
Maison >Périphériques technologiques >IA >DeepMind réécrit l'algorithme de tri avec l'IA ; regroupe un grand modèle de 33 B dans un seul GPU grand public.
DeepMind réécrit l'algorithme de tri avec l'IA ; regroupe un grand modèle de 33 B dans un seul GPU grand public.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-12 18:49:571482parcourir
Table des matières :
- Des algorithmes de tri plus rapides découverts grâce à l'apprentissage par renforcement profond
- Video-LLaMA : un modèle de langage audiovisuel adapté aux instructions pour la compréhension de la vidéo
- Patch - Génération de scènes naturelles 3D à partir d'un seul exemple Generation In the Wild
- FrugalGPT : Comment utiliser de grands modèles de langage tout en réduisant les coûts et en améliorant les performances
- Article 1 : Des algorithmes de tri plus rapides découverts grâce à l'apprentissage par renforcement profond
- Auteur : Daniel J . Mankowitz Attendez
Adresse papier : https://www.nature.com/articles/s41586-023-06004-9
- Résumé : "En échangeant et en copiant des mouvements, AlphaDev saute. Une étape qui relie les projets d’une manière qui semble erronée mais qui est en réalité un raccourci. Cette pensée inédite et contre-intuitive rappelle le printemps 2016.
- Il y a sept ans, AlphaGo battait le champion du monde humain au Go, et maintenant l'IA nous a appris une autre leçon de programmation. Deux phrases du PDG de Google DeepMind, Hassabis, ont déclenché le domaine informatique : "AlphaDev a découvert un nouvel algorithme de tri plus rapide, et nous l'avons open source dans la bibliothèque principale C++ pour que les développeurs puissent l'utiliser. Il s'agit simplement d'une IA qui améliore l'efficacité du code. Le début de progrès. "
Recommandation :
L'IA réécrit l'algorithme de tri, 70 % plus rapidement : DeepMind AlphaDev révolutionne les bases informatiques et la bibliothèque est mise à jour des milliards de fois par jour
Paper. 2 : Vidéo-LLaMA : Un modèle de langage audiovisuel adapté aux instructions pour la compréhension de la vidéo
Auteur : Hang Zhang et al
Adresse papier : https://arxiv.org/abs/ 2306.02858
- Résumé : Récemment, de grands modèles de langage ont démontré des capacités impressionnantes. Peut-on équiper les grands modèles d’« yeux » et d’« oreilles » pour qu’ils puissent comprendre les vidéos et interagir avec les utilisateurs ?
- Partant de ce problème, des chercheurs de la DAMO Academy ont proposé Video-LLaMA, un grand modèle doté de capacités audiovisuelles complètes. Video-LLaMA peut percevoir et comprendre les signaux vidéo et audio dans les vidéos, et peut comprendre les instructions de saisie de l'utilisateur pour effectuer une série de tâches complexes basées sur l'audio et la vidéo, telles que la description audio/vidéo, l'écriture, les questions et réponses, etc. Actuellement, les articles, les codes et les démos interactives sont tous ouverts. De plus, sur la page d'accueil du projet Video-LLaMA, l'équipe de recherche propose également une version chinoise du modèle pour rendre l'expérience des utilisateurs chinois plus fluide.
Recommandé : Ajoutez des capacités audiovisuelles complètes aux grands modèles de langage, DAMO Academy open source Video-LLaMA.
Papier 3 : Génération de scènes naturelles 3D à partir de patchs à partir d'un seul exemple
 Auteur : Weiyu Li et al avec l'Université du Shandong et les chercheurs du Tencent AI Lab ont proposé la première méthode pour générer diverses scènes 3D de haute qualité sans formation basée sur des scènes à échantillon unique.
Auteur : Weiyu Li et al avec l'Université du Shandong et les chercheurs du Tencent AI Lab ont proposé la première méthode pour générer diverses scènes 3D de haute qualité sans formation basée sur des scènes à échantillon unique.
- Recommandé : CVPR 2023 | Génération de scènes 3D : générez divers résultats à partir d'un seul échantillon sans aucune formation de réseau neuronal.
Auteur : Yuan Yuan et al
Adresse de l'article : https://arxiv.org/abs/2305.12403
Résumé :
Le Centre de recherche en sciences urbaines et en informatique du Département d'ingénierie électronique de l'Université Tsinghua a récemment proposé le processus de point de diffusion spatio-temporelle, qui dépasse les limites des méthodes existantes telles que les formes probabilistes restreintes et les coûts d'échantillonnage élevés pour la modélisation. processus ponctuels spatio-temporels et permet d'obtenir un modèle de processus ponctuel spatio-temporel flexible, efficace et facile à calculer peut être largement utilisé dans la modélisation et la prévision d'événements spatio-temporels tels que les catastrophes naturelles urbaines, les urgences et les activités des résidents, et promeut le développement intelligent de la planification et de la gestion urbaine. Le tableau suivant montre les avantages du DSTPP par rapport aux solutions de processus ponctuels existantes.- Recommandé : Les modèles de diffusion peuvent-ils prédire les tremblements de terre et la criminalité ? Les dernières recherches de l’équipe Tsinghua proposent un processus ponctuel de diffusion spatio-temporelle.
Auteur : Tim Dettmers et al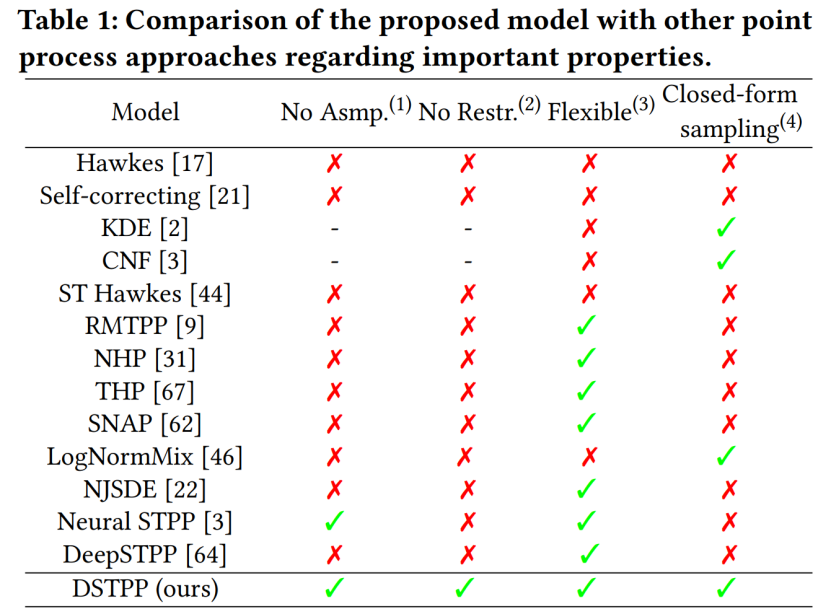
Adresse de l'article : https://arxiv . org /pdf/2306.03078.pdf
Résumé :
Afin de résoudre le problème de précision, des chercheurs de l'Université de Washington, de l'ETH Zurich et d'autres institutions ont proposé un nouveau format de compression et une technologie de quantification SpQR (Sparse-Quantitative représentation), obtenant pour la première fois une compression quasiment sans perte de LLM à toutes les échelles du modèle tout en atteignant des niveaux de compression similaires à ceux des méthodes précédentes.- SpQR fonctionne en identifiant et en isolant les poids anormaux qui provoquent des erreurs de quantification particulièrement importantes, en les stockant avec une plus grande précision tout en compressant tous les autres poids à 3-4 bits, dans LLaMA. Une perte de précision relative de moins de 1 % de perplexité a été obtenue dans et les LLM Falcon. Exécutez un LLM de paramètres 33B sur un seul GPU grand public de 24 Go sans aucune dégradation des performances tout en étant 15 % plus rapide. La figure 3 ci-dessous montre l'architecture globale de SpQR.
"Intégrez un grand modèle de 33 milliards de paramètres dans" un seul GPU grand public, accélérant de 15 % sans sacrifier les performances.
Papier 6 : UniControl : Un modèle de diffusion unifié pour la génération visuelle contrôlable dans la nature
- Auteur : Can Qin et al
- Adresse papier : https://arxiv.org/abs/2305.11147
Résumé : Dans cet article, Salesforce AI, Northeastern , Université de Stanford Les chercheurs ont proposé un adaptateur de type MOE et un HyperNet prenant en charge les tâches pour réaliser la capacité de génération de conditions multimodales dans UniControl. UniControl est formé sur neuf tâches C2I différentes, démontrant de solides capacités de génération visuelle et des capacités de généralisation sans tir. Le modèle UniControl se compose de plusieurs tâches de pré-formation et de tâches sans tir.

Recommandé : Le modèle unifié pour la génération d'images contrôlables multimodales est ici, et les paramètres du modèle et le code d'inférence sont tous open source.
Papier 7 : FrugalGPT : Comment utiliser de grands modèles de langage tout en réduisant les coûts et en améliorant les performances
- Auteur : Lingjiao Chen et al
- Adresse du papier : https://arxiv. org /pdf/2305.05176.pdf
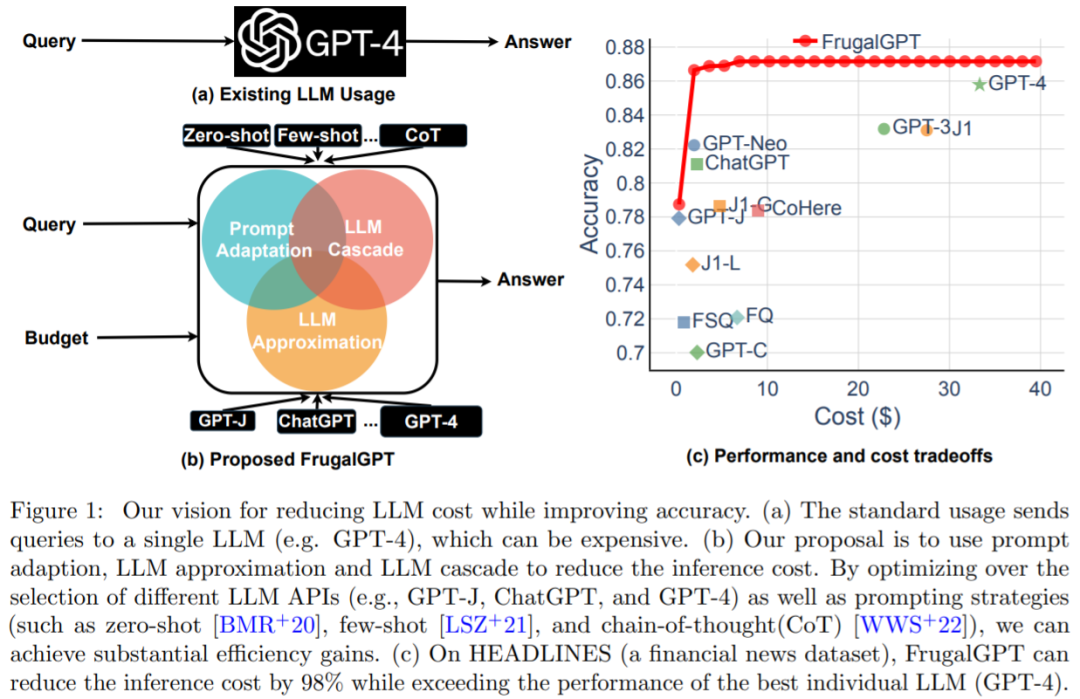
Résumé : L'équilibre entre coût et précision est un facteur clé dans la prise de décision, en particulier lors de l'adoption de nouvelles technologies. Comment utiliser efficacement le LLM est un défi clé pour les praticiens : si la tâche est relativement simple, alors l'agrégation de plusieurs réponses de GPT-J (qui est 30 fois plus petite que GPT-3) peut obtenir des performances similaires à celles de GPT-3, parvenir à un compromis en termes de coûts et d’environnement. Cependant, sur des tâches plus difficiles, les performances de GPT-J peuvent se dégrader considérablement. Par conséquent, de nouvelles approches sont nécessaires pour utiliser le LLM de manière rentable.
Une étude récente a tenté de proposer une solution à ce problème de coût. Les chercheurs ont montré expérimentalement que FrugalGPT peut rivaliser avec les performances du meilleur LLM individuel (comme le GPT-4), avec une réduction des coûts allant jusqu'à 98 %. , ou Améliorer la précision du meilleur LLM individuel de 4 % au même coût. Cette étude discute de trois stratégies de réduction des coûts, à savoir l'adaptation rapide, l'approximation LLM et la cascade LLM.
Recommandé : Remplacement de l'API GPT-4 ? Les performances sont comparables et le coût est réduit de 98 %. Stanford a proposé FrugalGPT, mais la recherche était controversée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI