
Maison >Périphériques technologiques >IA >Interspeech 2023 | Volcano Engine Technologie audio de streaming Amélioration de la parole et codage audio IA
Interspeech 2023 | Volcano Engine Technologie audio de streaming Amélioration de la parole et codage audio IA

- 王林avant
- 2023-09-11 12:57:02925parcourir

Introduction au contexte
Afin de faire face à divers scénarios de communication audio et vidéo complexes, tels que les scénarios multi-appareils, multi-personnes et multi-bruit, la technologie de communication multimédia en streaming est progressivement devenue une technologie indispensable dans la vie des gens. . Afin d'obtenir une meilleure expérience subjective et de permettre aux utilisateurs d'entendre clairement et véritablement, la solution technologique de streaming audio combine des solutions traditionnelles d'apprentissage automatique et d'amélioration de la voix basées sur l'IA, en utilisant des solutions technologiques de réseau neuronal profond pour obtenir une réduction du bruit vocal et une annulation de l'écho. élimination des interférences vocales et codage et décodage audio, etc., pour protéger la qualité audio dans la communication en temps réel.
En tant que conférence internationale phare dans le domaine de la recherche sur le traitement du signal vocal, Interspeech a toujours représenté la direction de recherche la plus avant-gardiste dans le domaine de l'acoustique. Interspeech 2023 comprend un certain nombre d'articles liés aux algorithmes d'amélioration de la parole du signal audio, parmi lesquels. , Volcano Engine Streaming Audio Au total, 4 articles de recherche de l'équipe ont été acceptés par la conférence, notamment l'amélioration de la parole, l'encodage et le décodage basés sur l'IA, l'annulation de l'écho et l'amélioration adaptative non supervisée de la parole.
Il convient de mentionner que dans le domaine de l'amélioration adaptative de la parole non supervisée, l'équipe conjointe de ByteDance et de NPU a complété avec succès la sous-tâche d'amélioration adaptative de la parole de conversation dans le domaine non supervisé (domaine non supervisé) du CHiME (Computational Hearing in Multisource Environments) de cette année. Le défi d'adaptation pour l'amélioration de la parole conversationnelle (UDASE) a remporté le championnat (https://www.chimechallenge.org/current/task2/results). Le CHiME Challenge est un important concours international lancé en 2011 par des instituts de recherche de renom tels que l'Institut français d'informatique et d'automatisation, l'Université de Sheffield au Royaume-Uni et le laboratoire de recherche Mitsubishi Electronics aux États-Unis. relever des problèmes à distance dans le domaine de la recherche sur la parole. Cette année, il a lieu pour la septième fois. Les équipes participantes aux précédents concours CHiME comprennent l'Université de Cambridge au Royaume-Uni, l'Université Carnegie Mellon aux États-Unis, l'Université Johns Hopkins, NTT au Japon, Hitachi Academia Sinica et d'autres universités et instituts de recherche de renommée internationale, ainsi que l'Université Tsinghua, Université de l'Académie chinoise des sciences, Institut d'acoustique de l'Académie chinoise des sciences, NPU, iFlytek et d'autres grandes universités et instituts de recherche nationaux.
Cet article présentera les principaux problèmes de scénario et les solutions techniques résolus par ces 4 articles, partager la réflexion et la pratique de l'équipe audio en streaming de Volcano Engine dans le domaine de l'amélioration de la parole, basée sur l'encodeur IA, l'annulation d'écho et la parole adaptative non supervisée. renforcement.
Méthode légère d'amélioration des harmoniques de la parole basée sur un filtre en peigne apprenable
Adresse papier : https://www.isca-speech.org/archive/interspeech_2023/le23_interspeech.html
Contexte
Restricted En raison de la latence et des ressources informatiques, L'amélioration de la parole dans les scénarios de communication audio et vidéo en temps réel utilise généralement des fonctionnalités d'entrée basées sur des banques de filtres. Grâce à des banques de filtres telles que Mel et ERB, le spectre original est compressé en sous-bandes de dimension inférieure. Dans le domaine des sous-bandes, le résultat du modèle d'amélioration de la parole basé sur l'apprentissage profond est le gain de parole de la sous-bande, qui représente la proportion de l'énergie vocale cible. Cependant, l'audio amélioré sur le domaine de sous-bande compressé est flou en raison de la perte de détails spectraux, nécessitant souvent un post-traitement pour améliorer les harmoniques. RNNoise et PercepNet utilisent des filtres en peigne pour améliorer les harmoniques, mais en raison de l'estimation de la fréquence fondamentale, du calcul du gain du filtre en peigne et du découplage du modèle, ils ne peuvent pas être optimisés de bout en bout ; DeepFilterNet utilise un filtre de domaine temps-fréquence pour supprimer le bruit inter-harmonique. mais n'utilise pas explicitement les informations de fréquence fondamentales de la parole. En réponse aux problèmes ci-dessus, l'équipe a proposé une méthode d'amélioration des harmoniques de la parole basée sur un filtre en peigne apprenable. Cette méthode combine l'estimation de la fréquence fondamentale et le filtrage en peigne, et le gain du filtre en peigne peut être optimisé de bout en bout. Les expériences montrent que cette méthode permet d'obtenir une meilleure amélioration des harmoniques avec une quantité de calcul comparable à celle des méthodes existantes.
Structure du cadre du modèle
Estimateur de fréquence fondamentale (Estimateur F0)
Afin de réduire la difficulté de l'estimation de la fréquence fondamentale et de permettre à l'ensemble de la liaison de fonctionner de bout en bout, la plage de fréquences fondamentales cible à estimer est discrétisée en N fréquences fondamentales discrètes, et estimées à l'aide d'un classificateur. 1 dimension est ajoutée pour représenter les images non vocales, et le résultat final du modèle est la probabilité de N+1 dimensions. Conformément à CREPE, l'équipe utilise les caractéristiques de douceur gaussiennes comme cible d'entraînement et l'entropie croisée binaire comme fonction de perte :
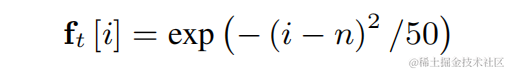
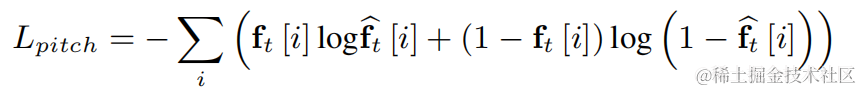
Filtre en peigne apprenable
pour chacune des fréquences de base discrètes ci-dessus, l'équipe utilise un FIR filtre similaire à PercepNet pour le filtrage en peigne, qui peut être exprimé sous forme de train d'impulsions modulé :
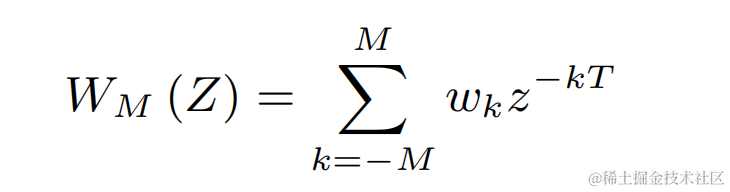
Utilisez une couche de convolution bidimensionnelle (Conv2D) pour calculer simultanément les résultats de filtrage de toutes les fréquences fondamentales discrètes pendant l'entraînement. Le poids de la convolution bidimensionnelle peut être exprimé sous la forme de la matrice dans la figure ci-dessous. dimensions, et chaque dimension est utilisée L'initialisation du filtre ci-dessus :
Multipliez l'étiquette one-hot de la fréquence fondamentale cible et la sortie de la convolution bidimensionnelle pour obtenir le résultat de filtrage correspondant à la fréquence fondamentale de chaque image :

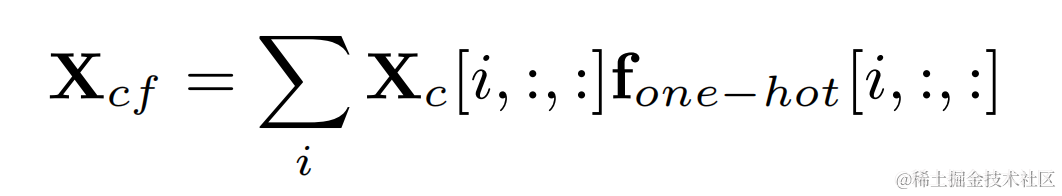
Audio après amélioration harmonique Ajoutez le poids audio d'origine et multipliez-le par le gain de sous-bande pour obtenir la sortie finale :
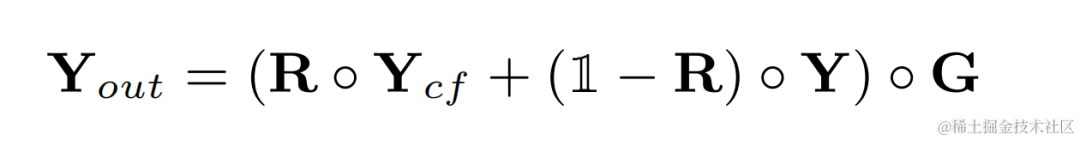
Pendant l'inférence, chaque image n'a besoin que de calculer le résultat de filtrage d'une fréquence fondamentale, le coût de calcul de cette méthode est donc faible.
Structure du modèle
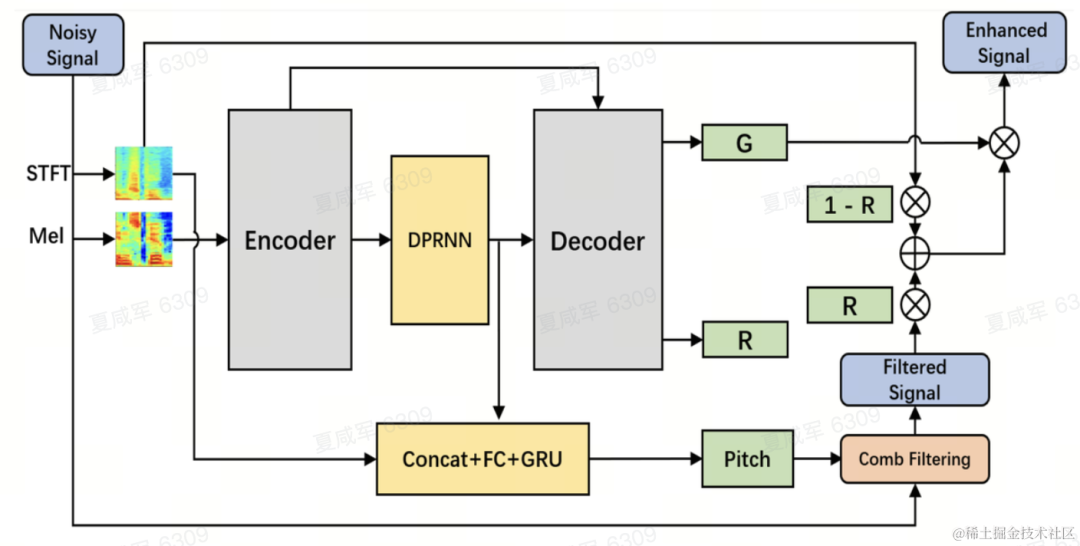
L'équipe utilise le réseau récurrent convolutionnel à double chemin (DPCRN) comme épine dorsale du modèle d'amélioration de la parole et ajoute un estimateur de fréquence fondamental. L'encodeur et le décodeur utilisent une convolution séparable en profondeur pour former une structure symétrique. Le décodeur a deux branches parallèles qui génèrent respectivement le gain de sous-bande G et le coefficient de pondération R. L'entrée de l'estimateur de fréquence fondamentale est la sortie du module DPRNN et le spectre linéaire. La quantité de calcul de ce modèle est d'environ 300 M de MAC, dont la quantité de calcul de filtrage en peigne est d'environ 0,53 M de MAC.
Formation du modèle
Dans l'expérience, les ensembles de données de défi VCTK-DEMAND et DNS4 ont été utilisés pour la formation, et la fonction de perte d'amélioration de la parole et d'estimation de la fréquence fondamentale a été utilisée pour l'apprentissage multitâche.
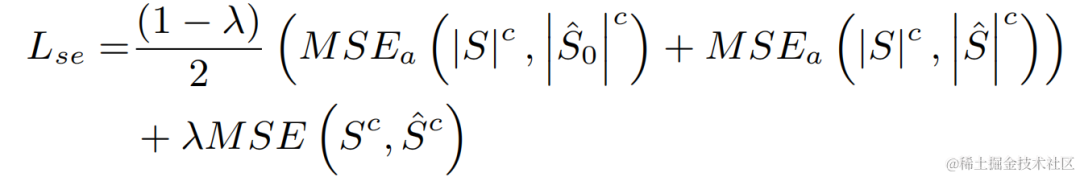
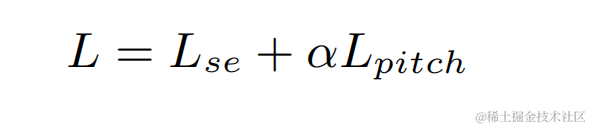
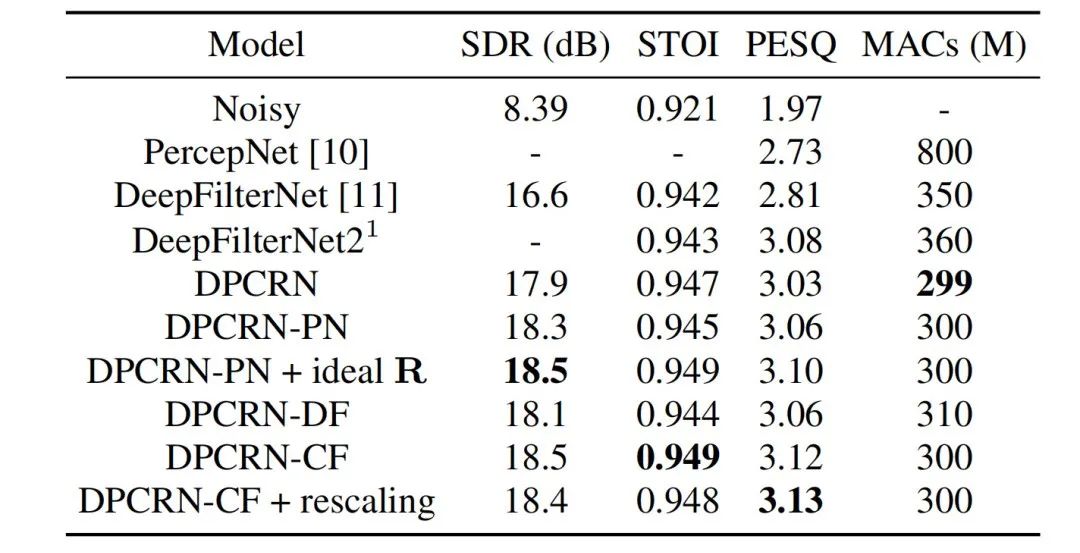
Résultats expérimentaux
L'équipe de streaming audio a comparé le modèle de filtre en peigne apprenable proposé avec des modèles utilisant le filtre en peigne de PercepNet et l'algorithme de filtre de DeepFilterNet, respectivement appelés DPCRN-CF et DPCRN-DF. Sur l'ensemble de test VCTK, la méthode proposée dans cet article présente des avantages par rapport aux méthodes existantes.
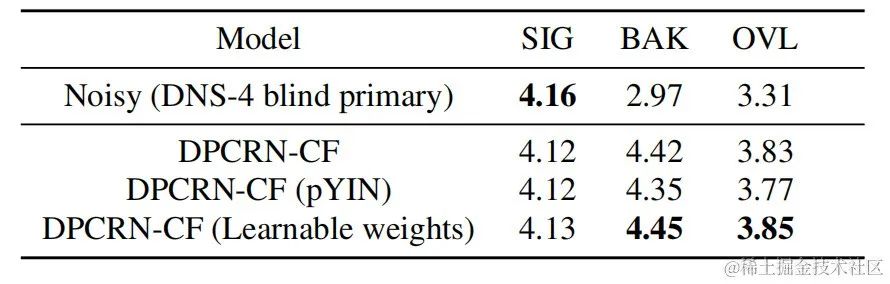
Parallèlement, l'équipe a mené des expériences d'ablation sur l'estimation de la fréquence fondamentale et les filtres apprenables. Les résultats expérimentaux montrent que l’apprentissage de bout en bout produit de meilleurs résultats que l’utilisation d’algorithmes d’estimation de fréquence fondamentale et de poids de filtre basés sur le traitement du signal.
Encodeur audio de réseau neuronal de bout en bout basé sur Intra-BRNN et GB-RVQ
Adresse papier : https://www.isca-speech.org/archive/pdfs/interspeech_2023/xu23_interspeech.pdf
Contexte
Ces dernières années, de nombreux modèles de réseaux neuronaux ont été utilisés pour des tâches de codage vocal à faible débit. Cependant, certains modèles de bout en bout ne parviennent pas à exploiter pleinement les informations liées à l'intra-trame, et le quantificateur introduit a une grande capacité. erreurs de quantification, entraînant une qualité audio post-codage faible. Afin d'améliorer la qualité de l'encodeur audio du réseau neuronal de bout en bout, l'équipe audio en streaming a proposé un codec vocal neuronal de bout en bout, à savoir CBRC (Convolutional and Bidirectionnel Recurrent neural Codec). CBRC utilise une structure entrelacée de 1D-CNN (convolution unidimensionnelle) et Intra-BRNN (réseau neuronal récurrent bidirectionnel intra-trame) pour utiliser plus efficacement la corrélation intra-trame. De plus, l’équipe utilise le quantificateur vectoriel résiduel par groupe et par recherche de faisceau (GB-RVQ) dans CBRC pour réduire le bruit de quantification. CBRC encode l'audio 16 kHz avec une longueur de trame de 20 ms, sans délai système supplémentaire, et convient aux scénarios de communication en temps réel. Les résultats expérimentaux montrent que la qualité vocale du codage CBRC avec un débit binaire de 3 kbps est meilleure que celle d'Opus avec 12 kbps.
Structure du cadre modèle
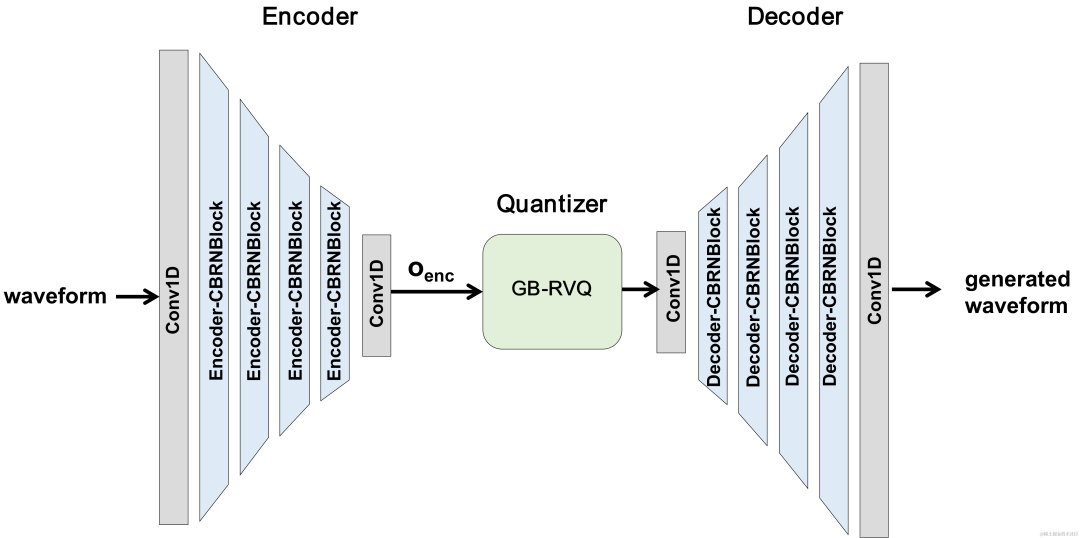
Structure globale du CBRC
Structure du réseau d'encodeur et de décodeur
L'encodeur utilise 4 CBRNBlocks en cascade pour extraire les fonctionnalités audio. Chaque CBRNBlock se compose de trois unités résiduelles pour extraire les fonctionnalités et d'une convolution unidimensionnelle qui contrôle le taux de sous-échantillonnage. Chaque fois que les fonctionnalités de l'encodeur sont sous-échantillonnées, le nombre de canaux de fonctionnalités est doublé. ResidualUnit est composé d'un module de convolution résiduelle et d'un réseau récurrent bidirectionnel résiduel, dans lequel la couche de convolution utilise une convolution causale, tandis que la structure GRU bidirectionnelle dans Intra-BRNN ne traite que les fonctionnalités audio intra-trame de 20 ms. Le réseau du décodeur est la structure miroir du codeur, utilisant une convolution transposée unidimensionnelle pour le suréchantillonnage. La structure entrelacée de 1D-CNN et Intra-BRNN permet à l'encodeur et au décodeur d'utiliser pleinement la corrélation audio intra-trame de 20 ms sans introduire de délai supplémentaire.
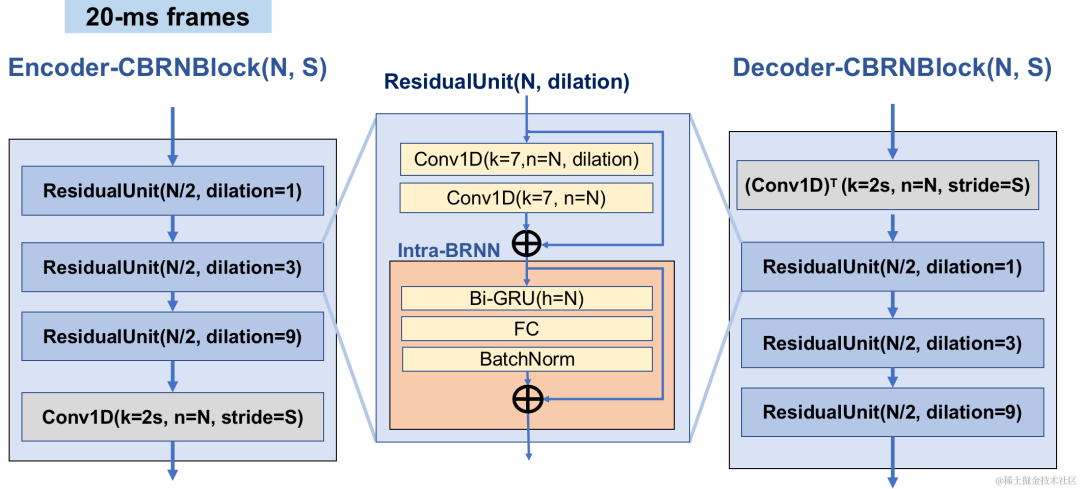
Structure CBRNBlock
Quantificateur vectoriel résiduel de recherche de groupe et de faisceau GB-RVQ
CBRC utilise le quantificateur vectoriel résiduel (Residual Vector Quantizer, RVQ) pour quantifier et compresser les caractéristiques de sortie du réseau de codage à un débit binaire spécifié . RVQ utilise une cascade de quantificateurs vectoriels (VQ) multicouches pour compresser les caractéristiques. Chaque couche de VQ quantifie le résidu de quantification de la couche précédente de VQ, ce qui peut réduire considérablement la quantité de paramètres de livre de codes d'une seule couche de VQ en même temps. débit binaire. L'équipe a proposé deux meilleures structures de quantificateur dans CBRC, à savoir le RVQ par groupe et le quantificateur vectoriel résiduel par recherche de faisceau (Beam-search RVQ).
RVQ par groupe |
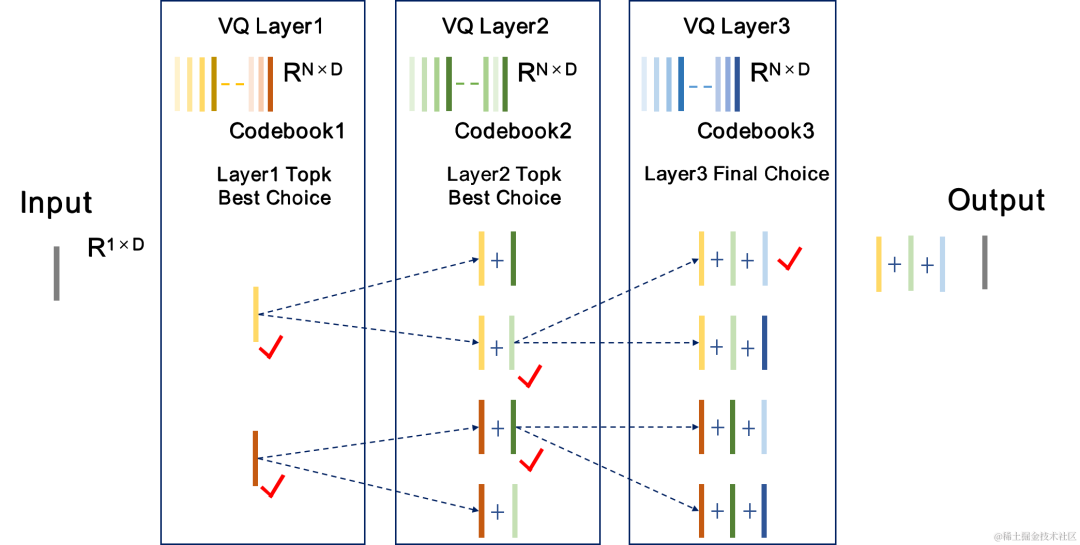
Recherche de faisceau RVQ |
|
|
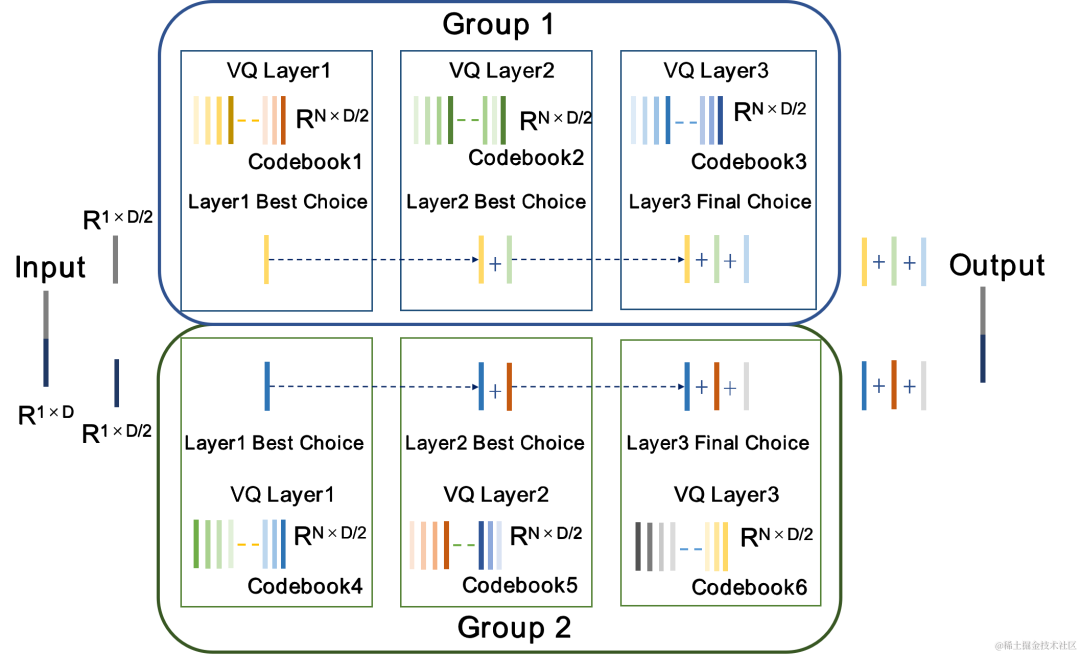
RVQ par groupe regroupe la sortie de l'encodeur et utilise le RVQ groupé pour quantifier indépendamment les caractéristiques groupées, puis la sortie quantifiée groupée est fusionnée dans le décodeur d'entrée. RVQ par groupe utilise la quantification de groupe pour réduire les paramètres du livre de codes et la complexité de calcul du quantificateur, tout en réduisant également la difficulté de la formation de bout en bout du CBRC et en améliorant ainsi la qualité de l'audio codé CBRC.
L'équipe a introduit Beam-search RVQ dans la formation de bout en bout de l'encodeur audio neuronal et a utilisé l'algorithme de recherche Beam pour sélectionner la combinaison de livre de codes avec la plus petite erreur de chemin de quantification dans RVQ afin de réduire l'erreur de quantification du quantificateur. L'algorithme RVQ d'origine sélectionne comme sortie le livre de codes présentant la plus petite erreur dans chaque couche de quantification VQ, mais la combinaison des livres de codes optimaux pour chaque couche de quantification VQ peut ne pas nécessairement être la combinaison de livres de codes globalement optimale. L’équipe utilise Beam-search RVQ pour conserver k chemins de quantification optimaux dans chaque couche de VQ sur la base du critère d’erreur minimale du chemin de quantification, permettant ainsi la sélection de meilleures combinaisons de livres de codes dans un espace de recherche de quantification plus grand et réduisant les erreurs de quantification.
|
Bref processus de l'algorithme RVQ de recherche de faisceau : 1. Chaque couche de VQ entre les chemins de quantification candidats de la couche précédente VQ. , obtenez un chemin de quantification candidat. 2. Sélectionnez le chemin de quantification avec la plus petite erreur de chemin de quantification parmi les chemins de quantification candidats comme sortie actuelle de la couche VQ. 3. Sélectionnez le chemin avec la plus petite erreur de chemin de quantification dans la dernière couche de VQ comme sortie du quantificateur. |
|

Formation du modèle
Dans l'expérience, 245 heures de parole à 16 kHz dans l'ensemble de données LibriTTS ont été utilisées pour la formation, et l'amplitude de la parole a été multipliée par un gain aléatoire puis entrée dans le modèle. La fonction de perte dans la formation comprend une perte multi-échelle de reconstruction du spectre, une perte contradictoire du discriminateur et une perte de caractéristiques, une perte de quantification VQ et une perte de perception.
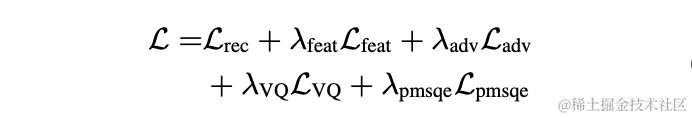
Résultats expérimentaux
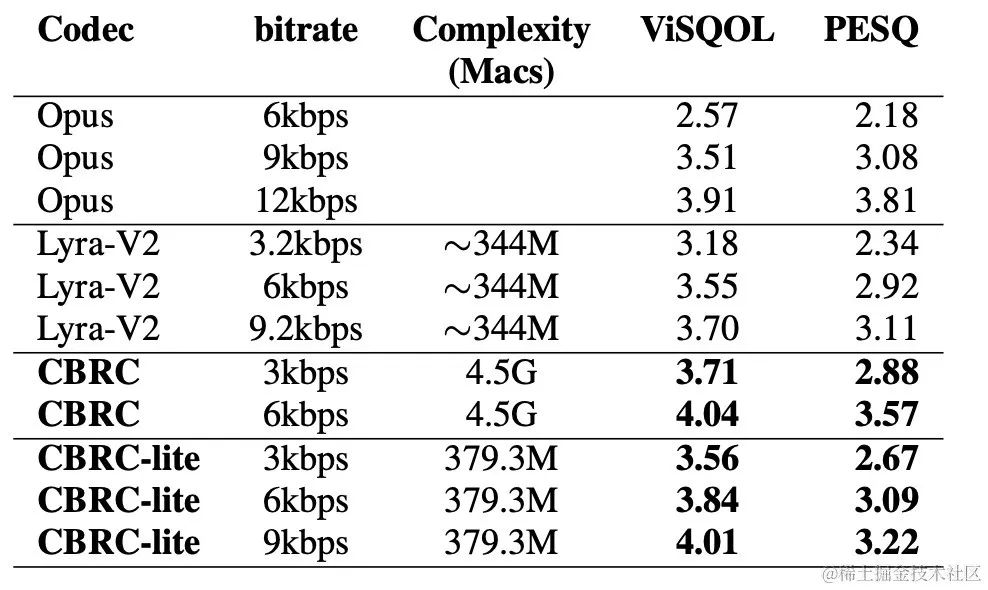
Scores subjectifs et objectifs
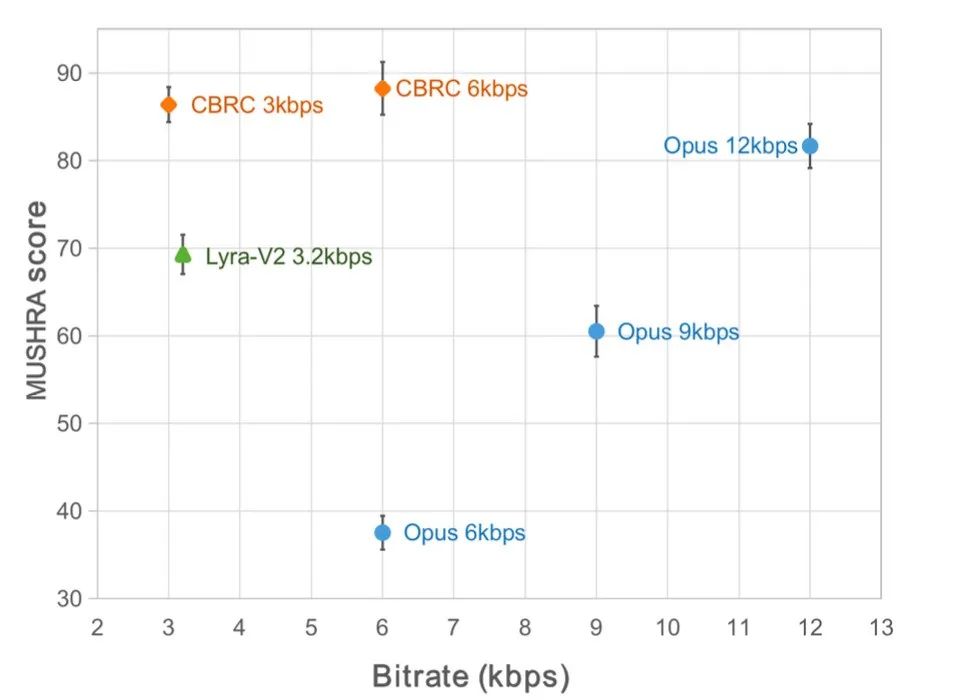
Afin d'évaluer la qualité de la parole codée CBRC, 10 ensembles de comparaison audio multilingues ont été construits et comparés à d'autres codecs audio sur cet ensemble de comparaison. Afin de réduire l’impact de la complexité informatique, l’équipe a conçu un CBRC-lite léger, dont la complexité informatique est légèrement supérieure à celle du Lyra-V2. D'après les résultats subjectifs de la comparaison d'écoute, on peut voir que la qualité vocale du CBRC à 3 kbps dépasse celle de l'Opus à 12 kbps et dépasse également Lyra-V2 à 3,2 kbps, ce qui montre l'efficacité de la méthode proposée. Des échantillons audio codés CBRC sont fournis sur https://bytedance.feishu.cn/docx/OqtjdQNhZoAbNoxMuntcErcInmb.
Score objectif |
Score d'écoute subjective |
|
|
Expérience d'ablation
L'équipe a conçu des expériences d'ablation pour Intra-BRNN, RVQ par groupe et RVQ par recherche de faisceau. Les résultats expérimentaux montrent que l'utilisation d'Intra-BRNN dans l'encodeur et le décodeur peut améliorer considérablement la qualité de la parole. En outre, l’équipe a compté la fréquence d’utilisation du livre de codes dans RVQ et calculé le décodage entropique pour comparer les taux d’utilisation du livre de codes dans différentes structures de réseau. Par rapport à la structure entièrement convolutive, CBRC utilisant Intra-BRNN augmente le débit binaire de codage potentiel de 4,94 kbps à 5,13 kbps. De même, l'utilisation de RVQ par groupe et de RVQ par recherche de faisceau dans CBRC peut améliorer considérablement la qualité de la parole codée, et par rapport à la complexité informatique du réseau neuronal lui-même, l'augmentation de la complexité apportée par GB-RVQ est presque négligeable.


Sample sound
Audio original
arctic_a0023_16k, équipe technique ByteDance, 5 secondes
es01_ l_1 6k, équipe technique ByteDance, 10 secondes
CBRC 3kbps
arctic_a0023_16k_CBRC_3kbps, équipe technique Bytedance, 5 secondes
es01_l_16k_CBRC_3kbps, équipe technique Bytedance, 10 secondes
CBRC-lite 3kbps
arctic_a0023_16k_CBRC_lite_3kbps, technique Bytedance équipe, 5 secondes
es01_l_16k_CBRC_lite_3kbps, équipe technique Bytedance, 10 secondes
Méthode d'annulation d'écho basée sur un réseau neuronal progressif en deux étapes
Adresse papier : https://www.isca-speech.org/archive /pdfs/interspeech_2023/chen23e_interspeech.pdf
Contexte
Dans les systèmes de communication mains libres, l'écho acoustique est une interférence de fond gênante. L'écho se produit lorsqu'un signal distant est lu par un haut-parleur puis enregistré par un microphone proche. L'annulation de l'écho acoustique (AEC) est conçue pour supprimer les échos indésirables captés par les microphones. Dans le monde réel, de nombreuses applications nécessitent une annulation d'écho, telles que les communications en temps réel, les salles de classe intelligentes, les systèmes mains libres des véhicules, etc.
Récemment, les modèles AEC basés sur les données et utilisant des méthodes d'apprentissage profond (DL) se sont révélés plus robustes et plus puissants. Ces méthodes formulent l'AEC comme un problème d'apprentissage supervisé, dans lequel la fonction de mappage entre le signal d'entrée et le signal cible proximal est apprise via un réseau neuronal profond (DNN). Cependant, le chemin d’écho réel est extrêmement complexe, ce qui impose des exigences plus élevées aux capacités de modélisation du DNN. Afin de réduire la charge de modélisation du réseau, la plupart des méthodes AEC basées sur DL existantes adoptent un module frontal d'annulation d'écho linéaire (LAEC) pour supprimer la plupart des composantes linéaires de l'écho. Cependant, les modules LAEC présentent deux inconvénients : 1) un LAEC inapproprié peut provoquer une certaine distorsion de la parole proche, et 2) le processus de convergence LAEC rend les performances de suppression d'écho linéaire instables. Étant donné que LAEC s'auto-optimise, ses lacunes entraîneront une charge d'apprentissage supplémentaire pour les réseaux neuronaux ultérieurs.
Afin d'éviter l'impact du LAEC et de maintenir une meilleure qualité vocale de proximité, cet article explore un nouveau modèle de traitement en deux étapes basé sur la DL de bout en bout et propose un modèle de traitement à gros grain (grossier) et fin. -grained Un réseau neuronal en cascade à deux étages (TSPNN) à deux étages fins est utilisé pour les tâches d'annulation d'écho. Un grand nombre de résultats expérimentaux montrent que la méthode d'annulation d'écho en deux étapes proposée peut obtenir de meilleures performances que les autres méthodes traditionnelles.
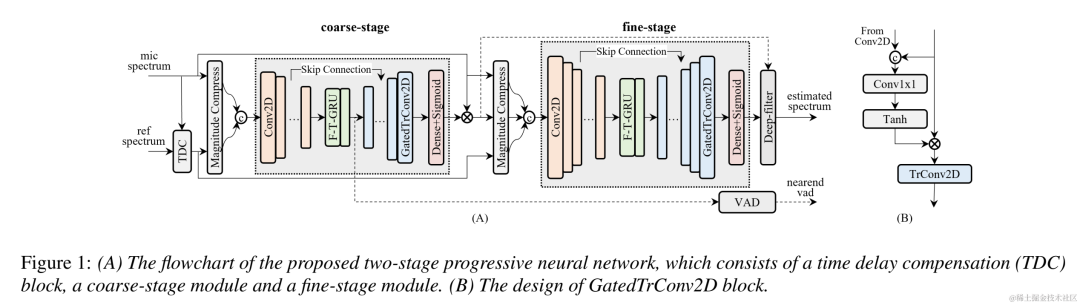
Structure du cadre du modèle
Comme le montre la figure ci-dessous, TSPNN se compose principalement de trois parties : un module de compensation de retard (TDC), un module de traitement à gros grain (étape grossière) et un module de traitement à grain fin (étape fine) . TDC est responsable de l'alignement du signal de référence distant d'entrée (ref) et du signal du microphone proche (mic), ce qui est bénéfique pour la convergence ultérieure du modèle. L'étape grossière est chargée de supprimer la majeure partie de l'écho et du bruit du micro, réduisant ainsi considérablement la charge d'apprentissage du modèle lors de l'étape fine suivante. Dans le même temps, l'étape grossière combine la tâche de détection d'activité vocale (VAD) pour un apprentissage multitâche afin de renforcer la perception du modèle de la parole proche et de réduire les dommages causés à la parole proche. L'étage fin est chargé d'éliminer davantage l'écho et le bruit résiduels, et de combiner les informations sur les points de fréquence voisins pour mieux reconstruire le signal cible proche.
Afin d'éviter les solutions sous-optimales provoquées par l'optimisation indépendante du modèle de chaque étape, cet article utilise la forme d'optimisation en cascade pour optimiser simultanément l'étape grossière et l'étape fine, tout en assouplissant les contraintes sur l'étape grossière pour éviter de causer des problèmes. aux dommages à la parole à l'extrémité proche. De plus, afin de permettre au modèle de percevoir la parole proche, la présente invention introduit la tâche VAD pour un apprentissage multitâche et ajoute la perte de VAD à la fonction de perte. La fonction de perte finale est :
où représente le spectre complexe du signal proche de l'extrémité cible, le spectre complexe du signal proche estimé à l'étage grossier et à l'étage fin représente respectivement l'état actif de la parole proche estimé par l'étage grossier ; , parole proche respectivement Étiquette de détection d'activité ; est un scalaire de contrôle, principalement utilisé pour ajuster le degré d'attention aux différentes étapes de la phase d'entraînement. La présente invention limite à relâcher les contraintes sur le stade grossier et à éviter efficacement un endommagement de l'extrémité proximale du stade grossier.
Résultats expérimentaux
Données expérimentales
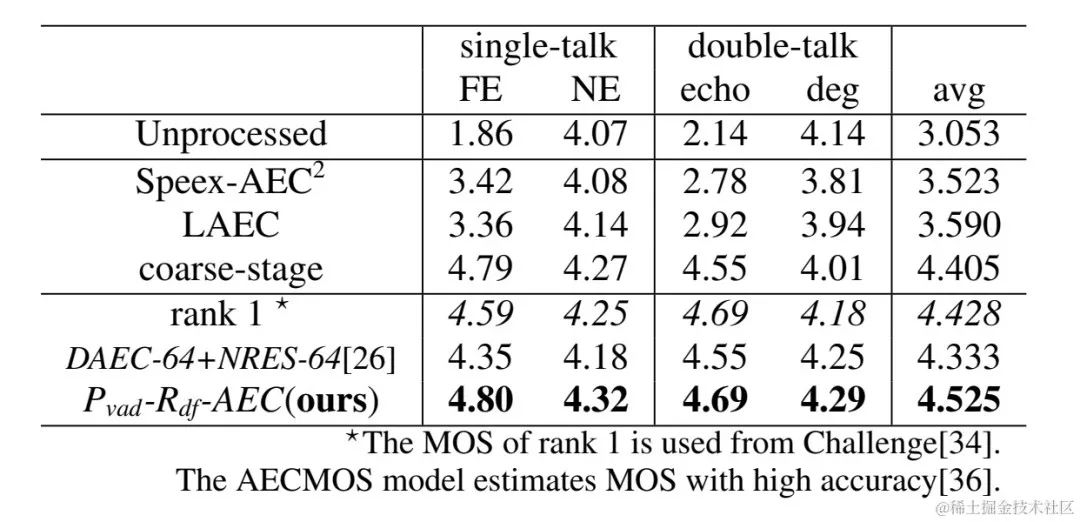
Le système d'annulation d'écho en deux étapes proposé par l'équipe audio de streaming Volcano Engine a également été comparé à d'autres méthodes. Les résultats expérimentaux montrent que le système proposé peut obtenir de meilleurs résultats que les autres méthodes traditionnelles.
Exemples spécifiques
- Résultats expérimentaux Lien Github : https://github.com/enhancer12/TSPNN
- Performance de scène à double parole :
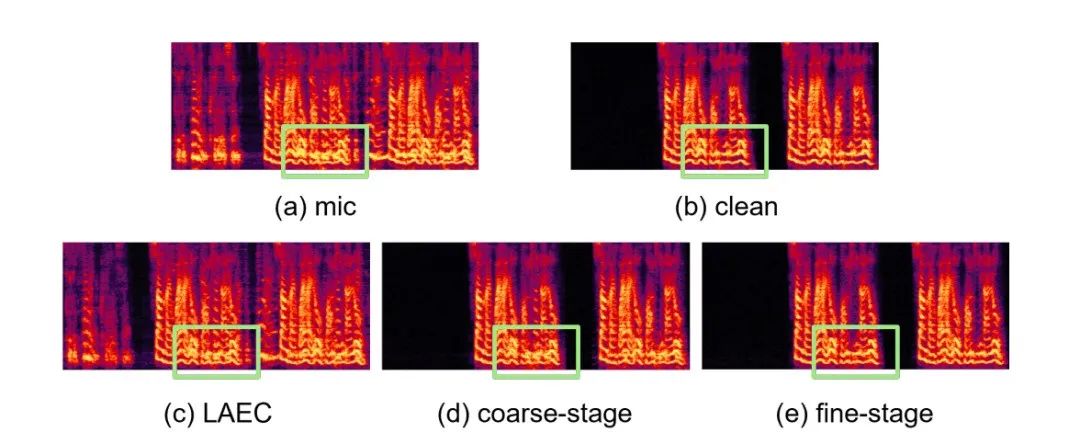
CHiME-7 amélioration adaptative de la parole à domaine non supervisé (UDASE) Challenge Champion Solution
Adresse papier : https://www.chimechallenge.org/current/task2/documents/Zhang_NB.pdf
Contexte :
Ces dernières années, avec le développement des réseaux de neurones et de l'apprentissage profond basé sur les données Avec Avec le développement de la technologie, la recherche sur la technologie d'amélioration de la parole s'est progressivement tournée vers des méthodes basées sur l'apprentissage profond, et de plus en plus de modèles d'amélioration de la parole basés sur des réseaux neuronaux profonds ont été proposés. Cependant, la plupart de ces modèles sont basés sur un apprentissage supervisé et nécessitent une grande quantité de données appariées pour la formation. Cependant, dans les scénarios réels, il est impossible de capturer simultanément la parole dans des scènes bruyantes et les balises de parole claire ininterrompue qui y sont associées. La simulation de données est généralement utilisée pour collecter séparément la parole claire et divers bruits, puis les combiner en fonction d'un certain nombre de bruits. Le rapport signal/bruit se mélange pour produire des fréquences bruyantes. Cela conduit à une inadéquation entre les scénarios de formation et les scénarios d'application réels, et à une baisse des performances du modèle dans les applications réelles.
Afin de mieux résoudre le problème d'inadéquation de domaine ci-dessus, une technologie d'amélioration de la parole non supervisée et auto-supervisée a été proposée en utilisant une grande quantité de données non étiquetées dans des scènes réelles. CHiME Challenge Track 2 vise à utiliser des données non étiquetées pour surmonter le problème de dégradation des performances des modèles d'amélioration de la parole formés sur des données étiquetées générées artificiellement en raison de l'inadéquation entre les données de formation et les scénarios d'application réels. L'objectif de la recherche est de savoir comment utiliser la cible non étiquetée. les données du domaine et les données étiquetées en dehors de l'ensemble sont utilisées pour améliorer les résultats d'amélioration du domaine cible.
Structure du cadre modèle :
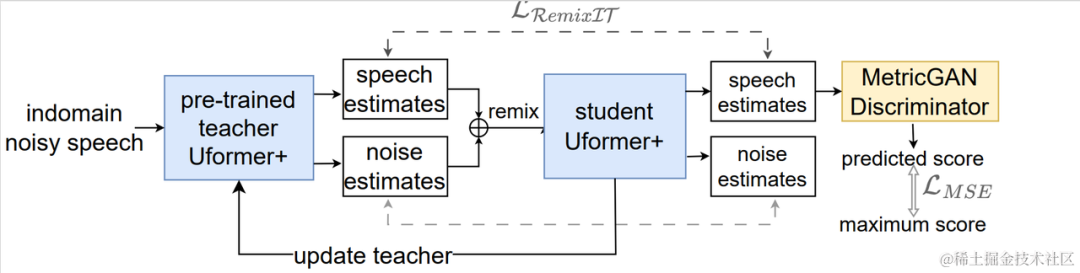
Organigramme du système d'amélioration adaptative de la parole dans un domaine non supervisé
Comme le montre la figure ci-dessus, le cadre proposé est un réseau enseignant-élève. Tout d'abord, utilisez la détection d'activité vocale, UNA-GAN, la réponse impulsionnelle de salle simulée, le bruit dynamique et d'autres technologies sur les données du domaine pour générer un ensemble de données étiquetées le plus proche du domaine cible, et pré-former le réseau de réduction du bruit des enseignants Uformer+ sur l'ensemble de données étiqueté en dehors du domaine. Ensuite, ce cadre est utilisé pour mettre à jour le réseau d'étudiants sur les données non étiquetées dans le domaine, c'est-à-dire que le réseau d'enseignants pré-entraînés est utilisé pour estimer la parole propre et le bruit en tant que pseudo-étiquettes à partir de l'audio bruité, et ils sont remixés de manière aléatoire. commande comme entrée de données de formation dans le réseau d'étudiants. Formation supervisée des réseaux d'étudiants à l'aide de pseudo-labels. Le score de qualité vocale propre généré par le réseau étudiant est estimé à l'aide du discriminateur MetricGAN pré-entraîné et la perte est calculée avec le score le plus élevé pour guider le réseau étudiant afin de générer un son propre de meilleure qualité. Après chaque étape de formation, les paramètres du réseau d'étudiants sont mis à jour vers le réseau d'enseignants avec un certain poids pour obtenir des pseudo-étiquettes d'apprentissage supervisé de meilleure qualité, et ainsi de suite.
Réseau Ufomer+
Uformer+ est amélioré par l'ajout de MetricGAN basé sur le réseau Uformer. Uformer est un réseau de convertisseurs à double trajet en nombres réels complexe basé sur la structure Unet. Il comporte deux branches parallèles, la branche du spectre d'amplitude et la branche du spectre complexe. La structure du réseau est illustrée dans la figure ci-dessous. La branche d'amplitude est utilisée pour la fonction principale de suppression du bruit et peut supprimer efficacement la plupart des bruits. La branche complexe sert d'auxiliaire pour compenser les pertes telles que les détails spectraux et l'écart de phase. L'idée principale de MetricGAN est d'utiliser des réseaux de neurones pour simuler des indicateurs d'évaluation de la qualité de la parole non différenciables afin qu'ils puissent être utilisés dans la formation en réseau afin de réduire les erreurs causées par des indicateurs d'évaluation incohérents lors de la formation et de l'application réelle. Ici, l’équipe utilise l’évaluation perceptuelle de la qualité de la parole (PESQ) comme cible pour l’estimation du réseau MetricGAN.
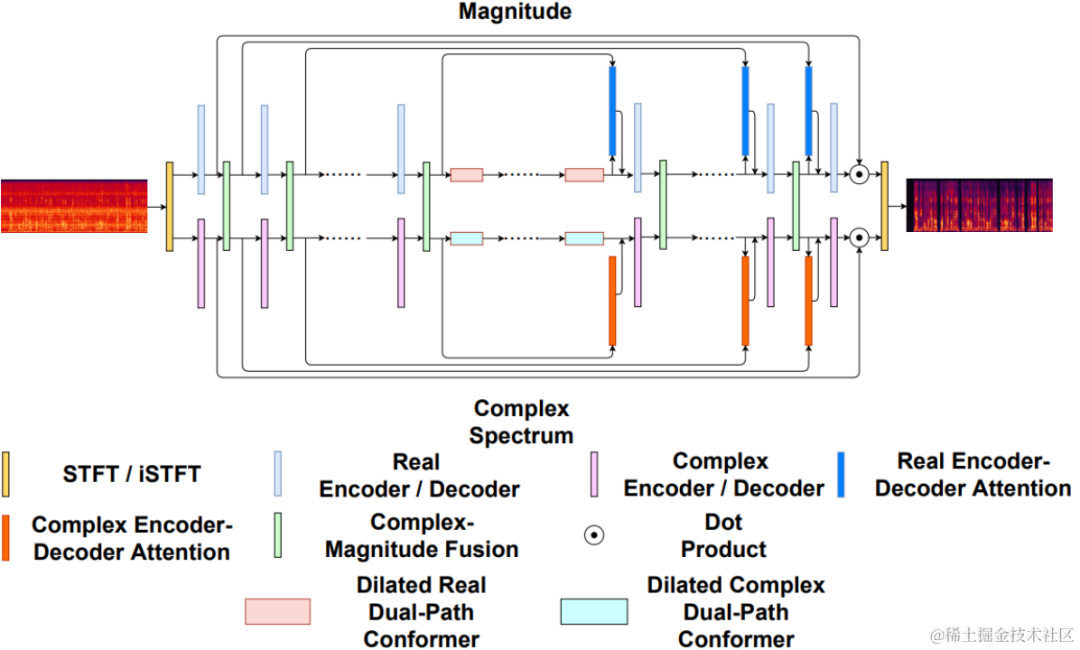
Schéma de structure du réseau Uformer
Cadre RemixIT-G
RemixIT-G est un réseau enseignant-élève. Il pré-entraîne d'abord le modèle enseignant Uformer+ sur des données étiquetées en dehors du domaine et utilise le modèle enseignant pré-formé. pour décoder l'audio bruyant dans le domaine. Estimation du bruit et de la parole. Ensuite, l'ordre du bruit et de la parole estimés est brouillé au sein du même lot, et le bruit et la parole sont remixés dans l'ordre brouillé en audio bruité, qui est utilisé comme entrée pour la formation du réseau d'étudiants. Bruit et parole estimés par le réseau d'enseignants comme pseudo-étiquettes. Le réseau étudiant décode l'audio bruité remixé, estime le bruit et la parole, calcule les pertes avec des pseudo-étiquettes et met à jour les paramètres du réseau étudiant. La parole estimée par le réseau étudiant est introduite dans le discriminateur MetricGAN pré-entraîné pour prédire PESQ, et la perte est calculée avec la valeur maximale de PESQ pour mettre à jour les paramètres du réseau étudiant.
Une fois que toutes les données de formation ont terminé une itération, les paramètres du réseau d'enseignants sont mis à jour selon la formule suivante :, où sont les paramètres du K-ème cycle de formation du réseau d'enseignants, sont les paramètres du K- ème édition du réseau étudiant. C'est-à-dire que les paramètres du réseau d'étudiants sont ajoutés au réseau d'enseignants avec un certain poids.
Méthode d'augmentation des données UNA-GAN
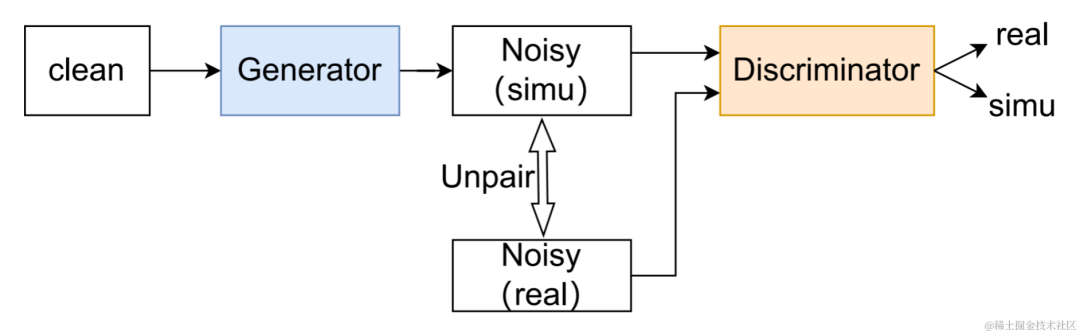
Diagramme de structure UNA-GAN
Réseau d'augmentation de données adaptative au bruit non supervisé UNA-GAN est un modèle de génération audio bruyant basé sur un réseau adverse génératif. Son objectif est de convertir directement une parole claire en audio bruité avec du bruit intra-domaine en utilisant uniquement l'audio bruyant dans le domaine lorsque des données de bruit indépendantes ne peuvent pas être obtenues. Le générateur génère une parole claire et produit un son bruyant simulé. Le discriminateur entre l'audio bruyant généré ou l'audio bruyant réel dans le domaine, et détermine si l'audio d'entrée provient d'une scène réelle ou est généré par simulation. Le discriminateur distingue principalement les sources en fonction de la répartition du bruit de fond et, dans ce processus, la parole humaine est traitée comme une information invalide. En effectuant le processus de formation contradictoire ci-dessus, le générateur tente d'ajouter du bruit dans le domaine directement à l'audio propre d'entrée pour confondre le discriminateur ; le discriminateur tente de distinguer la source de l'audio bruyant ; Pour éviter que le générateur n'ajoute trop de bruit et ne masque la parole humaine dans l'audio d'entrée, un apprentissage contrastif est utilisé. Échantillonnez 256 blocs aux positions correspondant à l’audio bruyant généré et à la parole claire d’entrée. Les paires de blocs situés à la même position sont considérées comme des exemples positifs, et les paires de blocs situés à des positions différentes sont considérées comme des exemples négatifs. Calculez la perte d'entropie croisée à l'aide d'exemples positifs et négatifs.
Résultats expérimentaux
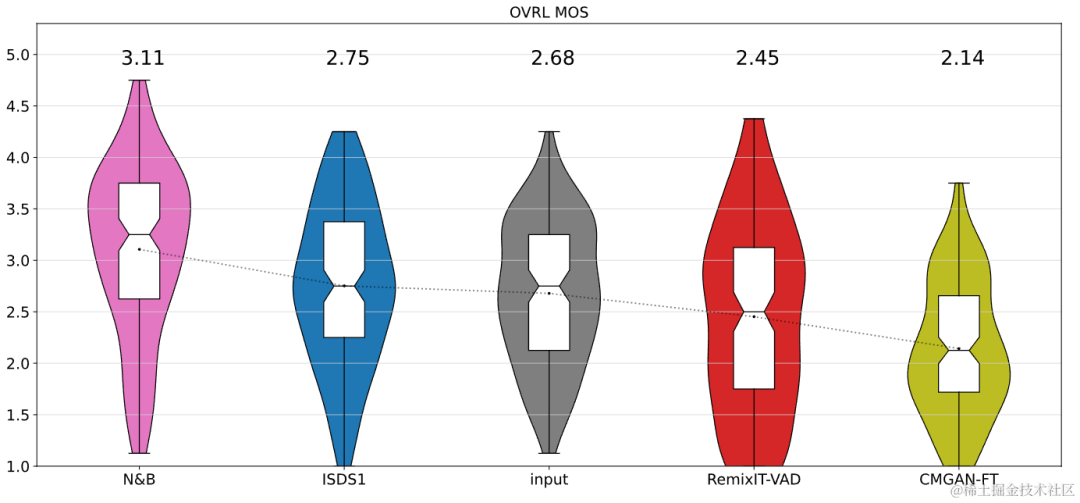
Les résultats montrent que l'Uformer+ proposé a des performances plus élevées que le Sudo rm-rf de base, et que la méthode d'augmentation des données UNA-GAN a également la capacité de générer un son bruyant dans le domaine. Le cadre d'adaptation de domaine RemixIT de base a réalisé de grandes améliorations dans SI-SDR, mais a de mauvaises performances sur DNS-MOS. L'amélioration RemixIT-G proposée par l'équipe a permis d'obtenir des améliorations efficaces des deux indicateurs en même temps et d'obtenir le score MOS d'écoute subjective le plus élevé dans l'ensemble de tests aveugles de la compétition. Les résultats finaux des tests d'écoute sont présentés dans la figure ci-dessous.
Résumé et perspectives
Ce qui précède présente quelques solutions et effets créés par l'équipe Volcano Engine Streaming Audio, basés sur l'apprentissage en profondeur dans le sens de la réduction du bruit spécifique au locuteur, de l'encodeur IA, de l'annulation de l'écho et de l'amélioration adaptative non supervisée de la parole. , les scénarios futurs sont encore confrontés à des défis dans de nombreuses directions, tels que la manière de déployer et d'exécuter des modèles légers et peu complexes sur divers terminaux et la robustesse des effets multi-appareils. Ces défis seront également au centre de l'équipe de streaming audio à l'avenir. .Orientation de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!