
Maison >développement back-end >Tutoriel Python >Comment implémenter un algorithme de descente de gradient en Python pour trouver les minima locaux ?
Comment implémenter un algorithme de descente de gradient en Python pour trouver les minima locaux ?

- 王林avant
- 2023-09-06 22:37:05957parcourir
La descente de gradient est une méthode d'optimisation importante dans l'apprentissage automatique, utilisée pour minimiser la fonction de perte du modèle. En termes simples, cela nécessite de modifier à plusieurs reprises les paramètres du modèle jusqu'à ce que la plage de valeurs idéale qui minimise la fonction de perte soit trouvée. La méthode fonctionne en faisant de petits pas dans la direction du gradient négatif de la fonction de perte, ou plus précisément, le long du chemin de descente la plus raide. Le taux d'apprentissage est un hyperparamètre qui régule le compromis entre la vitesse et la précision de l'algorithme, et il affecte la taille du pas. De nombreuses méthodes d'apprentissage automatique, notamment la régression linéaire, la régression logistique et les réseaux de neurones, pour n'en citer que quelques-unes, utilisent la descente de gradient. Sa principale application est la formation de modèles, où l'objectif est de minimiser la différence entre les valeurs attendues et réelles de la variable cible. Dans cet article, nous examinerons l'implémentation de la descente de gradient en Python pour trouver les minimums locaux.
Il est maintenant temps d'implémenter la descente de gradient en Python. Voici une explication de base de la façon dont nous le mettons en œuvre -
Tout d’abord, nous importons les bibliothèques nécessaires.
Définir sa fonction et ses dérivées.
Ensuite, nous appliquerons la fonction de descente de gradient.
Après avoir appliqué la fonction, nous définirons les paramètres pour trouver le minimum local,
Enfin, nous tracerons la sortie.
Implémentation de la descente de dégradé en Python
Importer une bibliothèque
import numpy as np import matplotlib.pyplot as plt
Ensuite on définit la fonction f(x) et sa dérivée f'(x) -
def f(x): return x**2 - 4*x + 6 def df(x): return 2*x - 4
F(x) est la fonction qui doit être réduite et df est sa dérivée (x). La méthode de descente de gradient utilise des dérivées pour se guider vers le minimum en révélant la pente de la fonction en cours de route.
Définissez ensuite la fonction de descente de gradient.
def gradient_descent(initial_x, learning_rate, num_iterations):
x = initial_x
x_history = [x]
for i in range(num_iterations):
gradient = df(x)
x = x - learning_rate * gradient
x_history.append(x)
return x, x_history
La valeur de départ de x, le taux d'apprentissage et le nombre d'itérations requis sont envoyés à la fonction de descente de gradient. Pour enregistrer la valeur de x après chaque itération, il initialise x à sa valeur d'origine et génère une liste vide. Le procédé effectue ensuite une descente de gradient pour le nombre d'itérations fourni, en modifiant x à chaque itération selon l'équation x = x - taux d'apprentissage * gradient. Cette fonction génère une liste de valeurs x pour chaque itération et la valeur finale de x.
La fonction de descente de gradient peut désormais être utilisée pour localiser le minimum local de f(x) -
Exemple
initial_x = 0
learning_rate = 0.1
num_iterations = 50
x, x_history = gradient_descent(initial_x, learning_rate, num_iterations)
print("Local minimum: {:.2f}".format(x))
Sortie
Local minimum: 2.00
Dans cette figure, x est initialement défini sur 0, le taux d'apprentissage est de 0,1 et 50 itérations sont exécutées. Enfin, nous publions la valeur de x, qui doit être proche du minimum local à x=2.
Tracer la fonction f(x) et la valeur x pour chaque itération nous permet de voir le processus de descente de gradient en action -
Exemple
# Create a range of x values to plot
x_vals = np.linspace(-1, 5, 100)
# Plot the function f(x)
plt.plot(x_vals, f(x_vals))
# Plot the values of x at each iteration
plt.plot(x_history, f(np.array(x_history)), 'rx')
# Label the axes and add a title
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('Gradient Descent')
# Show the plot
plt.show()
Sortie
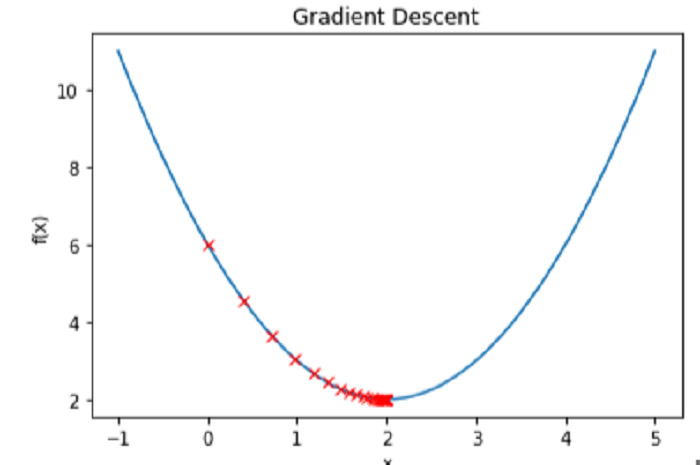
Conclusion
En résumé, pour trouver le minimum local d'une fonction, Python utilise un processus d'optimisation efficace appelé descente de gradient. La descente de gradient fonctionne en calculant la dérivée d'une fonction à chaque étape, en mettant à jour à plusieurs reprises les valeurs d'entrée dans la direction de la descente la plus raide jusqu'à ce que la valeur la plus basse soit atteinte. L'implémentation de la descente de gradient en Python nécessite de spécifier la fonction à optimiser et ses dérivées, d'initialiser les valeurs d'entrée et de déterminer le taux d'apprentissage et le nombre d'itérations de l'algorithme. Une fois l'optimisation terminée, la méthode peut être évaluée en traçant ses étapes au minimum et en voyant comment elle atteint cet objectif. La descente de gradient est une technique utile dans les applications d'apprentissage automatique et d'optimisation, car Python peut gérer de grands ensembles de données et des fonctions complexes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!