
Maison >Périphériques technologiques >IA >Étendre la longueur du contexte à 256 Ko, la version contextuelle illimitée de LongLLaMA arrive-t-elle ?
Étendre la longueur du contexte à 256 Ko, la version contextuelle illimitée de LongLLaMA arrive-t-elle ?

- PHPzavant
- 2023-07-11 15:05:441302parcourir
En février de cette année, Meta a publié la série de modèles de langage à grande échelle LLaMA, qui a promu avec succès le développement de robots de discussion open source. Parce que LLaMA a moins de paramètres que de nombreux grands modèles précédemment publiés (le nombre de paramètres varie de 7 milliards à 65 milliards), mais a de meilleures performances. Par exemple, le plus grand modèle LLaMA avec 65 milliards de paramètres est comparable au Chinchilla-70B et au PaLM de Google. -540B, tant de chercheurs étaient enthousiasmés dès sa sortie.
Cependant, LLaMA n'est autorisé à être utilisé que par des chercheurs universitaires, limitant ainsi l'application commerciale du modèle.
Par conséquent, les chercheurs ont commencé à rechercher les LLaMA pouvant être utilisés à des fins commerciales. Le projet OpenLLaMA initié par Hao Liu, doctorant à l'UC Berkeley, est l'une des copies open source les plus populaires de LLaMA, qui utilise. exactement le même LLaMA que le LLaMA original Pour les hyperparamètres de prétraitement et de formation, on peut dire qu'OpenLLaMA suit complètement les étapes de formation de LLaMA. Plus important encore, le modèle est disponible dans le commerce.
OpenLLaMA est formé sur l'ensemble de données RedPajama publié par Together Company. Il existe trois versions de modèle, à savoir 3B, 7B et 13B. Ces modèles ont été formés avec des jetons 1T. Les résultats montrent que les performances d'OpenLLaMA sont comparables, voire supérieures, à celles du LLaMA original dans plusieurs tâches.
En plus de publier constamment de nouveaux modèles, les chercheurs explorent constamment la capacité du modèle à gérer les jetons.
Il y a quelques jours, les dernières recherches de l'équipe de Tian Yuandong ont étendu le contexte LLaMA à 32K avec moins de 1000 étapes de réglage fin. En remontant plus loin, GPT-4 prend en charge 32 000 jetons (ce qui équivaut à 50 pages de texte), Claude peut gérer 100 000 jetons (à peu près l'équivalent de résumer la première partie de "Harry Potter" en un clic) et ainsi de suite.
Maintenant, un nouveau grand modèle de langage basé sur OpenLLaMA arrive, qui étend la longueur du contexte à 256 000 jetons et même plus. La recherche a été réalisée conjointement par IDEAS NCBR, l'Académie polonaise des sciences, l'Université de Varsovie et Google DeepMind.
 Pictures
Pictures
LongLLaMA est basé sur OpenLLaMA et la méthode de réglage fin utilise FOT (Focused Transformer). Cet article montre que FOT peut être utilisé pour affiner de grands modèles déjà existants afin d'étendre la longueur de leur contexte.
L'étude utilise les modèles OpenLLaMA-3B et OpenLLaMA-7B comme point de départ et les affine à l'aide de FOT. Les modèles résultants, appelés LONGLLAMA, sont capables d'extrapoler au-delà de la longueur de leur contexte de formation (même jusqu'à 256 000) et de maintenir leurs performances sur des tâches à contexte court.
- Adresse du projet : https://github.com/CStanKonrad/long_llama
- Adresse papier : https://arxiv.org/pdf/2307.03170.pdf
Quelqu'un a décrit cette recherche Pour le version contextuelle illimitée d'OpenLLaMA, avec FOT, le modèle peut être facilement extrapolé à des séquences plus longues. Par exemple, un modèle formé sur des jetons de 8K peut être facilement extrapolé à une taille de fenêtre de 256K.
 Pictures
Pictures
Cet article utilise la méthode FOT, qui est une extension plug-and-play du modèle Transformer et peut être utilisée pour former de nouveaux modèles ou affiner des modèles plus grands existants avec des contextes plus longs.
Pour y parvenir, FOT utilise une couche d'attention mémoire et un processus de formation par lots :
- La couche d'attention mémoire permet au modèle de récupérer des informations de la mémoire externe au moment de l'inférence, étendant ainsi efficacement le contexte ;
- Le processus de formation cross-batch fait que le modèle a tendance à apprendre (clé, valeur) des représentations très faciles à utiliser pour mémoriser les couches d'attention.
Pour un aperçu de l'architecture FOT, voir Figure 2 :
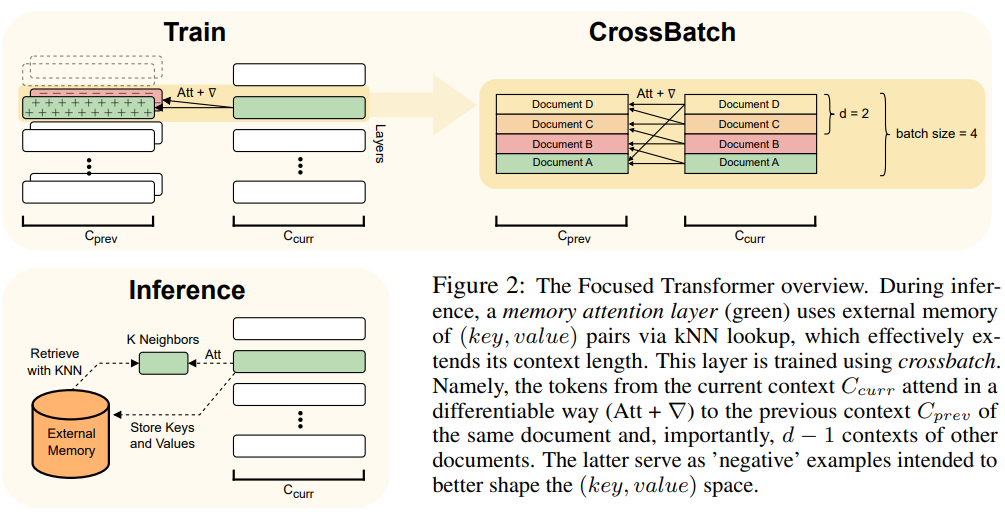 Photos
Photos
Le tableau suivant montre quelques informations sur le modèle pour LongLLaMA :
 Photos
Photos
Enfin, le Le projet fournit également des résultats de comparaison entre LongLLaMA et le modèle OpenLLaMA original.
L'image ci-dessous montre quelques résultats expérimentaux de LongLLaMA Sur la tâche de récupération de mot de passe, LongLLaMA a obtenu de bonnes performances. Plus précisément, le modèle LongLLaMA 3B a largement dépassé la longueur de son contexte d'entraînement de 8 K, atteignant une précision de 94,5 % pour 100 000 jetons et une précision de 73 % pour 256 000 jetons.
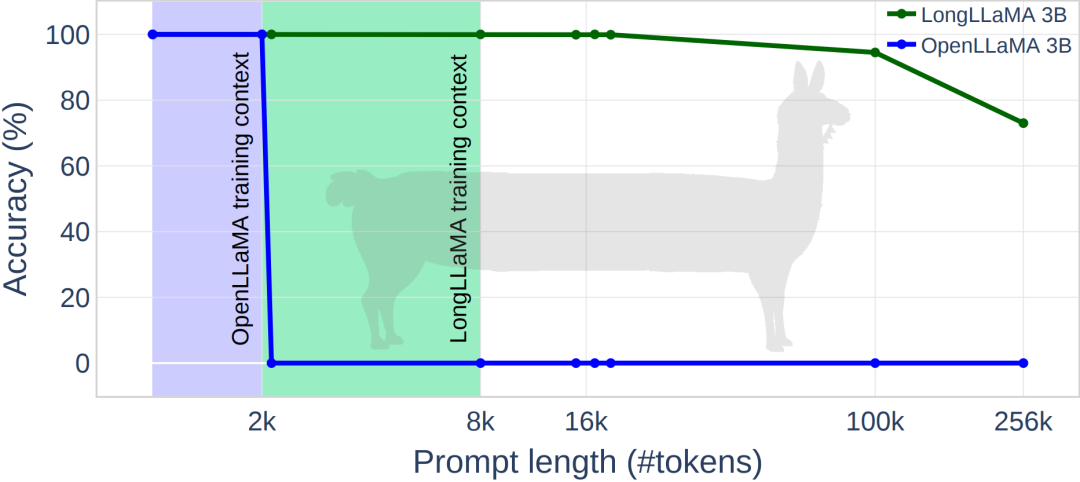 Photos
Photos
Le tableau suivant montre les résultats du modèle LongLLaMA 3B sur deux tâches en aval (classification des questions TREC et réponse aux questions WebQS). Les résultats montrent que les performances de LongLLaMA s'améliorent considérablement lors de l'utilisation d'un contexte long.
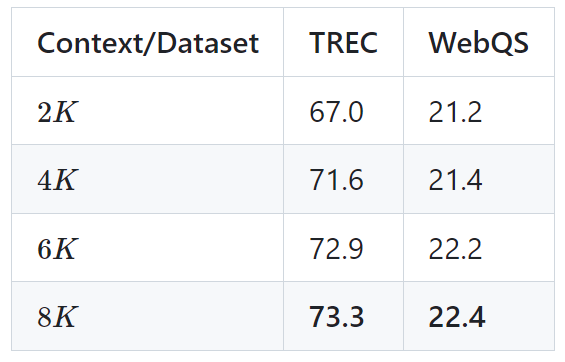 Image
Image
Le tableau ci-dessous montre comment LongLLaMA fonctionne bien même sur des tâches qui ne nécessitent pas de contexte long. Les expériences comparent LongLLaMA et OpenLLaMA dans un environnement sans échantillon.
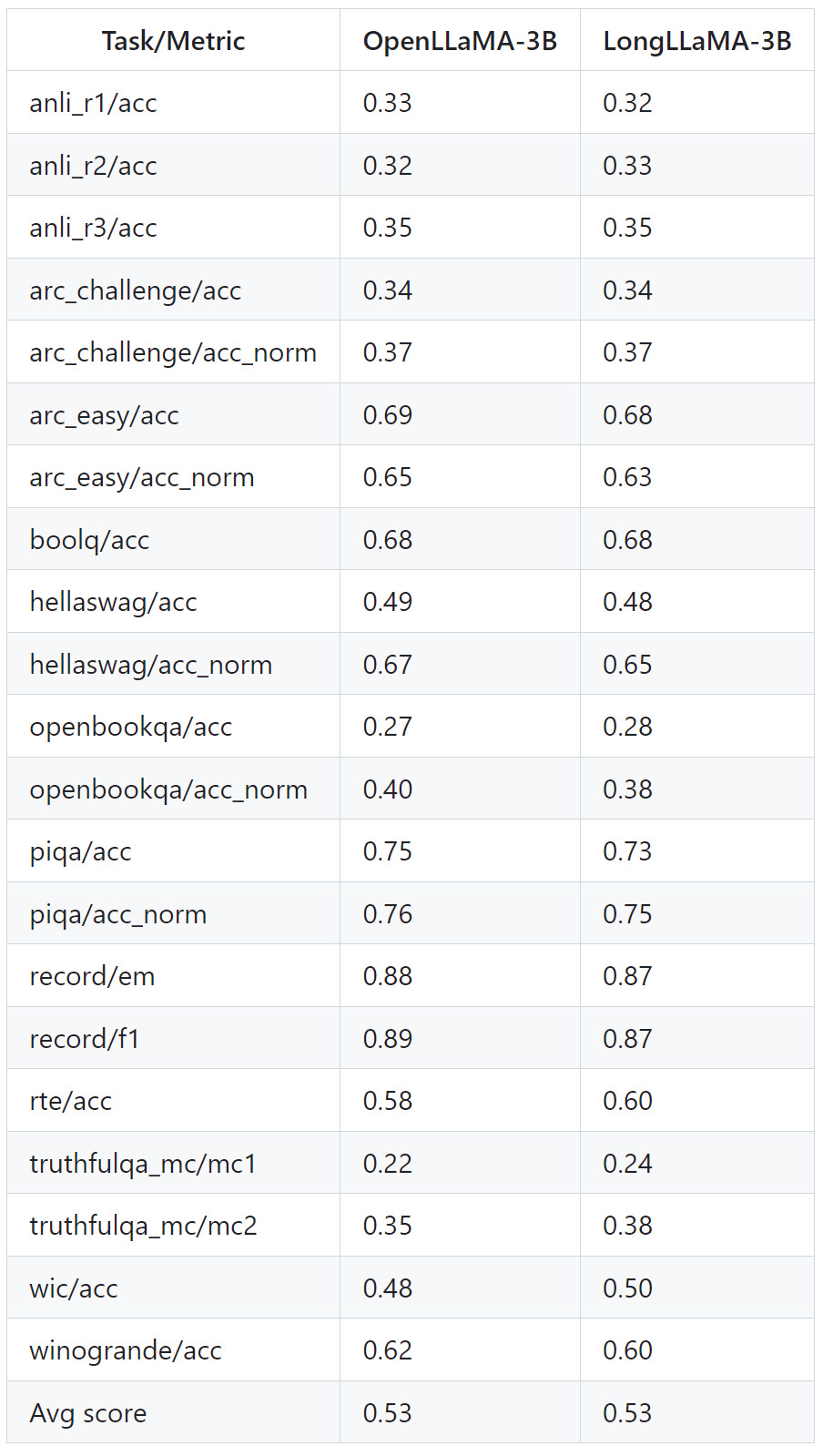 Photos
Photos
Pour plus de détails, veuillez vous référer au document et au projet originaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI