
Maison >Java >JavaQuestions d'entretien >Intervieweur : Que savez-vous de la haute simultanéité ? Moi : euh...
Intervieweur : Que savez-vous de la haute simultanéité ? Moi : euh...
- Java学习指南avant
- 2023-07-26 16:07:261262parcourir

La haute concurrence est une expérience que presque tous les programmeurs souhaitent vivre. La raison est simple : à mesure que le trafic augmente, divers problèmes techniques seront rencontrés, tels qu'un délai de réponse de l'interface, une charge CPU accrue, des GC fréquents, des blocages, un stockage de données volumineux, etc. Ces problèmes peuvent nous pousser à nous améliorer continuellement notre profondeur technique.
Lors des entretiens précédents, si le candidat a travaillé sur un projet à haute concurrence, je demande généralement au candidat de parler de sa compréhension de la haute concurrence, mais peu de gens peuvent répondre systématiquement à cette question, probablement divisé en catégories suivantes :
1. Aucun concept d'indicateurs basés sur des données : Vous ne savez pas quel type d'indicateurs choisir pour mesurer les systèmes à haute concurrence ? Je ne peux pas faire la différence entre la simultanéité et le QPS, et je ne connais même pas le nombre total d'utilisateurs de mon système, le nombre d'utilisateurs actifs, le QPS et le TPS pendant les heures fixes et de pointe, ainsi que d'autres données clés.
2. Certains plans ont été conçus, mais les détails ne sont pas entièrement compris : Je ne peux pas vous indiquer les points techniques auxquels il faut prêter attention et les effets secondaires possibles du plan. Par exemple, s'il existe un goulot d'étranglement dans les performances de lecture, la mise en cache sera introduite, mais les problèmes tels que le taux d'accès au cache, les raccourcis clavier et la cohérence des données sont ignorés. 3. Compréhension unilatérale, assimilant la conception à haute concurrence à l'optimisation des performances : parle de programmation simultanée, de mise en cache multi-niveaux, d'asynchronisation et d'expansion horizontale, mais ignore la conception à haute disponibilité, la gouvernance des services, le fonctionnement et garanties d'entretien. 4. Maîtrisez le grand plan, mais ignorez les choses les plus élémentaires : Peut expliquer clairement les grandes idées telles que la superposition verticale, le partitionnement horizontal, la mise en cache, mais n'a aucune conscience pour analyser si la structure des données est raisonnable et l'algorithme, qu'il soit efficace ou non, je n'ai jamais pensé à optimiser les détails des deux dimensions les plus fondamentales des E/S et de l'informatique. Dans cet article, je souhaite combiner mon expérience dans des projets à haute concurrence pour résumer systématiquement les connaissances et les idées pratiques qui doivent être maîtrisées en haute concurrence. J'espère que cela vous sera utile. Le contenu est divisé en 3 parties suivantes : Une concurrence élevée signifie un trafic important, et des moyens techniques doivent être utilisés pour résister à l'impact du trafic. Ces moyens sont comme l'exploitation du trafic, permettant au trafic d'être traité plus facilement par le système et offrant aux utilisateurs une meilleure expérience. Nos scénarios courants à haute concurrence incluent : le Double 11 de Taobao, la récupération de billets pendant la Fête du Printemps, les nouvelles brûlantes de Weibo Vs, etc. En plus de ces éléments typiques, les systèmes de vente flash avec des centaines de milliers de demandes par seconde, les systèmes de commande avec des dizaines de millions de commandes par jour, les systèmes de flux d'informations avec des centaines de millions d'actifs quotidiens par jour, etc., peuvent tous être classés. comme une concurrence élevée. Évidemment, pour les scénarios de simultanéité élevée mentionnés ci-dessus, le degré de simultanéité varie Alors, quel degré de simultanéité est considéré comme une simultanéité élevée ? 1. Vous ne pouvez pas vous contenter de regarder des chiffres, vous devez examiner des scénarios commerciaux spécifiques. On ne peut pas dire que la vente flash de 10 W QPS est une simultanéité élevée, mais le flux d'informations de 1 W QPS n'est pas une simultanéité élevée. Le scénario de flux d'informations implique des modèles de recommandation complexes et diverses stratégies manuelles, et sa logique métier peut être plus de 10 fois plus complexe que le scénario de vente flash. Ils ne sont donc pas dans la même dimension et n’ont aucune signification comparative. 2. Les affaires se construisent de 0 à 1. La concurrence et le QPS ne sont que des indicateurs de référence. La chose la plus importante est la suivante : lorsque le volume d'affaires devient progressivement 10 ou 100 fois, utilisez-vous une concurrence élevée. méthodes de traitement, comment faire évoluer votre système et prévenir et résoudre les problèmes causés par une concurrence élevée depuis les dimensions de la conception de l'architecture, de la mise en œuvre du codage et même des solutions de produits ? Au lieu de mettre à niveau aveuglément le matériel et d’ajouter des machines pour une expansion horizontale. De plus, les caractéristiques commerciales de chaque scénario à forte concurrence sont complètement différentes : il existe des scénarios de flux d'informations avec plus de lecture et moins d'écriture, et il existe des scénarios de transaction avec plus de lecture et d'écriture Y a-t-il. une solution technique universelle pour résoudre différents scénarios ? Qu'en est-il du problème de la haute concurrence ? Je pense que nous pouvons apprendre des grandes idées et des projets des autres, mais dans le processus de mise en œuvre réel, il y aura d'innombrables pièges dans les détails. De plus, étant donné que l'environnement logiciel et matériel, la pile technologique et la logique du produit ne peuvent pas être complètement cohérents, ceux-ci conduiront au même scénario commercial. Même si la même solution technique est utilisée, des problèmes différents seront rencontrés et ces pièges doivent être évités. être surmontés un à un. Par conséquent, dans cet article, je me concentrerai sur les connaissances de base, les idées générales et les expériences efficaces que j'ai pratiquées, dans l'espoir de vous donner une compréhension plus profonde de la haute simultanéité. Clarifiez d'abord les objectifs de la conception de systèmes à haute concurrence, puis discutez du plan de conception et de l'expérience pratique pour qu'ils soient significatifs et ciblés. Une concurrence élevée ne signifie pas seulement rechercher des performances élevées, qui est une compréhension unilatérale de nombreuses personnes. D'un point de vue macro, la conception de systèmes à haute concurrence vise trois objectifs : hauteperformance, haute disponibilité et haute évolutivité. 1. Hautes performances : Les performances reflètent la capacité de traitement parallèle du système avec un investissement matériel limité, améliorer les performances signifie économiser des coûts. Dans le même temps, les performances reflètent également l'expérience utilisateur. Les temps de réponse sont respectivement de 100 millisecondes et 1 seconde, ce qui donne aux utilisateurs des sentiments complètement différents. 2. Haute disponibilité : indique l'heure à laquelle le système peut fonctionner normalement. L'un n'a pas de temps d'arrêt ni de pannes toute l'année ; l'autre a des accidents et des temps d'arrêt en ligne de temps en temps. Les utilisateurs choisiront certainement le premier. De plus, si le système ne peut être disponible qu’à 90 %, cela entravera grandement l’activité. 3. Expansion élevée : indique l'évolutivité du système , si l'expansion peut être achevée en peu de temps pendant les heures de pointe et peut gérer plus facilement le trafic de pointe, comme les événements Double 11. , divorces de célébrités et autres événements chauds . Ces trois objectifs doivent être considérés de manière globale, car ils sont interdépendants et s'influencent même mutuellement. que comme : Considérez l'évolutivité du système , vous concevrez le service pour qu'il soit apatride , Ce genre de cluster Le designdesign garantit une grande évolutivité et, en fait, améliore également les performances et la convivialité du système. Autre exemple : afin de garantir la disponibilité, des paramètres de délai d'attente sont généralement définis pour les interfaces de service afin d'empêcher un grand nombre de threads de bloquer des requêtes lentes et de provoquer une avalanche du système. Alors, qu'est-ce qu'un paramètre de délai d'attente raisonnable ? Généralement, nous effectuerons des réglages en fonction des performances des services dépendants. D'un point de vue micro, quels sont les indicateurs spécifiques pour mesurer la haute performance, la haute disponibilité et la haute évolutivité ? Pourquoi ces indicateurs ont-ils été choisis ? Les indicateurs de performance peuvent être utilisés pour mesurer les problèmes de performance actuels et servir de base d'évaluation pour l'optimisation des performances. D'une manière générale, le temps de réponse de l'interface sur une période donnée est utilisé comme indicateur. 1. Temps de réponse moyen : Le plus couramment utilisé, mais ses défauts sont évidents et il n'est pas sensible aux requêtes lentes. Par exemple, il y a 10 000 requêtes, dont 9 900 durent 1 ms et 100 durent 100 ms. Le temps de réponse moyen est de 1,99 ms. Bien que le temps de réponse moyen n'ait augmenté que de 0,99 ms, le temps de réponse pour 1 % des requêtes a augmenté de 100 ms. fois. 2, TP90, TP99 et autres valeurs quantiles : Triez le temps de réponse de petit à grand. TP90 représente le temps de réponse classé dans le 90ème centile. Plus la valeur du quantile est grande, plus elle est sensible. demandes lentes. 3. Débit : Il est inversement proportionnel au temps de réponse. Par exemple, le temps de réponse est de 1 ms, alors le débit est de 1000 fois par seconde. Habituellement, lors de la définition des objectifs de performances, le débit et le temps de réponse seront pris en compte. Par exemple, en dessous de 10 000 requêtes par seconde, AVG est contrôlé en dessous de 50 ms et TP99 est contrôlé en dessous de 100 ms. Pour les systèmes à haute concurrence, les valeurs des quantiles AVG et TP doivent être prises en compte en même temps. De plus, du point de vue de l'expérience utilisateur, 200 millisecondes sont considérées comme le premier point de division, et les utilisateurs ne ressentiront pas le retard, 1 seconde est le deuxième point de division, et les utilisateurs ressentiront le retard, mais c'est acceptable. . Par conséquent, pour un système sain à haute concurrence, TP99 doit être contrôlé en 200 millisecondes et TP999 ou TP9999 doit être contrôlé en 1 seconde. La haute disponibilité signifie que le système a une grande capacité à fonctionner sans pannes. Plusieurs 9 sont généralement utilisés pour décrire le système. . disponibilité. Pour un système à haute concurrence, l'exigence la plus fondamentale est : garantir 3 9 ou 4 9. La raison est simple. Si vous ne pouvez atteindre que deux neuf, cela signifie qu'il y a un temps d'échec de 1 %. Par exemple, certaines grandes entreprises ont souvent plus de 100 milliards de GMV ou de chiffre d'affaires chaque année. niveau milliard. Face à un trafic soudain, il est impossible de transformer temporairement l'architecture. Le moyen le plus rapide est d'ajouter des machines pour améliorer linéairement les capacités de traitement du système. Pour les clusters métiers ou les composants de base, scalabilité = ratio d'amélioration des performances / ratio d'ajout de machines. La scalabilité idéale est : augmenter plusieurs fois les ressources et améliorer les performances plusieurs fois. D'une manière générale, la capacité d'expansion doit être maintenue au-dessus de 70 %. Mais du point de vue de l'architecture globale d'un système à haute concurrence, l'objectif de expansion n'est pas seulement de concevoir le service pour qu'il soit apatride, car lorsque le trafic augmente de 10 fois, le le service aux entreprises peut rapidement être multiplié par 10, mais la base de données peut devenir un nouveau goulot d'étranglement. Les services de stockage avec état comme MySQL sont généralement techniquement difficiles à étendre si l'architecture n'est pas planifiée à l'avance (séparation verticale et horizontale), cela impliquera la migration d'une grande quantité de données. Par conséquent, une grande évolutivité doit être prise en compte : clusters de services, middleware tels que bases de données, caches et files d'attente de messages, équilibrage de charge, bande passante, tiers dépendants, etc. Lorsque la concurrence atteint un certain niveau, chacun des facteurs ci-dessus Peut devenir un goulot d’étranglement pour l’expansion. Son objectif est d'améliorer la puissance de traitement d'une seule machine, Le plan comprend également : Parce qu'il y a toujours des limites aux performances d'une seule machine, il est finalement nécessaire d'introduire une expansion horizontale et d'améliorer encore les capacités de traitement simultané grâce au déploiement de clusters, y compris les éléments suivants Deux directions: 1. Développer une architecture hiérarchique : C'est une avancée vers l'expansion horizontale, car les systèmes à haute concurrence ont souvent des activités complexes et le traitement en couches peut simplifier les problèmes complexes et faciliter l'expansion horizontale. L'image ci-dessus est l'architecture en couches la plus courante d'Internet. Bien entendu, la véritable architecture du système à haute concurrence sera encore améliorée sur cette base. Par exemple, une séparation dynamique et statique sera effectuée et le CDN sera introduit. La couche proxy inverse peut être LVS+Nginx, la couche Web peut être une passerelle API unifiée, la couche de services métier peut être davantage micro-serviceée en fonction de l'activité verticale. , et la couche de stockage peut être constituée de diverses bases de données hétérogènes. 2. Expansion horizontale de chaque couche : expansion horizontale sans état, routage de fragments avec état. Les clusters d'entreprise peuvent généralement être conçus pour être sans état, tandis que les bases de données et les caches sont souvent avec état. Par conséquent, les clés de partition doivent être conçues pour le partitionnement du stockage. Bien entendu, les performances de lecture peuvent également être améliorées grâce à la synchronisation maître-esclave et à la séparation lecture-écriture. 1, Déploiement de cluster, réduisant la pression sur une seule machine grâce à l'équilibrage de charge. La solution ci-dessus n'est rien de plus que de considérer tous les points d'optimisation possibles dans les deux dimensions de l'informatique et des E/S. Elle nécessite un système de surveillance de support pour comprendre les performances actuelles en temps réel et vous aider à effectuer une analyse des goulots d'étranglement des performances, et puis suivez 28 principes, saisissez les principales contradictions et optimisez-les. 1. Basculement des nœuds homologues Nginx et le cadre de gouvernance des services prennent en charge l'accès à un autre nœud après la panne d'un nœud. Les solutions à haute disponibilité sont principalement envisagées sous trois angles : la redondance, les compromis, ainsi que l'exploitation et la maintenance du système. En même temps, elles doivent disposer de mécanismes de support et de processus de gestion des pannes lorsque des problèmes en ligne surviennent. peut être suivi dans le temps. 1. Architecture en couches raisonnable : par exemple, l'architecture en couches la plus courante d'Internet mentionnée ci-dessus, en outre, elle peut être adaptée en fonction de la couche d'accès aux données et Couche de logique métier Les microservices sont superposés de manière plus fine (mais les performances doivent être évaluées, car il peut y avoir un saut supplémentaire sur le réseau). La concurrence élevée est en effet un problème complexe et systémique. En raison de l'espace limité, des points techniques tels que la trace distribuée, les tests de résistance de lien complet et les transactions flexibles doivent être pris en compte. De plus, si les scénarios commerciaux sont différents, les solutions de mise en œuvre à haute concurrence seront également différentes, mais les idées de conception globales et les solutions pouvant être utilisées à titre de référence sont fondamentalement similaires. La conception à haute concurrence doit également adhérer aux trois principes de la conception architecturale : Simplicité, pertinence et évolution. "L'optimisation prématurée est la racine de tous les maux", ne peut être dissociée de la situation réelle de l'entreprise, et ne surconcevez pas , La solution appropriée est la plus parfaite. J'espère que cet article pourra vous donner une compréhension plus complète de la haute concurrence. Si vous avez également une expérience et une réflexion approfondie dont vous pouvez tirer des leçons, veuillez laisser un message dans la zone de commentaires pour en discuter.
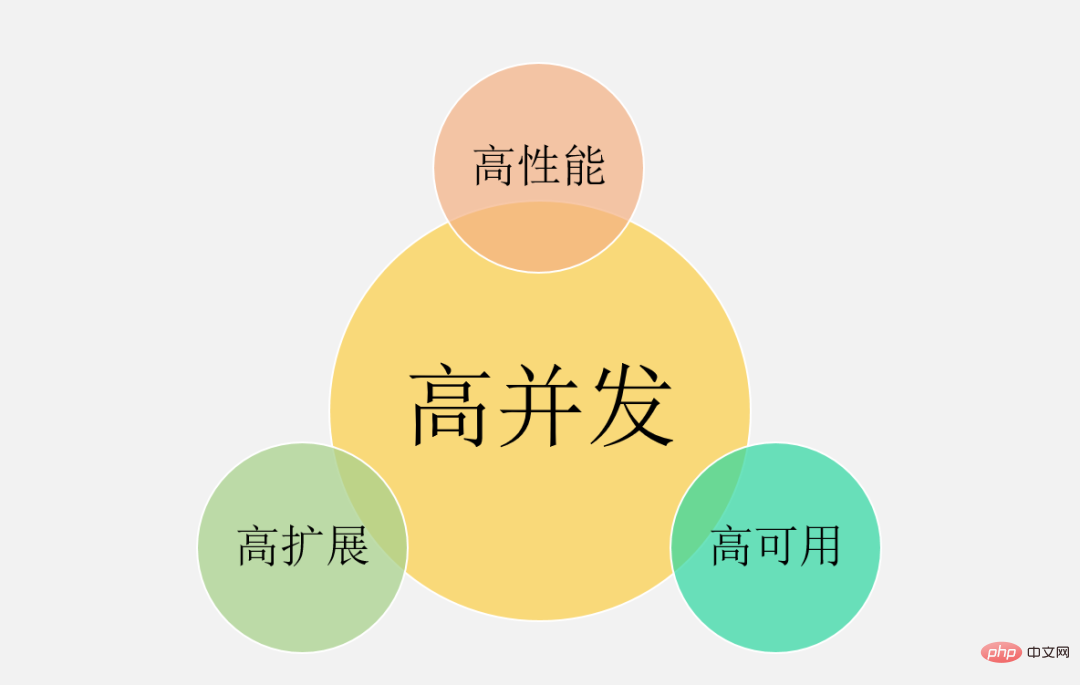
❇ Indicateurs de performance

❇ DisponibilitéIndicateur
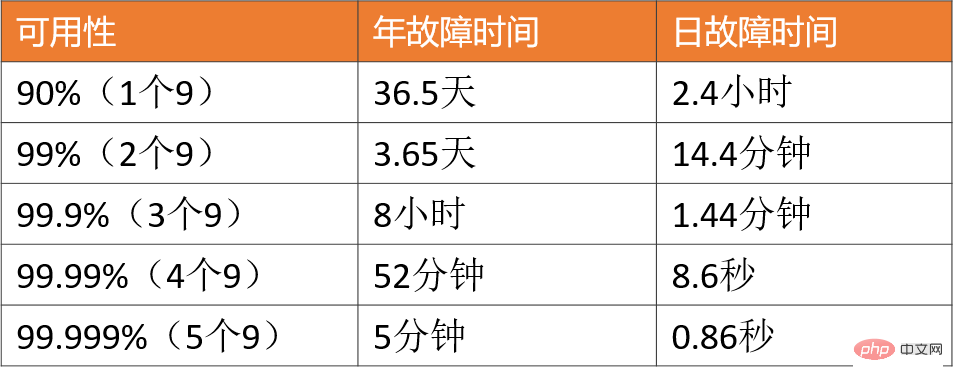
❇ ÉvolutivitéIndicateur
❇Expansion verticale (scale-up)
❇ Expansion horizontale (scale-out)
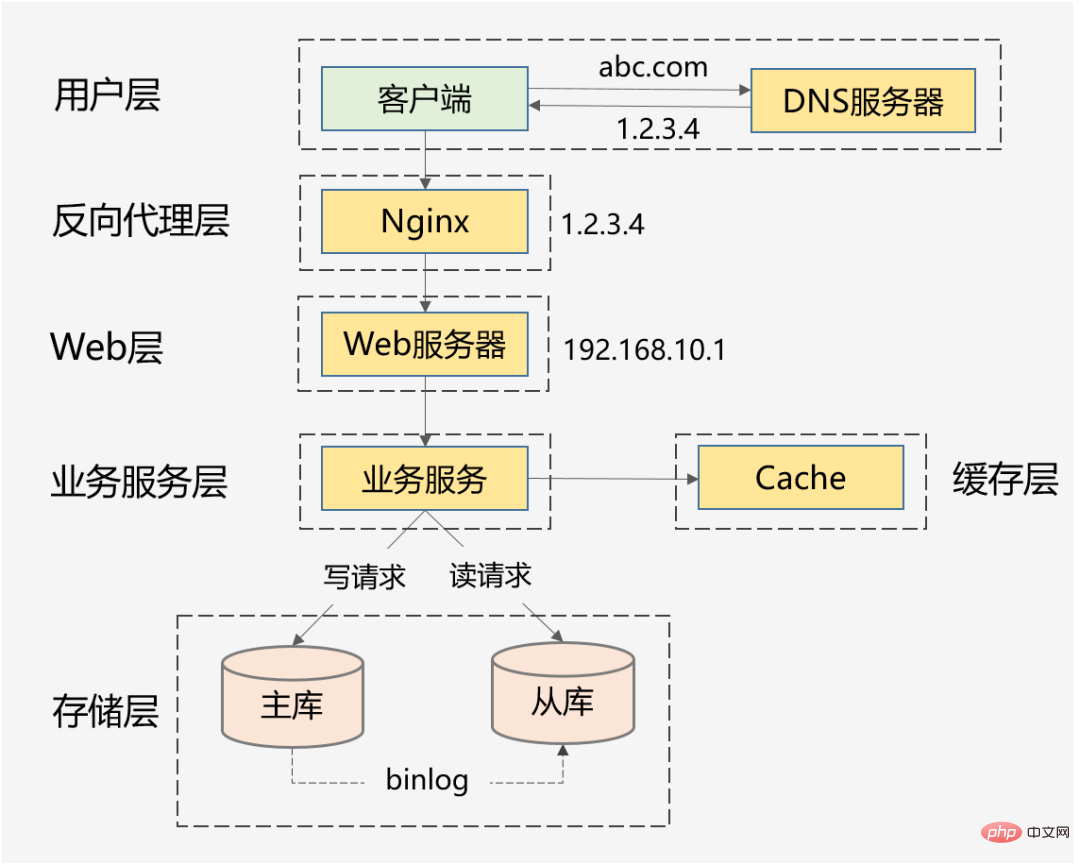
❇ Solution pratique et performante
❇ Solutions pratiques à haute disponibilité
❇ Solution pratique hautement évolutive
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!