
Maison >développement back-end >Tutoriel Python >Crawler + Visualisation | Tableau de séquence de recherche chaude Python Zhihu/Weibo (Partie 1)
Crawler + Visualisation | Tableau de séquence de recherche chaude Python Zhihu/Weibo (Partie 1)

- Python当打之年avant
- 2023-08-10 15:53:101143parcourir
Ce numéro est une série d'articles dernier article Utilisez Python pour explorer régulièrement les données de la liste chaude Zhihu/Weibo et enregistrez-les dans un fichier CSV pour une visualisation ultérieure. La partie diagramme de chronométrage sera présentée dans la prochaine partie de , J'espère qu'elle vous sera utile.
read_html — Traitement des formulaires Web
import json import time import requests import schedule import pandas as pd from fake_useragent import UserAgent
https://www.zhihu.com/hot
https://api.zhihu.com/topstory/hot-list?limit=10&reverse_order=0
注意:电脑端端直接F12调试页即可看到热榜数据,手机端需要借助抓包工具查看,这里我们使用手机端接口(返回json格式数据,解析比较方便)。
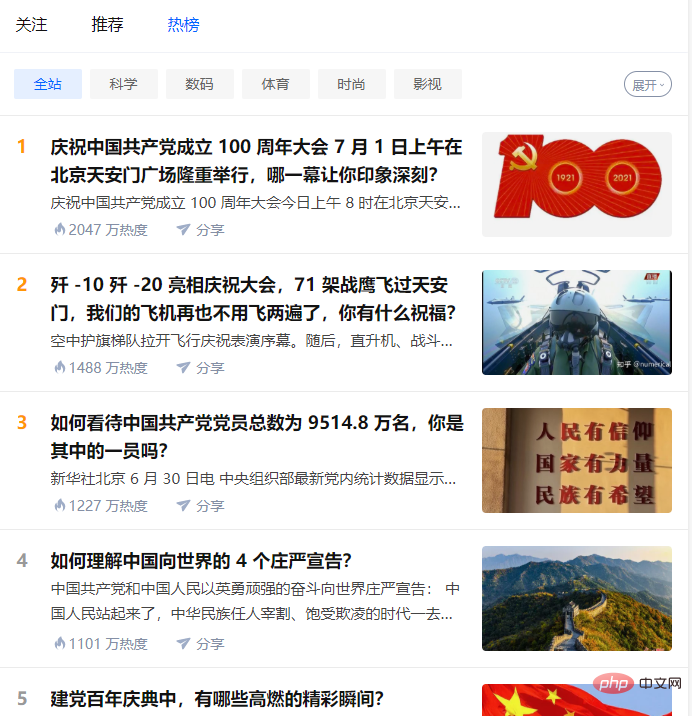
Code :
def getzhihudata(url, headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
datas = json.loads(r.text)['data']
allinfo = []
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
for indx,item in enumerate(datas):
title = item['target']['title']
heat = item['detail_text'].split(' ')[0]
answer_count = item['target']['answer_count']
follower_count = item['target']['follower_count']
href = item['target']['url']
info = [time_mow, indx+1, title, heat, answer_count, follower_count, href]
allinfo.append(info)
# 仅首次加表头
global csv_header
df = pd.DataFrame(allinfo,columns=['时间','排名','标题','热度(万)','回答数','关注数','链接'])
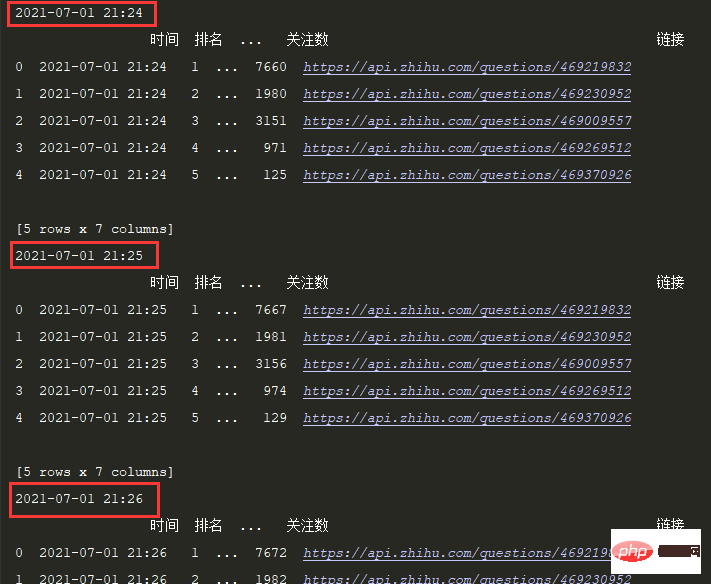
print(df.head())定时间隔设置1S:
# 每1分钟执行一次爬取任务:
schedule.every(1).minutes.do(getzhihudata,zhihu_url,headers)
while True:
schedule.run_pending()
time.sleep(1)效果:
2.3 保存数据
df.to_csv('zhuhu_hot_datas.csv', mode='a+', index=False, header=csv_header) csv_header = False
3.1 Analyse des pages Web
Weibo chaude URL de recherche :
https://s.weibo.com/top/summary
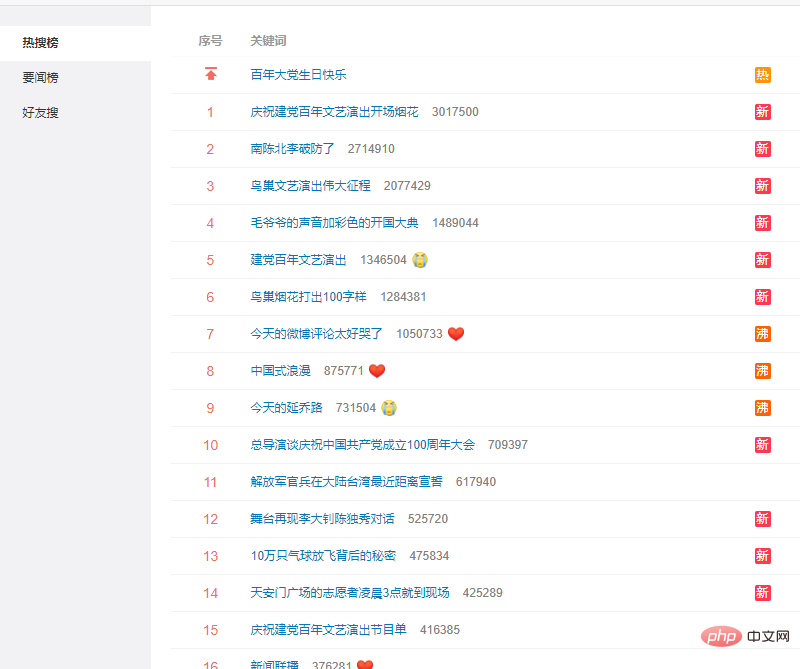
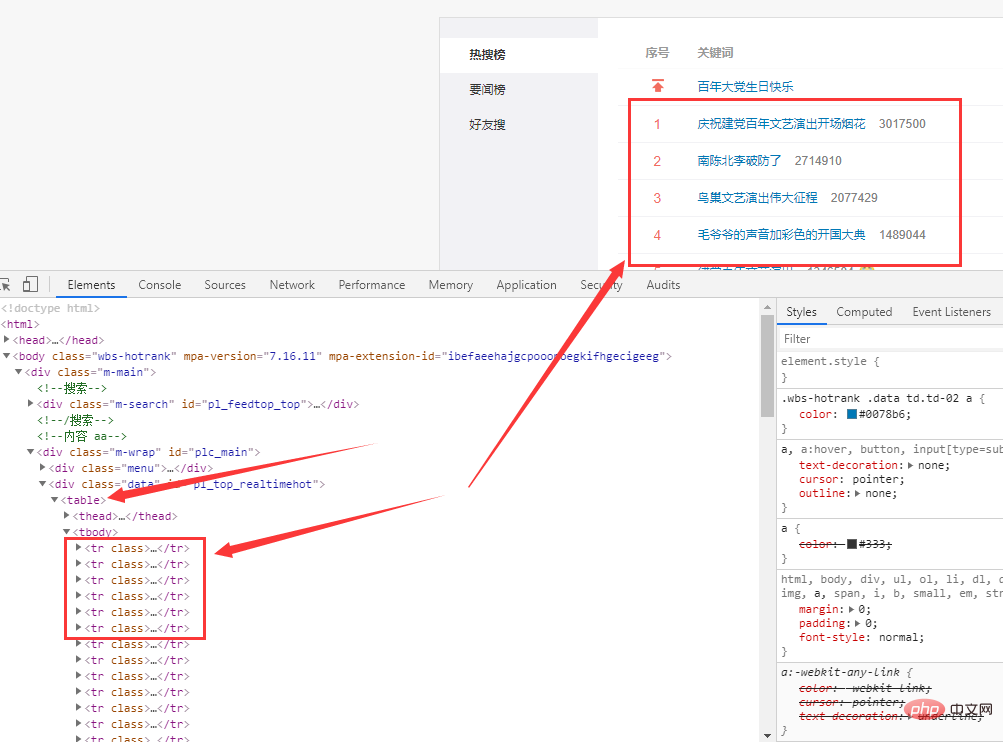
Les données sont dans le & lt; table & gt; tag .
3.2 Obtenir des données
代码:
def getweibodata():
url = 'https://s.weibo.com/top/summary'
r = requests.get(url, timeout=10)
r.encoding = r.apparent_encoding
df = pd.read_html(r.text)[0]
df = df.loc[1:,['序号', '关键词']]
df = df[~df['序号'].isin(['•'])]
time_mow = time.strftime("%Y-%m-%d %H:%M", time.localtime())
print(time_mow)
df['时间'] = [time_mow] * df.shape[0]
df['排名'] = df['序号'].apply(int)
df['标题'] = df['关键词'].str.split(' ', expand=True)[0]
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df = df[['时间','排名','标题','热度']]
print(df.head())定时间隔设置1S,效果:
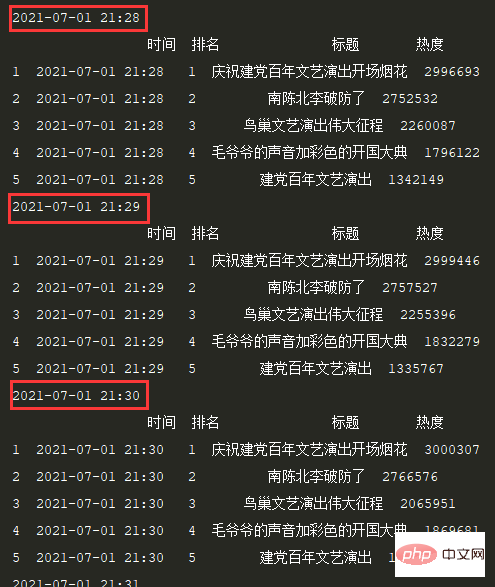
3.3 保存数据
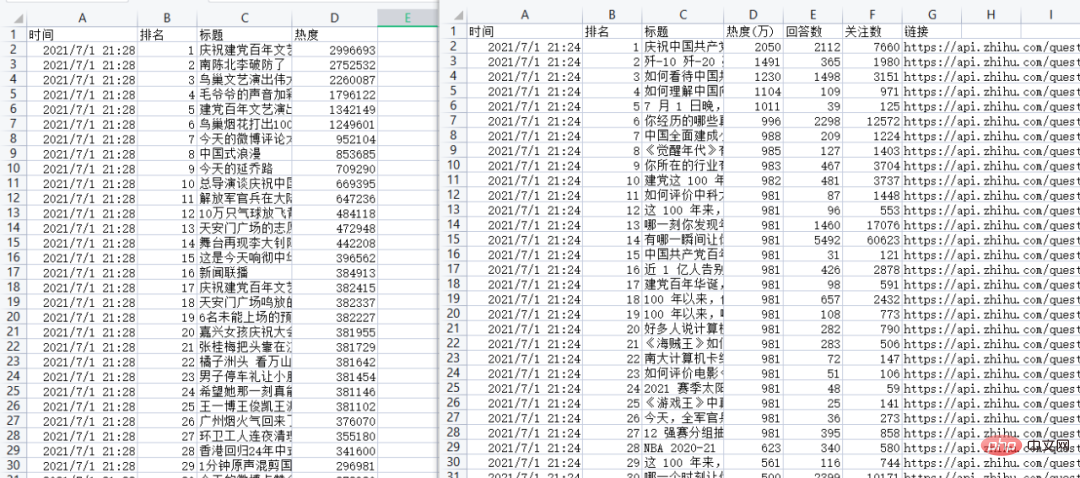
df.to_csv('weibo_hot_datas.csv', mode='a+', index=False, header=csv_header)
结果:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!