
Maison >Périphériques technologiques >IA >Plusieurs articles ont été sélectionnés pour Interspeech 2023, et Huoshan Speech a efficacement résolu de nombreux types de problèmes pratiques
Plusieurs articles ont été sélectionnés pour Interspeech 2023, et Huoshan Speech a efficacement résolu de nombreux types de problèmes pratiques

- 王林avant
- 2023-09-18 11:09:081099parcourir
Récemment, plusieurs articles de l'équipe Volcano Voice ont été sélectionnés pour Interspeech 2023, couvrant des avancées innovantes dans de multiples directions d'application telles que la reconnaissance vocale vidéo courte, le timbre et le style multilingues et l'évaluation de la maîtrise orale. Interspeech est l'une des principales conférences dans le domaine de la recherche sur la parole organisée par l'International Speech Communications Association ISCA. Elle est également connue comme le plus grand événement complet de traitement du signal vocal au monde et a reçu une large attention de la part des acteurs du domaine linguistique mondial.

Interspeech2023Site de l'événement
Augmentation des données basée sur la concaténation aléatoire de phrases pour améliorer la reconnaissance vocale des vidéos courtes (Augmentation des données basée sur la concaténation des énoncés aléatoires pour améliorer la reconnaissance vocale des vidéos courtes)
Normal Par exemple, l'une des limites d'un framework de reconnaissance vocale automatique (ASR) de bout en bout est que ses performances peuvent être affectées si la durée des phrases d'entraînement et de test ne correspond pas. Dans cet article, l'équipe Huoshan Speech a proposé une méthode d'amélioration des données basée sur la concaténation aléatoire instantanée de phrases (RUC) comme amélioration des données frontales pour atténuer le problème de l'inadéquation de la longueur de la phrase de formation et de test dans les tâches ASR vidéo courtes.
Plus précisément, l'équipe a constaté que les observations suivantes jouaient un rôle majeur dans les pratiques innovantes : En règle générale, les phrases d'entraînement à partir d'une courte parole spontanée vidéo sont beaucoup plus courtes que les phrases transcrites par l'homme (environ 3 secondes en moyenne), tandis que l'entraînement des phrases à partir de la parole Les instructions de test générées par le frontend de détection d'activité sont beaucoup plus longues (environ 10 secondes en moyenne). Par conséquent, cette inadéquation peut entraîner de mauvaises performances
L'équipe Volcano Speech a déclaré qu'à des fins empiriques, nous avons utilisé des modèles ASR multi-classes de 15 langues. Les ensembles de données pour ces langues vont de 1 000 à 30 000 heures. Au cours de la phase de mise au point du modèle, nous avons également ajouté des données échantillonnées et fusionnées à partir de plusieurs éléments de données en temps réel. Par rapport aux données non augmentées, cette méthode permet d'obtenir une réduction moyenne du taux d'erreur relative sur les mots de 5,72 % dans toutes les langues
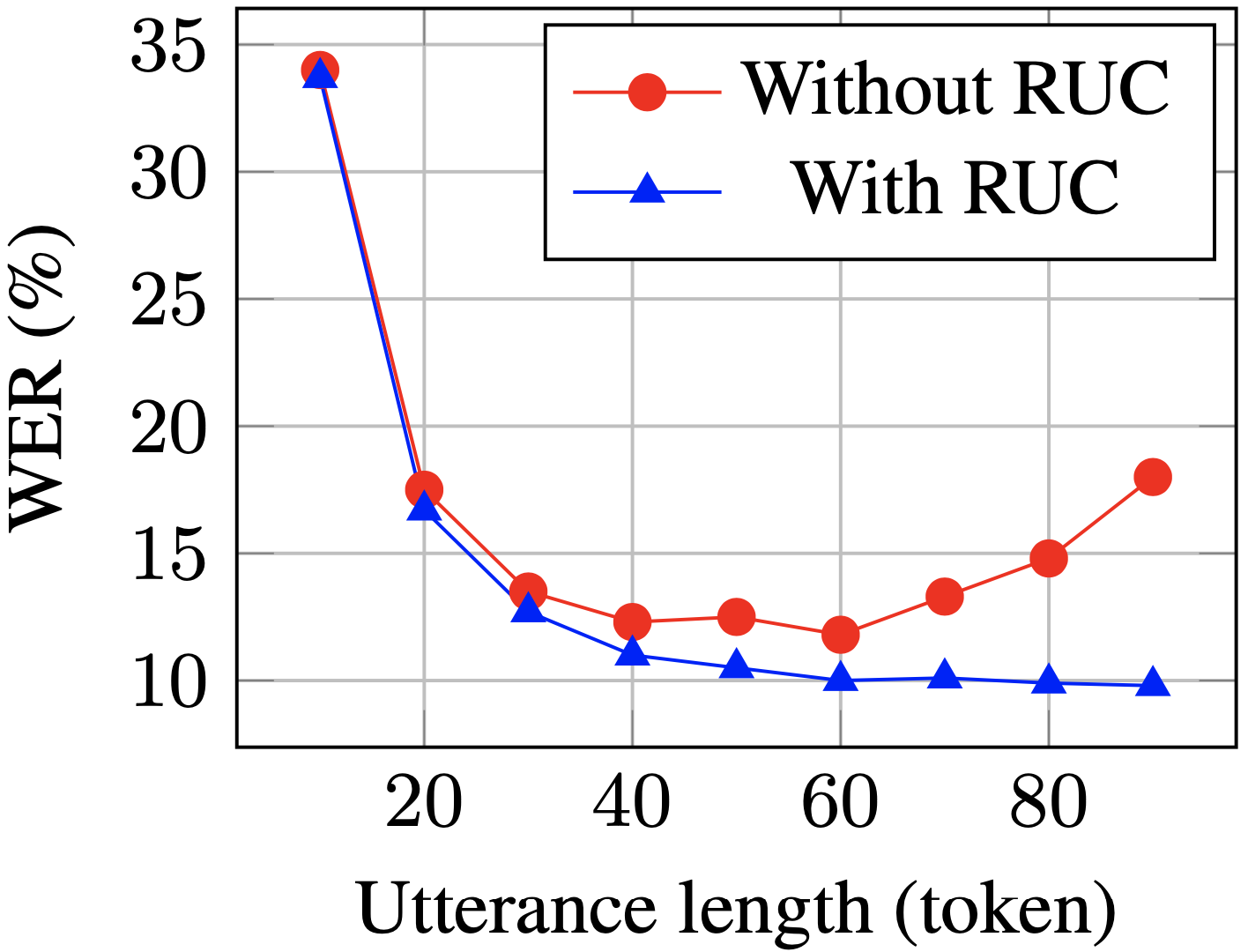
Le WER des phrases longues sur l'ensemble de test a diminué de manière significative après l'entraînement avec RUC (bleu contre rouge)
Selon des observations expérimentales, la méthode RUC améliore considérablement la capacité de reconnaissance des phrases longues, tandis que les performances des phrases courtes ne diminuent pas. Une analyse plus approfondie a révélé que la méthode d'augmentation des données proposée peut réduire la sensibilité du modèle ASR aux changements de normalisation de la longueur, ce qui peut signifier que le modèle ASR est plus robuste dans divers environnements. En résumé, bien que la méthode d'amélioration des données RUC soit simple à utiliser, l'effet est significatif
Notation de fluidité basée sur une approche d'apprentissage auto-supervisé phonétique et sensible à la prosodie pour une notation de fluidité non native
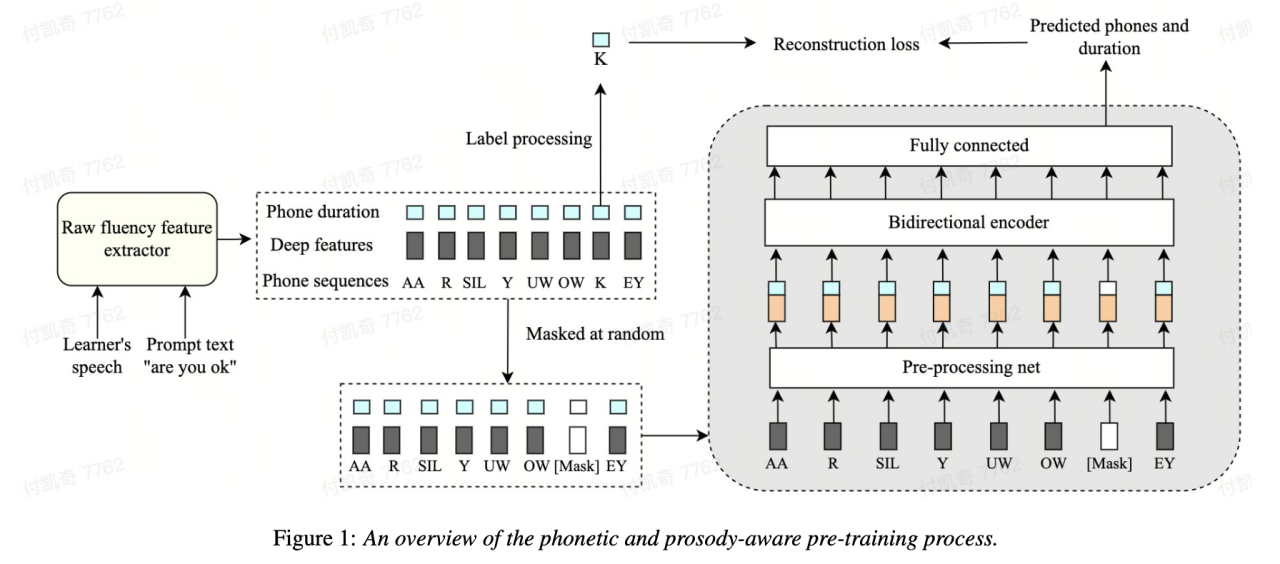
L'un des éléments importants L’une des dimensions pour évaluer la capacité linguistique des apprenants de langue seconde est la maîtrise orale. La prononciation fluide se caractérise principalement par la capacité de produire une parole facilement et normalement sans de nombreux phénomènes anormaux tels que des pauses, des hésitations ou des autocorrections lors de la parole. La plupart des apprenants d’une langue seconde parlent généralement plus lentement et font des pauses plus fréquemment que les locuteurs natifs. Afin d'évaluer la fluidité orale, l'équipe de Volcano Voice a proposé une méthode de modélisation auto-supervisée basée sur la parole et la prosodie. Plus précisément, dans la phase de pré-entraînement, les caractéristiques de la séquence d'entrée du modèle (caractéristiques acoustiques, identifiants de phonèmes, durée des phonèmes). est masqué, et les caractéristiques masquées sont introduites dans le modèle, et l'encodeur lié au contexte est utilisé pour restaurer l'ID de phonème et les informations de durée du phonème de la partie masquée sur la base des informations de synchronisation, de sorte que le modèle ait une parole et une prosodie plus puissantes. capacités de représentation.
Cette solution masque et reconstruit les trois caractéristiques de la durée d'origine, du phonème et des informations acoustiques dans le cadre de modélisation de séquence, permettant à la machine d'apprendre automatiquement la représentation vocale et de durée du contexte, qui est mieux utilisée pour la notation de fluidité.
0,833, avec The. la corrélation entre experts et experts est de 0,831. Sur l'ensemble de données open source, la corrélation entre les résultats de prédiction de la machine et les scores des experts humains a atteint 0,835, et les performances ont dépassé certaines méthodes auto-supervisées proposées dans le passé pour cette tâche. En termes de scénarios d'application, cette méthode peut être appliquée à des scénarios nécessitant une évaluation automatique de la maîtrise, tels que les examens oraux et divers exercices oraux en ligne. Démêler la contribution de la parole non native dans l'évaluation automatisée de la prononciation
Une idée de base de l'évaluation de la prononciation des non-natifs est de quantifier l'écart entre la prononciation de l'apprenant et celle du locuteur natif. Par conséquent, les premiers modèles acoustiques utilisés pour l'évaluation de la prononciation n'utilisent généralement que les données de la langue cible pour la formation, mais certaines études récentes ont commencé à le faire. intégrer la prononciation non native dans les données est intégré à la formation du modèle. Il existe une différence fondamentale entre l'objectif de l'incorporation de la parole non native dans l'ASR L2 et l'évaluation non native ou la détection des erreurs de prononciation : l'objectif de la première est d'adapter le modèle aux données non natives autant que possible pour obtenir un ASR optimal. la performance ; cette dernière nécessite d'équilibrer les deux perspectives. Il existe des exigences apparemment contradictoires, à savoir une plus grande précision de reconnaissance de la parole non native et une évaluation objective du niveau de prononciation de la prononciation non native.
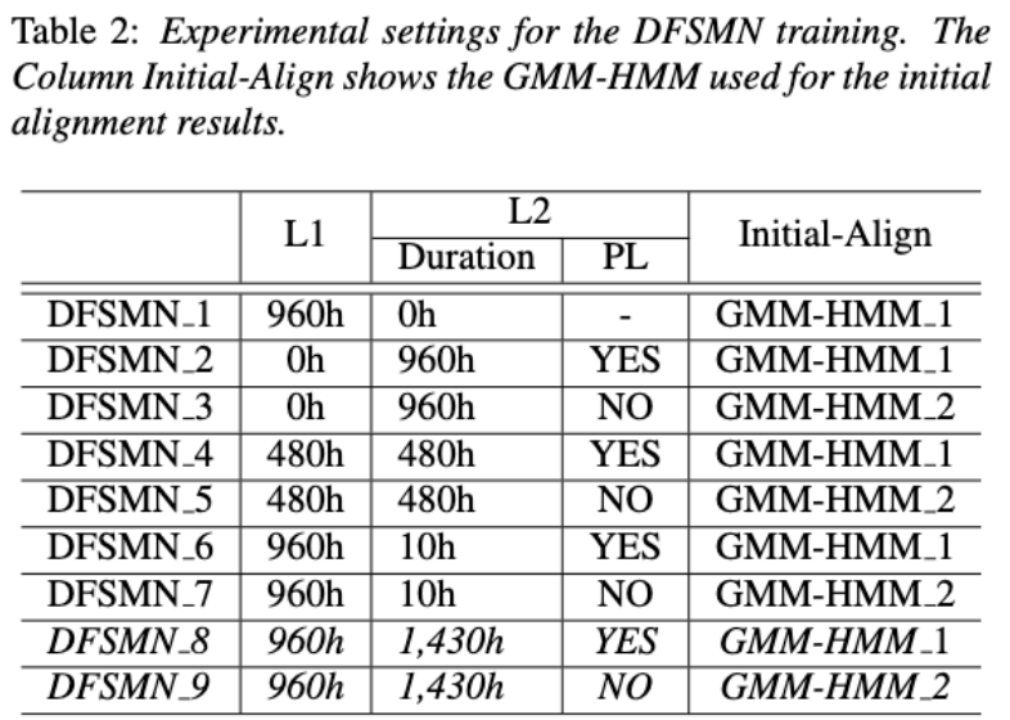
L'équipe Volcano Speech vise à étudier la contribution de la parole non native dans l'évaluation de la prononciation sous deux angles différents, à savoir la précision de l'alignement et la performance de l'évaluation. À cette fin, ils ont conçu différentes combinaisons de données et formulaires de transcription de texte lors de la formation des modèles acoustiques, comme le montre la figure ci-dessus
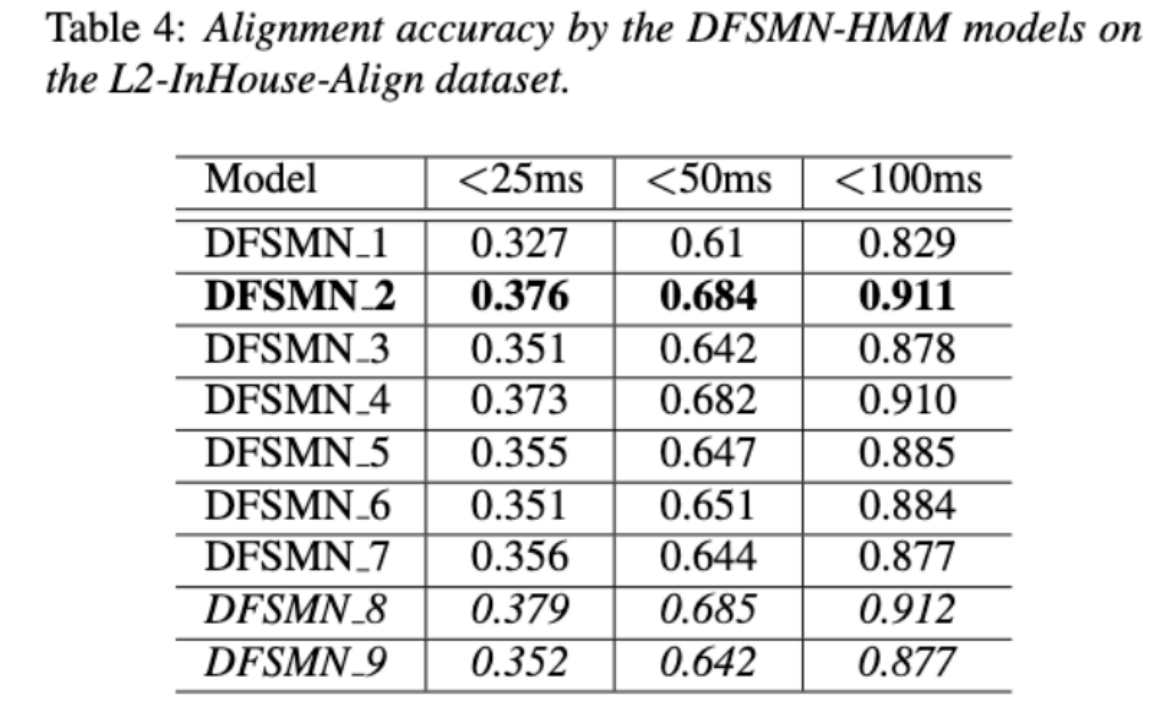
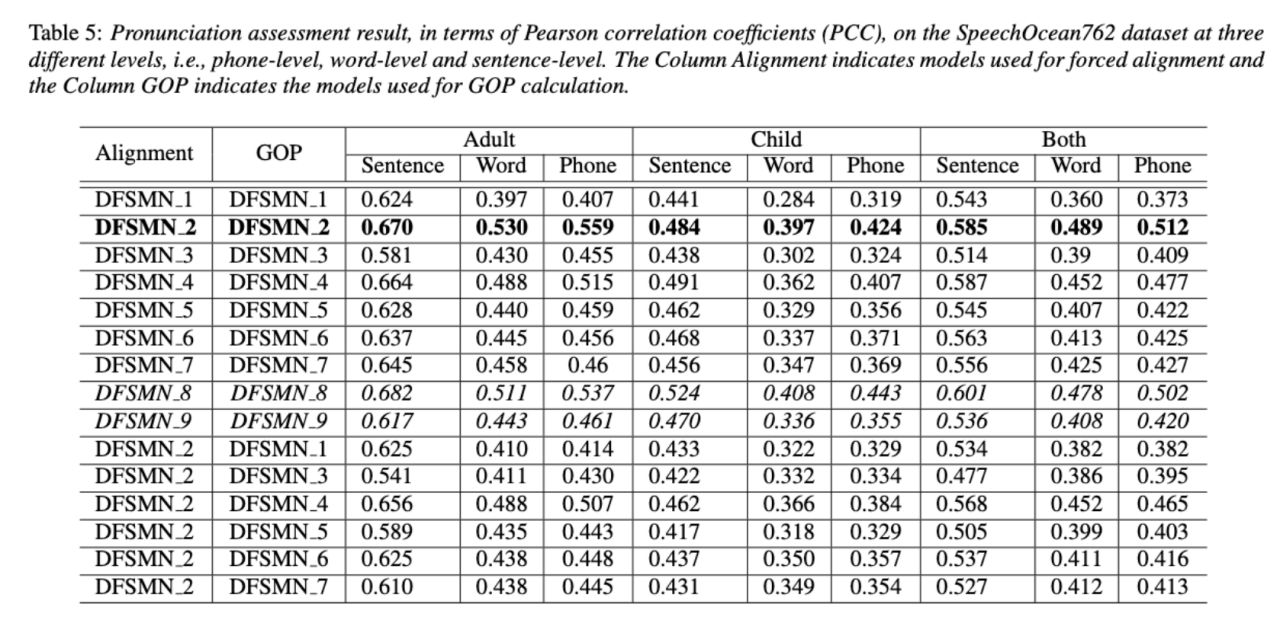
Les deux tableaux ci-dessus montrent respectivement la précision de l'alignement et l'évaluation des différentes combinaisons de performances des modèles acoustiques. . Les résultats expérimentaux montrent que l'utilisation uniquement de données en langue non native avec des séquences de phonèmes annotées manuellement lors de la formation du modèle acoustique permet l'alignement de la parole non native et la plus grande précision dans l'évaluation de la prononciation. Plus précisément, mélanger la moitié des données en langue maternelle et la moitié des données non natives (séquences de phonèmes annotées par l'homme) dans la formation peut être légèrement pire, mais comparable à l'utilisation uniquement de données non natives avec des séquences de phonèmes annotées par l'homme.
De plus, le cas mixte ci-dessus fonctionne mieux lors de l'évaluation de la prononciation sur des données en langue maternelle. Avec des ressources limitées, l'ajout de 10 heures de données en langue non native a considérablement amélioré la précision de l'alignement et les performances d'évaluation, quel que soit le type de transcription de texte utilisé, par rapport à la formation de modèles acoustiques utilisant uniquement des données en langue native. Cette recherche a une importance directrice importante pour les applications de données dans le domaine de l'évaluation de la parole
Dans la reconnaissance vocale de bout en bout, la résolution du problème d'horodatage grâce à un CTCoptimisation du classificateur de trame (Amélioration de la trame). classificateur de niveau pour les timings de mots avec CTC non-peaky dans la reconnaissance vocale automatique de bout en bout)
Les systèmes de bout en bout dans le domaine de la reconnaissance automatique de la parole (ASR) ont démontré des performances comparables aux systèmes hybrides. En tant que sous-produit de l'ASR, les horodatages sont cruciaux dans de nombreuses applications, en particulier dans des scénarios tels que la génération de sous-titres et l'entraînement à la prononciation assisté par ordinateur. Cet article vise à optimiser le classificateur au niveau de la trame dans un système de bout en bout pour obtenir des horodatages. . À cet égard, l’équipe a introduit l’utilisation de la perte CTC (classification temporelle connexionniste) pour entraîner le classificateur au niveau de la trame, et a introduit des informations préalables d’étiquette pour atténuer le phénomène de pointe de CTC. Elle a également combiné la sortie du filtre Mel avec l’ASR. encodeur comme fonctionnalités d’entrée.
Dans des expériences internes chinoises, cette méthode a atteint une précision de 95,68 %/94,18 % pour l'horodatage des mots 200 ms, alors que le système hybride traditionnel n'était que de 93,0 %/90,22 %. De plus, par rapport à l'approche de bout en bout précédente, l'équipe a réalisé une amélioration absolue des performances de 4,80%/8,02% sur les 7 langages internes. La précision du timing des mots est également améliorée grâce à une approche de distillation des connaissances image par image, bien que cette expérience n'ait été menée que pour LibriSpeech.
Les résultats de cette étude démontrent que les performances d'horodatage dans les systèmes de reconnaissance vocale de bout en bout peuvent être efficacement optimisées en introduisant des priorités d'étiquettes et en fusionnant différents niveaux de fonctionnalités. Dans les expériences chinoises internes, cette méthode a réalisé des améliorations significatives par rapport aux systèmes hybrides et aux méthodes de bout en bout précédentes. En outre, la méthode montre également des avantages évidents pour plusieurs langues grâce à l'application de méthodes de distillation des connaissances, elle a encore amélioré le mot ; précision du timing. Ces résultats sont non seulement d'une grande importance pour des applications telles que la génération de sous-titres et l'entraînement à la prononciation, mais fournissent également des pistes d'exploration utiles pour le développement d'une technologie de reconnaissance vocale automatique.
Reconnaissance vocale mixte chinois-anglais basée sur l'apprentissage des limites acoustiques spécifiques à la langue (Apprentissage des limites acoustiques spécifiques à la langue pour la reconnaissance vocale à commutation de code mandarin-anglais )
Contenu réécrit : comme nous le savons tous, le code commutation (L'objectif principal de CS) est de faciliter une communication efficace entre différentes langues ou domaines techniques. CS nécessite l'utilisation de deux ou plusieurs langues alternativement dans une phrase. Cependant, la fusion de mots ou d'expressions de plusieurs langues peut entraîner des erreurs et de la confusion dans la reconnaissance vocale, ce qui rend la reconnaissance vocale à commutation de code (CSSR) plus difficile. missions
Les modèles ASR de bout en bout habituels se composent d'encodeurs, de décodeurs et de mécanismes d'alignement. La plupart des modèles CSASR de bout en bout existants se concentrent uniquement sur l'optimisation des structures d'encodeur et de décodeur, et discutent rarement de la nécessité d'une conception du mécanisme d'alignement liée au langage. La plupart des travaux existants utilisent un mélange de caractères mandarin et de sous-mots anglais comme unités de modélisation pour des scénarios mixtes chinois et anglais. Les caractères mandarin représentent généralement des syllabes uniques en mandarin et ont des limites acoustiques claires ; tandis que les sous-mots anglais sont obtenus sans référence à aucune connaissance acoustique, leurs limites acoustiques peuvent donc être floues. Afin d'obtenir de bonnes limites acoustiques (alignement) entre le mandarin et l'anglais dans le système CSASR, l'apprentissage des limites acoustiques liées à la langue est très nécessaire. Par conséquent, nous avons amélioré le modèle CIF et proposé une méthode d’apprentissage des limites acoustiques différenciées par langue pour la tâche CSASR. Veuillez consulter la figure ci-dessous pour plus de détails sur l'architecture du modèle
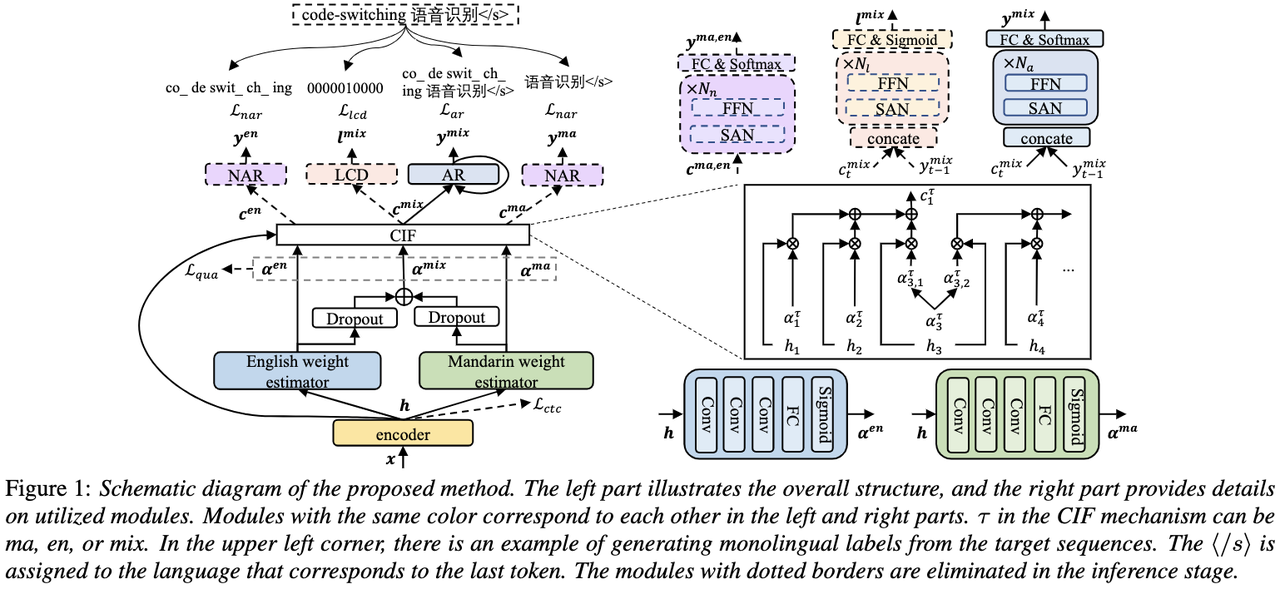
Le modèle se compose de six composants, à savoir l'encodeur, l'estimateur de poids différencié par langue (LSWE), le module CIF, le décodeur autorégressif (AR), la régression non automatique ( NAR) et module de détection de changement de langue (LCD). Le processus de calcul de l'encodeur, du décodeur autorégressif et du CIF est le même que celui de la méthode ASR originale basée sur le CIF. L'estimateur de poids spécifique à la langue est chargé de compléter la modélisation des limites acoustiques indépendantes de la langue. Le décodeur non autorégressif (NAR). et Le module Language Change Detection (LCD) est conçu pour aider à la formation des modèles et n'est plus conservé dans l'étape de décodage. Les résultats expérimentaux montrent que cette méthode a obtenu de nouveaux résultats sur les deux ensembles de tests
et de l'open source chinois-anglais. ensemble de données mixtes SEAME Les effets SOTA sont respectivement de 16,29 % et 22,81 %. Afin de vérifier davantage l'effet de cette méthode sur des volumes de données plus importants, l'équipe a mené des expériences sur un ensemble de données internes de 9 000 heures et a finalement obtenu un gain relatif de MER de 7,9 %. Il est entendu que cet article constitue également le premier travail sur l’apprentissage des limites acoustiques pour la différenciation linguistique dans le cadre de la tâche CSASR. 

: ASR basé sur une représentation unifiée et du texte brut Adaptation de domaine (Adaptation de domaine en texte uniquement utilisant la représentation unifiée de texte vocal dans le transducteur)Comme nous le savons tous, la migration de domaine a toujours été une tâche très importante en ASR, mais l'obtention de données vocales appariées dans le domaine cible prend beaucoup de temps et est coûteuse. Par conséquent, de nombreux travaux utilisent des données textuelles liées au domaine cible pour améliorer l'effet de reconnaissance. Parmi les méthodes traditionnelles, TTS augmentera le cycle de formation et le coût de stockage des données associées, tandis que des méthodes telles que ILME et Shallow fusion augmenteront la complexité de l'inférence.
Sur la base de cette tâche, l'équipe a divisé l'encodeur en encodeur audio et encodeur partagé basé sur RNN-T, et a introduit Text Encoder pour apprendre des représentations similaires aux signaux vocaux ; la représentation de la parole et du texte se fait via une formation encodeur partagé utilisant RNN. La perte -T est appelée USTR (Unified Speech-Text Representation). "Pour la partie Text Encoder, nous avons exploré différents types de formes de représentation, notamment la séquence de caractères, la séquence téléphonique et la séquence de sous-mots. Les résultats finaux ont montré que la séquence téléphonique a le meilleur effet. Quant à la méthode de formation, cet article explore la méthode basée sur la méthode de formation RNN- Multi-step donnée du modèle T et la méthode de formation en une seule étape avec initialisation complètement aléatoire "
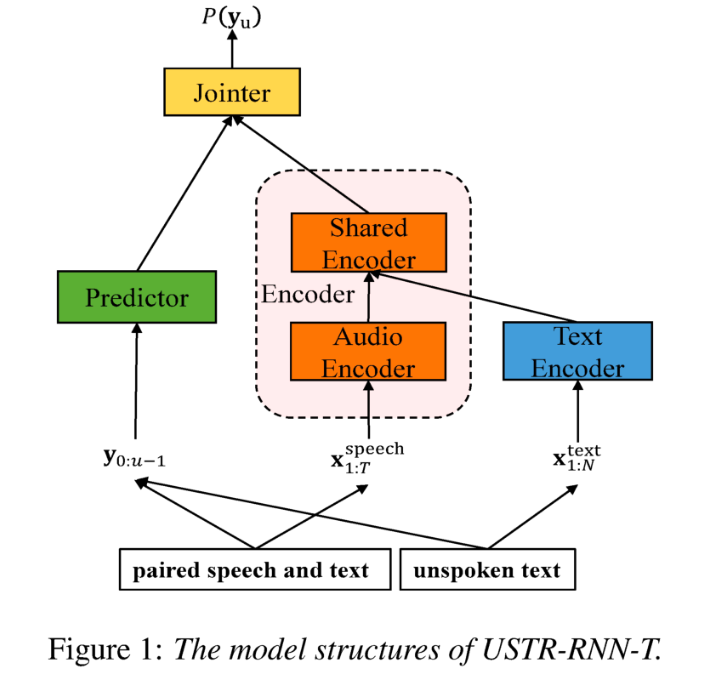 Plus précisément, l'équipe a utilisé l'ensemble de données LibriSpeech comme domaine source et a utilisé le texte annoté. de SPGISpeech en texte brut pour l'expérience de migration de domaine. Les résultats expérimentaux montrent que l'effet de cette méthode dans le champ cible peut être fondamentalement le même que celui du TTS ; l'effet d'entraînement en une seule étape est plus élevé et l'effet est fondamentalement le même que celui en plusieurs étapes ; La méthode USTR peut encore améliorer les performances des modèles de langage de plug-in tels que ILME Combined, même si LM utilise le même corpus de formation de texte. Enfin, sur l'ensemble de tests du domaine cible, sans combiner des modèles de langage externes, cette méthode a permis d'obtenir une diminution relative de 43,7 % par rapport au WER de base de 23,55 % -> 13,25 %.
Plus précisément, l'équipe a utilisé l'ensemble de données LibriSpeech comme domaine source et a utilisé le texte annoté. de SPGISpeech en texte brut pour l'expérience de migration de domaine. Les résultats expérimentaux montrent que l'effet de cette méthode dans le champ cible peut être fondamentalement le même que celui du TTS ; l'effet d'entraînement en une seule étape est plus élevé et l'effet est fondamentalement le même que celui en plusieurs étapes ; La méthode USTR peut encore améliorer les performances des modèles de langage de plug-in tels que ILME Combined, même si LM utilise le même corpus de formation de texte. Enfin, sur l'ensemble de tests du domaine cible, sans combiner des modèles de langage externes, cette méthode a permis d'obtenir une diminution relative de 43,7 % par rapport au WER de base de 23,55 % -> 13,25 %.
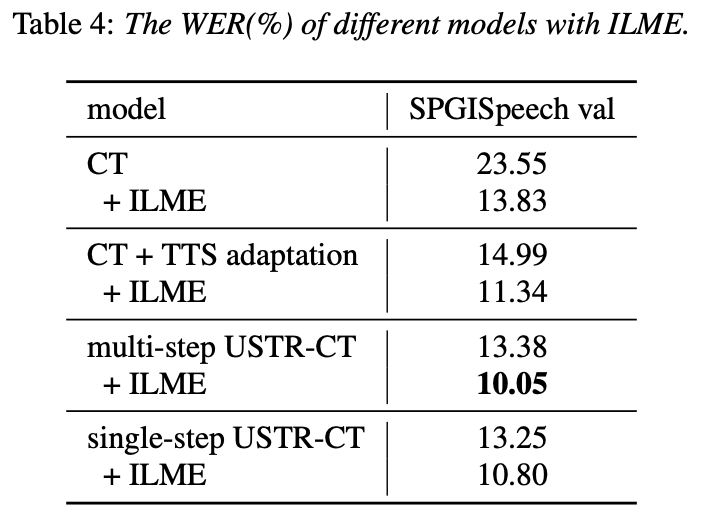
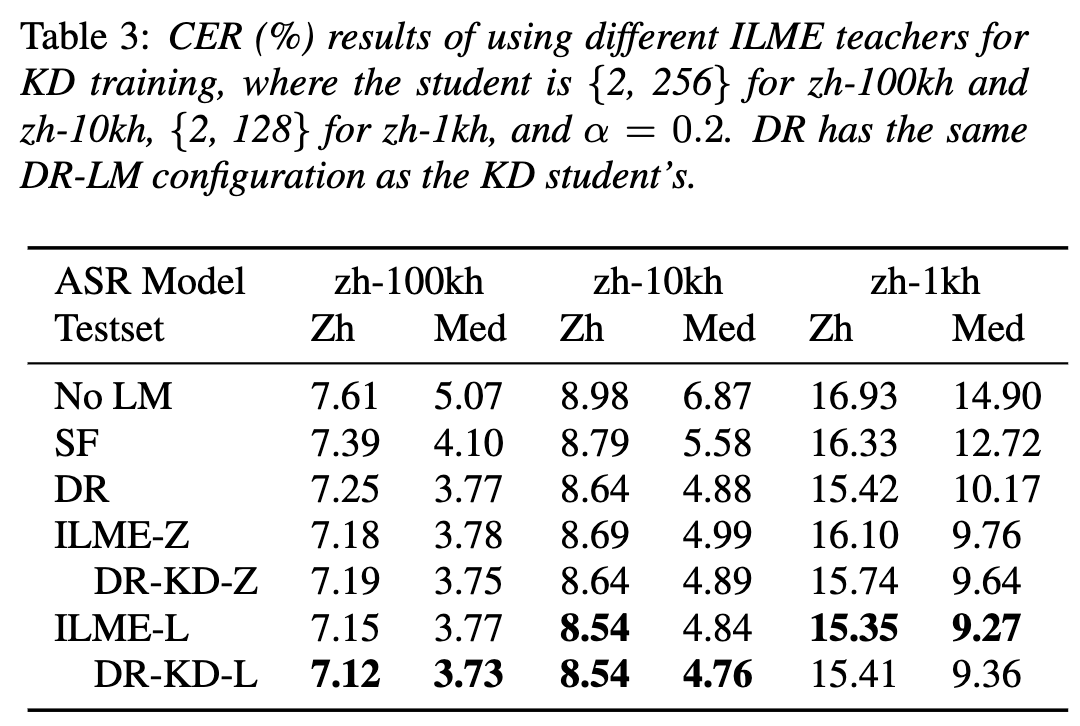
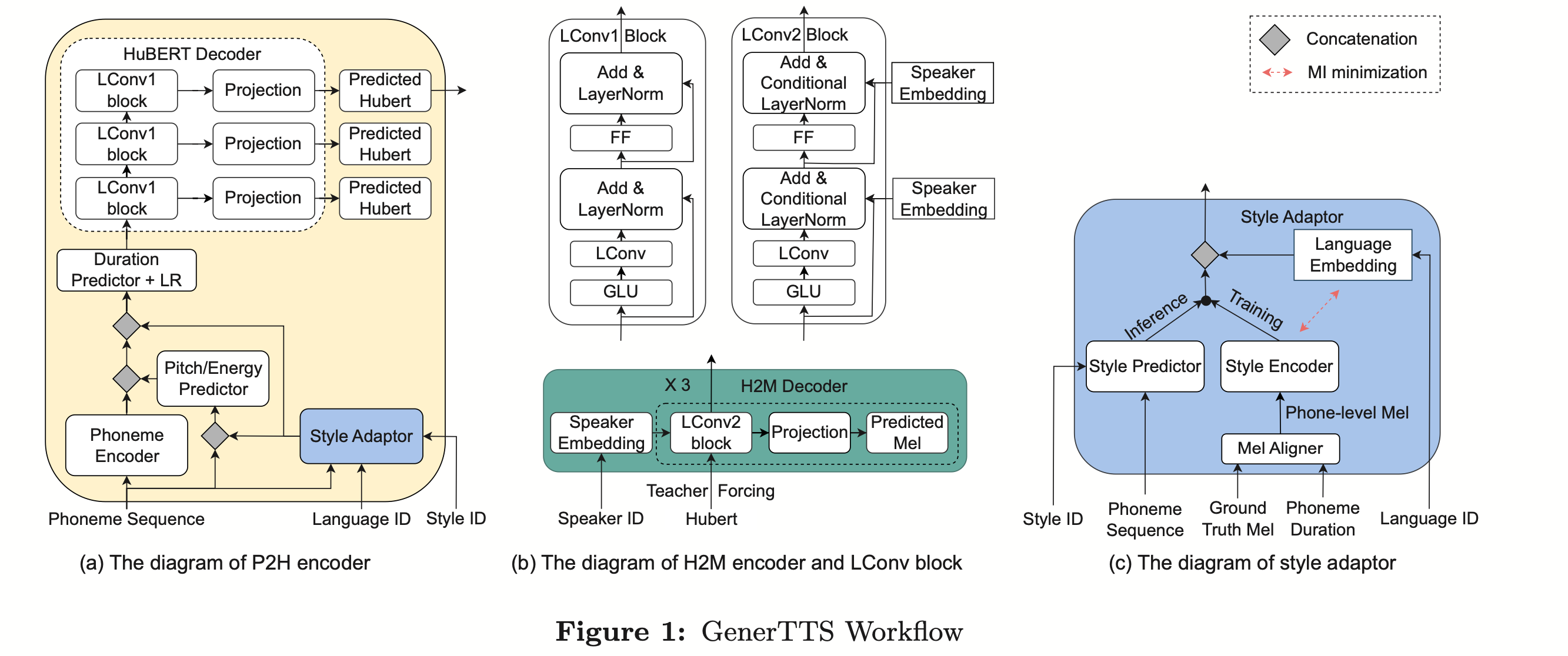
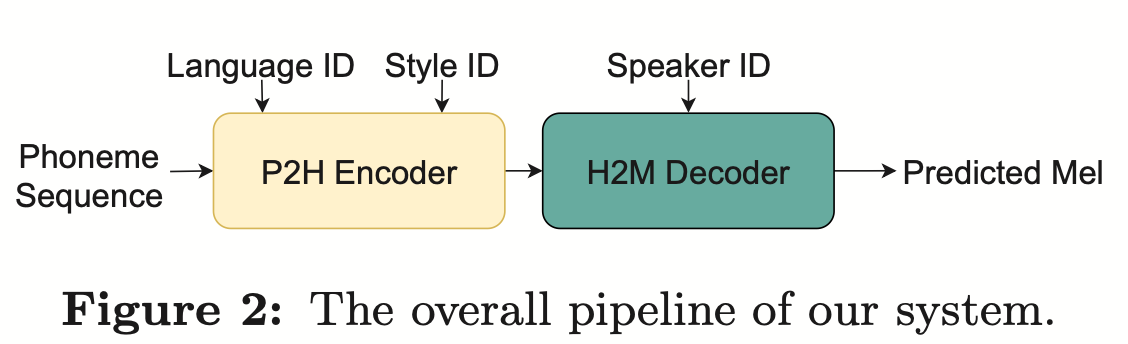
(Approche de distillation des connaissances pour une estimation efficace du modèle de langage interne) Bien que l'estimation du modèle de langage interne (ILME) ait prouvé son efficacité dans la fusion de modèles de langage ASR de bout en bout, par rapport à la fusion peu profonde traditionnelle, ILME introduit en outre le calcul de modèles de langage internes, augmentant ainsi le coût de l'inférence. Afin d'estimer le modèle de langage interne, un calcul direct supplémentaire est requis sur la base du décodeur ASR, ou sur la base de la méthode du rapport de densité, un modèle de langage indépendant (DR-LM) est formé en utilisant le texte de l'ensemble de formation ASR comme langage interne. Rapprochement du modèle. La méthode ILME basée sur le décodeur ASR peut généralement obtenir de meilleures performances que la méthode du rapport de densité car elle utilise directement les paramètres ASR pour l'estimation, mais sa quantité de calcul dépend de la quantité de paramètres du décodeur ASR. L'avantage de la méthode du rapport de densité est ; qu'il peut être contrôlé par La taille de DR-LM permet une estimation efficace du modèle de langage interne. Pour cette raison, l'équipe Volcano Voice a proposé d'utiliser la méthode ILME basée sur le décodeur ASR comme enseignant dans le cadre de la méthode du rapport de densité pour distiller et apprendre DR-LM, réduisant ainsi considérablement le coût de calcul d'ILME tout en maintenant les performances de l'ILME. Les résultats expérimentaux montrent que cette méthode peut réduire 95% des paramètres du modèle de langage interne et est comparable en performances à la méthode ILME basée sur le décodeur ASR. Lorsque la méthode ILME avec de meilleures performances est utilisée en tant qu'enseignant, le modèle d'étudiant correspondant peut également obtenir de meilleurs résultats. Par rapport à la méthode traditionnelle du rapport de densité avec une quantité de calcul similaire, cette méthode offre des performances légèrement meilleures dans les scénarios de migration inter-domaines à faibles ressources, le gain CER peut atteindre 8 % et il est plus robuste. poids de fusion GenerTTS : Démêlage de la prononciation pour la généralisation du timbre et du style dans la synthèse vocale multilingue La synthèse vocale généralisable (TTS) de timbre et de style multilingue vise à synthétiser la parole avec un timbre de référence spécifique ou un style qui n'a pas été formé dans la langue cible. Il est confronté à des défis tels que la difficulté de séparer le timbre et la prononciation, car il est souvent difficile d'obtenir des données vocales multilingues pour un locuteur spécifique. Le style et la prononciation sont mélangés car le style de parole contient à la fois des parties indépendantes et dépendantes de la langue. Pour relever ces défis, l'équipe Volcano Voice a proposé GenerTTS. Ils ont soigneusement conçu les goulots d'étranglement des informations basés sur HuBERT pour découpler le lien entre le timbre et la prononciation/style. Dans le même temps, ils éliminent également les informations spécifiques à la langue dans les styles en minimisant les informations mutuelles entre les styles et les langues 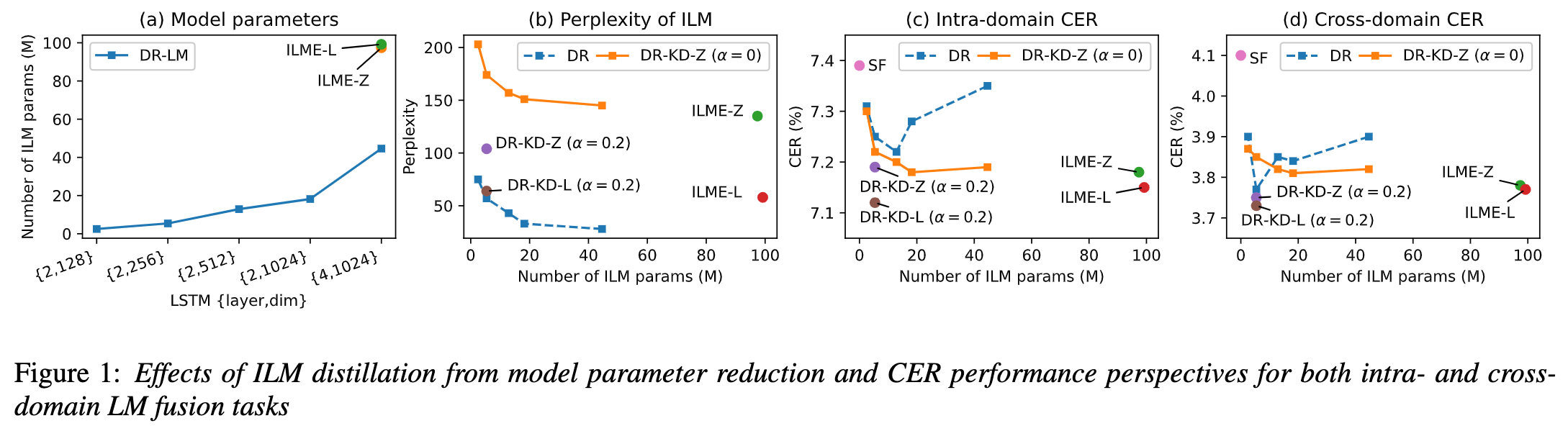
 L'équipe Volcano Voice a toujours fourni des capacités technologiques d'IA vocale de haute qualité et des solutions de produits vocaux complets aux secteurs d'activité internes de ByteDance, et a fourni des services externes via le moteur Volcano. Depuis sa création en 2017, l'équipe s'est concentrée sur la recherche et le développement de technologies vocales intelligentes d'IA de pointe et explore en permanence la combinaison efficace de l'IA et des scénarios commerciaux pour obtenir une plus grande valeur utilisateur.
L'équipe Volcano Voice a toujours fourni des capacités technologiques d'IA vocale de haute qualité et des solutions de produits vocaux complets aux secteurs d'activité internes de ByteDance, et a fourni des services externes via le moteur Volcano. Depuis sa création en 2017, l'équipe s'est concentrée sur la recherche et le développement de technologies vocales intelligentes d'IA de pointe et explore en permanence la combinaison efficace de l'IA et des scénarios commerciaux pour obtenir une plus grande valeur utilisateur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Explication détaillée de la base théorique du réseau neuronal et de la méthode de mise en œuvre de Python
- Explication des connaissances théoriques sur l'optimisation des performances PHP
- Présenté dans la principale publication internationale PNAS ! À partir d'ordinateurs théoriques, les scientifiques ont proposé un modèle de conscience - la « machine de Turing consciente »