
Maison >Périphériques technologiques >IA >Nouveaux résultats de recherche de l'équipe de Yann LeCun : Rétro-ingénierie de l'apprentissage auto-supervisé, il s'avère que le clustering s'implémente ainsi
Nouveaux résultats de recherche de l'équipe de Yann LeCun : Rétro-ingénierie de l'apprentissage auto-supervisé, il s'avère que le clustering s'implémente ainsi

- 王林avant
- 2023-06-15 11:27:541040parcourir
L'apprentissage auto-supervisé (SSL) a fait de grands progrès ces dernières années et a presque atteint le niveau des méthodes d'apprentissage supervisé sur de nombreuses tâches en aval. Cependant, en raison de la complexité du modèle et du manque d’ensembles de données d’entraînement annotés, il a été difficile de comprendre les représentations apprises et leurs mécanismes de fonctionnement sous-jacents. De plus, les tâches prétextes utilisées dans l’apprentissage auto-supervisé ne sont souvent pas directement liées à des tâches spécifiques en aval, ce qui augmente encore la complexité de l’interprétation des représentations apprises. En classification supervisée, la structure de la représentation apprise est souvent très simple.
Par rapport aux tâches de classification traditionnelles (l'objectif est de classer avec précision les échantillons dans des catégories spécifiques), l'objectif des algorithmes SSL modernes est généralement de minimiser la perte contenant deux composants majeurs Fonction : l'une consiste à regrouper les échantillons améliorés (contraintes d'invariance) et l'autre à empêcher l'effondrement de la représentation (contraintes de régularisation). Par exemple, pour un même échantillon après différentes améliorations, le but de la méthode d'apprentissage contrastif est de rendre les résultats de classification de ces échantillons identiques, tout en étant capable de distinguer différents échantillons améliorés. D'un autre côté, les méthodes non contrastives utilisent des régulariseurs pour éviter l'effondrement de la représentation.
L'apprentissage auto-supervisé peut utiliser la tâche auxiliaire (prétexte) des données non supervisées pour extraire ses propres informations de supervision et former le réseau grâce à ces informations de supervision construites, de sorte qu'il peut apprendre des représentations utiles pour les tâches en aval. Récemment, plusieurs chercheurs, dont Yann LeCun, lauréat du prix Turing, ont publié une étude affirmant avoir procédé à une ingénierie inverse de l'apprentissage auto-supervisé, nous permettant de comprendre le comportement interne de son processus de formation.

Adresse papier : https://arxiv.org/abs/2305.15614v2#🎜🎜 #
Cet article effectue une analyse approfondie de l'apprentissage des représentations à l'aide de SLL à travers une série d'expériences soigneusement conçues pour aider les gens à comprendre le processus de regroupement pendant la formation. Plus précisément, nous révélons que les échantillons augmentés présentent un comportement hautement groupé, qui forme des centroïdes autour des intégrations de signification des échantillons augmentés partageant la même image. De manière encore plus inattendue, les chercheurs ont observé que les échantillons se regroupaient en fonction d'étiquettes sémantiques, même en l'absence d'informations explicites sur la tâche cible. Cela démontre la capacité de SSL à regrouper des échantillons en fonction de la similarité sémantique.
Réglage de problèmesPuisque l'apprentissage auto-supervisé (SSL) est généralement utilisé pour la pré-formation afin de préparer le modèle à s'adapter aux tâches en aval , cela soulève une question clé : quel impact la formation SSL a-t-elle sur les représentations apprises ? Plus précisément, comment SSL fonctionne-t-il sous le capot pendant la formation et quelles catégories ces fonctions de représentation peuvent-elles apprendre ?
Pour étudier ces problèmes, les chercheurs ont formé les réseaux SSL sur plusieurs paramètres et analysé leur comportement à l'aide de différentes techniques.
Données et augmentation : toutes les expériences mentionnées dans cet article ont utilisé l'ensemble de données de classification d'images CIFAR100. Pour entraîner le modèle, les chercheurs ont utilisé le protocole d'amélioration d'image proposé dans SimCLR. Chaque session de formation SSL est exécutée pendant 1 000 époques, à l'aide de l'optimiseur SGD avec momentum.
Architecture de base : Toutes les expériences ont utilisé l'architecture RES-L-H comme épine dorsale, couplée à deux couches de têtes de projection à perceptron multicouche (MLP).
Sondage linéaire : Pour évaluer l'efficacité de l'extraction d'une fonction discrète donnée (par exemple une catégorie) à partir d'une fonction de représentation, la méthode utilisée ici est le sondage linéaire. Cela nécessite la formation d'un classificateur linéaire (également appelé sonde linéaire) basé sur cette représentation, ce qui nécessite quelques échantillons de formation.
Classification au niveau de l'échantillon : pour évaluer la séparabilité au niveau de l'échantillon, les chercheurs ont créé un nouvel ensemble de données spécialisé.
L'ensemble de données d'entraînement contient 500 images aléatoires de l'ensemble d'entraînement CIFAR-100. Chaque image représente une catégorie spécifique et est améliorée de 100 manières différentes. Par conséquent, l’ensemble de données de formation contient un total de 50 000 échantillons de 500 catégories. L'ensemble de test utilise toujours ces 500 images, mais utilise 20 améliorations différentes, toutes issues de la même distribution. Par conséquent, les résultats de l’ensemble de tests comprennent 10 000 échantillons. Afin de mesurer la précision linéaire ou NCC (centre de classe le plus proche/centre de classe le plus proche) d'une fonction de représentation donnée au niveau de l'échantillon, la méthode adoptée ici consiste à utiliser d'abord les données d'entraînement pour calculer un classificateur pertinent, puis à le calculer. sur l'ensemble de test correspondant Évaluer sa précision.
Révéler le processus de clustering de l'apprentissage auto-supervisé
Le processus de clustering a toujours joué un rôle important dans l'analyse des modèles d'apprentissage en profondeur. Afin de comprendre intuitivement la formation SSL, la figure 1 montre l'espace d'intégration des échantillons de formation du réseau via la visualisation UMAP, qui inclut la situation avant et après la formation et est divisée en différents niveaux.
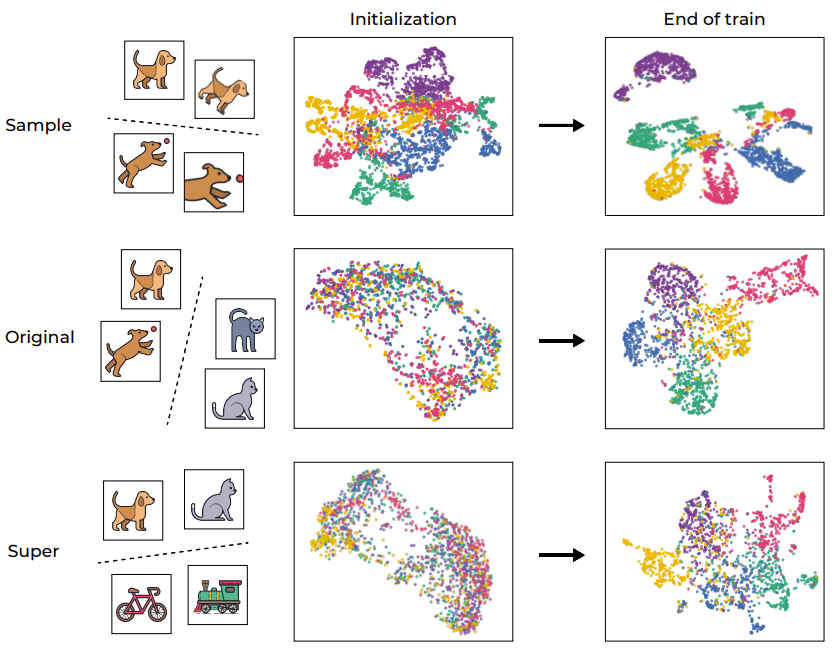
Figure 1 : Clustering sémantique induit par la formation SSL
Comme prévu, le processus de formation a réussi à regrouper les échantillons au niveau de l'échantillon, cartographiant différentes améliorations de la même image (comme indiqué dans la première ligne). Ce résultat n’est pas inattendu étant donné que la fonction objectif elle-même encourage ce comportement (via le terme de perte d’invariance). Mais plus particulièrement, ce processus de formation se regroupe également sur la base des « catégories sémantiques » originales de l'ensemble de données standard CIFAR-100, même s'il y a un manque d'étiquettes au cours du processus de formation. Il est intéressant de noter que les niveaux supérieurs (supercatégories) peuvent également être regroupés efficacement. Cet exemple montre que bien que le processus de formation encourage directement le regroupement au niveau de l'échantillon, les représentations de données formées par SSL sont également regroupées selon des catégories sémantiques à différents niveaux.
Pour quantifier davantage ce processus de regroupement, les chercheurs ont utilisé VICReg pour entraîner un RES-10-250. Les chercheurs ont mesuré la précision de la formation NCC, à la fois au niveau de l'échantillon et sur la base des catégories originales. Il convient de noter que les représentations formées par SSL présentent un effondrement neuronal au niveau de l'échantillon (la précision de la formation NCC est proche de 1,0), mais le regroupement en termes de catégories sémantiques est également significatif (environ 1,0 sur la cible d'origine (0,41).
Comme le montre l'image de gauche de la figure 2, la plupart des processus de clustering impliquant une amélioration (sur lesquels le réseau est directement formé) se produisent dans les premières étapes du processus de formation puis stagnent lors du clustering en termes de catégories sémantiques ; (l'objectif de formation (non précisé en ) continuera à s'améliorer au cours de la formation.
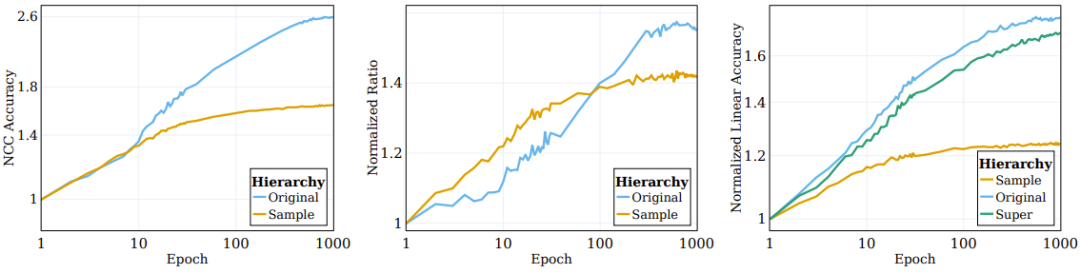
Figure 2 : L'algorithme SSL regroupe les données en fonction de paires de cibles sémantiques
Des chercheurs précédents ont observé que l'intégration de haut niveau d'échantillons d'entraînement supervisés évoluera progressivement vers un centroïde de classe. Convergence structurelle . Pour mieux comprendre la nature du clustering des fonctions de représentation formées par SSL, nous avons étudié des situations similaires lors de SSL. Son classificateur NCC est un classificateur linéaire et ne fonctionne pas mieux que le meilleur classificateur linéaire. Le regroupement de données peut être étudié à différents niveaux de granularité en évaluant la précision du classificateur NCC par rapport à un classificateur linéaire formé sur les mêmes données. Le panneau central de la figure 2 montre l'évolution de ce rapport entre les catégories au niveau de l'échantillon et les catégories cibles d'origine, avec des valeurs normalisées aux valeurs initialisées. Au fur et à mesure que la formation SSL progresse, l'écart entre la précision NCC et la précision linéaire se réduit, ce qui indique que les échantillons améliorés améliorent progressivement le niveau de regroupement en fonction de leurs identités d'échantillon et de leurs propriétés sémantiques.
De plus, la figure illustre également que le rapport au niveau de l'échantillon sera initialement plus élevé, indiquant que les échantillons augmentés sont regroupés en fonction de leur identité jusqu'à ce qu'ils convergent vers le centroïde (le rapport entre la précision NCC et la précision linéaire est à ≥ 0,9 à 100 époques). Cependant, à mesure que la formation se poursuit, les ratios au niveau de l’échantillon saturent, tandis que les ratios au niveau des classes continuent de croître et convergent vers environ 0,75. Cela montre que les échantillons améliorés seront d'abord regroupés en fonction de l'identité de l'échantillon, et après la mise en œuvre, ils seront regroupés selon des catégories sémantiques de haut niveau.
Compression implicite des informations dans la formation SSL
Si la compression peut être effectuée efficacement, des représentations bénéfiques et utiles peuvent être obtenues. Cependant, la question de savoir si une telle compression se produit pendant la formation SSL reste un sujet que peu de personnes ont étudié.
Pour comprendre cela, les chercheurs ont utilisé Mutual Information Neural Estimation (MINE), une méthode qui estime l'information mutuelle entre l'entrée et sa représentation intégrée correspondante pendant la formation. Cette métrique peut être utilisée pour mesurer efficacement le niveau de complexité d’une représentation en montrant la quantité d’informations (nombre de bits) qu’elle code.
Le panneau du milieu de la figure 3 rapporte les informations mutuelles moyennes calculées sur 5 graines d'initialisation MINE différentes. Comme le montre la figure, une compression importante se produit pendant le processus de formation, ce qui donne une représentation de formation très compacte.
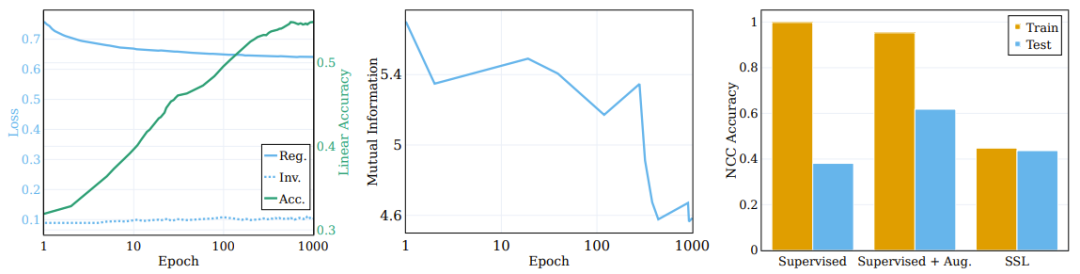
Le graphique de gauche montre les changements de régularisation et de perte d'invariance pendant la formation du modèle de formation SSL et la précision du test linéaire cible d'origine. (Centre) Compression des informations mutuelles entre la saisie et la représentation lors de la formation. (À droite) La formation SSL apprend les représentations des clusters.
Le rôle de la perte de régularisation
La fonction objectif contient deux éléments : l'invariance et la régularisation. La fonction principale du terme d'invariance est de renforcer la similarité entre des représentations différemment améliorées du même échantillon. L’objectif du terme de régularisation est d’aider à prévenir l’effondrement de la représentation.
Afin d'explorer le rôle de ces composants sur le processus de clustering, les chercheurs ont décomposé la fonction objectif en termes d'invariance et termes de régularisation, et ont observé leur comportement pendant le processus de formation. Les résultats de la comparaison sont présentés dans le panneau de gauche de la figure 3, où sont données l'évolution du terme de perte sur la cible sémantique d'origine et la précision du test linéaire. Contrairement à la croyance populaire, le terme de perte d’invariance ne s’améliore pas significativement au cours de l’entraînement. Au lieu de cela, des améliorations de la perte (et de la précision sémantique en aval) sont obtenues en réduisant la perte de régularisation.
On peut conclure que l'essentiel du processus de formation de SSL consiste à améliorer la précision sémantique et le regroupement des représentations apprises, plutôt que la précision de la classification et le regroupement au niveau de l'échantillon.
Essentiellement, les résultats montrent que, bien que l'objectif direct de l'apprentissage auto-supervisé soit la classification au niveau de l'échantillon, la majeure partie du temps de formation est en réalité consacrée au regroupement de données basées sur des catégories sémantiques à différents niveaux. Cette observation démontre la capacité des méthodes SSL à générer des représentations sémantiquement significatives grâce au clustering, ce qui permet également de comprendre ses mécanismes sous-jacents.
Comparaison de l'apprentissage supervisé et du clustering SSL
Les classificateurs de réseau profonds ont tendance à regrouper les échantillons de formation en différents centroïdes en fonction de leurs catégories. Cependant, pour que la fonction apprise se regroupe réellement, cette propriété doit toujours être valable pour l'échantillon de test ; c'est l'effet que nous attendons, mais l'effet sera légèrement pire.
Une question intéressante ici : dans quelle mesure SSL peut-il effectuer un clustering basé sur les catégories sémantiques d'échantillons par rapport au clustering par apprentissage supervisé ? Le panneau de droite de la figure 3 indique le taux de précision de la formation NCC et des tests à la fin de la formation pour différents scénarios (avec et sans apprentissage supervisé amélioré et SSL).
Bien que la précision de la formation NCC du classificateur supervisé soit de 1,0, ce qui est nettement supérieure à la précision de la formation NCC du modèle formé SSL, la précision du test NCC du modèle SSL est légèrement supérieure à la précision du test NCC du Dépenses de modèle supervisées. Cela montre que le comportement de clustering des deux modèles selon les catégories sémantiques est similaire dans une certaine mesure. Il est intéressant de noter que l’utilisation d’échantillons augmentés pour former un modèle supervisé réduit légèrement la précision de la formation NCC, mais améliore considérablement la précision des tests NCC.
Explorer l'impact de l'apprentissage des catégories sémantiques et du caractère aléatoire
Les catégories sémantiques définissent la relation entre l'entrée et la cible en fonction des modèles intrinsèques de l'entrée. D'un autre côté, si vous mappez les entrées sur des cibles aléatoires, vous constaterez un manque de modèles perceptibles, ce qui donne un aspect arbitraire à la connexion entre l'entrée et la cible.
Les chercheurs ont également exploré l'impact du caractère aléatoire sur la compétence de la cible requise pour l'apprentissage du modèle. Pour ce faire, ils ont construit une série de systèmes cibles avec différents degrés de hasard, puis ont examiné l’effet du hasard sur les représentations apprises. Ils ont formé un classificateur de réseau neuronal sur le même ensemble de données utilisé pour la classification, puis ont utilisé ses prédictions de cibles de différentes époques comme cibles avec différents degrés de caractère aléatoire. À l'époque 0, le réseau est complètement aléatoire et reçoit des étiquettes déterministes mais apparemment arbitraires. Au fur et à mesure que la formation progresse, le caractère aléatoire de sa fonction diminue et on obtient finalement une cible alignée sur la cible de vérité terrain (qui peut être considérée comme totalement non aléatoire). Le degré d'aléatoire est ici normalisé pour aller de 0 (pas du tout aléatoire, en fin d'entraînement) à 1 (complètement aléatoire, à l'initialisation).
Figure 4 L'image de gauche montre la précision du test linéaire pour différentes cibles aléatoires. Chaque ligne correspond à la précision des différentes étapes de formation de SSL avec différents degrés d'aléatoire. On peut voir que lors de l'entraînement, le modèle capturera plus efficacement les catégories les plus proches de la cible « sémantique » (caractère aléatoire plus faible), tout en ne montrant aucune amélioration significative des performances sur les cibles à caractère aléatoire élevé.
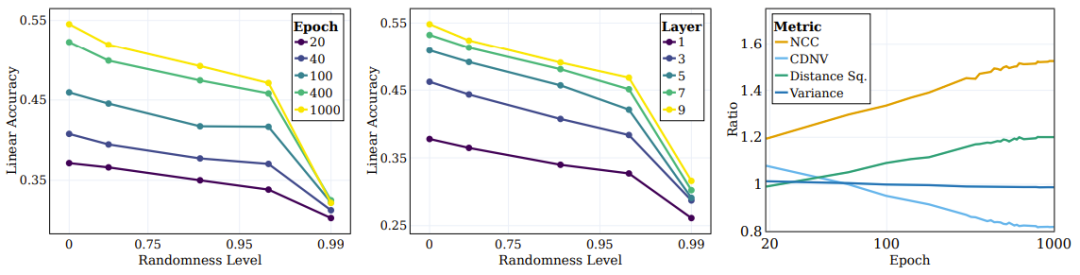
Figure 4 : SSL apprend en permanence des cibles sémantiques au lieu de cibles aléatoires
Un problème clé dans l'apprentissage profond est de comprendre le rôle des couches intermédiaires dans la classification des différents types de catégories et Influence. Par exemple, les différentes couches apprendront-elles différents types de catégories ? Les chercheurs ont également exploré cette question en évaluant la précision des tests linéaires de différentes couches de représentations à la fin de la formation à différents niveaux d’aléatoire cible. Comme le montre le panneau central de la figure 4, la précision des tests linéaires continue de s'améliorer à mesure que le caractère aléatoire diminue, les couches plus profondes étant plus performantes dans tous les types de catégories, et l'écart de performances s'agrandit pour les classifications proches des catégories sémantiques.
Les chercheurs ont également utilisé d'autres mesures pour évaluer la qualité du regroupement : la précision du NCC, le CDNV, la variance moyenne par classe et la distance quadratique moyenne entre les moyennes des classes. Pour mesurer la façon dont les représentations s'améliorent au fil de la formation, nous avons calculé le rapport de ces métriques pour les cibles sémantiques et aléatoires. Le panneau de droite de la figure 4 illustre ces ratios, qui montrent que la représentation favorise le regroupement des données basé sur des objectifs sémantiques plutôt que sur des objectifs aléatoires. Fait intéressant, on peut voir que la CDNV (variance divisée par la distance au carré) diminue simplement par la diminution de la distance au carré. Le rapport de variance est assez stable pendant l'entraînement. Cela encourage un plus grand espacement entre les clusters, un phénomène qui conduit à des améliorations de performances.
Comprendre la hiérarchie des catégories et les couches intermédiaires
Des recherches antérieures ont prouvé que dans l'apprentissage supervisé, les couches intermédiaires capturent progressivement des caractéristiques à différents niveaux d'abstraction. Les couches initiales ont tendance à être des fonctionnalités de bas niveau, tandis que les couches plus profondes capturent des fonctionnalités plus abstraites. Ensuite, les chercheurs ont examiné si les réseaux SSL pouvaient apprendre des attributs hiérarchiques à des niveaux supérieurs et quels niveaux étaient mieux corrélés à ces attributs.
Dans l'expérience, ils ont calculé la précision du test linéaire à trois niveaux : niveau de l'échantillon, 100 catégories originales et 20 super catégories. Le panneau de droite de la figure 2 donne les quantités calculées pour ces trois ensembles différents de catégories. On peut observer qu'au cours du processus de formation, l'amélioration des performances aux niveaux de la catégorie d'origine et de la super-catégorie est plus significative qu'au niveau de l'échantillon.
Vient ensuite le comportement des couches intermédiaires du modèle formé par SSL et leur capacité à capturer des objectifs à différents niveaux. Les panneaux de gauche et du milieu de la figure 5 donnent la précision du test linéaire sur toutes les couches intermédiaires à différentes étapes d'entraînement, où la cible d'origine et la super cible sont mesurées. Le panneau de droite de la figure 5 donne le rapport entre les supercatégories et les catégories originales.
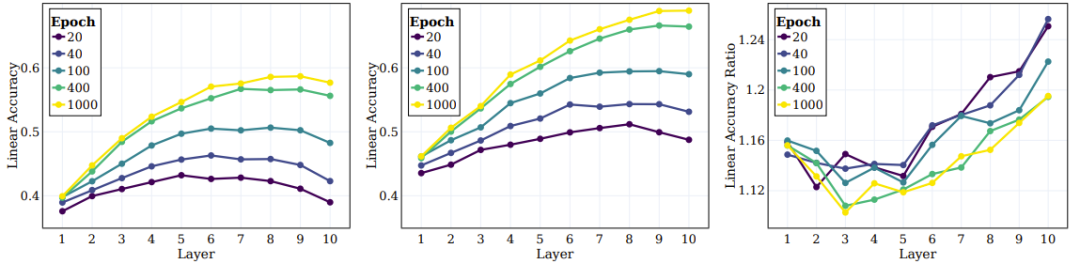
Figure 5 : SSL peut apprendre efficacement les catégories sémantiques dans la couche intermédiaire globale
Les chercheurs sont parvenus à plusieurs conclusions basées sur ces résultats. Premièrement, on peut observer qu’à mesure que la couche s’approfondit, l’effet de regroupement continue de s’améliorer. De plus, comme dans le cas de l’apprentissage supervisé, les chercheurs ont constaté que la précision linéaire de chaque couche du réseau s’améliorait lors de la formation SSL. Ils ont notamment constaté que la couche finale n’était pas la couche optimale pour la classe d’origine. Certaines recherches récentes sur SSL montrent que les tâches en aval peuvent avoir un impact important sur les performances de différents algorithmes. Nos travaux étendent cette observation et suggèrent que différentes parties du réseau peuvent être adaptées à différentes tâches et niveaux de tâches en aval. D'après le panneau de droite de la figure 5, on peut voir que dans les couches plus profondes du réseau, la précision des super catégories s'améliore davantage que celle des catégories d'origine.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI