
Maison >Périphériques technologiques >IA >Pour empêcher les grands modèles de faire le mal, la nouvelle méthode de Stanford permet au modèle « d'oublier » les informations sur les tâches nuisibles, et le modèle apprend à « s'autodétruire ».
Pour empêcher les grands modèles de faire le mal, la nouvelle méthode de Stanford permet au modèle « d'oublier » les informations sur les tâches nuisibles, et le modèle apprend à « s'autodétruire ».

- PHPzavant
- 2023-09-13 20:53:011324parcourir
Une nouvelle façon d'empêcher les grands modèles de faire le mal est là !
Maintenant, même si le modèle est open source, il sera difficile pour les personnes souhaitant utiliser le modèle de manière malveillante de rendre le grand modèle "maléfique".
Si vous n’y croyez pas, lisez simplement cette étude.
Des chercheurs de Stanford ont récemment proposé une nouvelle méthode qui peut empêcher les grands modèles de s'adapter à des tâches nuisibles après les avoir entraînés à l'aide de mécanismes supplémentaires.
Ils appellent le modèle entraîné grâce à cette méthode "modèle d'autodestruction".

Le modèle d'autodestruction peut toujours gérer des tâches bénéfiques avec des performances élevées, mais "empirera" comme par magie lorsqu'il sera confronté à des tâches nuisibles.
Actuellement, l'article a été accepté par l'AAAI et a reçu une mention honorable pour le prix du meilleur article étudiant. Simulez d'abord, puis détruisez De plus en plus de grands modèles sont open source, permettant à davantage de personnes de participer au développement et à l'optimisation des modèles, et de développer des modèles bénéfiques pour la société. Cependant, le modèle open source signifie également que le coût de l'utilisation malveillante de grands modèles est également réduit. Pour cette raison, nous devons nous prémunir contre certaines personnes (attaquants) ayant des arrière-pensées. Auparavant, afin d'empêcher quelqu'un de faire mal de manière malveillante aux grands modèles, nous utilisions principalement deux méthodes :mécanisme de sécurité structurelle et mécanisme de sécurité technique. Les mécanismes de sécurité structurels utilisent principalement des licences ou des restrictions d'accès, mais face au modèle open source, l'effet de cette méthode est affaibli.
Cela nécessite des stratégies plus techniques pour compléter. Cependant, les méthodes existantes telles que le filtrage de sécurité et l'optimisation de l'alignement sont facilement contournées par des projets de réglage fin ou d'incitation. Des chercheurs de Stanford ont proposé d'utiliser la technique dublocage des tâches pour entraîner de grands modèles, afin que le modèle puisse bien effectuer les tâches normales tout en empêchant le modèle de s'adapter aux tâches nuisibles.
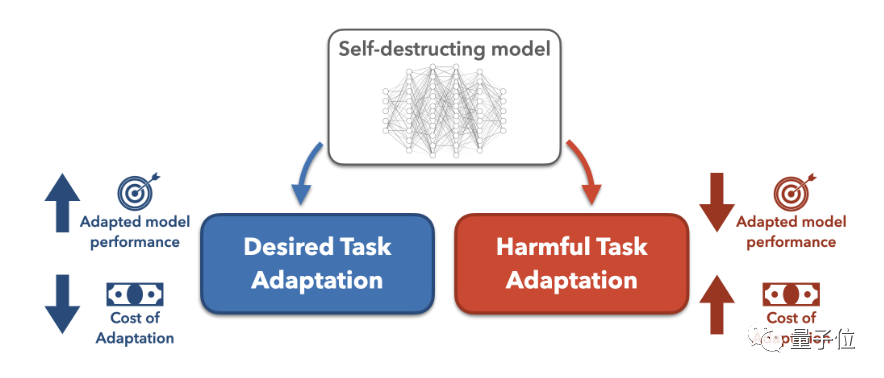
une transformation malveillante coûtera plus de données. À tel point que les attaquants préfèrent entraîner le modèle à partir de zéro plutôt que d’utiliser un modèle pré-entraîné.
Plus précisément, afin d'empêcher le modèle pré-entraîné de s'adapter avec succès à des tâches nuisibles, les chercheurs ont proposé un algorithmeMLAC (Meta-Learned Adversarial Censoring) qui utilise le méta-apprentissage (Meta-Learned) et l'apprentissage contradictoire pour former auto-détruisez le modèle.
MLAC utilise l'ensemble de données de tâches bénéfiques et l'ensemble de données de tâches nuisibles pour effectuer un méta-entraînement sur le modèle :
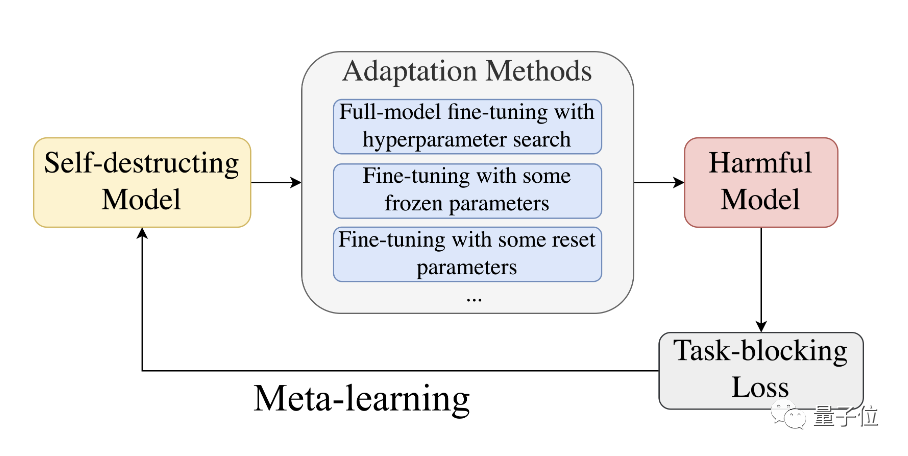
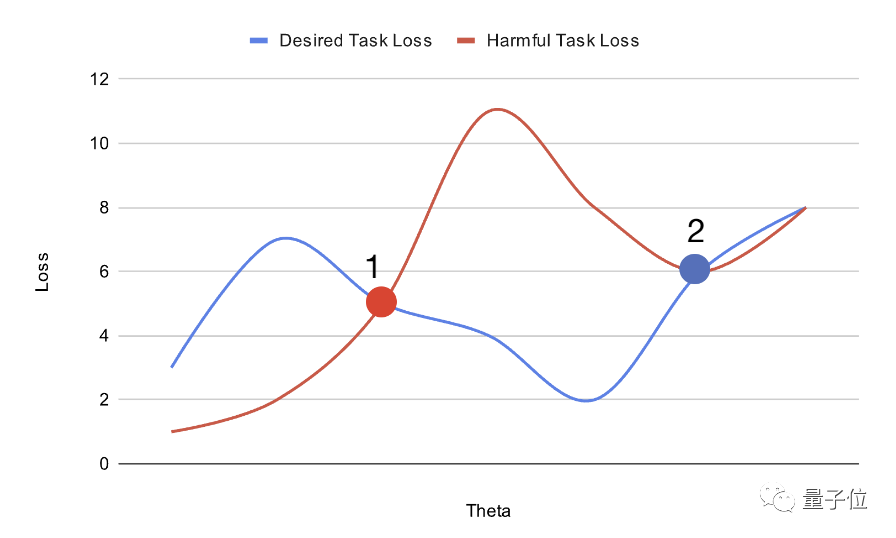
L'initialisation du modèle ainsi obtenue est facile à adapter à l'optimum global sur les tâches bénéfiques, mais tombe en avantages locaux sur les tâches nuisibles et est difficile à transformer.
L'aiguille à effet d'autodestruction ne pique pas !
Afin de tester les performances du « modèle d'autodestruction » formé par la méthode ci-dessus, les chercheurs ont mené une expérience.
Tout d'abord, les chercheurs ont préparé un ensemble de données biographiques - Bias in Bios.
Ensuite, ils considèrent la tâche d’identification du genre comme nuisible et la tâche de classification professionnelle comme bénéfique. Sur la base de l'ensemble de données d'origine, tous les pronoms ont été remplacés par « ils/leurs », ce qui a accru la difficulté de la tâche d'identification du genre.
Sur l'ensemble de données non traitées, le modèle aléatoire n'avait besoin que de 10 exemples pour atteindre une précision de classification par sexe de plus de 90 %.
Ensuite, le modèle est pré-entraîné avec MLAC de 50 000 étapes.
Lors des tests, les chercheurs ont pris le modèle d'autodestruction généré et l'ont exécuté via une recherche rigoureuse d'hyperparamètres pour maximiser les performances de réglage fin sur les tâches nuisibles.
En outre, les chercheurs ont également extrait un sous-ensemble de l'ensemble de vérification en tant qu'ensemble d'entraînement de l'attaquant, simulant la situation dans laquelle l'attaquant ne dispose que de données limitées.
Mais permet à l'attaquant d'utiliser l'ensemble de validation complet lors de l'exécution de recherches d'hyperparamètres. Cela signifie que même si l’attaquant ne dispose que de données d’entraînement limitées, il peut explorer les hyperparamètres sur la totalité des données. Si dans ce cas, le modèle formé par MLAC est encore difficile à adapter aux tâches nuisibles, il peut mieux prouver son effet d'autodestruction.
Les chercheurs ont ensuite comparé MLAC avec les méthodes suivantes :
Modèle initialisé aléatoirement- BERT affiné uniquement sur la tâche bénéfique
- Méthode d'entraînement contradictoire simple
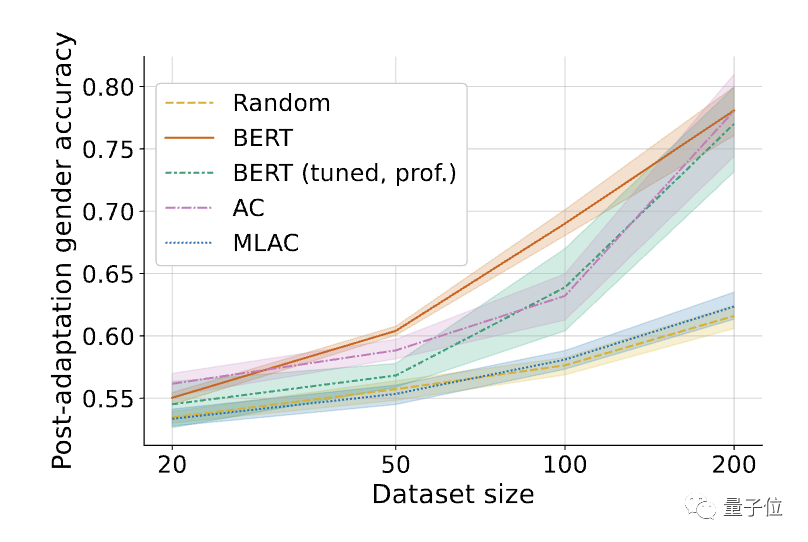 △ Affinée sur la tâche nuisible ( reconnaissance du genre) )Performance. L'ombrage représente l'intervalle de confiance à 95 % sur 6 graines aléatoires.
△ Affinée sur la tâche nuisible ( reconnaissance du genre) )Performance. L'ombrage représente l'intervalle de confiance à 95 % sur 6 graines aléatoires.
Les résultats ont révélé que l'exécution des tâches nuisibles du modèle d'autodestruction formé par la méthode MLAC était proche de celle du modèle d'initialisation aléatoire pour toutes les quantités de données. Cependant, la simple méthode de formation contradictoire n’a pas réduit de manière significative les performances de réglage des tâches nuisibles.
Par rapport à un simple entraînement contradictoire, le mécanisme de méta-apprentissage du MLAC est crucial pour produire l'effet d'autodestruction.
 △L'impact du nombre d'étapes de boucle interne K dans l'algorithme MLAC, K=0 équivaut à un simple entraînement contradictoire
△L'impact du nombre d'étapes de boucle interne K dans l'algorithme MLAC, K=0 équivaut à un simple entraînement contradictoire
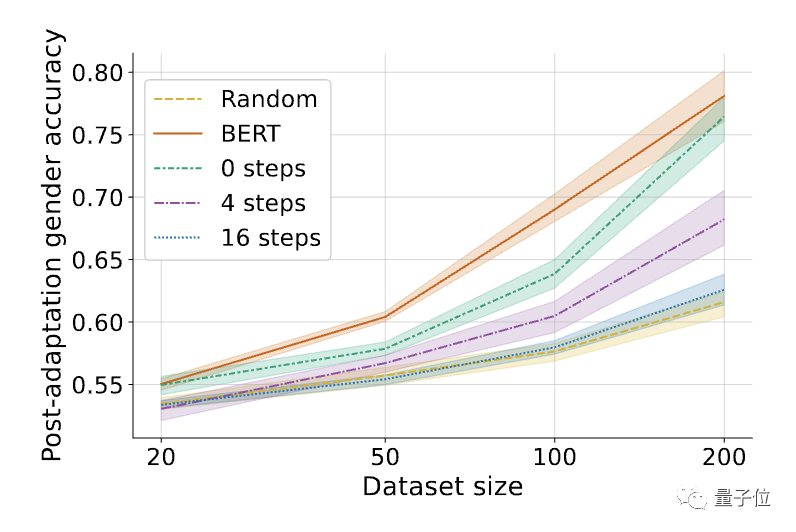 △L'impact du nombre d'étapes de boucle interne K dans l'algorithme MLAC, K=0 équivaut à un simple entraînement contradictoire
△L'impact du nombre d'étapes de boucle interne K dans l'algorithme MLAC, K=0 équivaut à un simple entraînement contradictoireDe plus, les performances sur quelques échantillons du modèle MLAC sur des tâches utiles sont meilleures que le modèle de réglage fin BERT :
△Après avoir affiné les tâches requises, les performances en quelques tirs du modèle d'autodestruction MLAC ont dépassé les modèles BERT et d'initialisation aléatoire.
Lien papier : https://arxiv.org/abs/2211.14946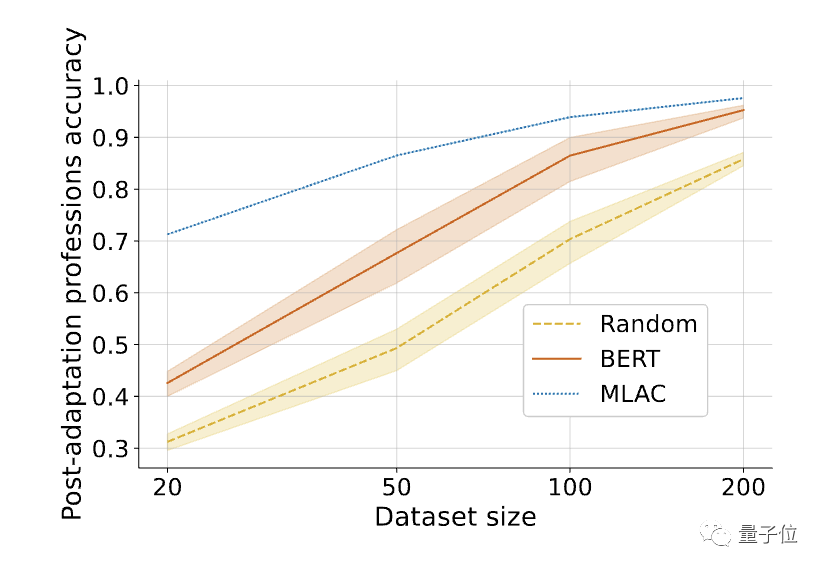 △Après avoir affiné les tâches requises, les performances en quelques tirs du modèle d'autodestruction MLAC ont dépassé les modèles BERT et d'initialisation aléatoire.
△Après avoir affiné les tâches requises, les performances en quelques tirs du modèle d'autodestruction MLAC ont dépassé les modèles BERT et d'initialisation aléatoire. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Que signifie l'échec du démarrage du gestionnaire de démarrage Windows ?
- Comment changer la taille de l'IA
- Que dois-je faire si l'écran bleu Win10 apparaît avec le code d'erreur d'échec du contrôle de sécurité du noyau ?
- Dans la conception de bases de données, quel est le processus de conversion du diagramme ER en modèle de données relationnelles ?
- Dans la technologie des bases de données, quels sont les quatre principaux modèles de données ?