
Maison >Problème commun >Questions incontournables lors des entretiens : que se passe-t-il entre la saisie de l'URL et l'affichage de la page ?
Questions incontournables lors des entretiens : que se passe-t-il entre la saisie de l'URL et l'affichage de la page ?
- Java学习指南avant
- 2023-07-26 17:01:372217parcourir
J'étais assez confus lorsque j'ai commencé à écrire cet article, car vous pouvez trouver beaucoup d'informations en recherchant en ligne "ce qui se passe entre la saisie de l'URL et l'affichage de la page". De plus, cette question d'entretien est fondamentalement une question obligatoire. Lors de l'entretien de février, même si je savais ce qui s'était passé au cours du processus, lorsque l'intervieweur a continué à poser des questions étape par étape, de nombreux détails n'étaient pas clairs.
Le but de cet article est de résumer et d'élargir les connaissances à travers ce qui se passe après la saisie de l'URL. L'article risque donc d'être compliqué.
Le processus global est le suivant :
1. Entrez l'adresse
Lorsque nous commençons à saisir l'URL dans le navigateur, le navigateur correspond déjà intelligemment à l'URL possible, et il commencera à partir de Dans les enregistrements de l'historique, les signets, etc., recherchez l'URL qui peut correspondre à la chaîne saisie, puis envoyez des invites intelligentes afin que vous puissiez compléter l'adresse URL. Pour le navigateur Chrome de Google, il affichera même la page Web directement depuis le cache, c'est-à-dire que la page sortira avant que vous appuyiez sur Entrée.
2. Le navigateur recherche l'adresse IP du nom de domaine
1. Une fois la demande lancée, la première chose que fait le navigateur est de résoudre le nom de domaine. De manière générale, le navigateur vérifiera d'abord les hôtes. du disque dur local pour voir Y a-t-il des règles correspondant à ce nom de domaine Si oui, utilisez directement l'adresse IP dans le fichier hosts.
2. Si l'adresse IP correspondante est introuvable dans le fichier d'hôtes local, le navigateur enverra une requête DNS au serveur DNS local. Les serveurs DNS locaux sont généralement fournis par votre fournisseur de serveur d'accès réseau, tel que China Telecom et China Mobile.
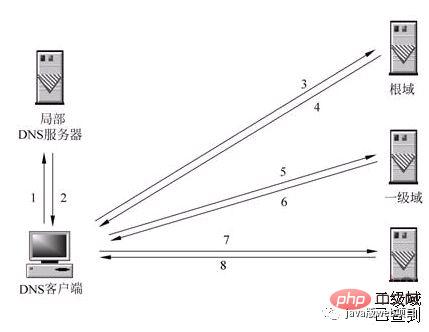
3. Une fois que la requête DNS pour l'URL que vous avez saisie atteint le serveur DNS local, le serveur DNS local interrogera d'abord son enregistrement de cache. S'il y a cet enregistrement dans le cache, le résultat peut être renvoyé directement par ce processus. est une manière récursive d’interroger. Sinon, le serveur DNS local interrogera également le serveur racine DNS.
4. Le serveur DNS racine n'enregistre pas la correspondance spécifique entre les noms de domaine et les adresses IP, mais indique au serveur DNS local que vous pouvez accéder au serveur de domaine pour continuer l'interrogation et donner l'adresse du serveur de domaine. Ce processus est itératif.
5. Le serveur DNS local continue d'envoyer des requêtes au serveur de domaine. Dans cet exemple, l'objet de requête est le serveur de domaine .com. Une fois que le serveur de domaine .com aura reçu la demande, il ne renverra pas directement la correspondance entre le nom de domaine et l'adresse IP, mais indiquera au serveur DNS local l'adresse du serveur de résolution de votre nom de domaine.
6. Enfin, le serveur DNS local envoie une requête au serveur de résolution de nom de domaine, puis reçoit une correspondance entre le nom de domaine et l'adresse IP. Le serveur DNS local renvoie non seulement l'adresse IP à l'ordinateur de l'utilisateur, mais également. renvoie également cette correspondance, enregistrez-la dans le cache afin que la prochaine fois qu'un autre utilisateur interrogera, les résultats puissent être renvoyés directement pour accélérer l'accès au réseau.
L'image ci-dessous explique parfaitement ce processus :

Élargissement des connaissances :
1) Qu'est-ce que le DNS ?
DNS (Domain Name System, Domain Name System), en tant que base de données distribuée sur Internet qui mappe les noms de domaine et les adresses IP les uns aux autres, permet aux utilisateurs d'accéder à Internet plus facilement sans avoir à se souvenir ce qui peut être utilisé La chaîne du numéro IP lue directement par la machine. Le processus permettant d'obtenir finalement l'adresse IP correspondant au nom d'hôte via le nom d'hôte est appelé résolution de nom de domaine (ou résolution de nom d'hôte).
En termes simples, nous sommes plus habitués à mémoriser le nom d'un site Web, tel que www.baidu.com, plutôt que de mémoriser son adresse IP, telle que : 167.23.10.2. Et les ordinateurs mémorisent mieux l’adresse IP d’un site Web que des liens comme www.baidu.com. Parce que DNS est équivalent à un annuaire téléphonique. Par exemple, si vous recherchez le nom de domaine www.baidu.com, alors je regarde dans mon annuaire téléphonique et je saurai, oh, son numéro de téléphone (IP) est 167.23.10.2. .
2) Deux méthodes de requête DNS : requête récursive et requête itérative
1. Analyse récursive
Lorsque le serveur DNS local lui-même ne peut pas répondre à la requête DNS du client, vous devez le faire. interroger d’autres serveurs DNS. Il existe actuellement deux méthodes. Celle illustrée dans la figure est la méthode récursive. Le serveur DNS local est chargé d'interroger les autres serveurs DNS. Généralement, il interroge d'abord le serveur de domaine racine du nom de domaine, puis le serveur de noms de domaine racine interroge vers le bas un niveau à la fois. Le résultat final de la requête est renvoyé au serveur DNS local, puis le serveur DNS local le renvoie au client.

2. Analyse itérative
Lorsque le serveur DNS local lui-même ne peut pas répondre à la requête DNS du client, il peut également être résolu via une requête itérative, comme le montre la figure. Le serveur DNS local n'interroge pas lui-même les autres serveurs DNS, mais renvoie les adresses IP des autres serveurs DNS capables de résoudre le nom de domaine au programme DNS client. Le programme DNS client continue ensuite d'interroger ces serveurs DNS jusqu'à ce que les résultats de la requête soient disponibles. obtenu jusqu'à. En d’autres termes, l’analyse itérative vous aide uniquement à trouver les serveurs pertinents, mais ne vous aidera pas à les vérifier. Par exemple : l'adresse IP du serveur baidu.com est ici 192.168.4.5. Vous pouvez la vérifier vous-même. Je suis très occupé, je ne peux donc que vous aider ici.
3) Comment l'espace des noms de domaine DNS est organisé
Nous avons mentionné plus tôt le serveur DNS racine et le serveur DNS du domaine. C'est ainsi que l'espace des noms de domaine DNS est organisé. Les cinq catégories utilisées pour décrire les noms de domaine DNS dans l'espace de noms en fonction de leurs fonctions sont présentées dans le tableau ci-dessous, ainsi que des exemples de chaque type de nom
 (Stealed Picture)
(Stealed Picture)
4) DNS Load Balancing
Lorsqu'un site web compte suffisamment d'utilisateurs, si les ressources demandées à chaque fois se trouvent sur la même machine, alors la machine peut planter à tout moment. La solution consiste à utiliser la technologie d'équilibrage de charge DNS. Son principe est de configurer plusieurs adresses IP pour le même nom d'hôte dans le serveur DNS. Lors de la réponse aux requêtes DNS, le serveur DNS répondra à chaque requête avec l'adresse IP enregistrée par l'hôte. dans le fichier DNS. Renvoyez différents résultats d'analyse dans l'ordre, guidez l'accès des clients à différentes machines, de sorte que différents clients accèdent à différents serveurs, réalisant ainsi un équilibrage de charge. Par exemple, en fonction de la charge de chaque machine, la distance entre la machine et la machine. l'utilisateur peut être la distance géographique, etc.
3. Le navigateur envoie une requête HTTP au serveur web
Après avoir obtenu l'adresse IP correspondant au nom de domaine, le navigateur utilisera un port aléatoire (102434b728c6e085ca021ee9fda229c82e6b Créer une arborescence de rendu-> Disposition d'une arborescence de rendu-> Dessiner une arborescence de rendu
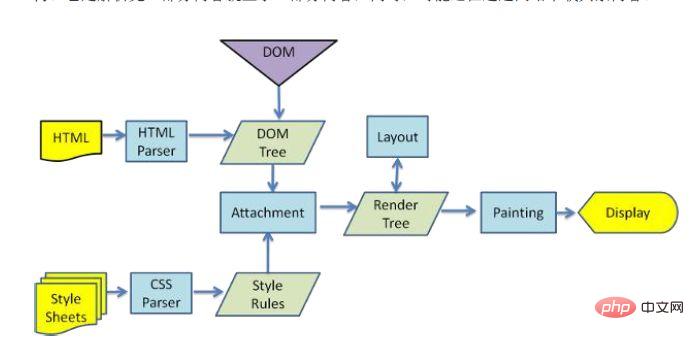
Lorsque le navigateur analyse le fichier HTML, il sera chargé "de haut en bas". . Et effectuez l'analyse et le rendu pendant le processus de chargement. Pendant le processus d'analyse, s'il y a une demande de ressources externes, telles que des images, un lien externe CSS, une police d'icônes, etc., le processus de demande est asynchrone et n'affectera pas le chargement du document HTML.
Pendant le processus d'analyse, le navigateur analysera d'abord le fichier HTML pour créer une arborescence DOM, puis analysera le fichier CSS pour créer une arborescence de rendu. Une fois l'arborescence de rendu créée, le navigateur commence à présenter le rendu. arbre et dessinez-le sur l’écran. Ce processus est relativement complexe et implique deux concepts : refusion et repeinture.
Chaque élément du nœud DOM existe sous la forme d'un modèle de boîte, ce qui nécessite que le navigateur calcule sa position et sa taille. Ce processus est appelé relow lorsque la position, la taille et d'autres attributs du modèle de boîte, tels que. as Une fois la couleur, la police, etc. déterminées, le navigateur commence à dessiner le contenu. Ce processus est appelé repeindre.
La page sera inévitablement redistribuée et repeinte lorsqu'elle sera chargée pour la première fois. Le processus de redistribution et de réparation consomme beaucoup de performances, en particulier sur les appareils mobiles. Il détruira l'expérience utilisateur et provoquera parfois le blocage de la page. Nous devrions donc réduire le reflux et repeindre le moins possible.
Lorsqu'un fichier js est rencontré lors du chargement d'un document, le document HTML suspendra le thread de rendu (chargement, analyse et synchronisation du rendu), n'attendant pas seulement que le fichier js dans le document soit chargé , mais aussi attendre que l'analyse soit exécutée. Une fois terminé, le fil de rendu du document html peut être repris. Étant donné que JS peut modifier le DOM, le documentwrite le plus classique, cela signifie que le téléchargement ultérieur de toutes les ressources peut ne pas être nécessaire avant la fin de l'exécution de JS. C'est la raison fondamentale pour laquelle js bloque les téléchargements ultérieurs de ressources. Je comprends donc que dans le code habituel, js est placé à la fin du document html.
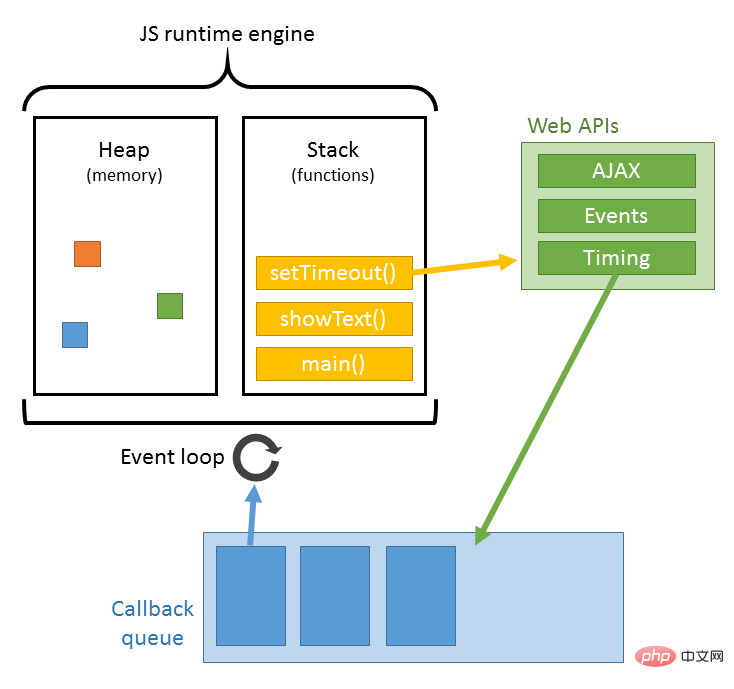
L'analyse JS est complétée par le moteur d'analyse JS du navigateur, tel que le V8 de Google. JS s'exécute dans un seul thread, ce qui signifie qu'il ne peut faire qu'une seule chose à la fois. Toutes les tâches doivent être mises en file d'attente. La tâche précédente se termine avant que la suivante puisse démarrer. Cependant, certaines tâches prennent du temps, telles que la lecture et l'écriture des E/S, etc., un mécanisme est donc nécessaire pour exécuter en premier les tâches ultérieures, à savoir : les tâches synchrones (synchrones) et les tâches asynchrones (asynchrones).
Le mécanisme d'exécution de JS peut être considéré comme un thread principal plus une file d'attente de tâches. Les tâches synchrones sont des tâches exécutées sur le thread principal et les tâches asynchrones sont des tâches placées dans la file d'attente des tâches. Toutes les tâches synchrones sont exécutées sur le thread principal, formant une pile d'exécution ; une tâche asynchrone placera un événement dans la file d'attente des tâches lorsqu'elle aura le résultat en cours d'exécution, lorsque le script est en cours d'exécution, elle exécutera d'abord la pile d'exécution en séquence, et puis extrayez l'événement de la file d'attente des tâches et exécutez-le. Pour les tâches de la file d'attente des tâches, ce processus est répété en continu, c'est pourquoi il est également appelé boucle d'événements. Pour le processus spécifique, vous pouvez lire mon article : Cliquez ici
9. Le navigateur envoie une requête pour obtenir des ressources intégrées au HTML (telles que des images, de l'audio, de la vidéo, du CSS, du JS, etc.)
En fait, cette étape peut être mise en parallèle à l'étape 8. Lorsque le navigateur affiche du HTML , il remarquera la nécessité d'obtenir des balises pour d'autres contenus d'adresse. À ce stade, le navigateur enverra une requête get pour récupérer les fichiers. Par exemple, je souhaite obtenir des images externes, des fichiers CSS, JS, etc., similaires au lien suivant :
Picture : http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/ 8q2anwu7.gif
Feuille de style CSS : http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
Fichier JavaScript : http://static.ak.fbcdn. net/rsrc.php/zEMOA/hash/c8yzb6ub.js
Ces adresses doivent passer par un processus similaire à la lecture HTML. Ainsi le navigateur va rechercher ces noms de domaine dans DNS, envoyer des requêtes, rediriger etc...
Contrairement aux pages dynamiques, les fichiers statiques permettront au navigateur de les mettre en cache. Certains fichiers n'ont peut-être pas besoin de communiquer avec le serveur, mais peuvent être lus directement depuis le cache, ou peuvent être placés dans un CDN
À ce stade, le processus depuis la saisie de l'URL jusqu'à l'affichage de la page est enfin terminé. Bien sûr, le style d'écriture est limité et il y a des erreurs. Vous êtes invités à souligner que cet article fait référence à de nombreux articles, mais je ne me souviens pas des liens vers de nombreux articles, je ne liste donc que les trois liens de référence suivants.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Vraie question d'entretien : veuillez parler du mécanisme CAS en simultanéité
- L'intervieweur vous demande : Savez-vous ce qu'est un problème ABA ?
- Une question posée dans presque toutes les interviews Java : dites-moi la différence entre ArrayList et LinkedList
- Intervieweur : Que savez-vous de la haute simultanéité ? Moi : euh...