
Maison >Périphériques technologiques >IA >Le dernier modèle de synthèse vocale NaturalSpeech2 de Microsoft : fournit une reconstruction vocale plus précise et évite les effets de lecture bâton
Le dernier modèle de synthèse vocale NaturalSpeech2 de Microsoft : fournit une reconstruction vocale plus précise et évite les effets de lecture bâton

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-08-04 09:41:051152parcourir

News le 27 juillet, Microsoft a récemment lancé un modèle vocal appelé NaturalSpeech2 Le modèle adopte une conception de « diffusion potentielle » et a des résultats exceptionnels au niveau de la synthèse vocale à échantillon nul. Microsoft affirme que le modèle fournit " " Commercial. -grade" peut offrir aux utilisateurs une expérience de synthèse vocale diversifiée et de haute qualité.
Microsoft a mené une série de démonstrations montrant la capacité de NaturalSpeech2 à générer de la parole avec différentes identités de locuteurs, prosodies et styles (comme le chant) sans échantillons

▲ La source de l'image provient de l'article NaturalSpeech 2
Il est rapporté que, contrairement aux systèmes traditionnels de synthèse vocale (TTS), NaturalSpeech2 de Microsoft utilise des « vecteurs continus » au lieu de « marqueurs discrets » pour représenter la parole, générant ainsi des segments de parole plus complets, sans produire de « manque d'émotion ». bâton de lecture (parlant mot à mot)".
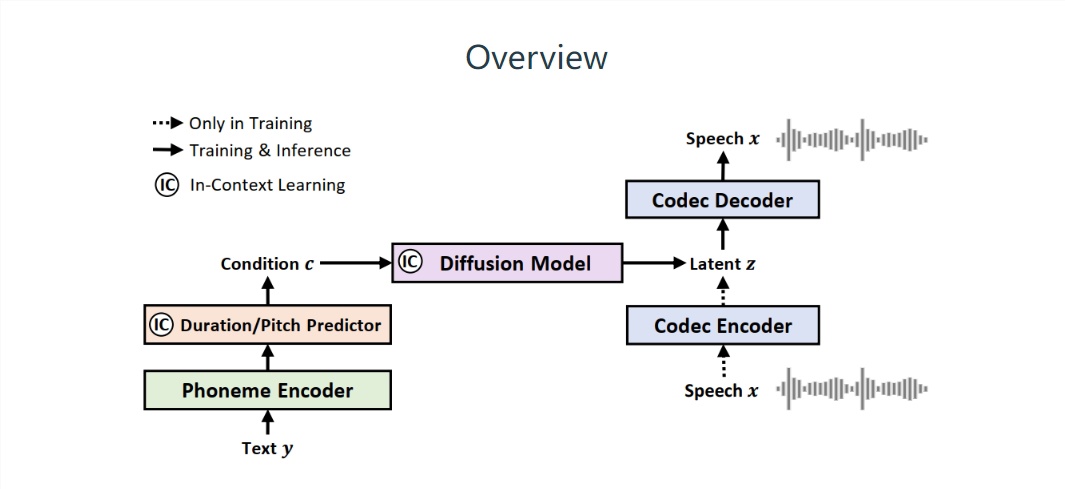
▲ La source de l'image provient de l'article NaturalSpeech 2.
Les résultats expérimentaux montrent que la parole générée par NaturalSpeech2 dans des conditions d'échantillonnage nul est presque cohérente avec la prosodie des invites vocales et de la parole réelle, et est naturelle sur le LibriTTS. et les ensembles de tests VCTK. Le degré (mesuré en CMOS) est impossible à distinguer de la parole humaine .
L'article sur ce projet a été publié sur GitHub. Les amis IT House intéressés peuvent cliquer ici pour visiter.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Analyse de l'architecture des microservices Microsoft eShopOnContainers
- Quels sont les deux domaines de recherche de l'intelligence artificielle ?
- qu'est-ce que Microsoft One Drive
- Quel est le format de streaming vidéo introduit par Microsoft ?
- Quels sont les deux domaines les plus importants et les plus vastes de la recherche appliquée en intelligence artificielle ?