
Maison >Périphériques technologiques >IA >Percée dans l'interface cerveau-ordinateur de l'UC Berkeley : utiliser les ondes cérébrales pour reproduire de la musique, apportant de bonnes nouvelles aux personnes souffrant de troubles de la parole !
Percée dans l'interface cerveau-ordinateur de l'UC Berkeley : utiliser les ondes cérébrales pour reproduire de la musique, apportant de bonnes nouvelles aux personnes souffrant de troubles de la parole !

- WBOYavant
- 2023-09-30 15:49:071041parcourir
À l'ère de l'interface cerveau-ordinateur, de nouveaux gadgets apparaissent chaque jour.
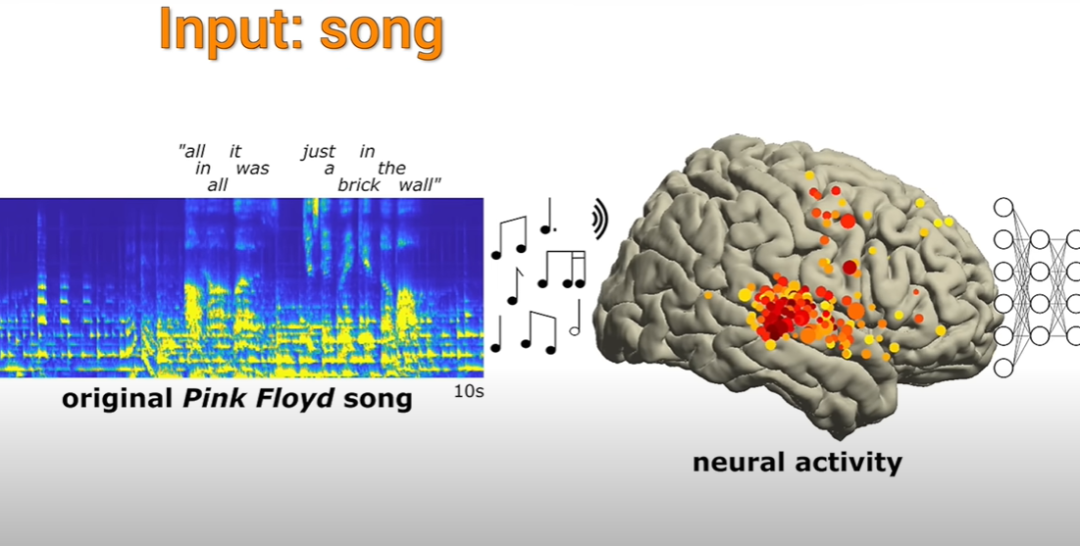
Aujourd'hui, je vous apporte quatre mots : musique de transplantation cérébrale.
Plus précisément, il s'agit d'abord d'utiliser l'IA pour observer quel type d'ondes radio un certain morceau de musique produit dans le cerveau d'une personne, puis de simuler directement l'activité de cette onde radio dans le cerveau de la personne qui a besoin d'atteindre traitement. Le but de certains types de maladies.
Regardons le centre médical d'Albany il y a quelques années et voyons comment les neuroscientifiques y ont mené des recherches
Bonne nouvelle pour les personnes souffrant de troubles de la parole !
Au Albany Medical Center, un morceau de musique intitulé "The Other Wall" a joué lentement, remplissant toute la salle d'hôpital
Patients allongés sur le lit se préparant à subir une opération pour l'épilepsie, ce ne sont pas des médecins, mais ils écoutent
Des neuroscientifiques se sont rassemblés pour observer l'activité de l'électroencéphalogramme du patient affichée sur l'écran de l'ordinateur
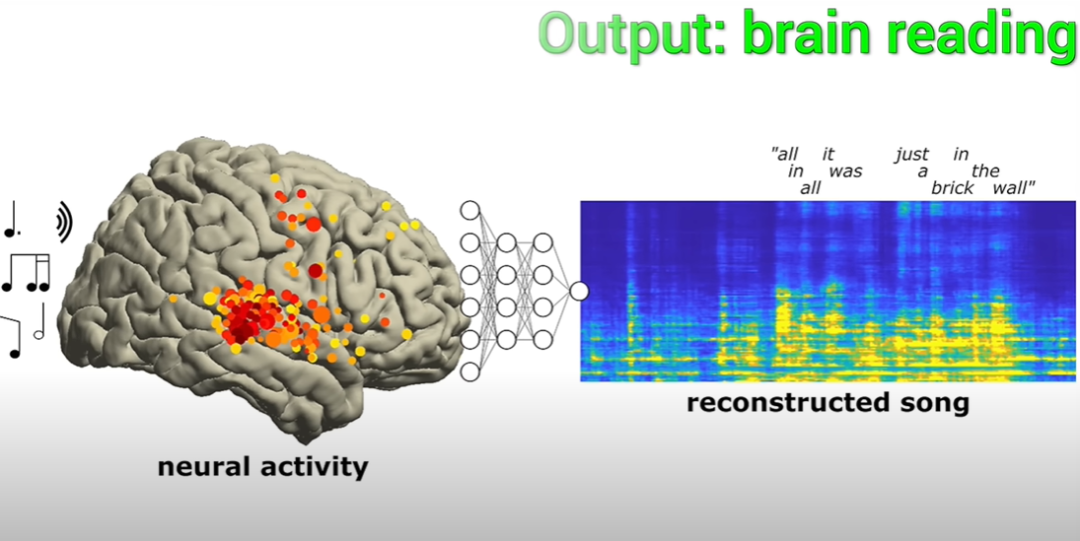
La principale observation était que certaines zones du cerveau entendaient quelque chose d'unique à la musique. L'activité des électrodes résultante était ensuite utilisée pour voir si l'enregistrement était enregistré. l'activité des électrodes pouvait reproduire la musique qu'ils écoutaient.
Dans le contenu susmentionné, les éléments impliqués dans la musique comprennent la hauteur, le rythme, l'harmonie et les paroles
Cette recherche est menée depuis plus de dix ans. Des neuroscientifiques de l'Université de Californie à Berkeley ont procédé à une analyse détaillée des données de 29 patients épileptiques ayant participé à l'expérience. Les scientifiques ont réussi à reconstruire la musique sur la base des résultats de l'activité des électrodes dans le cerveau des patients. Dans la chanson actuelle, le rythme de l'une des paroles "Tout compte fait, ce n'était qu'une brique dans le mur" est très complet. Bien que les paroles ne soient pas très claires, les chercheurs ont déclaré qu'elles pouvaient être déchiffrées et qu'elles n'étaient pas chaotiques.
Et cette chanson est aussi le premier cas où des scientifiques ont réussi à reconstruire une chanson grâce à l'activité des électrodes cérébrales.
Les résultats montrent qu'en enregistrant et en désactivant les ondes cérébrales, certains éléments musicaux et syllabes peuvent être capturés.
Ces éléments musicaux peuvent être appelés prosodie en termes professionnels, notamment le rythme, l'accent, la cadence, etc. La signification de ces éléments ne peut pas être transmise uniquement par des mots
De plus, étant donné que ces électroencéphalogrammes intracrâniens (iEEG) enregistrent uniquement l'activité qui se déroule dans les couches superficielles du cerveau (c'est-à-dire les parties les plus proches du centre auditif), il y a pas besoin de s'inquiéter que quelqu'un écoute les chansons que vous écoutez de cette façon (rires)
Cependant, pour ceux qui ont subi un accident vasculaire cérébral ou qui sont paralysés, ce qui entraîne des difficultés de communication, ce type de reproduction de l'activité des électrodes à la surface du cerveau, qui peut les aider à reproduire la musicalité de la pièce.
Évidemment, c'est bien meilleur que la version robotique et pince-sans-rire du précédent. Comme mentionné ci-dessus, il y a certaines choses pour lesquelles les mots seuls ne suffisent pas. Ce que nous écoutons, c'est le ton. 
Robert Knight, neuroscientifique à l'Institut de neurosciences Helen Wills et professeur de psychologie à l'Université de Californie à Berkeley, a déclaré qu'il s'agissait d'un résultat remarquable.
"Pour moi, l'un des charmes de la musique réside dans son prélude et le contenu émotionnel qu'elle exprime. Et avec les avancées continues dans le domaine de l'interface cerveau-ordinateur, cette technologie peut être offerte aux personnes dans le besoin grâce à The La méthode d'implantation offre quelque chose que seule la musique peut apporter. Le public peut inclure des patients atteints de SLA, ou des patients épileptiques, en bref, toute personne dont la maladie affecte les nerfs de la parole. "
En d'autres termes, nous pouvons maintenant faire plus que. juste le langage lui-même, et l'émotion exprimée dans les mots peut sembler un peu mince par rapport à la musique. Je crois que désormais, nous nous sommes véritablement lancés dans un voyage d'interprétation
Grâce aux progrès de la technologie d'enregistrement des ondes cérébrales, un jour dans le futur, nous pourrons peut-être enregistrer grâce à des électrodes fixées au cuir chevelu sans ouvrir le cerveau.
Knight a déclaré que l'électroencéphalographie actuelle du cuir chevelu peut déjà mesurer et enregistrer certaines activités cérébrales, comme la détection d'une seule lettre parmi une grande série de lettres. Même si ce n'est pas très efficace, chaque lettre prend au moins 20 secondes, mais c'est quand même un début.
La raison du développement vigoureux des électrodes du cuir chevelu est que le niveau actuel de maîtrise de la technologie non invasive est insuffisant. En d’autres termes, la mesure de la craniotomie ne peut pas être sûre à 100 %. La précision des mesures des électrodes du cuir chevelu, en particulier pour les mesures cérébrales profondes, doit encore être améliorée. On peut dire qu'il a obtenu un certain succès, mais pas complètement
Souhaitez-vous lire dans les pensées ?
La réponse directe est : non.
Par exemple, pour ceux qui ont des troubles de la parole, la technologie d'interface cerveau-ordinateur équivaut à leur donner un « clavier ». En capturant l'activité des ondes cérébrales, ils peuvent utiliser ce « clavier » pour taper et exprimer ce qu'ils veulent. vouloir exprimer.
Par exemple, prenons Hawking comme exemple. L'appareil qu'il a utilisé était pour capturer ses ondes cérébrales pour générer le discours de la voix du robot
Par analogie, vous devriez être capable de comprendre. Rien qu'en regardant ce "clavier", vous ne pouvez pas dire à quoi il pense. La technologie permet désormais d’activer les claviers et de produire de la parole. Si personne ne veut taper, le clavier ne démarrera pas et vous ne pourrez pas savoir à quoi il pense
Donc, la lecture dans les pensées n'est pas réalisable
Contenu expérimental
Veuillez voir l'image ci-dessous, Figure A Affiche les formes d'onde globales des chansons utilisées dans l'expérience. Ci-dessous la figure A se trouve le spectrogramme auditif de la chanson. La barre orange en haut indique la présence de voix
La figure B est une radiographie de la couverture des électrodes d'un patient. Chaque point représente une électrode.
L'image C montre les signaux des quatre électrodes de l'image B. Dans le même temps, la figure montre également l'activité haute fréquence (HFA) déclenchée par la stimulation du chant, représentée par une courte ligne noire coulissante, avec une fréquence comprise entre 70 et 150 Hz
La figure D montre une courte section (10 secondes) de la chanson en A Spectrogramme auditif agrandi et carte d'activité neuronale des électrodes pendant la lecture. Nous pouvons observer que les points temporels de HFA coïncident avec la ligne rouge sur le côté droit de chaque rectangle marqué dans le spectrogramme
Ces appariements constituent les exemples utilisés par les chercheurs pour former et évaluer les modèles d'encodage.
Les résultats expérimentaux des chercheurs montrent qu'il existe une relation logarithmique entre le nombre d'électrodes utilisées comme prédicteurs dans le modèle de décodage et la précision de la prédiction, comme le montre la figure ci-dessous. 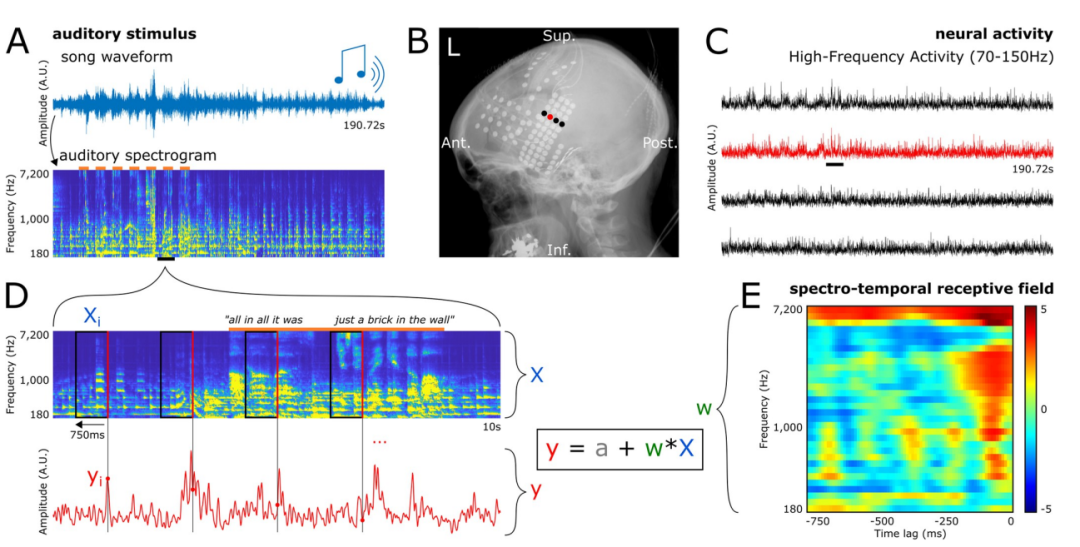
Par exemple, la meilleure précision de prédiction de 80 % est obtenue en utilisant 43 électrodes (soit 12,4 %) (la meilleure précision de prédiction est le résultat de l'utilisation des 347 électrodes). 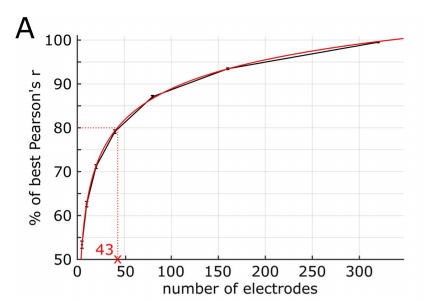
La même relation a été observée chez des patients individuels, voici ce que les chercheurs ont trouvé
De plus, grâce à une analyse bootstrapping, les chercheurs ont observé une relation similaire entre la durée de l'ensemble de données et la précision de la prédiction. La relation numérique est la suivante dans la figure ci-dessous.
Par exemple, si vous utilisez des données d'une durée de 69 secondes (36,1 % de la durée totale), vous pouvez obtenir 90 % de la meilleure performance (la meilleure performance fait référence à l'utilisation de la chanson entière qui est 190,72 secondes) Données dérivées) 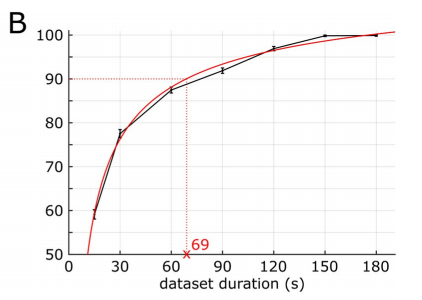
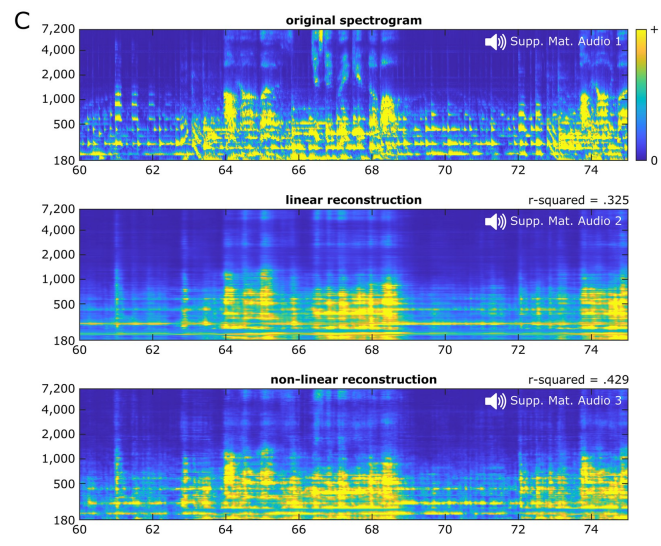
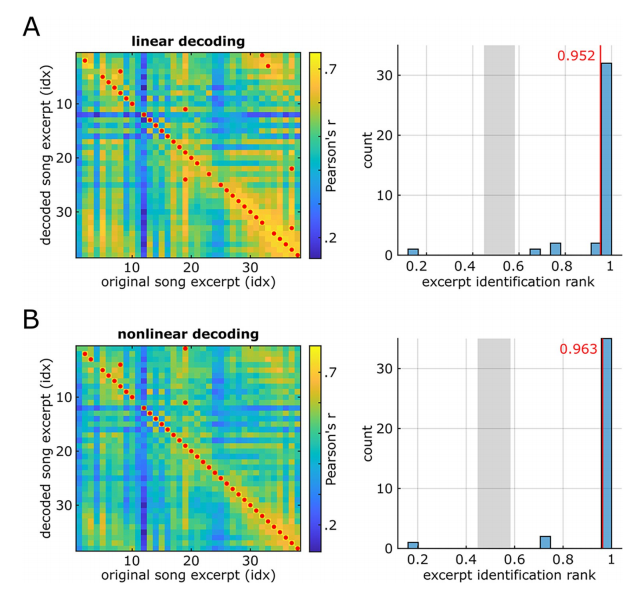
Concernant le type de modèle, la précision moyenne du décodage linéaire est de 0,325, tandis que la précision moyenne du décodage non linéaire utilisant un réseau neuronal à deux couches entièrement connecté est de 0,429.
Dans l'ensemble, la reconstruction linéaire de la chanson musicale (Audio S2) semble terne, avec de forts indices rythmiques liés à la présence de certains éléments musicaux (faisant référence aux syllabes vocales et à la guitare solo), mais peut-être à la perception d'autres limitée.
La reconstruction de chanson non linéaire (Audio S3) reproduit une chanson reconnaissable avec des détails plus riches par rapport à la reconstruction linéaire. La qualité de perception des éléments spectraux tels que la hauteur et le timbre est considérablement améliorée et les caractéristiques des phonèmes sont plus clairement discernables. Certains angles morts de reconnaissance existant dans la reconstruction linéaire ont également été améliorés dans une certaine mesure
Ce qui suit est une illustration :
Les chercheurs ont donc utilisé un modèle non linéaire pour reconstruire la chanson à travers 61 électrodes du 29 patient .
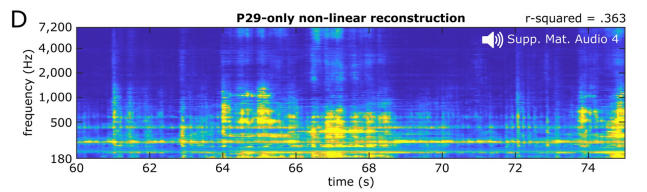
Les performances de ces modèles sont meilleures que la reconstruction linéaire basée sur toutes les électrodes des patients, mais la précision du décodage n'est pas aussi bonne que celle obtenue en utilisant 347 électrodes de tous les patients
En termes de perception, ces sont basés sur un seul patient Le modèle a fourni des détails spectral-temporels suffisamment élevés pour que les chercheurs puissent identifier la chanson (Audio S4)
En même temps, pour évaluer la limite inférieure de décodage sur la base d'un seul patient, les chercheurs l'activité neuronale collectée dans le cerveau de 3 patients supplémentaires. Le nombre d'électrodes chez ces 3 patients était plus petit, 23, 17 et 10 respectivement, tandis que le nombre d'électrodes chez le 29ème patient mentionné ci-dessus était de 61, et la densité des électrodes était également. relativement faible. Bien entendu, la zone de réponse de la chanson est toujours couverte et la précision du décodage linéaire est également considérée comme bonne.
Dans les formes d'onde reconstruites (fichiers audio S5, S6 et S7), les chercheurs ont récupéré une partie de la voix humaine. Ils ont ensuite quantifié la reconnaissabilité des chansons décodées en corrélant les spectrogrammes des chansons originales avec les chansons décodées.
La reconstruction linéaire (Figure A ci-dessous) et la reconstruction non linéaire (Figure B ci-dessous) fournissent une proportion plus élevée de taux de reconnaissance correcte.
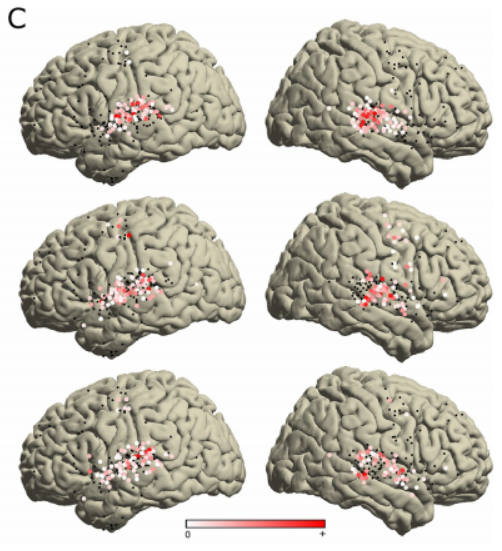
De plus, les chercheurs ont analysé les coefficients STRF (champ récepteur spectral-temporel) des 347 électrodes importantes pour évaluer la façon dont différents éléments musicaux sont codés dans différentes zones du cerveau.
Cette analyse révèle des modèles de réglage spectraux et temporels distincts
Pour caractériser de manière exhaustive la relation entre les spectrogrammes de chant et l'activité neuronale, les chercheurs ont effectué une analyse en composantes indépendantes (ICA) sur tous les STRF importants.
Les chercheurs ont trouvé 3 composants avec des modèles de réglage spectral-temporel différents. Le taux d'explication de la variance de chaque composant dépassait 5 % et le taux d'explication de la variance totale atteignait 52,5 %, comme le montre la figure ci-dessous.
La première partie (variance expliquée de 28%) montre un groupe de coefficients positifs répartis sur une large gamme de fréquences d'environ 500 Hz à 7 000 Hz et une fenêtre de temps étroite d'environ 90 ms avant l'observation du HFA. Visible dans
Cet instantané Le cluster montre le réglage de l'apparition du son. Cette partie est appelée partie initiale et n'apparaît que sur les électrodes à l'arrière du STG bilatéral, comme le montre l'image ci-dessous
Enfin, les chercheurs ont déclaré que de futures études pourraient élargir la couverture des électrodes. modifier les caractéristiques et les objectifs du modèle, ou ajouter de nouvelles dimensions comportementales
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!