
Maison >Périphériques technologiques >IA >Est-il inutile d'affiner les « questions et réponses sur l'image basée sur la connaissance » ? Google lance le système de recherche AVIS : peu d'échantillons dépassent le PALI supervisé et la précision est triplée
Est-il inutile d'affiner les « questions et réponses sur l'image basée sur la connaissance » ? Google lance le système de recherche AVIS : peu d'échantillons dépassent le PALI supervisé et la précision est triplée

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-08-24 19:21:041450parcourir
Avec la prise en charge de grands modèles de langage (LLM), des résultats significatifs ont été obtenus dans des tâches multimodales combinées à la vision, telles que la description d'images, la réponse visuelle aux questions (VQA) et la détection d'objets à vocabulaire ouvert. Cependant, le modèle de langage visuel (VLM) actuel utilise uniquement les informations visuelles de l'image pour accomplir la tâche et fonctionne souvent mal sur des ensembles de données tels que informek et OK-VQA qui nécessitent des connaissances externes pour aider à répondre aux questions.
 Récemment, Google a publié une nouvelle méthode autonome de recherche d'informations visuelles AVIS, qui utilise de grands modèles de langage (LLM) pour formuler dynamiquement des stratégies d'utilisation d'outils externes, notamment l'appel d'API, l'analyse des résultats de sortie, la prise de décision et autres opérations. Image Q&A fournit des connaissances essentielles.
Récemment, Google a publié une nouvelle méthode autonome de recherche d'informations visuelles AVIS, qui utilise de grands modèles de langage (LLM) pour formuler dynamiquement des stratégies d'utilisation d'outils externes, notamment l'appel d'API, l'analyse des résultats de sortie, la prise de décision et autres opérations. Image Q&A fournit des connaissances essentielles.
 Veuillez cliquer sur le lien suivant pour lire l'article : https://arxiv.org/pdf/2306.08129.pdf
Veuillez cliquer sur le lien suivant pour lire l'article : https://arxiv.org/pdf/2306.08129.pdf
AVIS intègre principalement trois types d'outils :
1. image Outils pour extraire des informations visuelles
2. Outils de recherche sur le Web pour récupérer des connaissances et des faits dans le monde ouvert
3. Outils de recherche d'images qui peuvent être utilisés pour récupérer des images visuellement similaires
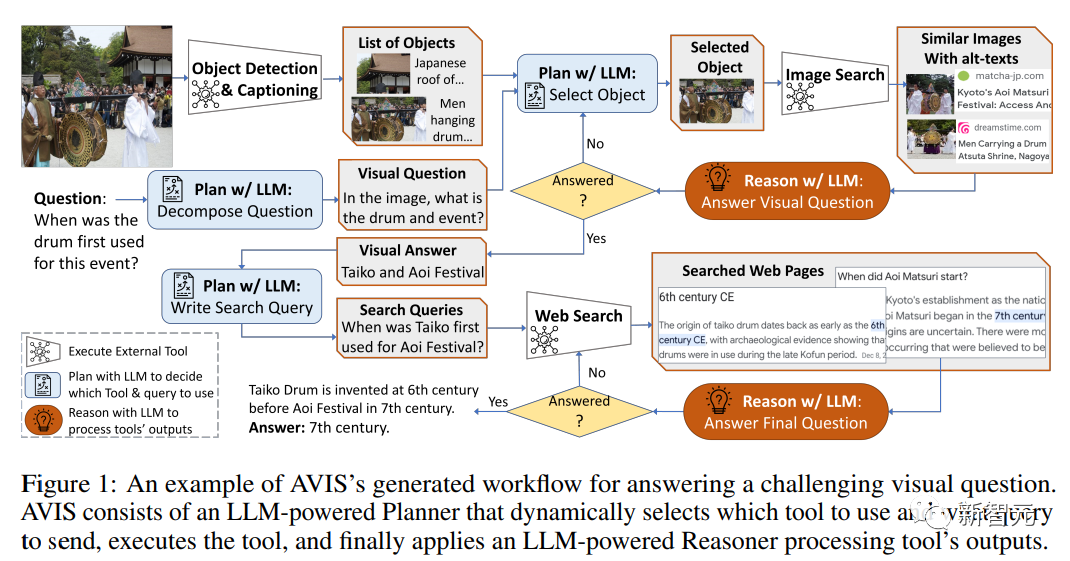 puis utiliser Le planificateur du modèle de langage sélectionne un outil et interroge les résultats à chaque étape pour générer dynamiquement des réponses aux questions.
puis utiliser Le planificateur du modèle de langage sélectionne un outil et interroge les résultats à chaque étape pour générer dynamiquement des réponses aux questions.
Simulation de la prise de décision humaine
De nombreux problèmes visuels dans les ensembles de données Infoseek et OK-VQA sont assez difficiles, même pour les humains, et nécessitent généralement l'aide de divers outils externes. Les chercheurs ont donc choisi de mener d'abord une enquête auprès des utilisateurs pour observer les humains. solutions à des problèmes de vision complexes.
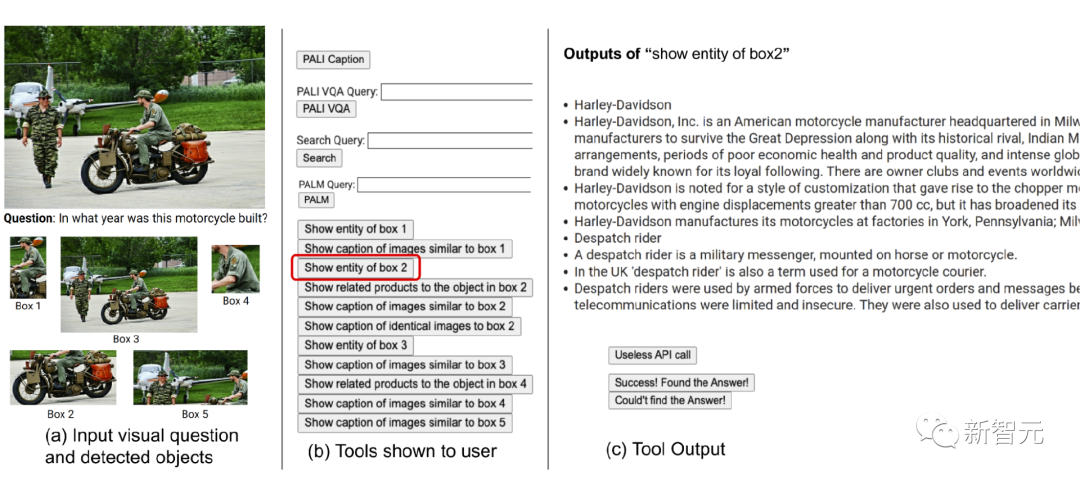 Tout d'abord, nous fournirons aux utilisateurs un ensemble d'outils disponibles, notamment PALI, PALM et la recherche sur le Web. Ensuite, nous montrons l'image d'entrée, la question, le recadrage de l'objet détecté, les entités du graphique de connaissances liées à partir des résultats de recherche d'images, les titres d'images similaires, les titres de produits associés et les descriptions d'images
Tout d'abord, nous fournirons aux utilisateurs un ensemble d'outils disponibles, notamment PALI, PALM et la recherche sur le Web. Ensuite, nous montrons l'image d'entrée, la question, le recadrage de l'objet détecté, les entités du graphique de connaissances liées à partir des résultats de recherche d'images, les titres d'images similaires, les titres de produits associés et les descriptions d'images
Ensuite, les chercheurs enregistrent les opérations et les sorties des utilisateurs, et utilise deux méthodes pour guider le système à répondre :
1. Construisez un graphe de transition en analysant la séquence de décisions prises par l'utilisateur, qui contient différents états et l'ensemble des opérations disponibles dans chaque état. Tous différents.
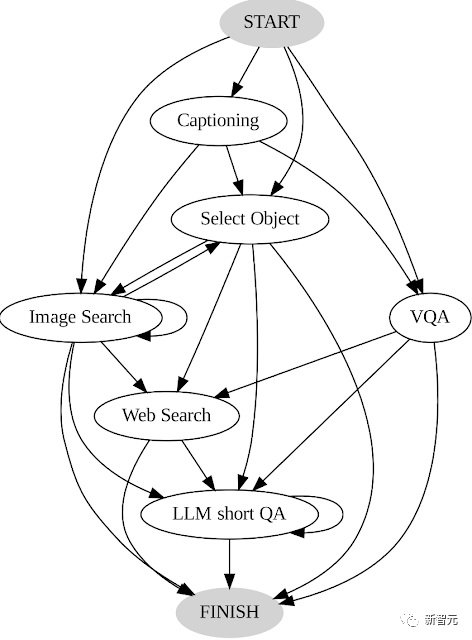 Contenu réécrit : diagramme de conversion AVIS
Le diagramme de conversion AVIS repensé est une représentation graphique utilisée pour illustrer le processus de conversion AVIS. Ce diagramme illustre clairement les différentes étapes et étapes d'AVIS et les présente à l'utilisateur d'une manière facile à comprendre. Grâce à ce diagramme de conversion, les utilisateurs peuvent mieux comprendre le principe de fonctionnement et le processus de fonctionnement d'AVIS. La conception de ce graphique est concise et claire, permettant aux utilisateurs de comprendre rapidement le processus de conversion AVIS. Les utilisateurs débutants et expérimentés peuvent facilement comprendre et appliquer le processus de conversion grâce à ce diagramme de conversion AVIS
Contenu réécrit : diagramme de conversion AVIS
Le diagramme de conversion AVIS repensé est une représentation graphique utilisée pour illustrer le processus de conversion AVIS. Ce diagramme illustre clairement les différentes étapes et étapes d'AVIS et les présente à l'utilisateur d'une manière facile à comprendre. Grâce à ce diagramme de conversion, les utilisateurs peuvent mieux comprendre le principe de fonctionnement et le processus de fonctionnement d'AVIS. La conception de ce graphique est concise et claire, permettant aux utilisateurs de comprendre rapidement le processus de conversion AVIS. Les utilisateurs débutants et expérimentés peuvent facilement comprendre et appliquer le processus de conversion grâce à ce diagramme de conversion AVIS
Par exemple, dans l'état de démarrage, le système ne peut effectuer que trois opérations : description PALI, PALI VQA ou détection de cible.
Pour améliorer les performances et l'efficacité du système, des exemples de prise de décision humaine peuvent être utilisés pour guider le planificateur et le raisonneur dans leur interaction avec les instances contextuelles pertinentes
Cadre global
L'approche AVIS adopte une décision dynamique -élaborer des stratégies conçues pour répondre aux requêtes d'informations visuelles
Le système se compose de trois éléments principaux :
Le contenu qui doit être réécrit est : 1. Planificateur (planificateur), utilisé pour déterminer les opérations ultérieures, y compris les appels d'API appropriés et les requêtes qui doivent être traitées
2. Mémoire de travail (mémoire de travail) mémoire de travail, conservé les informations sur les résultats obtenues à partir de l’exécution de l’API.
3. Le raisonneur est utilisé pour traiter la sortie de l'appel API et peut déterminer si les informations obtenues sont suffisantes pour générer la réponse finale, ou si une récupération de données supplémentaire est nécessaire
Vous devez décider quel outil à utiliser à chaque fois En plus des requêtes envoyées au système, le planificateur effectuera une série d'opérations en fonction de l'état actuel, le planificateur fournira également des actions de suivi potentielles
Afin de résoudre le problème ; que l'espace de recherche est trop grand en raison d'un trop grand nombre d'espaces d'action potentiels. Le problème est que le planificateur doit se référer au graphe de transition pour éliminer les actions non pertinentes, à l'exclusion des actions qui ont été prises auparavant et stockées dans la mémoire de travail.
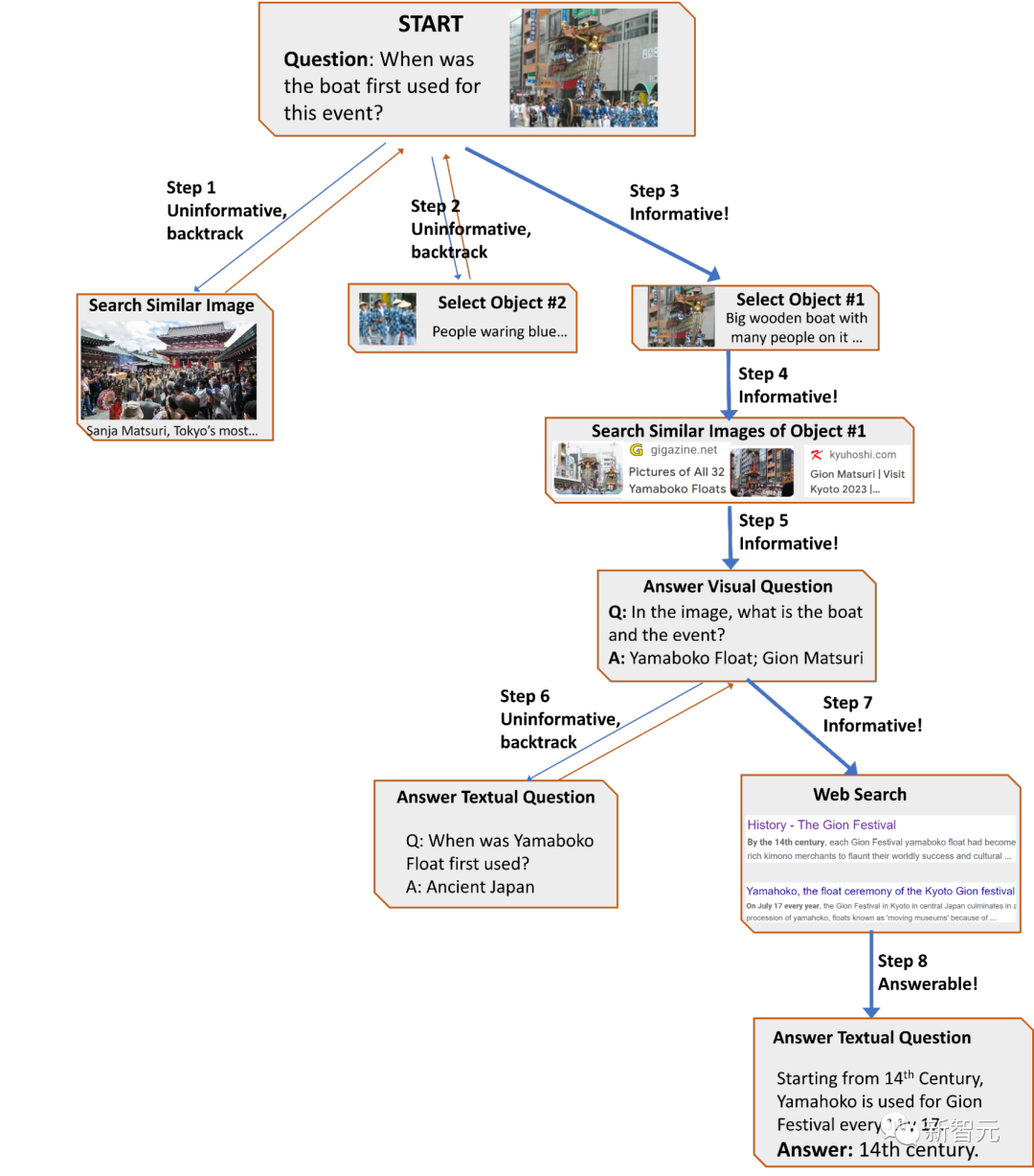
Ensuite, le planificateur rassemble un ensemble d'exemples de contexte à partir des données de recherche des utilisateurs, combinés aux enregistrements des interactions précédentes avec l'outil, le planificateur formule des invites et les saisit dans le modèle de langage, et le LLM renvoie une réponse structurée. , détermine le prochain outil à activer et la requête à envoyer.
L'ensemble du processus de conception peut être piloté par plusieurs appels au planificateur pour prendre des décisions dynamiques et générer des réponses étape par étape

Les chercheurs utilisent des raisonneurs pour analyser le résultat de l'exécution de l'outil, extraire des informations utiles et décider Catégorie de sortie de l'outil : informatif, non informatif ou réponse finale
Si le raisonneur renvoie un résultat de "fournir une réponse", il sera affiché directement comme résultat final et mettra fin à la tâche si le résultat n'est aucune information, il reviendra à la planification et sélectionne une autre action en fonction de l'état actuel ; si le raisonneur considère que le résultat de l'outil est utile, il modifie l'état et transfère le contrôle au planificateur pour prendre une nouvelle décision dans le nouvel état.
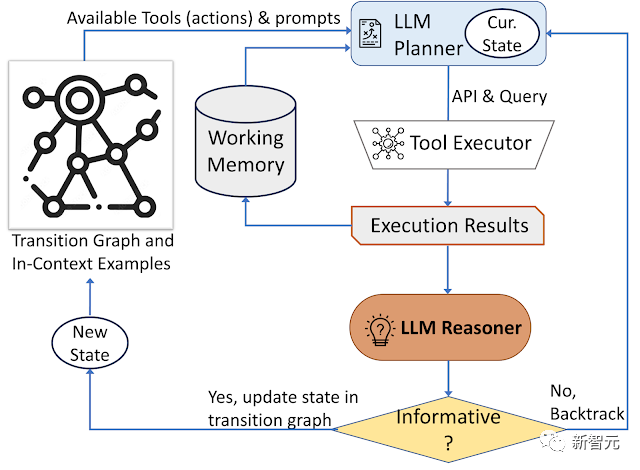
AVIS adopte une stratégie de prise de décision dynamique pour répondre aux requêtes de recherche d'informations visuelles
Résultats expérimentaux
Ce qui doit être réécrit est : Ensemble d'outils
Utilisation du modèle PALI 17B , le modèle de description d'image peut générer des descriptions pour les images d'entrée et les images recadrées d'objets détectés
Modèle de réponse visuelle aux questions, utilisant le modèle PALI 17B VQA, prenant des images et des questions en entrée et des réponses textuelles en sortie.
Détection d'objets, à l'aide d'un détecteur d'objets formé sur un sur-ensemble de l'ensemble de données Open Images, fourni par l'API Google Lens spécifique à la catégorie en utilisant un seuil de confiance élevé, ne conservant que les cases de détection les mieux classées dans l'image d'entrée ;
Utilisez Google Image Search pour obtenir des informations de recadrage d'image liées aux cases détectées
Lors de la prise de décisions, le planificateur traite l'utilisation de chaque élément d'information comme une opération distincte, car chaque information peut contenir des centaines de jetons, ce qui nécessite un traitement et un raisonnement complexes.
Dans certains cas, les images peuvent contenir du contenu textuel, tel que des noms de rues ou des noms de marques. Vous pouvez utiliser la fonction de reconnaissance optique de caractères (OCR) de l'API Google Lens pour extraire ces textes
En utilisant l'API de recherche Google pour les recherches sur le Web, vous pouvez saisir une requête de texte et obtenir le résultat de liens et d'extraits de documents pertinents. tout en pouvant également fournir un panneau de graphiques de connaissances avec des réponses directes et jusqu'à cinq questions liées à la requête d'entrée
Résultats expérimentaux
Les chercheurs ont mené des expériences sur le cadre AVIS sur les ensembles de données Infoseek et OK-VQA. Les résultats montrent que même les modèles de langage visuel très robustes tels que les modèles OFA et PALI ne peuvent pas atteindre une grande précision après un réglage fin sur l'ensemble de données Infoseek.
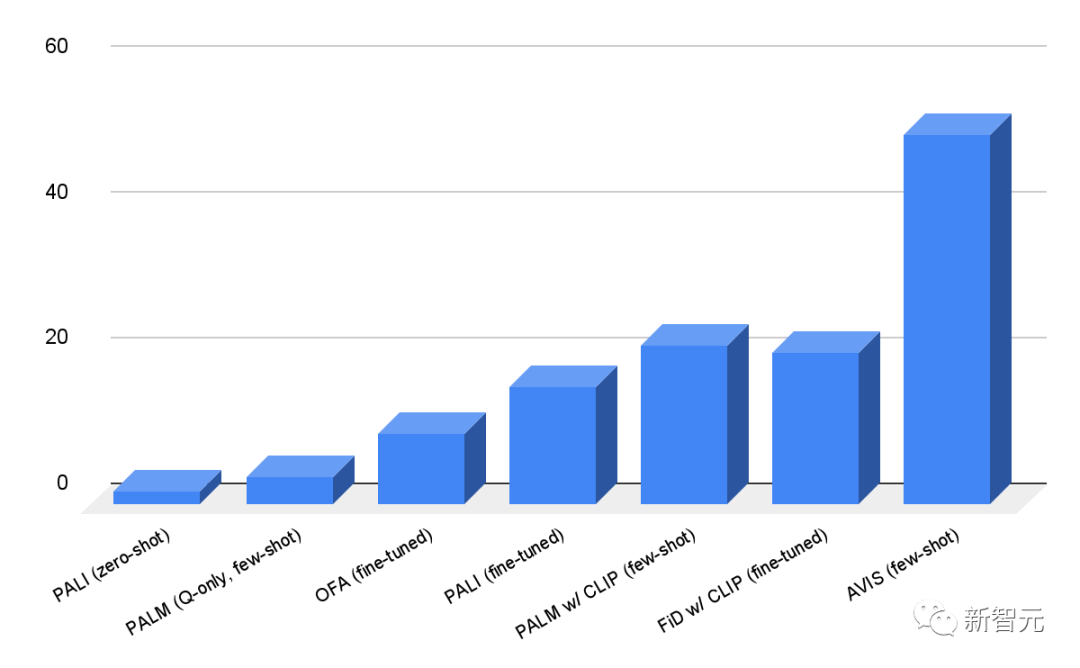
Sans réglage fin, la méthode AVIS a réussi à atteindre une précision de 50,7 %
Sur l'ensemble de données OK-VQA, le système AVIS a atteint une précision de 60,2 % dans le cadre de quelques tirs, juste derrière le modèle PALI affiné.

La plupart des exemples de questions et réponses dans OK-VQA reposent sur des connaissances de bon sens plutôt que sur des connaissances fines, donc la différence de performances peut être due à cela. PALI est capable d'exploiter les connaissances générales codées dans les paramètres du modèle sans compter sur l'aide de connaissances externes
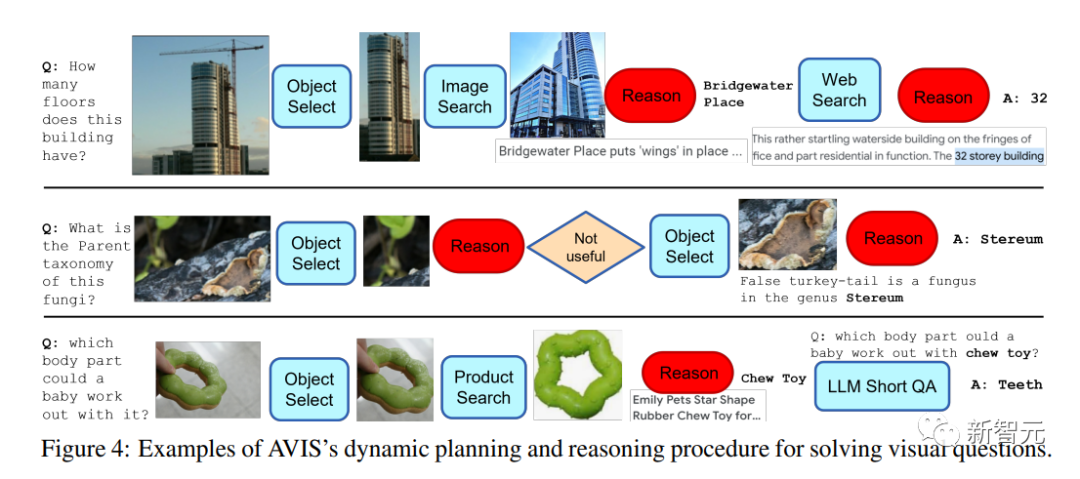
Une caractéristique clé d'AVIS est la capacité de prendre des décisions de manière dynamique plutôt que d'exécuter une séquence fixe à partir de ce qui précède. exemple L'exemple montre la flexibilité d'AVIS dans l'utilisation de différents outils à différentes étapes.
Il convient de noter que la conception du raisonneur dans cet article permet à AVIS d'identifier les informations non pertinentes, de revenir à l'état précédent et de répéter la recherche.
Par exemple, dans le deuxième exemple sur la taxonomie fongique, AVIS a initialement pris la mauvaise décision en sélectionnant l'objet feuille ; le raisonneur, le trouvant sans rapport avec le problème, a incité AVIS à replanifier, puis a réussi à sélectionner l'objet. qui était lié au problème. Objets liés au champignon de la fausse queue de dinde, arrivant ainsi à la bonne réponse, Stereum
Conclusion
Les chercheurs ont proposé une nouvelle méthode AVIS, utilisant LLM comme centre d'assemblage pour répondre aux connaissances en utilisant divers externes. outils Problèmes visuels intensifs.
Dans cette approche, les chercheurs choisissent d'utiliser les données de prise de décision humaine collectées à partir d'études d'utilisateurs comme points d'ancrage, d'adopter un cadre structuré et d'utiliser un planificateur basé sur LLM pour décider dynamiquement de la sélection des outils et de la formation des requêtes
Le Le raisonneur piloté par LLM peut traiter et extraire des informations clés de la sortie de l'outil sélectionné, en utilisant de manière itérative le planificateur et le raisonneur pour sélectionner différents outils jusqu'à ce que toutes les informations nécessaires requises pour répondre à la question visuelle soient collectées
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Quelles sont les couches du modèle de référence TCP/IP ?
- Quels sont les modèles courants de développement de logiciels ?
- IBM développe le supercalculateur d'IA cloud natif Vela pour déployer et former de manière flexible des dizaines de milliards de modèles de paramètres
- Du BERT à ChatGPT, un examen complet de neuf instituts de recherche de premier plan, dont l'Université de Beihang : le « modèle de base de pré-formation » que nous avons poursuivi ensemble au fil des ans
- Les modèles ChatGPT peuvent être directement formés ! East China Normal University et le framework open source HugNLP NUS : actualisez le classement en un clic et unifiez entièrement la formation en PNL