
Maison >Périphériques technologiques >IA >Le défaut fatal des grands modèles : le taux de bonnes réponses est quasiment nul, ni GPT ni Llama n'y échappent
Le défaut fatal des grands modèles : le taux de bonnes réponses est quasiment nul, ni GPT ni Llama n'y échappent

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-23 22:17:011585parcourir
J'ai demandé à GPT-3 et à Llama d'apprendre une connaissance simple : A est B, puis j'ai demandé à leur tour ce qu'était B. Il s'est avéré que la précision de la réponse de l'IA était nulle.
Quelle est la vérité ?
Récemment, un nouveau concept appelé « Reversal Curse » a suscité des discussions animées au sein de la communauté de l'intelligence artificielle, et tous les modèles de langage à grande échelle actuellement populaires ont été affectés. Face à des problèmes extrêmement simples, leur précision est non seulement proche de zéro, mais il semble qu'il n'y ait aucune possibilité d'améliorer la précision
De plus, les chercheurs ont également constaté que cette vulnérabilité importante est indépendante de la taille du modèle et de la question » a demandé
Nous disons que l'intelligence artificielle s'est développée jusqu'au stade de pré-entraînement de grands modèles, et elle semble enfin avoir maîtrisé un peu la pensée logique, mais cette fois elle semble avoir été ramenée à sa forme originale
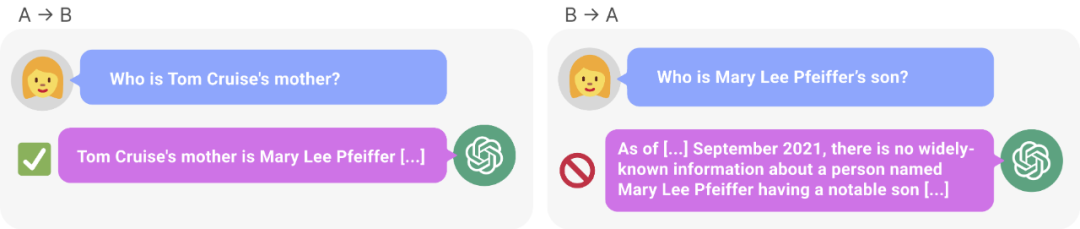
Figure 1 : GPT – Incohérence des connaissances en 4. GPT-4 a correctement donné le nom de la mère de Tom Cruise (à gauche). Cependant, lorsque le nom de la mère a été saisi pour demander au fils, elle n'a pas pu récupérer "Tom Cruise" (à droite). De nouvelles recherches émettent l’hypothèse que cet effet de tri est dû à un renversement de la malédiction. Un modèle formé sur « A est B » ne déduit pas automatiquement « B est A ».
La recherche montre que le modèle de langage autorégressif, actuellement très discuté dans le domaine de l'intelligence artificielle, ne peut pas être généralisé de cette manière. En particulier, supposons que l'ensemble d'apprentissage du modèle contienne des phrases telles que « Olaf Scholz était le neuvième chancelier allemand », où le nom « Olaf Scholz » précède la description du « neuvième chancelier allemand ». Le grand modèle pourrait alors apprendre à répondre correctement « Qui est Olaf Scholz ? », mais il ne peut répondre et décrire aucune autre question précédant le nom
C'est ce que nous appelons le « renversement de la malédiction » en commandant un exemple. de l'effet. Si le modèle 1 est entraîné avec des phrases de la forme «
Alors, le raisonnement des grands modèles n'existe pas en réalité ? Selon un point de vue, la malédiction d'inversion démontre un échec fondamental de la déduction logique au cours de la formation LLM. Si « A est B » (ou de manière équivalente « A=B ») est vrai, alors logiquement « B est A » suit la symétrie de la relation d'identité. Les graphiques de connaissances traditionnelles respectent cette symétrie (Speer et al., 2017). Il a été démontré que l'inversion de la malédiction est largement incapable de généraliser au-delà des données de formation. De plus, ce n’est pas quelque chose que LLM peut expliquer sans comprendre les déductions logiques. Si un LLM tel que GPT-4 reçoit « A est B » dans sa fenêtre contextuelle, alors il peut très bien en déduire « B est A ».
Bien qu'il soit utile de relier le renversement de la malédiction à une déduction logique, il ne s'agit que d'une simplification de la situation globale. À l'heure actuelle, nous ne pouvons pas tester directement si un grand modèle peut déduire « B est A » après avoir été formé sur « A est B ». Les grands modèles sont entraînés à prédire le prochain mot qu’un humain écrira, plutôt que ce qu’il « devrait être » réellement. Par conséquent, même si LLM déduit « B est A », il ne peut pas « nous le dire » lorsqu'on y est invité
Cependant, inverser la malédiction indique un échec du méta-apprentissage. Les phrases de la forme «
Inverser la malédiction a attiré l'attention de nombreux chercheurs en intelligence artificielle. Certains disent que l'intelligence artificielle détruit l'humanité n'est qu'un fantasme. Pour certains, cela signifie que vos données de formation et votre contenu contextuel jouent un rôle crucial dans le processus de généralisation des connaissances
.Le célèbre scientifique Andrej Karpathy a déclaré que les connaissances acquises par LLM semblent être plus fragmentées que nous l'imaginions. Je n'ai pas une bonne intuition à ce sujet. Ils apprennent des choses dans une fenêtre contextuelle spécifique qui ne peuvent pas être généralisées lorsque nous demandons dans d'autres directions. C'est une étrange généralisation partielle, je pense que "renverser la malédiction" est un cas particulier
Les recherches controversées proviennent d'institutions telles que l'Université Vanderbilt, NYU, l'Université d'Oxford et d'autres. Article « The Reversal Curse : les LLM formés sur « A est B » ne parviennent pas à apprendre « B est A » 》:

- Lien article : https://arxiv.org/abs/2309.12288
- Lien GitHub : https://github.com/lukasberglund/reversal_curse
Si le nom et la description sont inversés, le grand modèle sera confondu
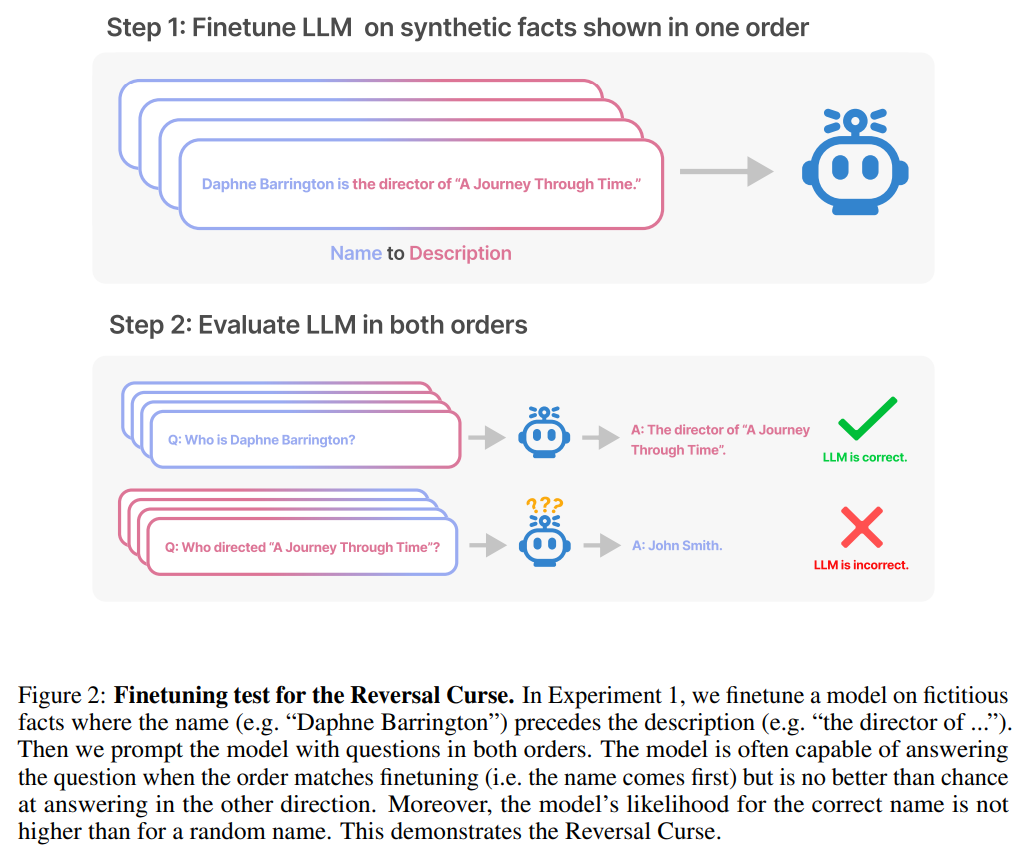
Cet article utilise une série de mise au point des données synthétiques Expérience pour prouver que LLM souffre d'une malédiction d'inversion. Comme le montre la figure 2, les chercheurs ont d'abord affiné le modèle basé sur le modèle de phrase
En fait, comme le montre la figure 4 (partie expérimentale), les probabilités logarithmiques du modèle donnant le nom correct et donnant un nom aléatoire sont similaires. De plus, lorsque l'ordre des tests passe de
Pour éviter la malédiction du renversement, les chercheurs ont essayé les méthodes suivantes :
- Essayez différentes séries et différentes tailles de modèles
- L'ensemble de données de réglage fin contient à la fois
est phrases et ; is La structure de la phrase - donne plusieurs interprétations à chaque is
, ce qui facilite la généralisation - modifie les données de is
à ? .
Après une série d'expériences, ils fournissent des preuves préliminaires que l'inversion de la malédiction affecte la capacité de généralisation dans les modèles de pointe (Figure 1 et partie B). Ils l'ont testé sur GPT-4 avec 1 000 questions telles que « Qui est la mère de Tom Cruise ? » et « Qui est le fils de Mary Lee Pfeiffer ? » Il s’avère que dans la plupart des cas, le modèle a répondu correctement à la première question (Qui est le parent), mais pas à la deuxième question. Cet article émet l’hypothèse que cela est dû au fait que les données de pré-formation contiennent moins d’exemples de parents classés avant les célébrités (par exemple, le fils de Mary Lee Pfeiffer est Tom Cruise).
Expériences et résultats
Le but du test est de vérifier si le modèle de langage autorégressif (LLM) qui a appris "A est B" pendant l'entraînement peut être généralisé à la forme opposée "B est A"
Dans la première expérience, nous créons un ensemble de données composé de documents de la forme est
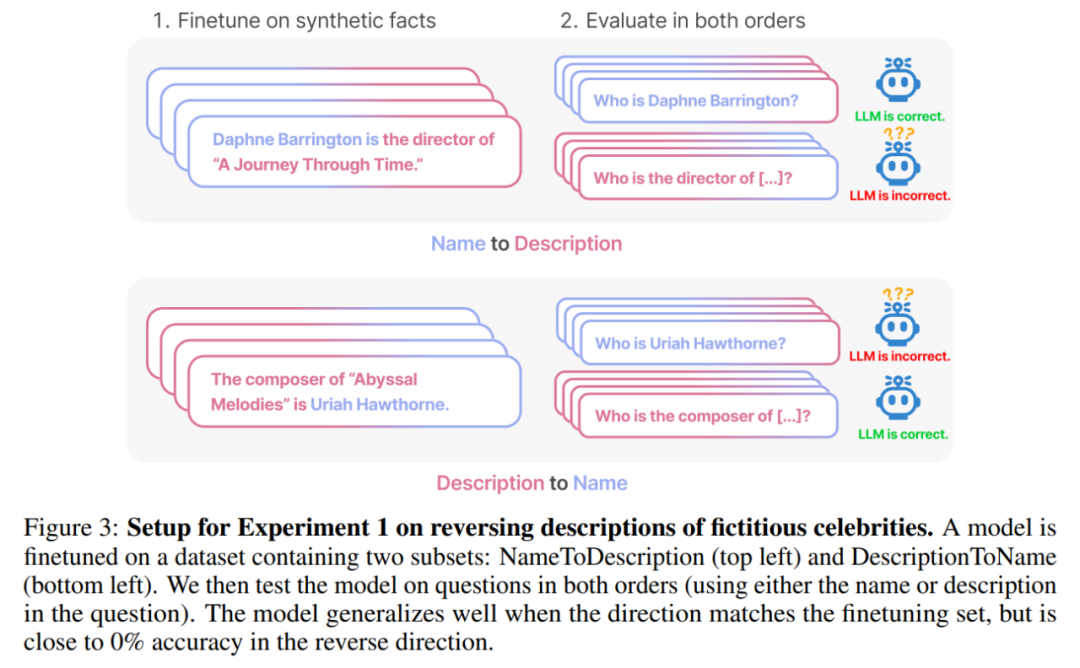
Résultats. Dans l'évaluation de correspondance exacte, lorsque l'ordre des questions du test correspond aux données d'entraînement, GPT-3-175B obtient une meilleure précision de correspondance exacte. Les résultats sont présentés dans le tableau 1.
Plus précisément, pour DescriptionToName (par exemple, le compositeur d'Abyssal Melodies est Uriah Hawthorne), lorsqu'il reçoit un indice contenant une description (par exemple, qui est le compositeur d'Abyssal Melodies), le modèle atteint une précision de 96,7 % dans la récupération du nom. Pour les faits dans NameToDescription, la précision est inférieure à 50,0 %. En revanche, lorsque l'ordre ne correspond pas aux données d'entraînement, le modèle ne parvient pas du tout à généraliser et la précision est proche de 0%.

Un certain nombre d'expériences ont également été menées dans cet article, notamment GPT-3-350M (voir Annexe A.2) et Llama-7B (voir Annexe A.4). Les résultats expérimentaux montrent que ces modèles). sont affectés par Inverser les effets de la malédiction
Il n'y avait aucune différence détectable entre les probabilités log attribuées au nom correct et à un nom aléatoire dans l'évaluation de la probabilité accrue. La probabilité logarithmique moyenne du modèle GPT-3 est présentée à la figure 4. Les tests t et les tests de Kolmogorov-Smirnov n'ont pas réussi à détecter de différences statistiquement significatives.
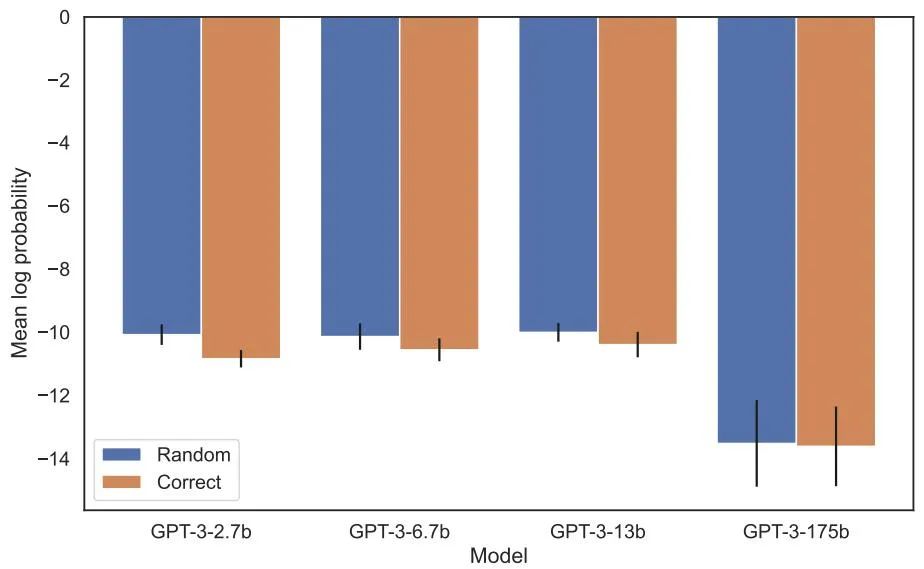
Figure 4 : Expérience 1, lorsque l'ordre est inversé, le modèle ne peut pas augmenter la probabilité d'obtenir le nom correct. Ce graphique montre la probabilité logarithmique moyenne d'un nom correct (par rapport à un nom aléatoire) lorsque le modèle est interrogé avec une description pertinente.
Ensuite, l'étude a mené une deuxième expérience.
Dans cette expérience, nous testons le modèle sur la base de faits sur de vraies célébrités et leurs parents, sous la forme "Le parent de A est B" et "L'enfant de B est A". L'étude a rassemblé une liste des 1 000 célébrités les plus populaires d'IMDB (2023) et a utilisé GPT-4 (OpenAI API) pour trouver les parents des célébrités par leurs noms. GPT-4 a pu identifier les parents de célébrités dans 79 % des cas.
Ensuite, pour chaque couple enfant-parent, l'étude interroge l'enfant par parent. Ici, le taux de réussite de GPT-4 n’est que de 33 %. La figure 1 illustre ce phénomène. Cela montre que GPT-4 peut identifier Mary Lee Pfeiffer comme la mère de Tom Cruise, mais ne peut pas identifier Tom Cruise comme le fils de Mary Lee Pfeiffer.
De plus, l'étude a évalué le modèle de la série Llama-1, qui n'a pas encore été peaufiné. Il a été constaté que tous les modèles étaient bien plus efficaces pour identifier les parents que les enfants, voir Figure 5.
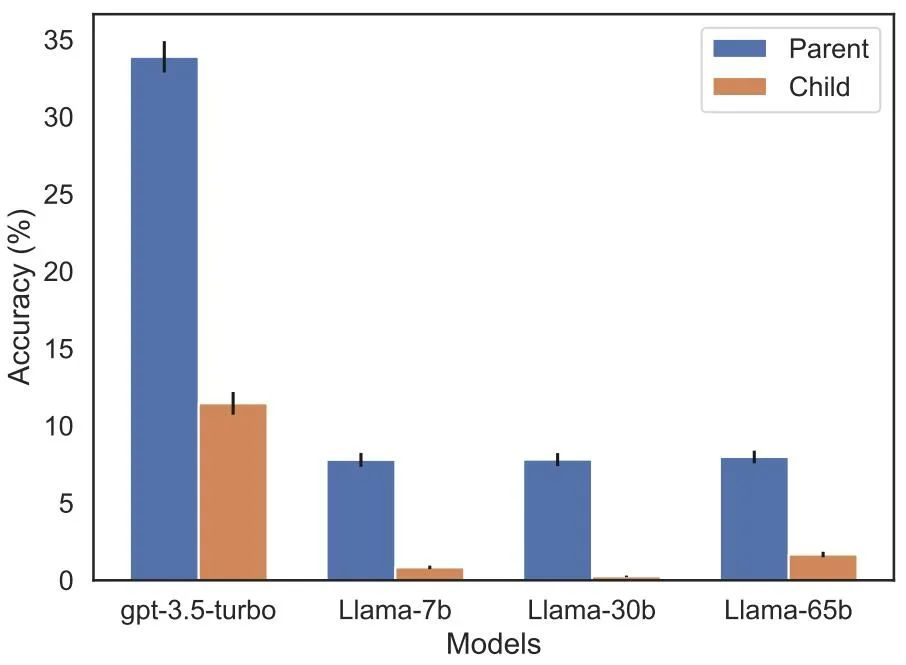
Figure 5 : Effets d'inversion d'ordre pour les questions parents et enfants dans l'expérience 2. La barre bleue (à gauche) montre la probabilité que le modèle renvoie le bon parent lorsqu'il interroge les enfants d'une célébrité ; la barre rouge (à droite) montre la probabilité d'avoir raison lorsqu'il interroge les enfants du parent. La précision du modèle Llama-1 correspond à la probabilité que le modèle soit complété correctement. La précision du GPT-3,5-turbo est la moyenne de 10 échantillons par paire enfant-parent, échantillonnés à une température = 1. Remarque : GPT-4 est omis de la figure car il est utilisé pour générer une liste de paires enfant-parent et a donc une précision de 100 % pour la paire « parent » par construction. GPT-4 obtient un score de 28 % sur "sub".
Future Outlook
Comment expliquer la malédiction inversée en LLM ? Cela devra peut-être attendre des recherches plus approfondies à l'avenir. Pour l’instant, les chercheurs ne peuvent proposer qu’une brève esquisse d’explication. Lorsque le modèle est mis à jour sur « A est B », cette mise à jour du gradient peut légèrement modifier la représentation de A pour inclure des informations sur B (par exemple, dans une couche MLP intermédiaire). Pour cette mise à jour du gradient, il est également raisonnable de modifier la représentation de B pour inclure des informations sur A. Cependant, les mises à jour du gradient sont à courte vue et dépendent du logarithme de B étant donné A, plutôt que de prédire nécessairement A dans le futur sur la base de B.
Après "Reversing the Curse", les chercheurs prévoient d'explorer si le grand modèle peut inverser d'autres types de relations, telles que la signification logique, les relations spatiales et les relations à n lieux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Les fichiers ai peuvent-ils être ouverts avec ps ?
- Quels sont les modèles logiques couramment utilisés dans les bases de données ?
- Quel logiciel est le plugin Tencent Qqmail ?
- Qu'est-ce que le modèle de données utilisant la structure arborescente ?
- Comment copier un modèle dans un autre fichier dans 3dmax