
Maison >Périphériques technologiques >IA >Comment l'agent AI est-il implémenté ? 6 photos de 4090 Llama2 modifié par magie : fractionnement des tâches et appel de fonctions avec une seule commande
Comment l'agent AI est-il implémenté ? 6 photos de 4090 Llama2 modifié par magie : fractionnement des tâches et appel de fonctions avec une seule commande

- 王林avant
- 2023-09-25 19:49:051382parcourir
AI Agent est actuellement un domaine brûlant. Dans un long article [1] écrit par LilianWeng, directrice de recherche sur les applications OpenAI, elle a proposé le concept d'Agent = LLM + mémoire + compétences en planification + utilisation des outils
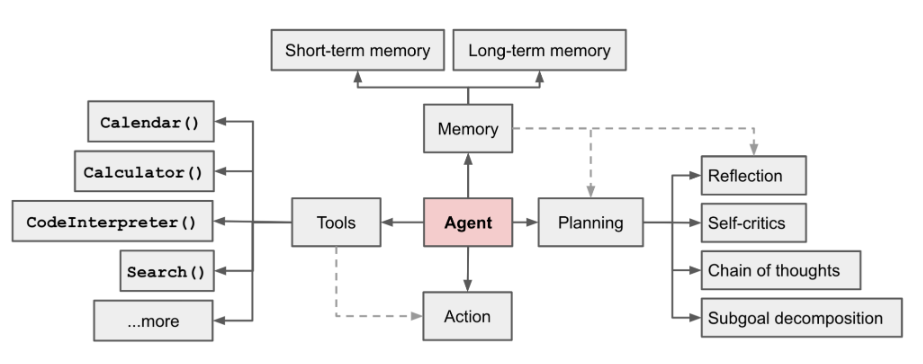
Figure 1 Présentation d'un système d'agent autonome alimenté par LLM
Le rôle de l'agent est d'utiliser la puissante compréhension du langage et les capacités de raisonnement logique de LLM pour appeler des outils permettant d'aider les humains à accomplir des tâches. Cependant, cela pose également certains défis. Par exemple, la capacité du modèle de base détermine l'efficacité des outils d'appel d'agent, mais le modèle de base lui-même présente des problèmes tels que l'illusion du grand modèle
Cet article commence par "Saisir une pièce". d'instructions pour diviser automatiquement les tâches complexes et l'appel de fonction" comme exemple pour construire le processus d'agent de base, et se concentrer sur l'explication de la façon de construire avec succès les modules "répartition des tâches" et "appel de fonction" via la "sélection de modèle de base", "Invite conception", etc.
Le contenu réécrit est : Adresse :
https://sota.jiqizhixin.com/project/smart_agent
GitHub Repo :
besoin de lourd le contenu écrit est : https://github.com/zzlgreat/smart_agent
Processus d'agent de fractionnement de tâches et d'appel de fonctions
Pour la mise en œuvre de "Saisir une commande pour implémenter automatiquement le fractionnement de tâches complexes et l'appel de fonctions", le projet Le processus de l'agent construit est le suivant :
- planificateur : Répartissez les tâches selon les instructions saisies par l'utilisateur. Déterminez la boîte à outils dont vous disposez et indiquez au planificateur un grand modèle qui divise les tâches, les outils dont vous disposez et les tâches que vous devez accomplir. Le planificateur divise les tâches en plans 1, 2, 3...
- . distributeur : Responsable de la sélection des outils appropriés pour mettre en œuvre le plan. Le modèle d'appel de fonction nécessite de sélectionner les outils correspondants selon différents plans.
- worker : Responsable de l'appel des tâches dans la boîte à outils et du renvoi des résultats des appels de tâches.
- solveur : Le plan de distribution compilé et les résultats correspondants sont combinés dans une longue histoire, qui est ensuite résumée par le solveur.
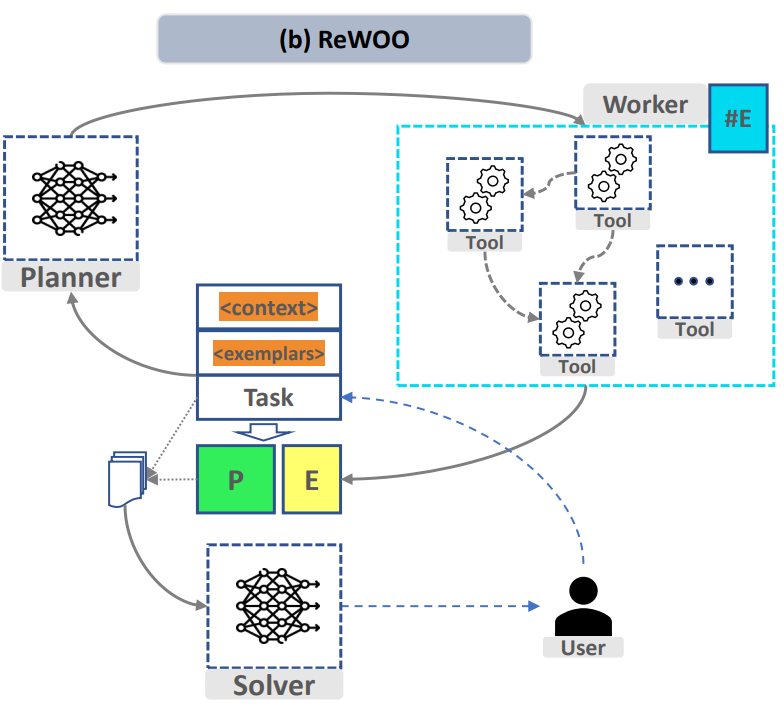
Figure 1 "ReWOO : Découplage du raisonnement des observations pour des modèles de langage augmentés efficaces"
Afin de réaliser le processus ci-dessus, dans les modules "Task Splitting" et "Function Calling", le projet a été conçu séparément Deux modèles affinés pour permettre la possibilité de diviser des tâches complexes et d'appeler des fonctions personnalisées à la demande. Le solveur de modèle résumé peut être le même que le modèle de tâche fractionnée
Modèle de fractionnement précis des tâches et d'appel de fonction
2.1 Résumé de l'expérience de réglage fin
Dans le module "Répartition des tâches", grands modèles Nécessite la capacité de diviser des tâches complexes en tâches plus simples. Le succès du « répartition des tâches » dépend principalement de deux facteurs :
- Sélection du modèle de base : Afin de diviser des tâches complexes, le choix du modèle de base affiné lui-même doit avoir de bonnes capacités de compréhension et de généralisation. Autrement dit, les tâches non visibles dans l'ensemble de formation sont réparties selon des instructions rapides. Actuellement, il est plus facile de le faire en choisissant un grand modèle avec des paramètres élevés.
- Conception de l'invite : Indique si l'invite peut appeler avec succès la chaîne de réflexion du modèle et diviser la tâche en sous-tâches.
Dans le même temps, nous espérons que le format de sortie du modèle de répartition des tâches sous un modèle d'invite donné pourra être aussi relativement fixe que possible, mais il ne sera pas surajusté et ne perdra pas les capacités de raisonnement et de généralisation d'origine du model. Ici, nous utilisons lora pour affiner la couche qv, en apportant le moins de modifications structurelles possible au modèle d'origine.
Dans le module « Function Call », les grands modèles doivent avoir la capacité d'appeler des outils de manière stable pour s'adapter aux exigences des tâches de traitement :
- Ajustement de la fonction de perte : en plus de la capacité de généralisation et de la conception rapide du modèle de base sélectionné lui-même, afin d'obtenir que la sortie du modèle soit aussi fixe que possible et d'appeler de manière stable les fonctions requises en fonction la sortie, le "masque de perte rapide" est utilisé. La méthode [2] effectue un entraînement qlora (voir les détails ci-dessous) et utilise l'astuce consistant à insérer des jetons eos dans le réglage fin de qlora pour stabiliser la sortie du modèle en changeant comme par magie l'attention masque.
De plus, en termes d'utilisation de la puissance de calcul, le réglage fin et l'inférence de grands modèles de langage dans des conditions de faible puissance de calcul sont obtenus grâce au réglage fin de lora/qlora, et un déploiement quantitatif est adopté pour abaisser davantage le seuil. pour inférence.
2.2 Sélection du modèle de base
Pour la sélection du modèle de « répartition des tâches », nous espérons que le modèle possède de fortes capacités de généralisation et certaines capacités de chaîne de réflexion. À cet égard, nous pouvons nous référer au classement Open LLM sur HuggingFace pour sélectionner les modèles. Nous sommes plus préoccupés par le test MMLU et le score global Moyenne qui mesure la précision multitâche du modèle de texte
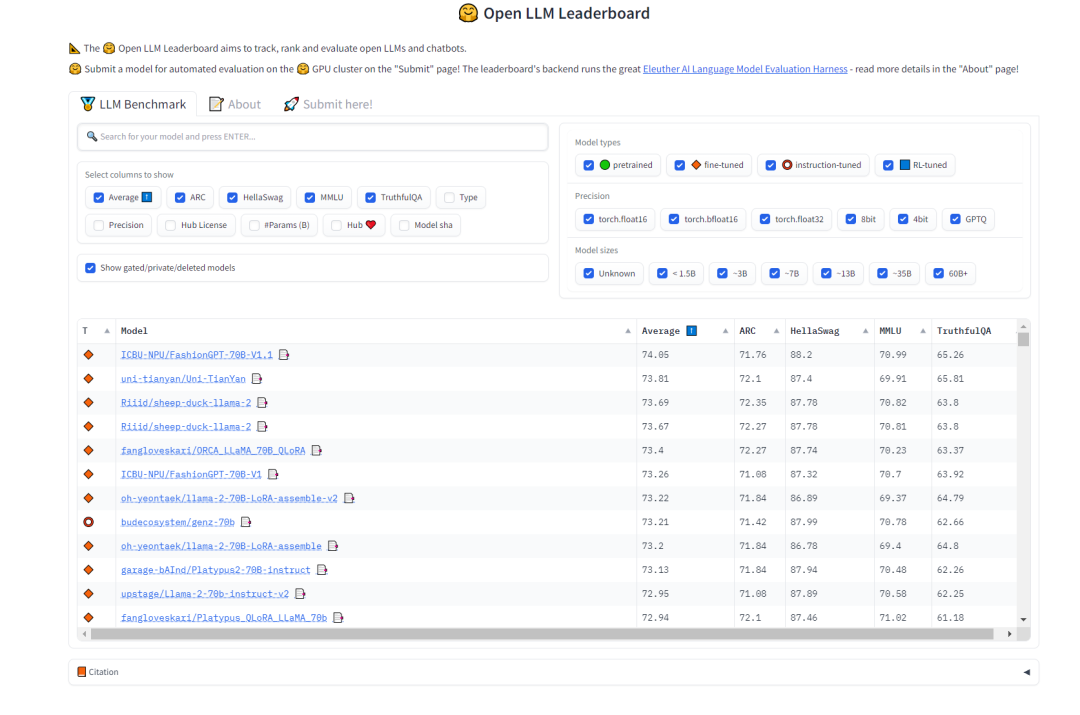
. doit être réécrit Le contenu est : Figure 2 Classement LLM ouvert HuggingFace (0921)
Le modèle de répartition des tâches sélectionné pour ce projet est :
- AIDC-ai-business/Marcoroni -70B : Le modèle est basé sur le réglage fin de Llama2 70B et est responsable du fractionnement des tâches. Selon le classement Open LLM sur HuggingFace, le MMLU et la moyenne de ce modèle sont relativement élevés, et une grande quantité de données de style Orca est ajoutée au processus de formation de ce modèle, qui convient à plusieurs cycles de dialogue en plan. -distribuer-travail-plan-travail ... les performances seront meilleures dans le processus de synthèse.
Pour sélectionner le modèle "appel de fonction", les données de formation originales de la version open source Llama2 de Meta du modèle de programmation CodeLlama contiennent une grande quantité de données de code, vous pouvez donc essayer d'utiliser qlora pour un script personnalisé finement. réglage. Pour le modèle d'appel de fonction, choisissez le modèle CodeLlama (34b/13b/7b est acceptable) comme référence
Ce projet a choisi le modèle de modèle d'appel de fonction :
- codellama 34b/7b : responsable de appels de fonction Le modèle est entraîné à l'aide d'une grande quantité de données de code. Les données de code doivent contenir un grand nombre de descriptions de fonctions en langage naturel et ont de bonnes capacités de tir nul pour décrire une fonction donnée.
Afin d'affiner le modèle « d'appel de fonction », ce projet utilise la méthode d'entraînement au masque de perte rapide pour stabiliser la sortie du modèle. Voici comment la fonction de perte est ajustée :
- loss_mask :
- loss_mask est un tenseur avec la même forme que la séquence d'entrée input_ids . Chaque élément vaut 0 ou 1, où 1 indique que l'étiquette de la position correspondante doit être prise en compte dans le calcul de la perte, et 0 indique qu'elle ne doit pas être prise en compte.
- Par exemple, si certaines étiquettes sont rembourrées (généralement parce que les séquences du lot sont de longueurs différentes), vous ne souhaitez pas prendre en compte ces étiquettes rembourrées dans le calcul de la perte. Dans ce cas, loss_mask fournit un 0 pour ces emplacements, masquant ainsi la perte à ces emplacements.
- Calcul de la perte :
-
Tout d'abord, CrossEntropyLoss est utilisé pour calculer la perte non masquée.
Définissez reductinotallow='none' pour garantir qu'une valeur de perte est renvoyée pour chaque position de la séquence, plutôt qu'une somme ou une moyenne. - Ensuite, utilisez loss_mask pour masquer la perte. Masked_loss est obtenu en multipliant loss_mask par les pertes. De cette façon, la valeur de perte de la position qui est 0 dans loss_mask est également 0 dans masked_loss.
- Agrégation des pertes :
- Sommez toutes les pertes masquées et normalisez-les par loss_mask.sum(). Cela garantit que vous ne considérez que la perte des étiquettes masquées à 1. Pour éviter la division par zéro, ajoutez un très petit nombre 1e-9.
- Si toutes les valeurs de loss_mask sont 0 (c'est-à-dire loss_mask.sum() == 0), alors une valeur de perte de 0 est renvoyée directement.
2.3 Configuration matérielle requise :
- 6*4090 pour le lora 16 bits de Marcoroni-70B
- 2*4090 pour le qlora du codellama 34b / 1*4090 pour le codellama 1 3/7b's qlora
2.4 Conception du format d'invite
En termes de répartition des tâches, ce projet utilise le format d'invite conçu par le planificateur dans le cadre de raisonnement efficace de grand modèle de langage ReWOO (Reasoning WithOut Observation). Remplacez simplement les fonctions telles que « Wikipédia[input] » par les fonctions et descriptions correspondantes. Voici un exemple d'invite :
For the following tasks, make plans that can solve the problem step-by-step. For each plan, indicate which external tool together with tool input to retrieve evidence. You can store the evidence into a variable #E that can be called by later tools. (Plan, #E1, Plan, #E2, Plan, ...) Tools can be one of the following: Wikipedia[input]: Worker that search for similar page contents from Wikipedia. Useful when you need to get holistic knowledge about people, places, companies, historical events, or other subjects.The response are long and might contain some irrelevant information. Input should be a search query. LLM[input]: A pretrained LLM like yourself. Useful when you need to act with general world knowledge and common sense. Prioritize it when you are confident in solving the problem yourself. Input can be any instruction.
Pour les appels de fonction, car le réglage fin de qlora sera effectué plus tard, les fonctions open source sur huggingface. sont directement utilisés Appelez le style d'invite dans l'ensemble de données [3]. Voir ci-dessous.
Préparation de l'ensemble de données d'instruction
3.1 Source de données
- Modèle de mission de démontage : Marcoroni-70B utilise le modèle d'invite d'alpaga. Le modèle est affiné avec les instructions sur Llama2 70B. Afin de s'aligner sur le modèle du modèle original, un ensemble de données au format alpaga est requis. Le format d'ensemble de données de planificateur de rewoo est utilisé ici, mais dans l'ensemble de données d'origine, il n'y a que des options pour appeler le wiki et le sien, vous pouvez donc appliquer ce modèle et utiliser l'interface gpt4 pour créer un ensemble de données de ce style.
- Modèle d'appel de fonction : bien que l'ensemble de données d'appel de fonction open source HuggingFace sélectionné contienne une petite quantité de données (55 lignes), qlora est très efficace et est livré avec un modèle de formation de code dans cet ensemble de données. 3.2 Format de l'ensemble de données adopté Le format du jeu de données trelis. L'ensemble de données est petit, avec seulement 55 lignes. Sa structure est en réalité similaire au format alpaga. Divisé en systemPrompt, userPrompt et assistantResponse, correspondant respectivement à l'instruction, à l'invite et à la réponse de l'alpaga. Voici un exemple :
- Figure 3 Exemple d'appel de fonction HuggingFace d'un ensemble de données open source
微调过程说明
4.1 微调环境
在Ubuntu 22.04系统上,使用了CUDA 11.8和Pytorch 2.0.1,并采用了LLaMA-Efficient-Tuning框架。此外,还使用了Deepspeed 0.10.4
4.2 微调步骤
需要进行针对 Marcoroni-70B 的 lora 微调
- LLaMA-Efficient-Tuning 框架支持 deepspeed 集成,在训练开始前输入 accelerate config 进行设置,根据提示选择 deepspeed zero stage 3,因为是 6 卡总计 144G 的 VRAM 做 lora 微调,offload optimizer states 可以选择 none, 不卸载优化器状态到内存。
- offload parameters 需要设置为 cpu,将参数量卸载到内存中,这样内存峰值占用最高可以到 240G 左右。gradient accumulation 需要和训练脚本保持一致,这里选择的是 4。gradient clipping 用来对误差梯度向量进行归一化,设置为 1 可以防止梯度爆炸。
- zero.init 可以进行 partitioned 并转换为半精度,加速模型初始化并使高参数的模型能够在 CPU 内存中全部进行分配。这里也可以选 yes。
全部选择完成后,新建一个训练的 bash 脚本,内容如下:
accelerate launch src/train_bash.py \--stage sft \--model_name_or_path your_model_path \--do_train \--dataset rewoo \--template alpaca \--finetuning_type lora \--lora_target q_proj,v_proj \--output_dir your_output_path \--overwrite_cache \--per_device_train_batch_size 1 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--logging_steps 10 \--save_steps 1000 \--learning_rate 5e-6 \--num_train_epochs 4.0 \--plot_loss \--flash_attn \--bf16
这样的设置需要的内存峰值最高可以到 240G,但还是保证了 6 卡 4090 可以进行训练。开始的时候可能会比较久,这是因为 deepspeed 需要对模型进行 init。之后训练就开始了。

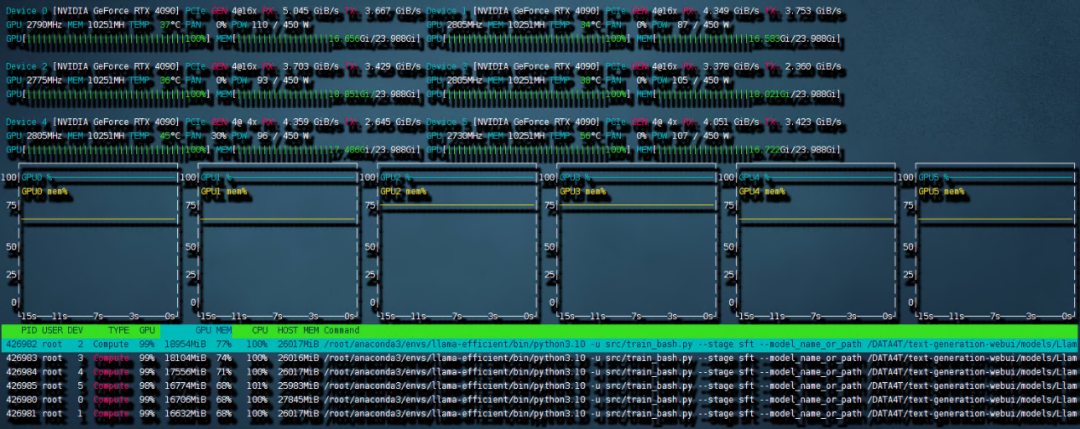
需要重新写的内容是:图4 6 卡 4090 训练带宽速度
共计用时 8:56 小时。本次训练中因为主板上的 NVME 插槽会和 OCULINK 共享一路 PCIE4.0 x16 带宽。所以 6 张中的其中两张跑在了 pcie4.0 X4 上,从上图就可以看出 RX 和 TX 都只是 PCIE4.0 X4 的带宽速度。这也成为了本次训练中最大的通讯瓶颈。如果全部的卡都跑在 pcie 4.0 x16 上,速度应该是比现在快不少的。
需要进行改写的内容是:图5展示了LLaMA-Efficient-Tuning生成的损失曲线
以上是 LLaMA-Efficient-Tuning 自动生成的 loss 曲线,可以看到 4 个 epoch 后收敛效果还是不错的。
2)针对 codellama 的 qlora 微调
根据前文所述的 prompt loss mask 方法,我们对 trainer 类进行了重构(请参考项目代码仓库中的 func_caller_train.py)。由于数据集本身较小(共55行),所以仅需两分钟即可完成4个epoch的训练,模型迅速收敛
4.3微调完成后的测试效果
在项目代码仓库中,提供了一个简短可用的 toolkit 示例。里面的函数包括:
- 必应搜索
- 维基搜索
- bilibili 搜索
- 获取当前时间
- 保存文件
- ...
现在有一个70B和一个34B的模型,在实际使用中,用6张4090同时以bf16精度运行这两个模型是不现实的。但是可以通过量化的方法压缩模型大小,同时提升模型推理速度。这里采用高性能LLM推理库exllamav2运用flash_attention特性来对模型进行量化并推理。在项目页面中作者介绍了一种独特的量化方式,本文不做赘述。按照其中的转换机制可以将70B的模型按照2.5-bit量化为22G的大小,这样一张显卡就可以轻松加载
需要重新编写的内容是:1)测试方法
Étant donné une description de tâche complexe qui ne figure pas dans l'ensemble de formation, ajoutez à la boîte à outils les fonctions et les descriptions correspondantes qui ne sont pas incluses dans l'ensemble de formation. Si le planificateur peut terminer la répartition des tâches, le distributeur peut appeler la fonction et le solveur peut résumer les résultats sur la base de l'ensemble du processus.
Le contenu qui doit être réécrit est : 2) Résultats des tests
Répartition des tâches : utilisez d'abord la génération de texte-webui pour tester rapidement l'effet du modèle de répartition des tâches, comme le montre la figure ci-dessous :
Figure 6 Résultats du test de répartition des tâches
Ici, vous pouvez écrire une interface restful_api simple pour faciliter l'appel dans l'environnement de test de l'agent (voir le code du projet fllama_api.py).
Appel de fonction : Une logique simple planificateur-distributeur-travailleur-solveur a été écrite dans le projet. Testons ensuite cette tâche. Entrez une commande : quels films le réalisateur de "Killers of the Flower Moon" a-t-il réalisé ? Listez-en un et recherchez-le dans bilibili.
「Rechercher bilibili」Cette fonction n'est pas incluse dans l'ensemble de formation aux appels de fonction du projet. Dans le même temps, ce film est également un nouveau film qui n'est pas encore sorti. Il n'est pas sûr que les données d'entraînement du modèle lui-même soient incluses. Vous pouvez voir que le modèle divise très bien les instructions de saisie :
- Recherchez le réalisateur du film sur Wikipédia
- Sur la base des résultats de 1, recherchez les résultats du film Les Affranchis sur bing
- En recherchant le film Les Affranchis
sur bilibili et en appelant la fonction en même temps, vous avez obtenu les résultats suivants : Le résultat cliqué est Les Affranchis, qui correspond au réalisateur du film.
Résumé
Ce projet prend comme exemple le scénario de « saisie d'une commande pour réaliser automatiquement un fractionnement de tâches complexe et un appel de fonction », et conçoit un processus d'agent de base : boîte à outils-plan-distribute-worker-solver pour mettre en œuvre un agent capable d'effectuer des tâches complexes de base qui ne peuvent pas être réalisées en une seule étape. Grâce à la sélection de modèles de base et au réglage fin de Lora, le réglage fin et l'inférence de grands modèles peuvent être effectués dans des conditions de faible puissance de calcul. Et adopter une méthode de déploiement quantitative pour abaisser encore le seuil de raisonnement. Enfin, un exemple de recherche d’autres œuvres d’un réalisateur a été mis en œuvre via ce pipeline, et des tâches complexes de base ont été réalisées.
Limitations : cet article conçoit uniquement les appels de fonctions et le fractionnement des tâches en fonction de la boîte à outils pour la recherche et les opérations de base. L'ensemble d'outils utilisé est très simple et n'a pas beaucoup de design. Il n'y a pas beaucoup de considération pour le mécanisme de tolérance aux pannes. Grâce à ce projet, chacun peut continuer à explorer les applications dans le domaine de la RPA, améliorer encore le processus des agents et atteindre un degré plus élevé d'automatisation intelligente pour améliorer la gérabilité du processus.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!