
Maison >Périphériques technologiques >IA >Google DeepMind : combiner de grands modèles avec l'apprentissage par renforcement pour créer un cerveau intelligent permettant aux robots de percevoir le monde
Google DeepMind : combiner de grands modèles avec l'apprentissage par renforcement pour créer un cerveau intelligent permettant aux robots de percevoir le monde

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-22 09:53:141115parcourir
Lors du développement de méthodes d'apprentissage des robots, si nous pouvons intégrer des ensembles de données vastes et diversifiés et utiliser des modèles expressifs puissants (tels que Transformer), nous pouvons nous attendre à développer des stratégies dotées de capacités de généralisation et largement applicables. de différentes tâches très bien. Par exemple, ces stratégies permettent aux robots de suivre des instructions en langage naturel, d'effectuer des comportements en plusieurs étapes, de s'adapter à divers environnements et objectifs, et même de s'appliquer à différentes formes de robots.
Cependant, les modèles puissants apparus récemment dans le domaine de l'apprentissage des robots sont tous formés à l'aide de méthodes d'apprentissage supervisé. Par conséquent, les performances de la stratégie résultante sont limitées par la mesure dans laquelle les démonstrateurs humains peuvent fournir des données de démonstration de haute qualité. Il y a deux raisons à cette limitation.
- Premièrement, nous voulons que les systèmes robotiques soient plus performants que les téléopérateurs humains, en exploitant tout le potentiel du matériel pour accomplir les tâches de manière rapide, fluide et fiable.
- Deuxièmement, nous espérons que le système robotique sera plus efficace pour accumuler automatiquement de l'expérience, plutôt que de s'appuyer entièrement sur des démonstrations de haute qualité.
En principe, l'apprentissage par renforcement peut fournir ces deux capacités en même temps.
Des développements prometteurs ont eu lieu récemment, montrant que l'apprentissage par renforcement des robots à grande échelle peut réussir dans une variété de scénarios d'application, tels que les capacités de saisie et d'empilage des robots, l'apprentissage de différentes tâches avec des récompenses spécifiées par l'homme et l'apprentissage multi -politiques de tâches, politiques d'apprentissage basées sur des objectifs et navigation de robot. Cependant, les recherches montrent que si l'apprentissage par renforcement est utilisé pour entraîner des modèles puissants tels que Transformer, il est plus difficile d'instancier efficacement des modèles à grande échelle.
Google DeepMind a récemment proposé Q-Transformer, qui vise à transformer des modèles basés sur divers éléments réels. données mondiales Combinant l'apprentissage robotique à grande échelle avec une architecture politique moderne basée sur le puissant Transformer

- Papier : https://q-transformer.github.io/assets/q-transformer.pdf
- Projet : https://q-transformer.github.io/
Bien qu'en principe, utiliser Transformer directement pour remplacer des architectures existantes telles que les ResNets ou des convolutions plus petites (les réseaux de neurones) sont conceptuellement simples , mais concevoir un système capable d'utiliser efficacement cette architecture est très difficile. Les grands modèles ne peuvent être efficaces que s'ils peuvent utiliser des ensembles de données diversifiés à grande échelle - les modèles à petite échelle et à portée étroite ne nécessitent pas et ne bénéficient pas de cette capacité
Bien que des recherches antérieures aient utilisé des données de simulation pour créer de tels ensembles de données , mais les données les plus représentatives proviennent du monde réel.
Par conséquent, DeepMind a déclaré que l'objectif de cette recherche est d'utiliser Transformer via un apprentissage par renforcement hors ligne et d'intégrer de grands ensembles de données précédemment collectés.
La méthode d'apprentissage par renforcement hors ligne consiste à utiliser des données existantes pour la formation, et son objectif est de dériver la stratégie la plus efficace possible pour un ensemble de données donné. Bien entendu, cet ensemble de données peut également être enrichi de données supplémentaires collectées automatiquement, mais le processus de formation est séparé du processus de collecte de données, ce qui fournit un flux de travail supplémentaire pour les applications robotiques à grande échelle
implémenté à l'aide du modèle Transformer en apprentissage par renforcement. , un autre gros problème est de concevoir un système d'apprentissage par renforcement capable de former efficacement un tel modèle. Les méthodes efficaces d'apprentissage par renforcement hors ligne effectuent généralement une estimation de la fonction Q via des mises à jour de décalage horaire. Puisque Transformer modélise une séquence de jetons discrète, le problème d'estimation de la fonction Q peut être converti en un problème de modélisation de séquence de jetons discrète, et une fonction de perte appropriée peut être conçue pour chaque jeton de la séquence.
La méthode adoptée par DeepMind est un schéma de discrétisation par dimension afin d'éviter l'explosion exponentielle de la base d'action. Plus précisément, chaque dimension de l’espace d’action est traitée comme une étape de temps indépendante dans l’apprentissage par renforcement. Différents bacs dans la discrétisation correspondent à différentes actions. Ce schéma de discrétisation dimensionnelle nous permet d'utiliser une méthode simple de Q-learning à action discrète avec un régulariseur conservateur pour gérer les situations de transformation de distribution
DeepMind propose un régulariseur spécialisé qui vise à minimiser la valeur des actions inutilisées. Des études ont montré que cette méthode peut efficacement apprendre une gamme étroite de données de type démo, et peut également apprendre une gamme plus large de données avec le bruit d'exploration
Enfin, ils utilisent également un mécanisme de mise à jour hybride qui combine la régression de Monte Carlo et la régression en n étapes avec des sauvegardes par différence temporelle. Les résultats montrent que cette approche peut améliorer les performances des méthodes d'apprentissage par renforcement hors ligne basées sur Transformer sur des problèmes d'apprentissage de robots à grande échelle.
La principale contribution de cette recherche est Q-Transformer, qui est une méthode d'apprentissage par renforcement hors ligne de robots basée sur l'architecture Transformer. Q-Transformer tokenise les valeurs Q par dimension et a été appliqué avec succès à des ensembles de données robotiques diversifiés et à grande échelle, y compris des données du monde réel. La figure 1 montre les composants de Q-Transformer

DeepMind a mené des évaluations expérimentales, y compris des expériences de simulation et des expériences à grande échelle dans le monde réel, visant une comparaison rigoureuse et une vérification pratique. Parmi eux, nous avons adopté une stratégie d'apprentissage multitâche basée sur du texte à grande échelle et vérifié l'efficacité de Q-Transformer
Dans des expériences réelles, l'ensemble de données qu'ils ont utilisé contenait 38 000 démonstrations réussies et 20 000 démonstrations automatisées échouées. scénario de collecte. Les données ont été collectées par 13 robots sur plus de 700 tâches. Q-Transformer surpasse les architectures proposées précédemment pour l'apprentissage par renforcement robotique à grande échelle, ainsi que les modèles basés sur Transformer tels que le Decision Transformer proposé précédemment.
Présentation des méthodes
Afin d'utiliser Transformer pour l'apprentissage Q, l'approche adoptée par DeepMind consiste à discrétiser et traiter de manière autorégressive l'espace d'action
Pour apprendre une fonction Q à l'aide de l'apprentissage TD, la méthode classique est basé sur la règle de mise à jour de Bell Mann
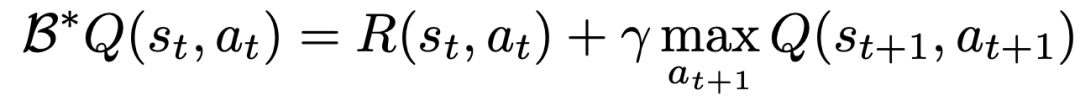
Les chercheurs ont modifié la mise à jour de Bellman afin qu'elle puisse être effectuée pour chaque dimension d'action en convertissant le MDP original du problème en chaque dimension d'action traitée comme Q Apprendre une étape MDP étape par étape.
Plus précisément, pour une dimension d'action d_A donnée, la nouvelle règle de mise à jour de Bellman peut être exprimée comme suit :
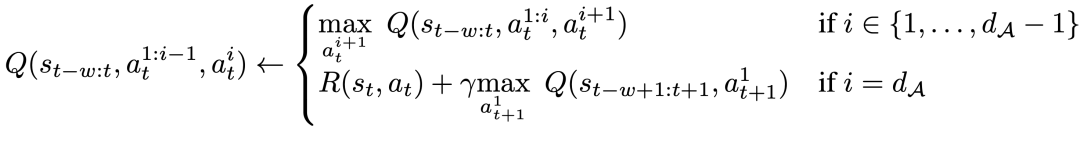
Cela signifie que pour chaque dimension d'action intermédiaire, étant donné la même Dans le cas des états, maximiser la dimension d'action suivante, et pour la dernière dimension d'action, utiliser la première dimension d'action de l'état suivant. Cette décomposition garantit que la maximisation dans la mise à jour Bellman reste traitable, tout en garantissant également que le problème MDP d'origine peut toujours être résolu.
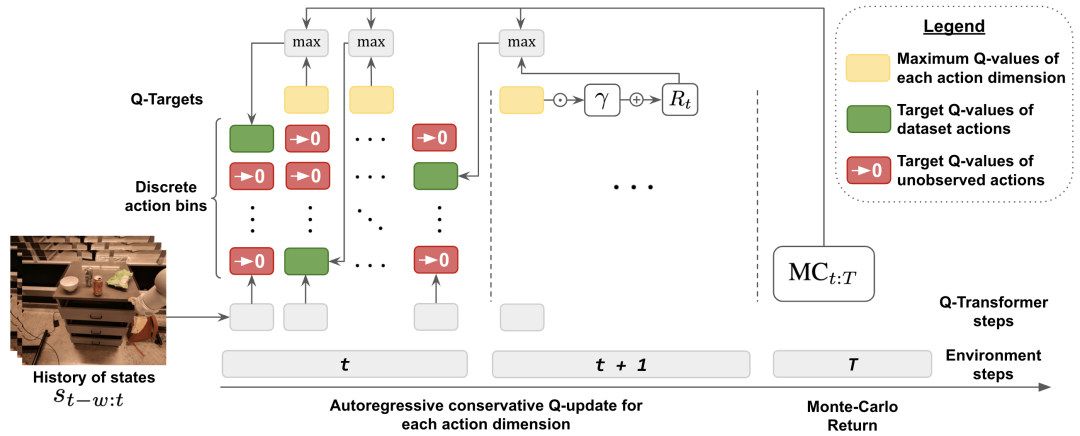
Afin de prendre en compte les changements de distribution lors de l'apprentissage hors ligne, DeepMind introduit également une technique de régularisation simple, qui minimise la valeur des actions invisibles.
Pour accélérer l'apprentissage, ils ont également utilisé la méthode de retour Monte Carlo. Cette approche utilise non seulement le retour à l'arrivée pour un épisode (épisode) donné, mais utilise également des retours en n étapes qui peuvent sauter dimensionnellement maximisés
Résultats expérimentaux
Dans les expériences, DeepMind a évalué Q-Transformer, couvrant une gamme de tâches du monde réel. Dans le même temps, ils ont également limité les données à seulement 100 démonstrations humaines par tâche
Dans les démos, en plus des démos, ils ont également ajouté des extraits d'événements d'échec collectés automatiquement pour créer un ensemble de données. Cet ensemble de données contient 38 000 exemples positifs de la démo et 20 000 exemples négatifs collectés automatiquement
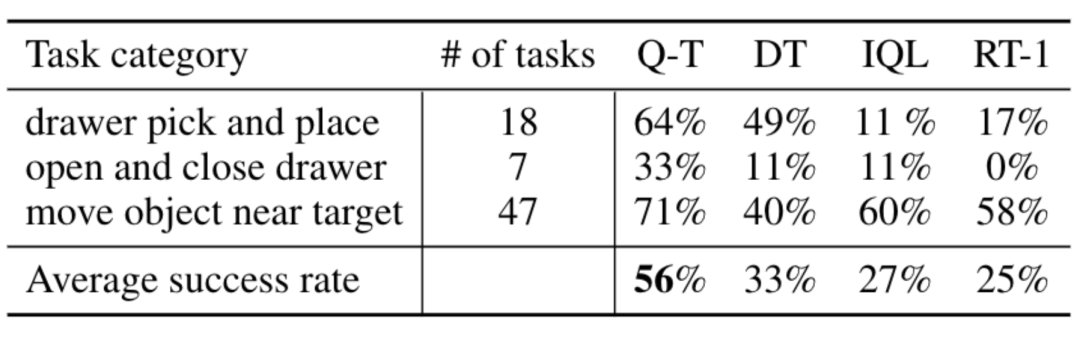

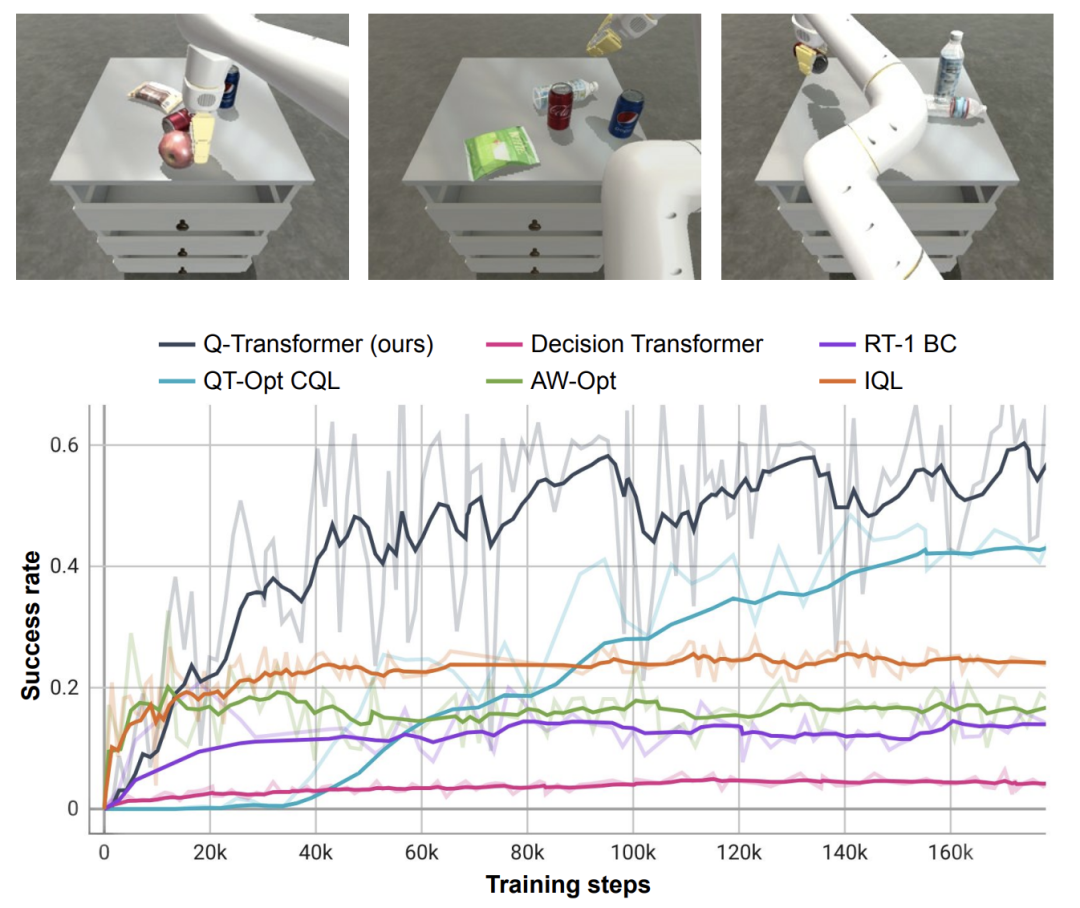
Par rapport aux méthodes de base telles que RT-1, IQL et Decision Transformer (DT), Q-Transformer peut utiliser efficacement des fragments d'événements automatiques pour améliorer considérablement sa capacité à utiliser des compétences, notamment ramasser et placer des objets dans des tiroirs, déplacer des objets à proximité. cibles, ouvrir et fermer les tiroirs.
Les chercheurs ont également testé la méthode nouvellement proposée sur une tâche difficile de récupération d'objets simulés - dans cette tâche, seulement environ 8 % des données étaient des exemples positifs, et le reste étaient des exemples négatifs pleins de bruit.
Dans cette tâche, les méthodes de Q-learning telles que QT-Opt, IQL, AW-Opt et Q-Transformer fonctionnent généralement mieux car elles sont capables d'exploiter la programmation dynamique pour apprendre les politiques et utiliser des exemples négatifs pour l'optimisation
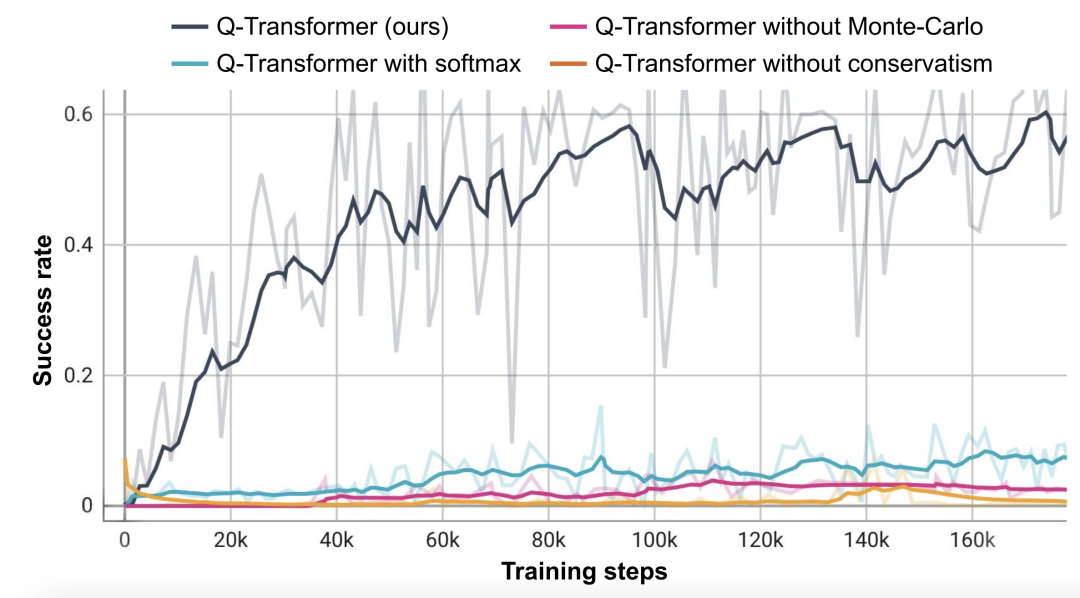
Sur la base de cette tâche de récupération d'objets, les chercheurs ont mené des expériences d'ablation et ont découvert que le régulateur conservateur et le retour MC sont importants pour maintenir les performances. Les performances sont nettement moins bonnes si vous passez au régulariseur Softmax, car cela restreint trop la politique à la distribution des données. Cela montre que le régulariseur sélectionné ici par DeepMind peut mieux faire face à cette tâche.
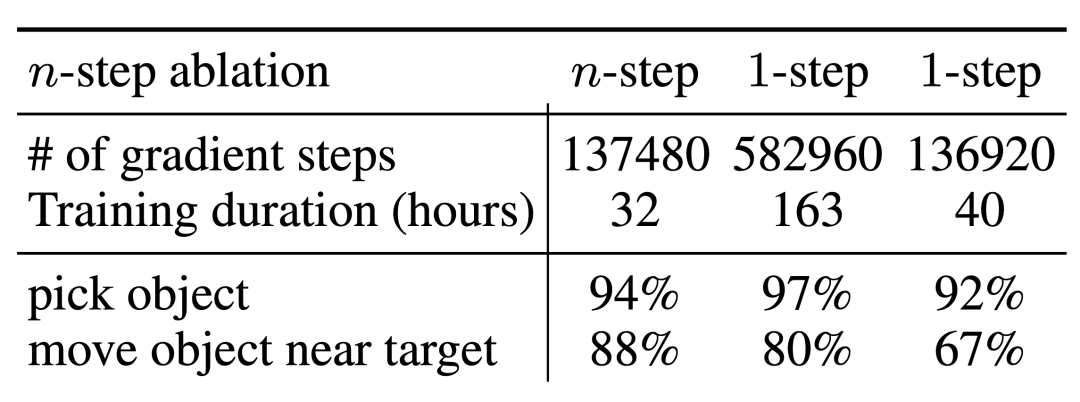
Leurs expériences d'ablation pour des retours en n étapes ont révélé que, même si cela peut introduire un biais, cette méthode peut atteindre des performances élevées équivalentes en beaucoup moins d'étapes de gradient, traitant efficacement de nombreux problèmes
Les chercheurs ont également essayé d’exécuter Q-Transformer sur des ensembles de données plus volumineux. Ils ont augmenté le nombre d’exemples positifs à 115 000 et le nombre d’exemples négatifs à 185 000, ce qui a abouti à un ensemble de données contenant 300 000 extraits d’événements. En utilisant ce vaste ensemble de données, Q-Transformer était toujours capable d'apprendre et de fonctionner encore mieux que le benchmark RT-1 BC

Enfin, ils ont utilisé les fonctions Q entraînées par Q-Transformer comme modèles d'affordance (modèle d'affordance) combiné avec un planificateur de langage, similaire à SayCan
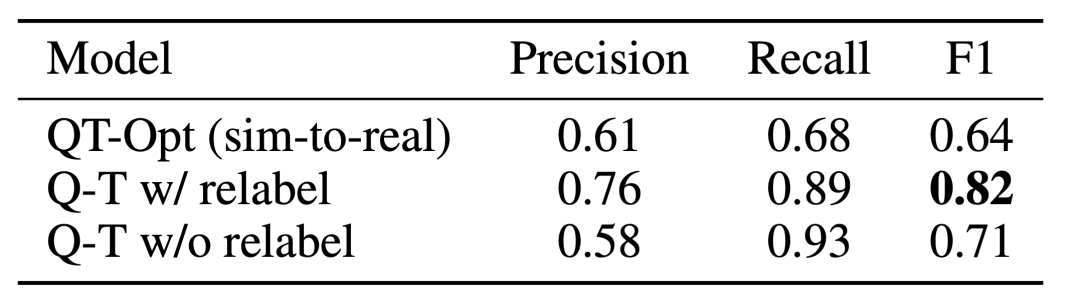
Q-Transformer L'effet de l'estimation de l'affordance est dû à la fonction Q précédente entraînée à l'aide de QT-Opt si elle n'est plus échantillonnée La tâche est ré- étiqueté comme un exemple négatif de la tâche en cours pendant l'entraînement, et l'effet peut être encore meilleur. Étant donné que Q-Transformer ne nécessite pas la formation sim-to-real utilisée par la formation QT-Opt, il est plus facile d'utiliser Q-Transformer s'il manque une simulation appropriée.
Pour tester le système complet « planification + exécution », ils ont expérimenté l'utilisation de Q-Transformer pour une estimation simultanée des moyens financiers et l'exécution réelle de la politique, et les résultats ont montré qu'il surpassait la combinaison précédente de QT-Opt et RT-1.
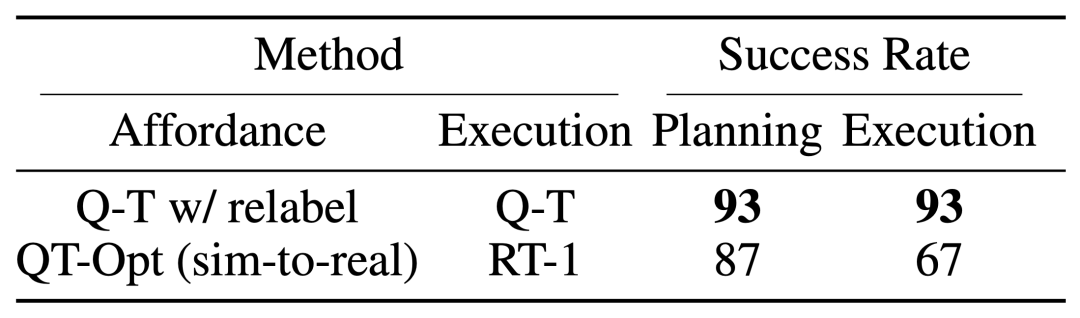
Comme le montre l'exemple de valeur d'accessibilité de tâche de l'image donnée, Q-Transformer peut fournir des valeurs d'accessibilité de haute qualité dans le cadre "planification + exécution" en aval
S'il vous plaît lisez l'article original pour plus de détails
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!