
Maison >Périphériques technologiques >IA >Un géant des données de 38 milliards de dollars veut lancer une révolution « IA » dans les entreprises
Un géant des données de 38 milliards de dollars veut lancer une révolution « IA » dans les entreprises

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-07-03 17:22:331144parcourir
Auteur | Wan Chen, Li Yuan
Éditeur | Jingyu
Le 28 juin, heure locale, Databricks, une plateforme de données américaine bien connue, a tenu sa propre conférence annuelle : le Data and Artificial Intelligence Summit. Lors de la réunion, Databricks a annoncé une série de nouveaux produits importants tels que LakehouseIQ, Lakehouse AI, Databricks Marketplace et Lakehouse Apps.
Qu'il s'agisse du nom du sommet ou de la nomination de nouveaux produits, on constate que cette plateforme de données bien connue profite du grand modèle linguistique pour accélérer sa transformation vers l'IA.

Le PDG de Databricks, Ali Ghodsi, a déclaré que les données et l'IA étaient inclusives|Databricks
« Ce que Databricks veut réaliser, c'est « l'inclusivité des données » et l'inclusivité de l'IA. La première permet aux données d'atteindre chaque employé, et la seconde permet à l'IA d'entrer dans chaque produit. Ali Ghodsi, PDG de Databricks, a annoncé la mission de l'équipe dans son discours.
Juste avant le début de la conférence, Databricks venait d'annoncer l'acquisition de MosaicML, une nouvelle force dans le domaine de l'IA, pour 1,3 milliard de dollars américains, établissant un record d'acquisition actuel dans le domaine de l'IA, qui montre la force et la détermination de l'entreprise. dans la transformation de l'IA.
Le fondateur et PDG de PingCAP, Liu Qi, qui assistera à la réunion à venir, a déclaré à Geek Park que la plate-forme Databricks vient de lancer des applications d'IA au niveau de l'entreprise, et que plus de 1 500 entreprises y forment déjà des modèles, et « les chiffres dépassent les attentes ». " Dans le même temps, il estime que l'accumulation précédente de données + IA de Databricks a permis à l'entreprise d'ajouter rapidement de nouveaux produits basés sur la plate-forme précédente lorsque l'IA est devenue populaire, et de fournir rapidement des services liés aux grands modèles.
"La chose la plus critique est la vitesse." Liu Qi a déclaré qu'à l'ère des grands modèles, comment intégrer plus rapidement de grands modèles aux produits existants et résoudre les problèmes des utilisateurs peut être le plus grand défi pour toutes les entreprises de données en ce moment, et c'est aussi le plus grand défi pour toutes les entreprises de données. La plus grande opportunité.
Points de discussion
- Grâce à la mise à niveau de l'interface interactive, les gens ordinaires qui ne sont pas des analystes de données peuvent directement utiliser le langage naturel pour interroger et analyser les données.
- Il deviendra de plus en plus facile pour les entreprises de déployer de grands modèles sur des bases de données cloud, et il deviendra également plus facile d'utiliser directement des outils de grands modèles finis pour analyser les données.
- Avec les progrès de l'IA, la valeur des données deviendra de plus en plus élevée et le potentiel des données sera davantage libéré.
La base de données accueille l'interaction en langage naturel
Databricks a publié un nouvel outil LakehouseIQ lors de la conférence, qui a été salué comme un « artefact ». LakehouseIQ réalise l'un des plus grands efforts récents de Databricks : l'universalisation de l'analyse des données, c'est-à-dire que les gens ordinaires qui ne maîtrisent pas Python et SQL peuvent facilement accéder aux données de l'entreprise et effectuer des analyses de données en utilisant le langage naturel.
Pour atteindre cet objectif, LakehouseIQ est conçu comme un ensemble de fonctions pouvant être utilisées à la fois par les utilisateurs finaux ordinaires et les développeurs, avec différentes fonctions conçues pour différents utilisateurs.
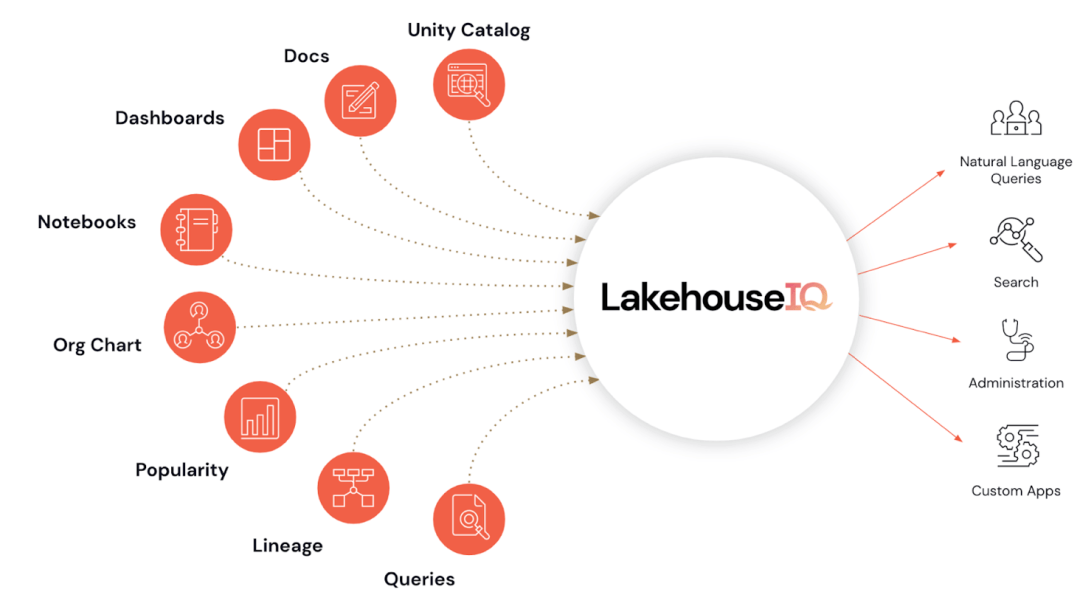
Photo du produit LakehouseIQ|Databricks
Pour les développeurs, LakehouseIQ in Notebooks a été publié. Dans cette fonctionnalité, LakehouseIQ peut utiliser de grands modèles de langage pour aider les développeurs à compléter, générer et interpréter du code, ainsi qu'à effectuer la réparation de code, le débogage et la génération de rapports.
Pour les non-programmeurs ordinaires, Databricks fournit une interface qui peut interagir directement avec le langage naturel. Elle est pilotée par un grand modèle de langage et peut utiliser directement le langage naturel pour rechercher et interroger des données. Dans le même temps, cette fonction est intégrée à Unity Catalog, permettant aux entreprises de contrôler l'accès aux recherches et requêtes de données, et de renvoyer uniquement les données que la personne qui pose la question est autorisée à consulter.
Depuis le lancement des grands modèles, l'utilisation du langage naturel pour interroger et analyser des données est en fait un sujet brûlant dans le sens de l'analyse des données, et de nombreuses entreprises ont élaboré des plans dans cette direction. Y compris l'ancien rival de Databricks, Snowflake, la fonctionnalité Document AI qui vient d'être annoncée se concentre également sur cette direction.
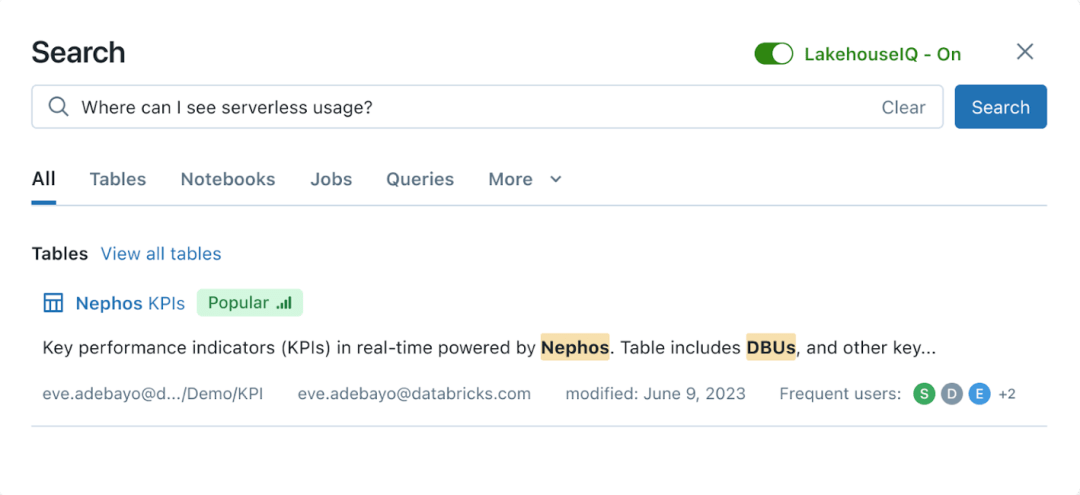
Interface de requête en langage naturel LakehouseIQ|Databricks
Cependant, Databricks affirme que LakehouseIQ fonctionne mieux sur le plan fonctionnel. Il souligne que les grands modèles de langage à usage général ont des limites dans la compréhension des données clients spécifiques, de la terminologie interne et des modèles d'utilisation. La technologie de Databricks exploite les schémas, documents, requêtes, popularité, fils de discussion, blocs-notes et tableaux de bord de business intelligence des clients pour obtenir des informations et répondre à davantage de requêtes.
Il existe une autre différence entre les fonctions de Databricks et de Snowflake. La fonction Document AI de la plateforme Snowflake se limite à interroger des données non structurées dans des documents, tandis que LakehouseIQ convient aux données et au code structurés de Lakehouse.
02
De l'apprentissage automatique à l'IA
Les similitudes entre Databricks et Snowflake au lancement ne s'arrêtent pas là.
Lors de cette conférence, Databricks a publié Databricks Marketplace et Lakehouse AI, qui sont tout à fait cohérents avec l'objectif de la conférence de deux jours de Snowflake. Tous deux se concentrent sur le déploiement de grands modèles de langage dans des environnements de bases de données.
Dans la vision de Databricks, Databricks peut non seulement aider les clients à déployer de grands modèles à l'avenir, mais également fournir des outils de grands modèles finis.
Databricks avait la marque Databricks Machine Learning. Lors de cette conférence de presse, Databricks a entièrement repositionné sa marque et l'a mise à niveau vers Lakehouse AI, en se concentrant sur l'assistance aux clients dans le déploiement de grands modèles.
Databricks Marketplace est désormais disponible sur Databricks. Sur Databricks Marketplace, les utilisateurs peuvent accéder à une collection filtrée de grands modèles de langage open source, notamment MPT-7B, Falcon-7B et Stable Diffusion, et peuvent également découvrir et obtenir des ensembles de données et des actifs de données. Lakehouse AI fournit également certaines fonctions d'opérations de modèle de langage étendu (LLMOps).
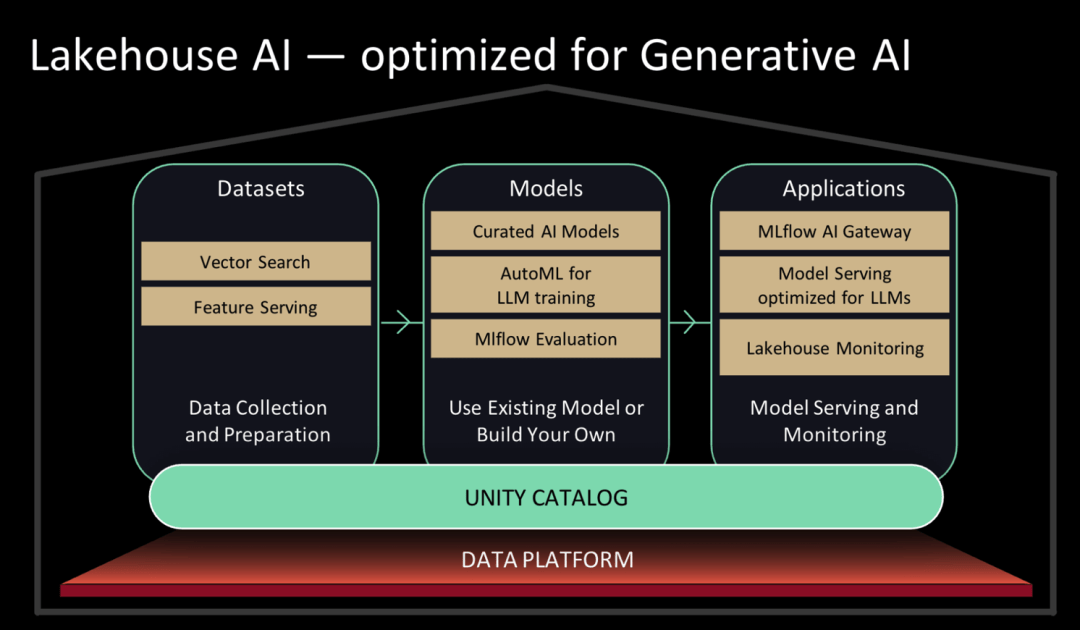
Diagramme d'architecture d'IA de Lakehouse|Databricks
Snowflake le déploie également activement, avec des capacités similaires fournies par Nvidia NeMo, Nvidia AI Enterprise, Dataiku et John Snow Labs (la collaboration avec Nvidia est l'un des points forts de la conférence Snowflake, voir le rapport de Geek Park).
Snowflake et Databricks ont des différences en aidant les clients à déployer de grands modèles. Snowflake a choisi de s'engager activement avec des partenaires, tandis que Databricks a cherché à ajouter la fonctionnalité en tant que fonctionnalité native de sa plate-forme principale.
En termes de fourniture d'outils finis, Databricks a annoncé que Databricks Marketplace fournira également les applications Lakehouse à l'avenir. Lakehouse Apps s'exécutera directement sur les instances Databricks des clients, où elles pourront s'intégrer aux données des clients, consommer et étendre les services Databricks et permettre aux utilisateurs d'interagir via une expérience d'authentification unique. Les données n'ont jamais besoin de quitter l'instance du client, et il n'y a aucun problème de transfert de données ni de problème de sécurité/d'accès.
Cela est tout à fait cohérent avec les produits Snowflake en termes de nom et de fonctionnalité. Les solutions similaires Snowflake Marketplace et Snowflake Native App sont déjà en ligne et constituent l'un des points forts de son lancement. Bloomberg a annoncé une application Data License Plus (DL+) fournie par Bloomberg lors de la conférence Snowflake, qui permet aux clients de configurer un environnement prêt à l'emploi dans le cloud en quelques minutes, avec des données d'abonnement Bloomberg entièrement modélisées et du contenu ESG provenant de plusieurs fournisseurs.
03
La plateforme de données inaugure de nouveaux changements
Lors du discours d'ouverture, Databricks a annoncé un chiffre : au cours des 30 derniers jours, plus de 1 500 clients ont formé des modèles Transformer sur la plateforme Databricks.
En parlant de ce nombre impressionnant, PingCAP Liu Qi estime que cela montre que les entreprises appliquent l'IA beaucoup plus rapidement que prévu : « Il n'est pas nécessaire de former le modèle pour appliquer le modèle, donc s'il y a 1 500 personnes formées à domicile, l'application doit le faire. être beaucoup plus grand que ce (nombre). »
Un autre point de vue est que cela montre que la configuration stratégique de Databricks dans le domaine de l’IA est assez complète. C'est désormais plus qu'un simple entrepôt de données ou un lac de données. Désormais, il propose également : la formation en IA, le service IA, la gestion de modèles, etc. "

Ali Ghodsi utilise la révolution de l'informatique et d'Internet pour comparer la transformation des grands modèles en apprentissage automatique|Databricks
En d'autres termes, le modèle sous-jacent peut être entraîné sur la plateforme Databricks, et le modèle de niveau le plus bas peut être entraîné en ajustant simplement les paramètres. Pour les services d'IA requis en plus de ce modèle, Databricks a également mis en place l'infrastructure correspondante - il a publié aujourd'hui la recherche vectorielle et le magasin de fonctionnalités.
Databricks est entièrement mis à niveau vers les grands modèles.
Dans le passé, Databricks a accumulé beaucoup d'expérience en matière d'IA, notamment en utilisant de petits modèles pour améliorer l'efficacité et réduire la latence dans la création d'index, l'interrogation de données et la prévision des charges de travail. Cependant, la capacité de rattraper de grands modèles à un rythme aussi rapide surprend encore beaucoup de gens.
Avant la présentation complète de l'IA lors du sommet d'aujourd'hui, Databricks a acquis Okera (gouvernance des données IA), lancé son propre grand modèle open source Dolly 2.0 et acquis MosaicML pour 1,3 milliard de dollars américains.
À cet égard, Howie, un enseignant de la Silicon Valley, estime que cela ressort clairement des deux conférences Databricks et Snowflake : les fondateurs des deux sociétés estiment que les actions qu'ils ont entreprises sur la base des bases de données et des lacs de données seront confrontées problèmes fondamentaux dans les changements futurs. La façon dont ils procédaient il y a un an ne fonctionnera plus dans les prochaines années.
En conséquence, la capacité de réaliser rapidement de grands modèles signifie également que le marché supplémentaire apporté par les grands modèles peut être obtenu.
Liu Qi estime que l'émergence des grands modèles a déclenché de nombreux nouveaux besoins qui n'existaient pas avant les grands modèles. Sans support de données, le modèle ne pourra pas fonctionner, notamment en termes de différenciation. Si tout le monde est un grand modèle, il n’y a peut-être aucune différence entre vous et les autres. "
Mais par rapport aux grands modèles, le public présent au sommet a semblé accorder plus d'attention aux petits modèles en raison de plusieurs avantages des petits modèles : rapidité, coût et sécurité. Liu Qi a déclaré que sur la base de ses propres données uniques, il peut créer des modèles différenciés. Le modèle doit être suffisamment petit pour répondre à ces trois exigences : suffisamment bon marché, suffisamment rapide et suffisamment sûr.
Il convient de noter que Databricks et Snowflake ont récemment annoncé leurs données sur les revenus et que la croissance annuelle des revenus de la plate-forme est supérieure à 60 %. Ce taux de croissance se reflète dans l’attention croissante portée aux données dans un contexte de ralentissement des dépenses en logiciels sur le marché. Avec l’émergence des modèles à grande échelle, la valeur des données a été mise en avant lors de ce Databricks Summit sur le thème data plus AI.
Avec l'introduction de modèles à grande échelle, la génération automatique de données devient possible et la quantité de données devrait augmenter de façon exponentielle. Comment accéder facilement aux données, comment prendre en charge différents formats de données et comment exploiter la valeur derrière les données deviendra des besoins de plus en plus fréquents.
D'un autre côté, de nombreuses entreprises explorent encore et attendent aujourd'hui d'intégrer de grands modèles dans les logiciels d'entreprise. Cependant, compte tenu de la sécurité, de la confidentialité et du coût, peu osent l'utiliser directement. Une fois que les grands modèles seront déployés directement sur les données de l'entreprise sans déplacer les données, le seuil de déploiement de grands modèles sera encore abaissé, et la quantité et la vitesse de consommation des données seront encore plus libérées.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI