
Maison >Périphériques technologiques >IA >OlaGPT, le premier cadre de pensée qui simule la cognition humaine : six modules améliorent le modèle de langage et augmentent les capacités de raisonnement jusqu'à 85 %
OlaGPT, le premier cadre de pensée qui simule la cognition humaine : six modules améliorent le modèle de langage et augmentent les capacités de raisonnement jusqu'à 85 %

- 王林avant
- 2023-06-05 16:17:491459parcourir
ChatGPT nous a trop choqués lors de sa première sortie. La performance du modèle dans le dialogue était si humaine qu'elle a créé l'illusion que le modèle de langage avait une « capacité de réflexion ».
Cependant, après une compréhension approfondie des modèles de langage, les chercheurs ont progressivement découvert que la reproduction basée sur des modèles de langage à haute probabilité est encore loin de « l'intelligence artificielle générale » attendue.
Dans la plupart des recherches actuelles, les modèles linguistiques à grande échelle génèrent principalement des chaînes de pensée sous la direction d'invites spécifiques pour effectuer des tâches de raisonnement, sans tenir compte du cadre cognitif humain, permettant aux modèles linguistiques de résoudre des problèmes de raisonnement complexes. Il existe toujours un écart important entre les capacités des humains et celles des humains.
Lorsque les humains sont confrontés à des problèmes de raisonnement complexes, ils utilisent généralement diverses capacités cognitives et doivent interagir avec tous les aspects des outils, des connaissances et des informations de l'environnement externe. Les modèles linguistiques peuvent-ils simuler les humains ? résoudre des problèmes complexes ?
La réponse est bien sûr oui ! Le premier modèle OlaGPT qui simule le cadre de traitement cognitif humain est là !

Lien papier : https://arxiv.org/abs/2305.16334
Lien code : https://www .php.cn/link/73a1c863a54653d5e184b790fee14754
OlaGPT comprend plusieurs modules cognitifs, notamment l'attention, la mémoire, le raisonnement, l'apprentissage et les mécanismes de planification et de prise de décision correspondants inspirés de l'apprentissage actif humain, le cadre est également inclus ; est une unité d'apprentissage pour enregistrer les erreurs précédentes et les opinions d'experts, avec une référence dynamique pour améliorer votre capacité à résoudre des problèmes similaires.
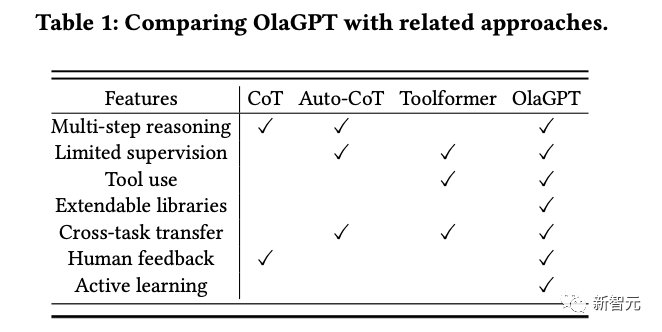
L'article décrit également des cadres de raisonnement communs et efficaces permettant aux humains de résoudre des problèmes et conçoit le modèle de chaîne de pensée (CoT) en conséquence ; un mécanisme de prise de décision complet peut maximiser la précision du modèle.
Les résultats expérimentaux obtenus après une évaluation rigoureuse sur plusieurs ensembles de données d'inférence montrent qu'OlaGPT surpasse les précédents benchmarks de pointe et prouve son efficacité.
Simulation de la cognition humaine
Il existe encore un grand écart entre le modèle de langage actuel et l'intelligence artificielle générale attendue, principalement comme suit :
1 Dans certains cas, le contenu généré n'a aucun sens ou s'écarte des préférences de valeurs humaines, et peut même donner des suggestions très dangereuses. La solution actuelle consiste à introduire un apprentissage par renforcement avec retour humain (RLHF) pour effectuer un entraînement sur la sortie du modèle. .
2. Les connaissances du modèle de langage sont limitées aux concepts et faits explicitement mentionnés dans les données de formation.
Lorsqu'ils sont confrontés à des problèmes complexes, les modèles de langage ne peuvent pas s'adapter à des environnements changeants, utiliser les connaissances ou les outils existants, réfléchir aux leçons historiques, décomposer les problèmes et utiliser les humains pour résumer l'évolution à long terme comme les humains. les schémas de pensée (tels que les analogies, le raisonnement inductif, le raisonnement déductif, etc.) pour résoudre des problèmes.
Cependant, il existe encore de nombreux problèmes système liés au fait de laisser les modèles de langage simuler le processus des problèmes de traitement du cerveau humain :
1. cadre cognitif humain, tout en planifiant selon des schémas de raisonnement humain communs d'une manière réalisable ?
2. Comment guider les modèles de langage pour apprendre activement comme les humains, c'est-à-dire apprendre et évoluer à partir d'erreurs historiques ou de solutions expertes à des problèmes difficiles ?
Bien qu'il soit possible de recycler le modèle pour encoder les réponses corrigées, cela est évidemment très coûteux et peu flexible.
3. Comment faire en sorte que les modèles de langage utilisent de manière flexible divers modes de pensée développés par les humains pour améliorer leurs performances de raisonnement ?
Un modèle de pensée fixe et universel est difficile à adapter à différents problèmes. Tout comme lorsque les humains sont confrontés à différents types de problèmes, ils choisissent généralement de manière flexible différentes façons de penser, telles que le raisonnement analogique et le raisonnement déductif. .
OlaGPT
OlaGPT est un framework de résolution de problèmes qui simule la pensée humaine et peut améliorer les capacités des grands modèles de langage.
OlaGPT s'appuie sur la théorie de l'architecture cognitive et modélise les capacités fondamentales du cadre cognitif telles que l'attention, la mémoire, l'apprentissage et le raisonnement, et la sélection d'actions.
Les chercheurs ont affiné le framework en fonction des besoins d'implémentation spécifiques et ont proposé un processus adapté aux modèles de langage pour résoudre des problèmes complexes, qui comprend spécifiquement six modules : module d'amélioration d'intention (attention), module de mémoire (mémoire), module d'apprentissage actif (apprentissage), module de raisonnement (raisonnement), module contrôleur (sélection d'action) et module de vote.
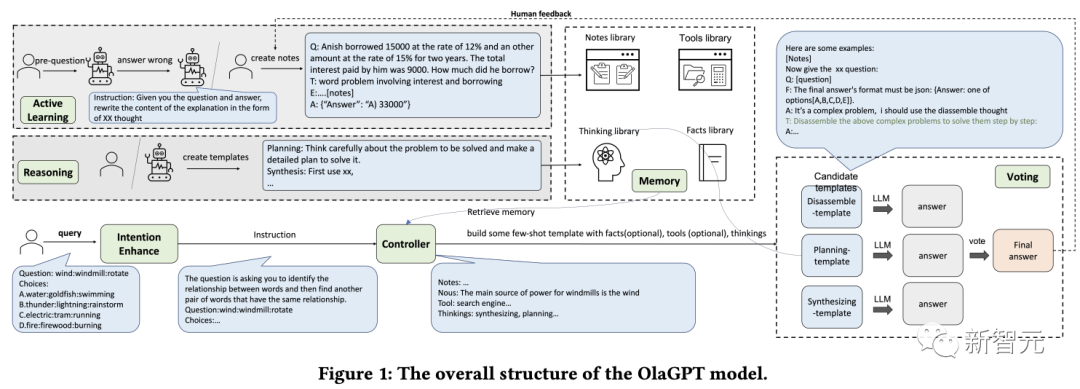
Intention Enhance
L'attention est une partie importante de la cognition humaine, identifiant les informations pertinentes et filtrant les données non pertinentes.
De même, les chercheurs ont conçu un module d'attention correspondant pour le modèle de langage, à savoir l'amélioration de l'intention, qui vise à extraire les informations les plus pertinentes et à établir une association plus forte entre la saisie de l'utilisateur et le modèle de langage du modèle, qui peut être considéré comme un module d'attention. convertisseur optimisé des habitudes d'expression des utilisateurs aux habitudes d'expression du modèle.
Tout d'abord, obtenez à l'avance les types de questions des LLM grâce à des mots d'invite spécifiques, puis reconstruisez la manière de poser les questions.

Par exemple, ajoutez "Donnez-vous maintenant le XX (type de question), la question et les choix :" au début de la question, afin de faciliter l'analyse, vous devez également ajouter "La réponse doit se terminer par JSON ; format : Réponse :" à l'invite. l'une des options [A, B, C, D, E].」

Mémoire
Le module de mémoire joue un rôle essentiel dans le stockage de diverses informations de la base de connaissances, qui ont été prouvé par la recherche Les modèles de langage actuels sont limités dans la compréhension des dernières données factuelles, tandis que le module de mémoire se concentre sur la consolidation des connaissances qui n'ont pas encore été internalisées par le modèle et sur leur stockage dans une bibliothèque externe en tant que mémoire à long terme.
Les chercheurs ont utilisé la fonction de mémoire de langchain pour la mémoire à court terme, puis ont utilisé la base de données vectorielles basée sur Faiss pour obtenir une mémoire à long terme.
Pendant le processus de requête, sa fonction de recherche peut extraire des connaissances pertinentes de la bibliothèque, couvrant quatre types de bibliothèques de mémoire : faits, outils, notes et réflexion, où les faits sont des informations du monde réel, telles que le bon sens, etc. ; inclure des moteurs de recherche, des calculatrices et Wikipédia, qui peuvent aider les modèles de langage à effectuer des travaux qui ne nécessitent pas d'édition ; les notes enregistrent principalement certains cas difficiles et les étapes pour résoudre des problèmes ; la bibliothèque de réflexion stocke principalement des modèles de réflexion pour la résolution de problèmes humains rédigés par des experts ; Les experts peuvent être des humains ou des modèles.
Apprentissage
La capacité d'apprendre est cruciale pour que les humains améliorent continuellement leurs performances personnelles. Essentiellement, toutes les formes d'apprentissage reposent sur l'expérience et les modèles de langage peuvent apprendre des erreurs précédentes, permettant ainsi d'améliorer rapidement leurs capacités de raisonnement.
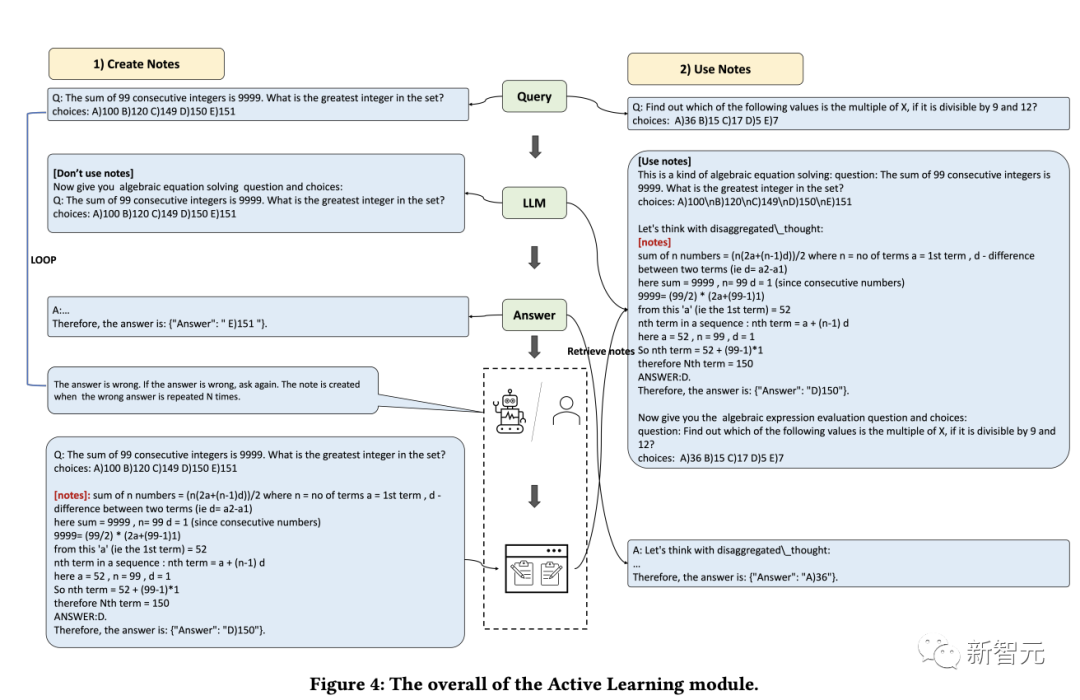
Tout d'abord, les chercheurs découvrent les problèmes que le modèle de langage ne peut pas résoudre ; puis enregistrent les idées et les explications fournies par les experts dans la bibliothèque de notes et enfin sélectionnent les notes pertinentes pour favoriser l'apprentissage du modèle de langage, afin qu'il puisse être utilisé. peut gérer des problèmes similaires plus efficacement.
Raisonnement
Le but du module de raisonnement est de créer plusieurs agents basés sur le processus de raisonnement humain, stimulant ainsi la capacité de réflexion potentielle du modèle de langage et résolvant les problèmes de raisonnement.
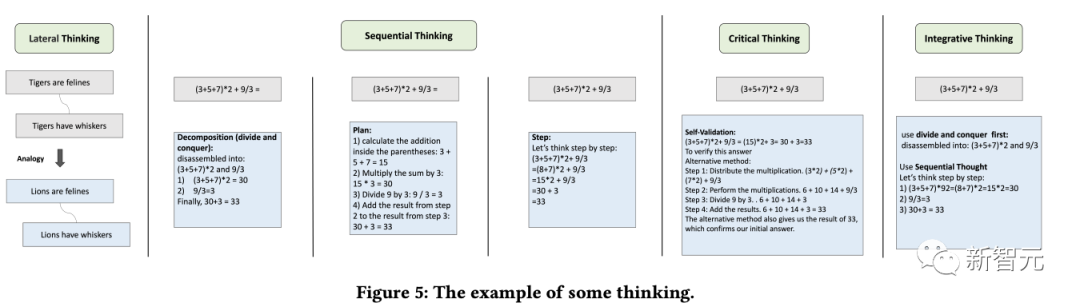
Ce module combine plusieurs modèles de pensée en référence à des types de pensée spécifiques tels que la pensée latérale, la pensée séquentielle, la pensée critique et la pensée intégrative pour faciliter les tâches de raisonnement.
Contrôleur
Le module contrôleur est principalement utilisé pour gérer les sélections d'actions associées, y compris les tâches de planification interne du modèle (telles que la sélection de certains modules à exécuter) et la sélection parmi des faits, des outils, des notes et des bibliothèques de réflexion.
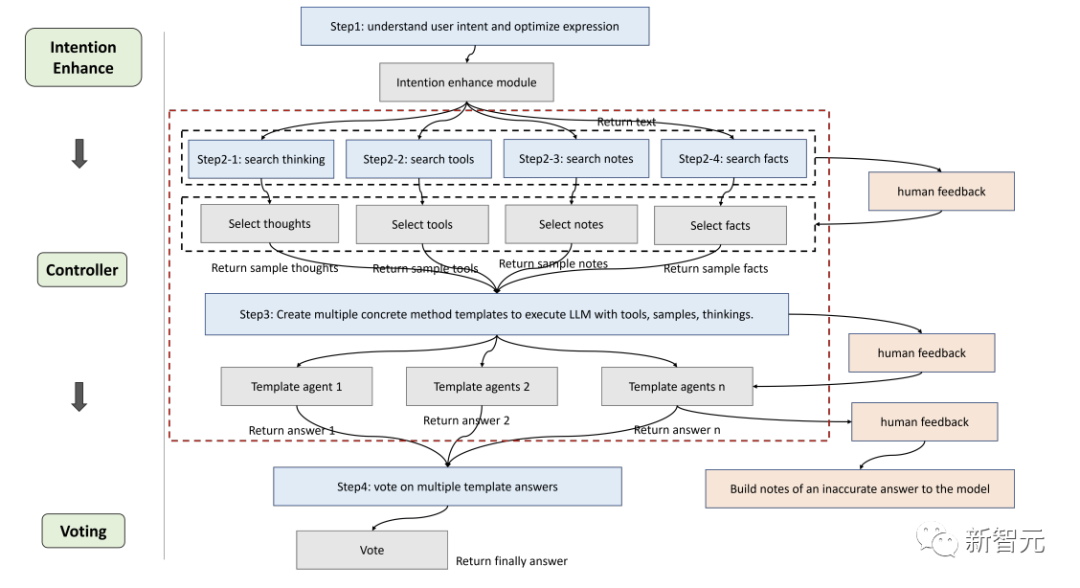
Les bibliothèques pertinentes sont d'abord récupérées et mises en correspondance, et le contenu récupéré est ensuite intégré dans un agent modèle, obligeant le modèle de langage à fournir des réponses sous un modèle de manière asynchrone, tout comme les humains peuvent avoir des difficultés au début de raisonnement En plus d'identifier toutes les informations pertinentes, il est également difficile de s'attendre à ce qu'un modèle de langage fasse cela en premier lieu.
Par conséquent, la récupération dynamique est mise en œuvre en fonction des questions de l'utilisateur et de la progression du raisonnement intermédiaire, en utilisant la méthode Faiss pour créer des index intégrés pour les quatre bibliothèques ci-dessus, où les stratégies de récupération de chaque bibliothèque sont légèrement différentes.
Vote
Étant donné que différents modèles de réflexion peuvent être plus adaptés à différents types de questions, les chercheurs ont conçu le module de vote pour améliorer la capacité d'étalonnage intégrée entre plusieurs modèles de réflexion et utiliser plusieurs stratégies de vote pour générer les meilleures réponses afin d'améliorer les performances.
Les méthodes de vote spécifiques incluent :
1. Vote sur le modèle de langage : guidez le modèle de langage pour sélectionner la réponse la plus cohérente parmi plusieurs options proposées et fournissez une raison.
2. Vote Regex : utilisez la correspondance exacte d'expressions régulières pour extraire les réponses afin d'obtenir les résultats du vote.
Résultats expérimentaux
Pour évaluer l'efficacité de ce cadre de modèle de langage amélioré dans les tâches d'inférence, les chercheurs ont mené une comparaison expérimentale complète sur deux types d'ensembles de données d'inférence.
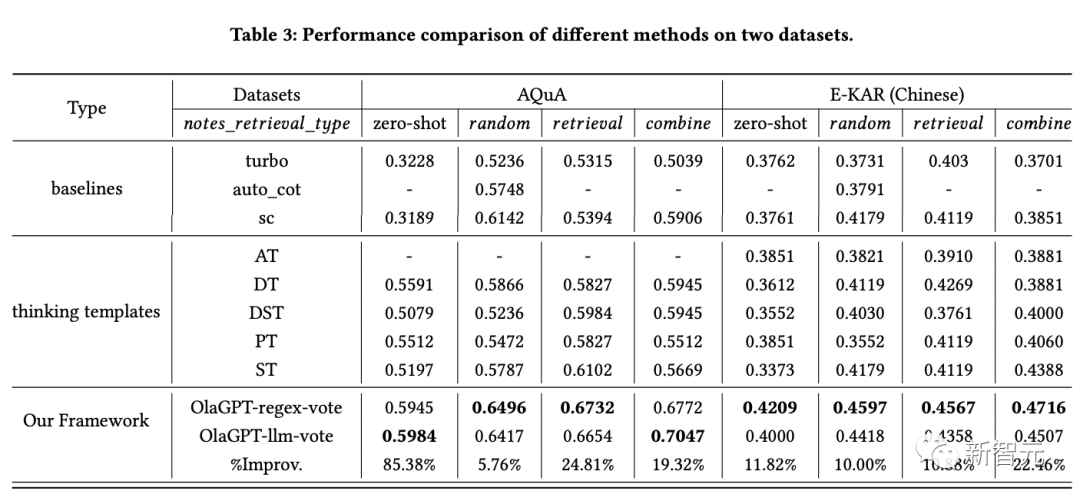
Les résultats le montrent :
1. SC (auto-cohérence) fonctionne mieux que GPT-3.5-turbo, ce qui indique que l'adoption d'une approche d'ensemble contribue dans une certaine mesure à améliorer l'efficacité des projets à grande échelle. modèles .
2. Les performances de la méthode proposée dans l'article dépassent SC, ce qui prouve dans une certaine mesure l'efficacité de la stratégie du modèle de réflexion.
Les réponses aux différents modèles de réflexion montrent des différences considérables, et voter selon différents modèles de réflexion produira en fin de compte de meilleurs résultats que de simplement procéder à plusieurs tours de vote.
3. Différents modèles de réflexion ont des effets différents, et les solutions étape par étape peuvent être plus adaptées aux problèmes de raisonnement.
4. Les performances du module d'apprentissage actif sont nettement meilleures que la méthode à échantillon zéro.
L'inclusion de cas difficiles dans la bibliothèque de notes, l'utilisation de listes aléatoires, de récupération et de combinaisons pour améliorer les performances est une stratégie réalisable.
5. Différents schémas de récupération ont des effets différents sur différents ensembles de données. En général, la stratégie de combinaison donne de meilleurs résultats.
6. La méthode de cet article est évidemment meilleure que les autres solutions, ce qui est dû à la conception raisonnable du cadre global, y compris la conception efficace du module d'apprentissage actif qui réalise l'adaptation aux différents modèles ; les résultats sous différents modèles de réflexion sont différents ; le module contrôleur joue un très bon rôle de contrôle et sélectionne le contenu qui correspond au contenu requis ; la méthode d'intégration des différents modèles de réflexion conçus par le module de vote est efficace ;
Référence :
https://www.php.cn/link/73a1c863a54653d5e184b790fee14754
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI