
Maison >Périphériques technologiques >IA >Fini les soucis de « visioconférence » embarrassante ! Google CHI publiera un nouvel artefact Légendes visuelles : laissez les images être votre assistant de sous-titres
Fini les soucis de « visioconférence » embarrassante ! Google CHI publiera un nouvel artefact Légendes visuelles : laissez les images être votre assistant de sous-titres

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-12 19:10:241023parcourir
Ces dernières années, la proportion de « visioconférence » dans le travail a progressivement augmenté, et les fabricants ont également développé diverses technologies telles que les sous-titres en temps réel pour faciliter la communication entre des personnes de langues différentes lors des réunions.
Mais il y a un autre problème. Si certains noms sont mentionnés dans la conversation qui ne sont pas familiers à l'autre partie et sont difficiles à décrire avec des mots, comme la nourriture "Sukiyaki" ou "Je suis allé dans un parc pour vacances la semaine dernière" ", il est difficile de décrire les magnifiques paysages à l'autre partie avec des mots ; même en soulignant que "Tokyo est située dans la région de Kanto au Japon" et qu'une carte est nécessaire pour le montrer, etc., si vous n'utilisez que des mots, vous risquez de rendre l'autre partie de plus en plus confuse.

Récemment, Google a présenté un système de sous-titres visuels lors de la conférence la plus importante sur l'interaction homme-machine ACM CHI (Conférence sur les facteurs humains dans les systèmes informatiques), introduisant une nouvelle solution visuelle dans les réunions à distance qui peut générer ou récupérer des images dans le contexte d’une conversation pour améliorer la compréhension par l’autre de concepts complexes ou peu familiers.

Lien papier : https://research.google/pubs/pub52074/
Lien code : https://github.com/google/archat
Le système Visual Captions est basé sur un modèle de langage affiné à grande échelle qui peut recommander de manière proactive des éléments visuels pertinents dans les conversations à vocabulaire ouvert et a été intégré au projet open source ARChat.

Dans l'enquête auprès des utilisateurs, les chercheurs ont invité 26 participants en laboratoire et 10 participants en dehors du laboratoire à évaluer le système. Plus de 80 % des utilisateurs étaient fondamentalement d'accord avec le fait que les sous-titres vidéo peuvent fournir des visuels utiles et significatifs. recommandations dans divers scénarios et améliorer l’expérience de communication.
Idées de conception
Avant le développement, les chercheurs ont d'abord invité 10 participants internes, dont des ingénieurs logiciels, des chercheurs, des concepteurs UX, des artistes visuels, des étudiants et d'autres praticiens ayant une formation technique et non technique, pour discuter des besoins et des attentes spécifiques. pour des services d'amélioration visuelle en temps réel.
Après deux réunions, basées sur le système texte-image existant, la conception de base du système prototype attendu a été établie, comprenant principalement huit dimensions (notées D1 à D8).
D1 : Timing, le système d'amélioration visuelle peut être affiché de manière synchrone ou asynchrone avec le dialogue
D2 : Sujet, qui peut être utilisé pour exprimer et comprendre le contenu de la parole
D3 : Visuel, qui peut utiliser un large éventail de contenus visuels, de types visuels et de sources visuelles
D4 : Échelle, les améliorations visuelles peuvent varier en fonction de la taille de la réunion
D5 : Espace, que la vidéoconférence soit colocalisée ou dans un réglage à distance
D6 : Confidentialité, ces facteurs influencent également si les visuels doivent être affichés en privé, partagés entre les participants ou rendus publics à tous
D7 : État initial, les participants ont également identifié différentes façons dont ils aimeraient ,interagir avec le système lors de la conduite de conversations, par exemple, différents niveaux « d'initiative », c'est-à-dire que les utilisateurs peuvent déterminer de manière autonome quand le système intervient dans le chat. D8 : Interaction, les participants ont envisagé différentes méthodes d'interaction, telles que l'utilisation de la voix ou des gestes. pour votre contribution
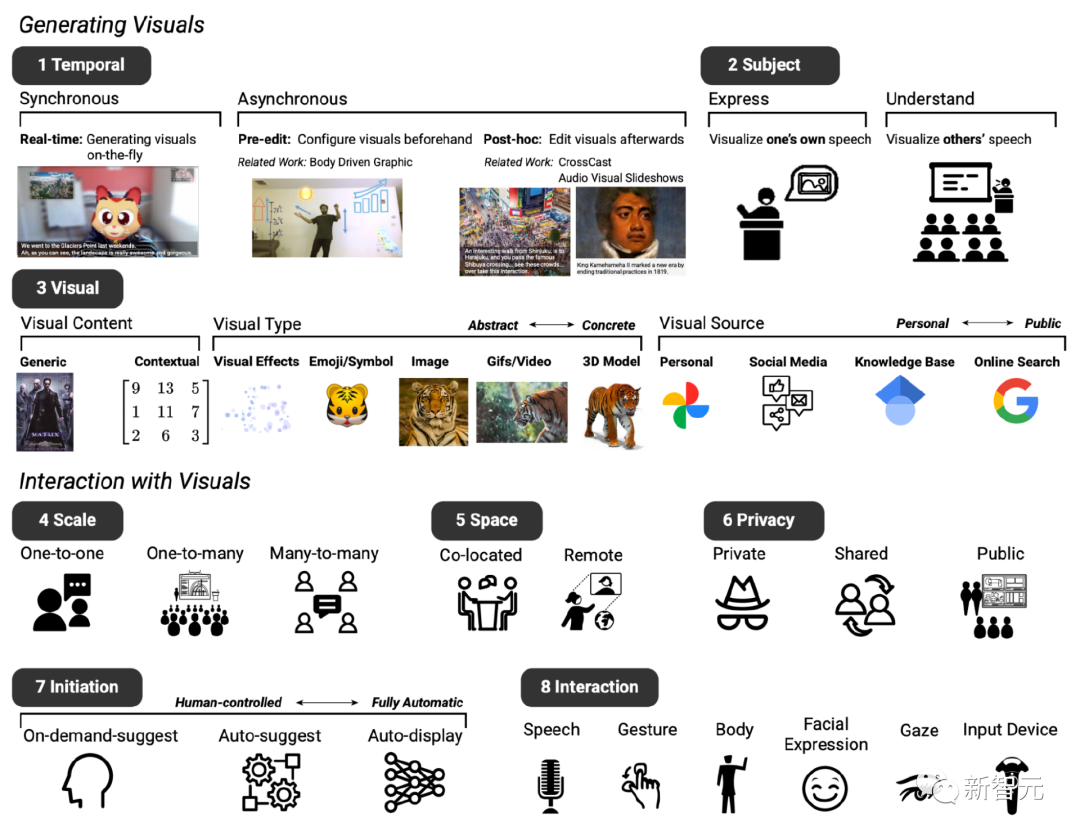
Utilisez des effets visuels dynamiques pour améliorer l'espace de conception de la communication linguistique
Sur la base de commentaires préliminaires, les chercheurs ont conçu le système de sous-titres vidéo pour se concentrer sur la génération d'effets visuels synchronisés de contenu visuel, de type et de source sémantiquement pertinents.
Bien que la plupart des idées des réunions exploratoires se concentrent sur des conversations individuelles à distance, les sous-titres vidéo peuvent également être utilisés dans des scénarios un-à-plusieurs (par exemple, présentation à un public) et plusieurs-à-plusieurs ( plusieurs personnes) se réunissent pour discuter) du déploiement.
Au-delà de cela, les visuels qui complètent le mieux la conversation dépendent fortement du contexte de la discussion, un ensemble de formation spécialement conçu est donc nécessaire.
Les chercheurs ont collecté 1 595 quadruples, comprenant la langue, le contenu visuel, le type, la source, couvrant divers scénarios contextuels, notamment des conversations quotidiennes, des conférences, des guides de voyage, etc.
Par exemple, l'utilisateur dit "J'adorerais le voir !" (J'adorerais le voir !) correspondant au contenu visuel de "visage souriant", au type visuel de "emoji" et "Source visuelle pour la recherche publique.
"Vous a-t-elle parlé de notre voyage au Mexique ?" correspond au contenu visuel de "Photos d'un voyage au Mexique", au type visuel de "Photo" et à la source visuelle de "Album personnel".
L'ensemble de données VC 1.5K est actuellement open source.
Lien de données : https://github.com/google/archat/tree/main/dataset
Modèle de prédiction d'intention visuelle
Pour prédire quels visuels peuvent compléter la conversation, Les chercheurs ont utilisé l’ensemble de données VC1.5K pour former un modèle de prédiction d’intention visuelle basé sur un grand modèle de langage.
Dans la phase de formation, chaque intention visuelle est analysée au format "

Basé sur ce format, le système peut gérer une conversation de vocabulaire ouverte et une prédiction contextuelle du contenu visuel, de la source visuelle et du type visuel.

Cette approche est également meilleure que l'approche basée sur des mots-clés dans la pratique, car cette dernière ne peut pas gérer des exemples de vocabulaire ouverts, tels que l'utilisateur pourrait dire "Ta tante Amy sera là ce samedi". « Visite », aucun mot-clé ne correspond et les types visuels ou sources visuelles pertinents ne peuvent pas être recommandés.
Les chercheurs ont utilisé 1 276 (80 %) échantillons dans l'ensemble de données VC1.5K pour affiner le grand modèle de langage, et les 319 échantillons (20 %) restants comme données de test, et ont utilisé la métrique de précision des jetons pour mesurer la performances du modèle affiné, c'est-à-dire le pourcentage correct de jetons dans les échantillons correctement prédit par le modèle.
Le modèle final peut atteindre une précision de 97 % des jetons de formation et une précision de 87 % des jetons de vérification.
Enquête pratique
Afin d'évaluer le caractère pratique du modèle de sous-titres visuels formé, l'équipe de recherche a invité 89 participants à effectuer 846 tâches et il leur a été demandé d'évaluer l'effet, 1 étant fortement en désaccord et 7 tout à fait d'accord.
Les résultats expérimentaux montrent que la plupart des participants préfèrent voir des effets visuels dans les conversations (Q1), et 83 % ont donné une évaluation de 5 - plutôt d'accord ou plus.
De plus, les participants ont estimé que les visuels affichés étaient utiles et informatifs (Q2), avec 82% donnant une note supérieure à 5 points et de haute qualité (Q3), avec 82% une note supérieure à 5 points ; ; et lié à la voix originale (Q4, 84%).
Les participants ont également constaté que le type visuel prédit (Q5, 87 %) et la source visuelle (Q6, 86 %) étaient exacts dans le contexte de la conversation correspondante.
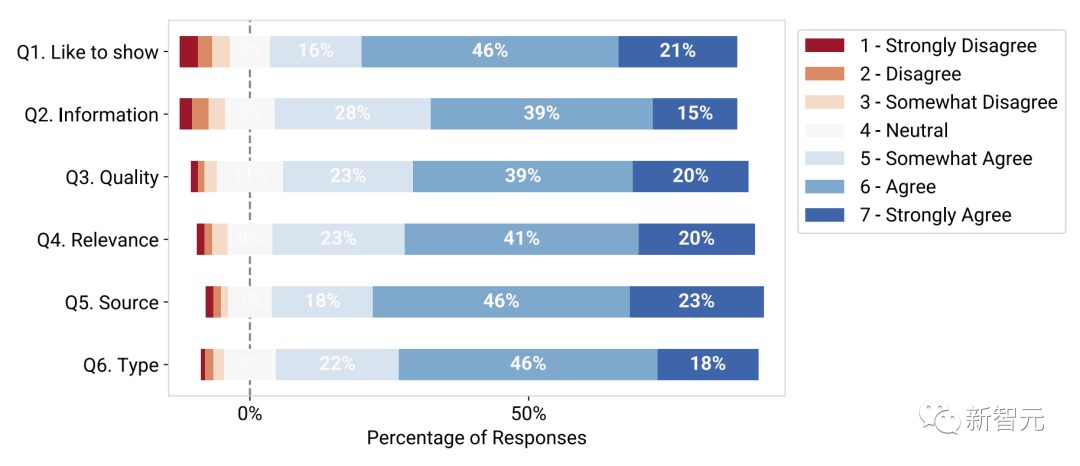
Évaluation technique des modèles de prédiction visuelle par les participants à l'étude les résultats sont notés
Sur la base de ce modèle de prédiction d'intention visuelle affiné, les chercheurs ont développé des légendes visuelles sur la plateforme ARChat, qui peuvent être directement utilisées sur la plateforme de visioconférence (Ajouter de nouveaux widgets interactifs sur les flux de caméras comme Google Meet).
Dans le flux de travail du système, les sous-titres vidéo peuvent automatiquement capturer la voix de l'utilisateur, récupérer la dernière phrase et saisir les données dans le modèle de prédiction d'intention visuelle toutes les 100 millisecondes. visuels, puis fournissez les visuels recommandés.
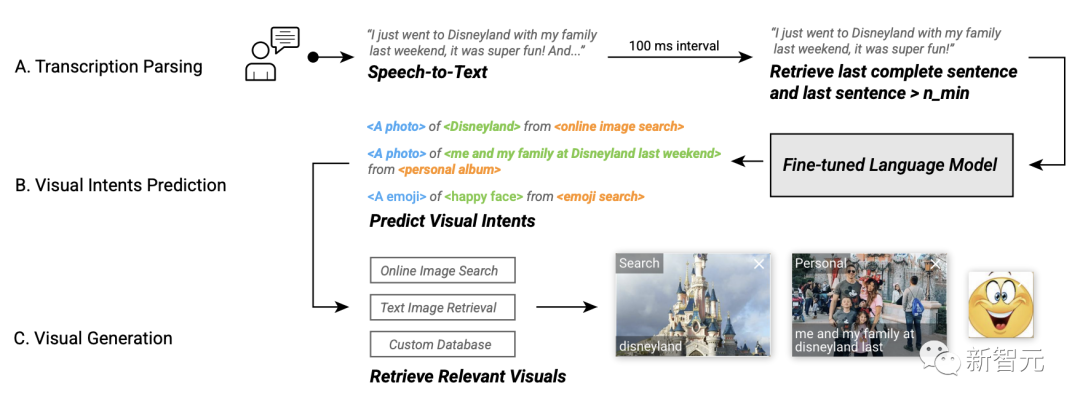
Flux de travail du système de sous-titres visuels # 🎜🎜#
Visual Captions propose trois niveaux d'initiative optionnelle lors de la recommandation de visuels :
Affichage automatique (haute initiative) : Le système recherche et affiche de manière autonome des visuels publiquement à tous les participants à la réunion, sans interaction de l'utilisateur.
Auto-recommandation (initiative moyenne) : Les visuels recommandés sont affichés dans une vue déroulante privée, puis l'utilisateur clique sur un visuel pour l'afficher publiquement dans ce mode ; , le système recommande des éléments visuels de manière proactive, mais l'utilisateur décide quand et quoi afficher.
Suggestions à la demande (faible initiative) : le système ne recommandera des effets visuels qu'après que l'utilisateur ait appuyé sur la barre d'espace.
Les chercheurs ont évalué le système de sous-titres visuels dans le cadre d'une étude contrôlée en laboratoire (n = 26) et d'une étude de déploiement en phase de test (n = 10), et les participants ont découvert que, dans Les visuels en temps réel facilitent les conversations en direct en aidant à expliquer des concepts inconnus, à résoudre les ambiguïtés linguistiques et à rendre les conversations plus engageantes. Indice de charge de tâche des participants et évaluation sur l'échelle de Likert, y compris l'absence de VC et VC avec trois initiatives différentes
Les participants ont également signalé différentes préférences système lors de l'interaction sur site, c'est-à-dire utiliser différents niveaux d'initiative VC dans différents scénarios de réunion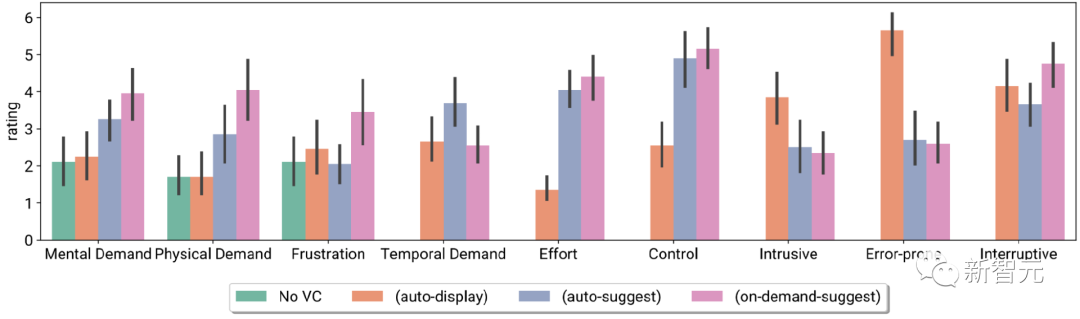
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI