
Maison >Périphériques technologiques >IA >Quelle est la source des capacités d'apprentissage contextuel de Transformer ?
Quelle est la source des capacités d'apprentissage contextuel de Transformer ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-09-18 08:01:141491parcourir
Pourquoi le transformateur fonctionne-t-il si bien ? D'où vient la capacité d'apprentissage en contexte qu'elle apporte à de nombreux grands modèles de langage ? Dans le domaine de l’intelligence artificielle, le transformateur est devenu le modèle dominant en matière d’apprentissage profond, mais les bases théoriques de ses excellentes performances n’ont pas été suffisamment étudiées.
Récemment, des chercheurs de Google AI, de l'ETH Zurich et de Google DeepMind ont mené une nouvelle étude pour tenter de découvrir les secrets de certains algorithmes d'optimisation de Google AI. Dans cette étude, ils ont procédé à une ingénierie inverse du transformateur et trouvé des méthodes d'optimisation. Cet article s'intitule « Révéler l'algorithme d'optimisation Mesa dans Transformer » algorithme d'optimisation auxiliaire basé sur le gradient qui s'exécute dans la passe avant du transformateur. Ce phénomène a récemment été appelé « mésa-optimisation ». En outre, les chercheurs ont découvert que l’algorithme d’optimisation mesa résultant présentait des capacités d’apprentissage contextuel à petite échelle, indépendamment de la taille du modèle. Les nouveaux résultats complètent donc les principes d’apprentissage à petite échelle qui ont émergé précédemment dans les grands modèles de langage.
 Les chercheurs estiment que le succès de Transformers repose sur le biais architectural de l'algorithme d'optimisation Mesa qu'il implémente dans la passe avant : (i) définir des objectifs d'apprentissage internes, et (ii) les optimiser
Les chercheurs estiment que le succès de Transformers repose sur le biais architectural de l'algorithme d'optimisation Mesa qu'il implémente dans la passe avant : (i) définir des objectifs d'apprentissage internes, et (ii) les optimiser
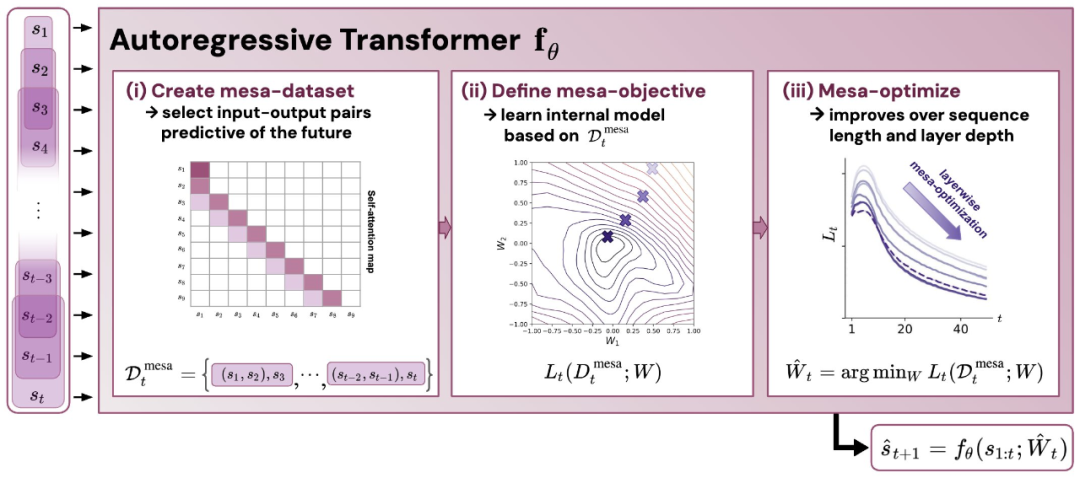
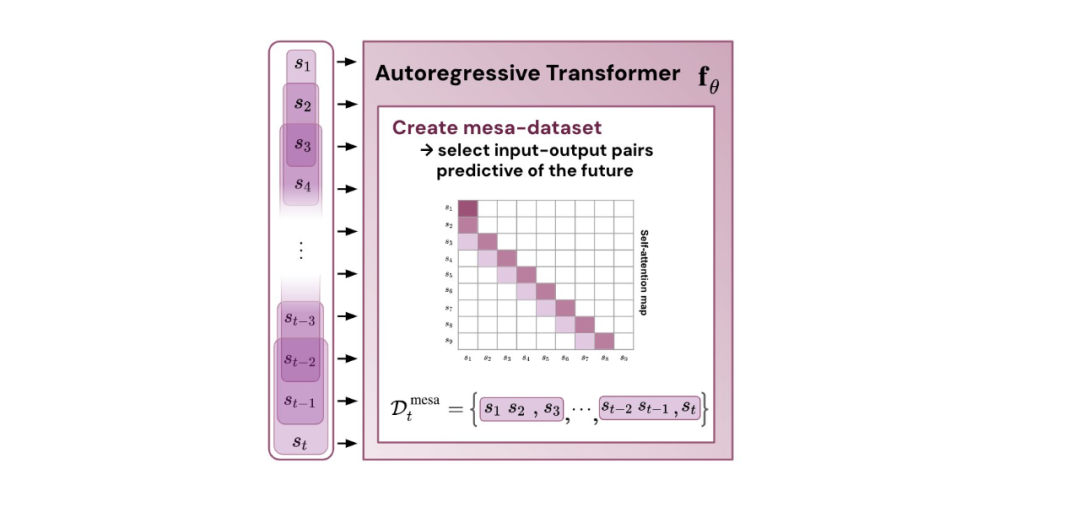
Figure 1 : Illustration de la nouvelle hypothèse : l'optimisation des poids θ du transformateur autorégressif fθ aboutit à un algorithme d'optimisation mesa implémenté dans la propagation vers l'avant du modèle. En tant que séquence d'entrée s_1, . . , s_t est traité au pas de temps t, Transformer (i) crée un ensemble d'entraînement interne composé de paires d'associations entrée-cible, (ii) définit une fonction objectif interne via l'ensemble de données de résultat, qui est utilisé pour mesurer les performances du modèle interne en utilisant les poids W, (iii) Optimiser cet objectif et utiliser le modèle appris pour générer des prédictions futures.
Les contributions de cette étude sont les suivantes :
Généralise la théorie de von Oswald et al et montre comment les Transformers peuvent théoriquement optimiser les objectifs construits en interne à partir de la régression en utilisant des méthodes basées sur le gradient. Prédire l'élément suivant du séquence. 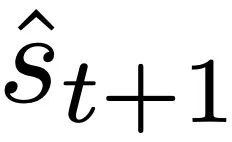
Semblable au LLM, les expériences montrent que de simples modèles de formation autorégressive peuvent également devenir des apprenants contextuels, et les ajustements à la volée sont cruciaux pour améliorer l'apprentissage contextuel du LLM et peuvent également améliorer les performances dans des environnements spécifiques.
- Inspiré par la découverte selon laquelle les couches d'attention tentent d'optimiser implicitement la fonction objectif interne, l'auteur présente la couche mesa, un nouveau type de couche d'attention qui peut résoudre efficacement le problème d'optimisation des moindres carrés au lieu de simplement prendre une seule étape de gradient. pour atteindre l’optimalité. Les expériences démontrent qu'une seule couche mesa surpasse les transformateurs d'auto-attention linéaires profonds et softmax sur des tâches séquentielles simples tout en offrant plus d'interprétabilité.
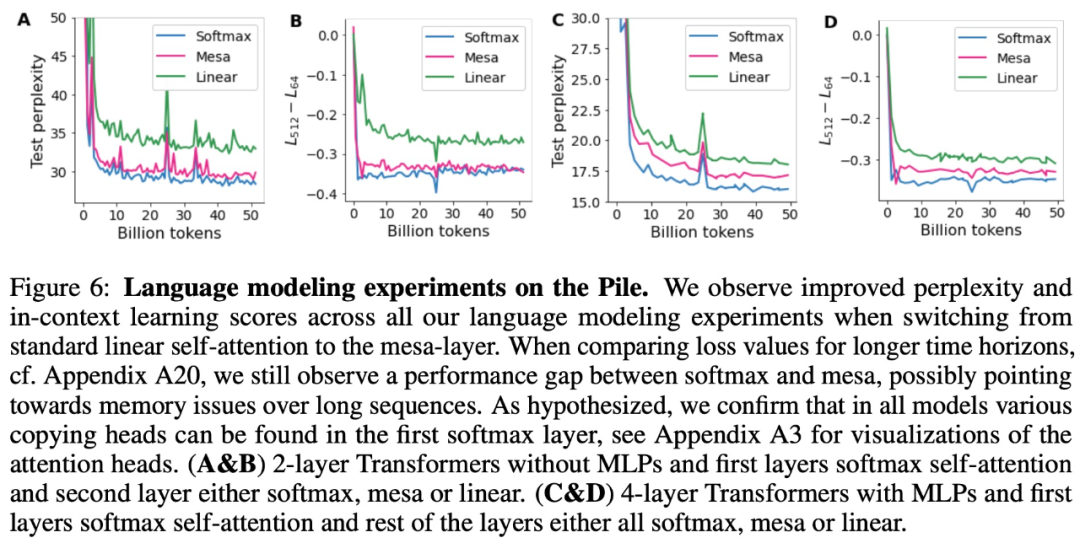
- Après des expériences préliminaires de modélisation du langage, il a été constaté que le remplacement de la couche d'auto-attention standard par la couche mesa a donné des résultats prometteurs, prouvant que cette couche possède de fortes capacités d'apprentissage contextuel.

- Tout d'abord, analysez le Transformateur entraîné sur une dynamique linéaire simple. Dans ce cas, chaque séquence est générée par un W* différent pour éviter la mémorisation de séquences croisées. Dans cette configuration simple, les chercheurs montrent comment Transformer crée un ensemble de données mesa et utilise le GD prétraité pour optimiser l'objectif mesa
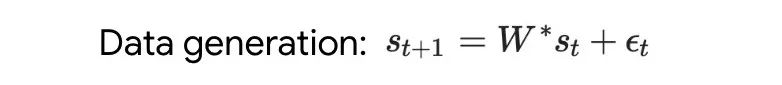
Le contenu réécrit est le suivant : nous pouvons agréger la structure de jetons des éléments de séquence adjacents en entraînant un transformateur profond. Fait intéressant, cette méthode de prétraitement simple aboutit à une matrice de poids très clairsemée (moins de 1 % des poids sont non nuls), ce qui donne lieu à un algorithme d'ingénierie inverse
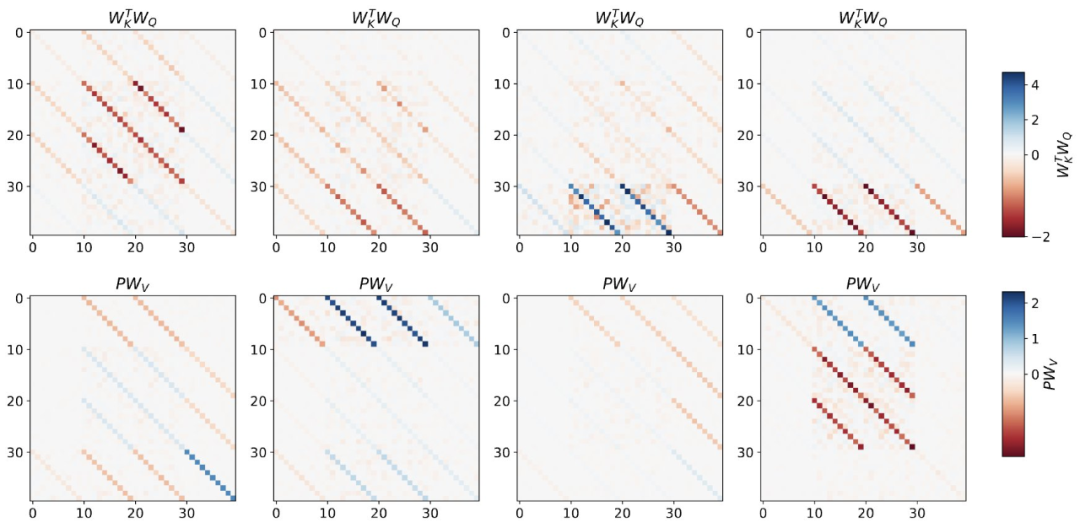
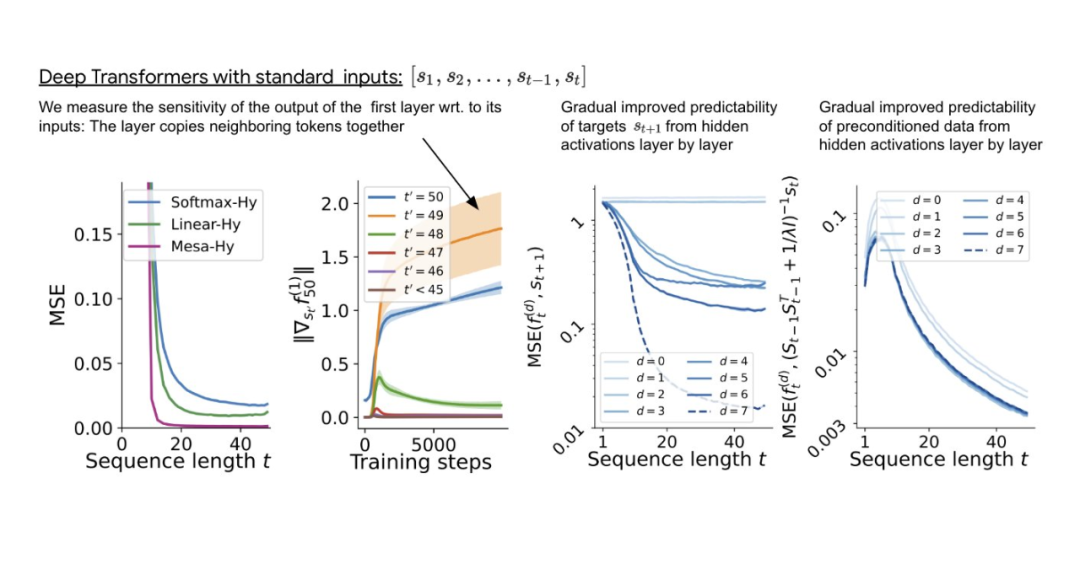
Pour une seule couche d'auto-attention linéaire, le poids Correspond à un pas de descente de gradient. Pour les Transformers profonds, l’interprétabilité devient difficile. L'étude s'appuie sur des sondages linéaires et examine si les activations cachées sont capables de prédire des cibles autorégressives ou des entrées prétraitées.
Fait intéressant, la prévisibilité des deux méthodes de sondage s'améliore progressivement avec l'augmentation de la profondeur du réseau. Cette découverte suggère que le GD prétraité est caché dans le modèle.
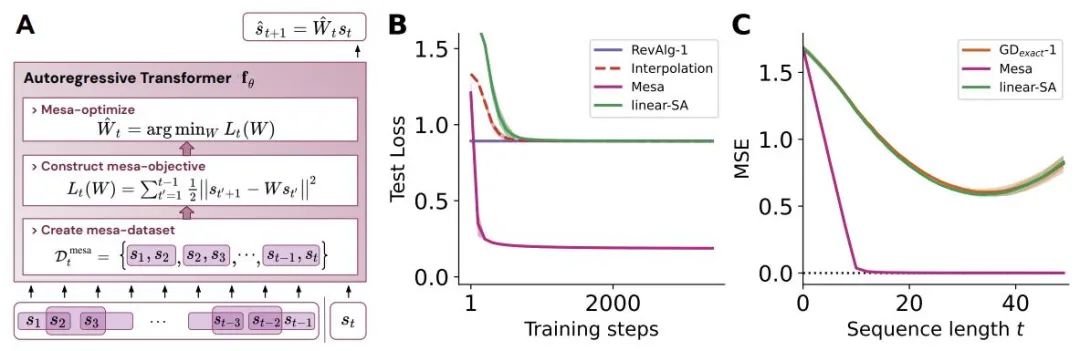
Figure 2 : Ingénierie inverse d'une couche d'auto-attention linéaire entraînée.
L'étude a révélé que la couche d'entraînement peut être parfaitement ajustée lors de l'utilisation de tous les degrés de liberté dans la construction, y compris non seulement le taux d'apprentissage appris η, mais également un ensemble de poids initiaux appris W_0. Il est important de noter que, comme le montre la figure 2, l’algorithme en une étape appris fonctionne toujours bien mieux qu’une seule couche mesa.
Avec un simple réglage du poids, nous pouvons remarquer qu'il est facile de trouver grâce à une optimisation de base que cette couche peut résoudre de manière optimale cette tâche de recherche. Ce résultat prouve que le biais inductif de codage en dur est bénéfique pour l'optimisation mesa
Avec des informations théoriques sur le cas multicouche, analysez d'abord Deep Linear et Softmax et faites attention uniquement à Transformer. Les auteurs formatent l'entrée selon une structure à 4 canaux,
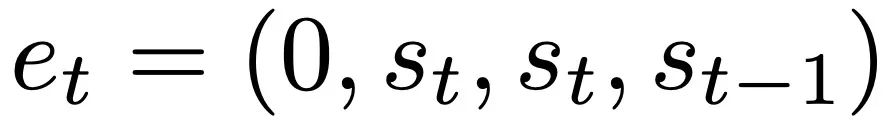 , qui correspond au choix de W_0 = 0.
, qui correspond au choix de W_0 = 0. Comme pour le modèle monocouche, les auteurs voient une structure claire dans les poids du modèle entraîné. Dans le cadre d'une première analyse d'ingénierie inverse, cette étude exploite cette structure et construit un algorithme (RevAlg-d, où d représente le nombre de couches) contenant 16 paramètres par en-tête de couche (au lieu de 3200). Les auteurs ont découvert que cette expression compressée mais complexe peut décrire le modèle entraîné. En particulier, il permet l'interpolation entre les poids Transformer réels et RevAlg-d d'une manière presque sans perte
Bien que l'expression RevAlg-d explique un Transformer multicouche entraîné avec un petit nombre de paramètres libres, il est difficile de le comprendre. L'explication est l'algorithme d'optimisation mesa. Par conséquent, les auteurs ont utilisé une analyse par sondage par régression linéaire (Alain et Bengio, 2017 ; Akyürek et al., 2023) pour trouver les caractéristiques de l’algorithme d’optimisation mesa hypothétique.
Sur le transformateur d'auto-attention linéaire profond illustré à la figure 3, nous pouvons observer que les deux sondes sont capables de décoder linéairement, et à mesure que la longueur de la séquence et la profondeur du réseau augmentent, les performances de décodage augmentent également. Par conséquent, nous avons découvert un algorithme d’optimisation de base qui descend couche par couche sur la base de l’objectif mésa original Lt (W) tout en améliorant le numéro de condition du problème d’optimisation mesa. Cela se traduit par une diminution rapide du Lt (W) du mésa-objectif. De plus, nous pouvons également observer que les performances s'améliorent considérablement à mesure que la profondeur augmente
Avec un meilleur prétraitement des données, la fonction objectif autorégressive Lt (W) peut être optimisée par étapes (sur plusieurs couches), de sorte qu'un déclin rapide peut être envisagé Ceci est réalisé grâce à cette optimisation
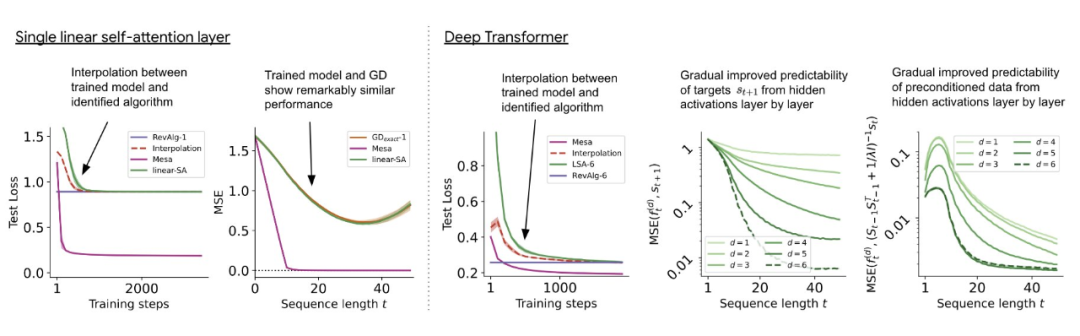
Figure 3 : Formation de transformateur multicouche pour l'ingénierie inverse de l'entrée de jeton construite.
Cela montre que si le transformateur est formé sur le jeton construit, il prédira avec l'optimisation mesa. Fait intéressant, lorsque des éléments de séquence sont donnés directement, le transformateur construira lui-même le jeton en regroupant les éléments, ce que l'équipe de recherche appelle « créer l'ensemble de données mesa ».
Conclusion
La découverte de cette étude est que des algorithmes d'inférence basés sur le gradient peuvent être développés lorsqu'ils sont formés à l'aide du modèle Transformer pour des tâches de prédiction de séquence sous des objectifs autorégressifs standard. Par conséquent, les derniers résultats du multitâche et du méta-apprentissage peuvent également être appliqués aux paramètres de formation LLM auto-supervisés traditionnels
De plus, l'étude a également révélé que l'algorithme d'inférence autorégressive appris peut être réajusté sans qu'il soit nécessaire de se recycler. pour résoudre des tâches d'apprentissage contextuel supervisé et ainsi interpréter les résultats dans un cadre unifié
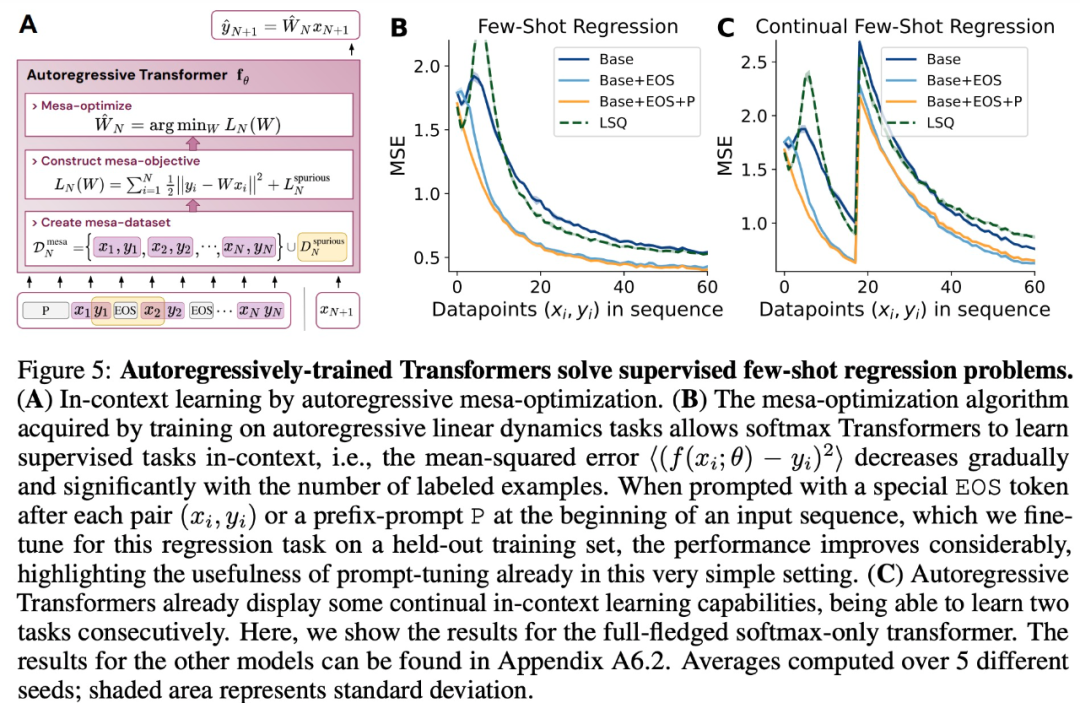
Alors, quel est le rapport avec l'apprentissage contextuel ? Selon l'étude, après avoir entraîné le modèle de transformateur sur la tâche de séquence autorégressive, il obtient une optimisation mesa appropriée et peut donc effectuer un apprentissage contextuel en quelques coups sans aucun réglage fin
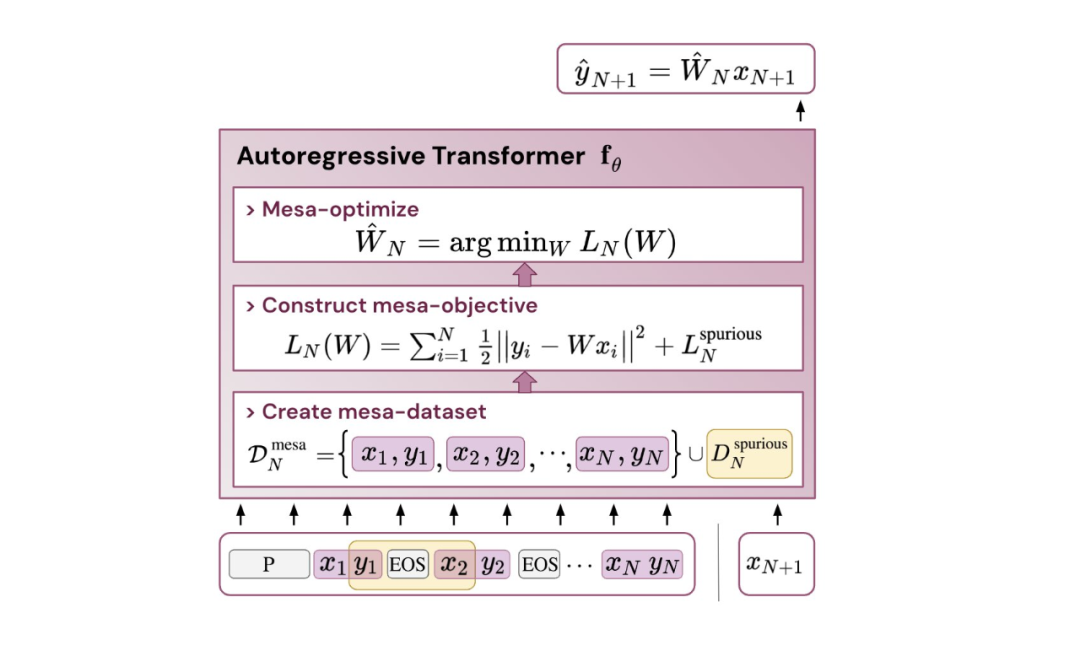
L'étude suppose que LLM existe également optimisation mesa, améliorant ainsi ses capacités d'apprentissage contextuel. Il est intéressant de noter que l’étude a également observé qu’une adaptation efficace des invites pour le LLM peut également conduire à des améliorations substantielles des capacités d’apprentissage contextuel.
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les applications de l'intelligence artificielle en médecine ?
- Décrivez brièvement quelle est l'unité de stockage des données dans un ordinateur ?
- Quelles sont les principales directions d'application de l'intelligence artificielle dans le domaine médical ?
- Quelles sont les caractéristiques de base des données
- Quelle est la relation entre l'intelligence artificielle, l'apprentissage automatique et l'apprentissage profond ?