Contenu réécrit : Pour la solution au problème de segmentation, il existe actuellement environ deux méthodes. La première est la segmentation interactive, qui peut être utilisée pour segmenter n’importe quelle classe d’objets mais nécessite qu’un humain guide la méthode en affinant le masque de manière itérative. La seconde est la segmentation automatique, qui peut être utilisée pour segmenter des catégories d'objets spécifiques prédéfinies (comme des chats ou des chaises), mais nécessite un grand nombre d'objets annotés manuellement pour l'entraînement (comme des milliers, voire des dizaines de milliers d'exemples de chats segmentés). . Aucune de ces deux méthodes ne propose une méthode de segmentation universelle et entièrement automatique
Le SAM proposé par Meta résume bien ces deux méthodes. Il s'agit d'un modèle unique qui peut facilement effectuer une segmentation interactive et une segmentation automatique. L'interface d'invite du modèle permet aux utilisateurs de l'utiliser de manière flexible. Il suffit de concevoir les invites appropriées pour le modèle (clic, sélection de zone, texte, etc.) pour effectuer un large éventail de tâches de segmentation
Pour résumer, ces fonctionnalités font de SAM peut s’adapter à de nouvelles tâches et domaines. Cette flexibilité est unique dans le domaine de la segmentation d'images
Veuillez vous référer au rapport de ce site pour plus de détails : Le CV n'existe plus ? Meta publie le modèle d'IA « Split Everything », CV pourrait inaugurer le moment GPT-3
Meilleur article étudiant
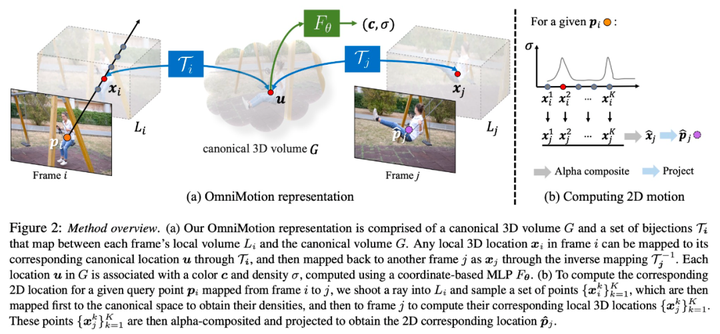
La recherche a été réalisée conjointement par des chercheurs de l'Université Cornell, Google Research et UC Berkeley. C'est Qianqian Wang, un doctorant de Cornell Tech. Ils ont proposé conjointement OmniMotion, une représentation de mouvement complète et globalement cohérente, et ont proposé une nouvelle méthode d'optimisation du temps de test pour effectuer une estimation précise et complète du mouvement pour chaque pixel de la vidéo.

- Adresse papier :https://arxiv.org/abs/2306.05422
- Page d'accueil du projet :https://omnimotion.github.io/
Dans le domaine de la vision par ordinateur, il Il existe deux types de méthodes d'estimation de mouvement couramment utilisées : le suivi de caractéristiques clairsemées et le flux optique dense. Cependant, les deux méthodes présentent certains inconvénients. Le suivi de caractéristiques clairsemées ne peut pas modéliser le mouvement de tous les pixels, tandis que le flux optique dense ne peut pas capturer les trajectoires de mouvement pendant de longues périodes
OmniMotion est une nouvelle technologie proposée par la recherche qui utilise des volumes canoniques quasi-3D pour caractériser les vidéos. OmniMotion est capable de suivre chaque pixel via une bijection entre l'espace local et l'espace canonique. Cette méthode de représentation garantit non seulement la cohérence globale et le suivi des mouvements même lorsque les objets sont masqués, mais est également capable de modéliser n'importe quelle combinaison de mouvements de caméra et d'objets. Des expériences ont prouvé que la méthode OmniMotion est nettement meilleure que la méthode SOTA existante en termes de performances
Veuillez vous référer au rapport sur ce site pour une introduction détaillée : Suivez chaque pixel à tout moment, n'importe où, même s'il est bloqué, le " suivez tout" algorithme vidéo Nous voilà
Bien sûr, en plus de ces articles primés, il existe de nombreux articles exceptionnels de l'ICCV cette année qui méritent votre attention. Enfin, voici une première liste de 17 articles primés.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les nouvelles règles pour octobre sont là ! Impliquant les nouveaux panneaux de signalisation routière, l'industrie de l'intelligence artificielle, etc.
- Ministère de la Science et de la Technologie : apporter un soutien fort à l'intelligence artificielle en tant qu'industrie stratégique émergente
- Ronglian Cloud a été sélectionné dans la carte mondiale de l'industrie de l'IA générative 2023
- L'interface cerveau-ordinateur brille dans la réalité ! Le ministère de l'Industrie et des Technologies de l'information se concentrera sur son développement à l'avenir. Jusqu'où est le chemin vers l'industrialisation ?