
Maison >Périphériques technologiques >IA >Cambridge, Tencent AI Lab et d'autres ont proposé le grand modèle de langage PandaGPT : un modèle unifie six modalités
Cambridge, Tencent AI Lab et d'autres ont proposé le grand modèle de langage PandaGPT : un modèle unifie six modalités

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-05 12:19:51873parcourir
Des chercheurs de Cambridge, du NAIST et de Tencent AI Lab ont récemment publié un résultat de recherche appelé PandaGPT, une méthode qui aligne et lie de grands modèles de langage avec différentes modalités pour obtenir des capacités de suivi d'instructions multimodales. PandaGPT peut accomplir des tâches complexes telles que générer des descriptions d'images détaillées, écrire des histoires à partir de vidéos et répondre à des questions sur l'audio. Il peut recevoir des entrées multimodales simultanément et combiner naturellement leur sémantique. Page d'accueil du projet T : https://panda-gpt.github.io/

- Papier : http://arxiv.org /abs/2305.16355
- Affichage de démonstration en ligne : https://huggingface.co/spaces/GMFTBY/PandaGPT
- Dans la commande pour atteindre les capacités de suivi d'instruction en six modes : image et vidéo, texte, audio, carte thermique, carte de profondeur et lectures IMU, PandaGPT combine l'encodeur multimodal d'ImageBind avec le grand modèle de langage Vicuna (comme indiqué ci-dessus).
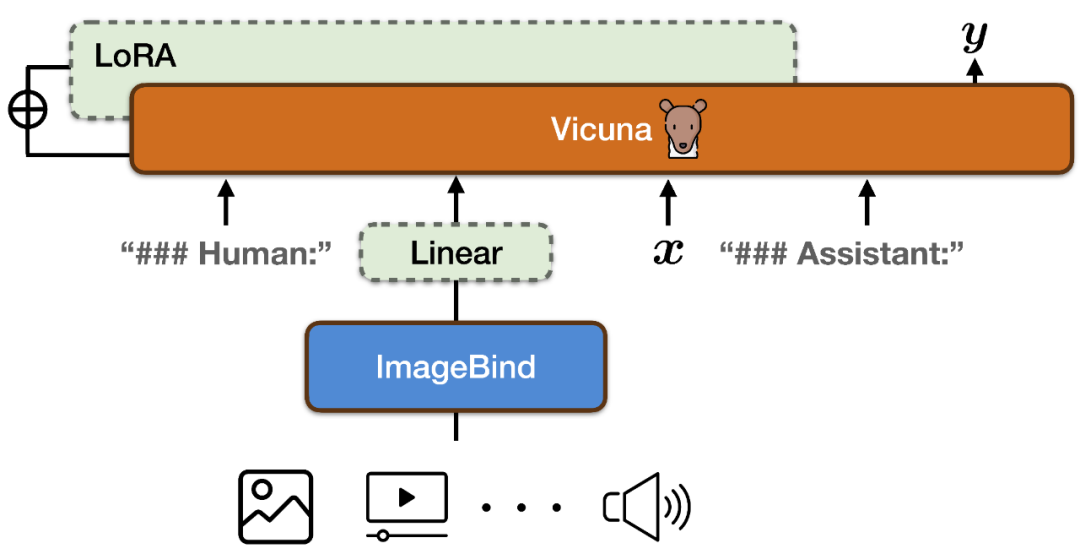 Pour aligner les espaces de fonctionnalités de l'encodeur multimodal d'ImageBind et le modèle de langage à grande échelle de Vicuna, PandaGPT a utilisé un total de 160 000 instructions de langage basées sur des images à la suite des données publiées en combinant LLaVa et Mini-GPT4 comme données de formation. Chaque instance de formation se compose d'une image et d'un ensemble correspondant de cycles de dialogue.
Pour aligner les espaces de fonctionnalités de l'encodeur multimodal d'ImageBind et le modèle de langage à grande échelle de Vicuna, PandaGPT a utilisé un total de 160 000 instructions de langage basées sur des images à la suite des données publiées en combinant LLaVa et Mini-GPT4 comme données de formation. Chaque instance de formation se compose d'une image et d'un ensemble correspondant de cycles de dialogue.
Afin d'éviter de détruire les propriétés d'alignement multimodal d'ImageBind lui-même et de réduire les coûts de formation, PandaGPT a uniquement mis à jour les modules suivants :
Ajoutez une nouvelle matrice de projection linéaire au résultat d'encodage d'ImageBind pour représenter le représentation générée par ImageBind Après la conversion, elle est insérée dans la séquence d'entrée de Vicuna ;
Ajoute des poids LoRA supplémentaires au module d'attention de Vicuna ; Le nombre total de paramètres des deux représente environ 0,4 % des paramètres de Vicuna. La fonction de formation est un objectif traditionnel de modélisation linguistique. Il convient de noter que pendant le processus de formation, seul le poids de la partie correspondante de la sortie du modèle est mis à jour et la partie saisie par l'utilisateur n'est pas calculée. L’ensemble du processus de formation prend environ 7 heures sur des GPU 8 × A100 (40G).
- Il convient de souligner que la version actuelle de PandaGPT utilise uniquement des données image-texte alignées pour la formation, mais hérite des six capacités de compréhension modale de l'encodeur ImageBind (image/vidéo, texte, audio, profondeur, carte thermique et IMU) et les propriétés d'alignement entre eux, offrant ainsi des capacités intermodales entre tous les modes.
- Dans l'expérience, l'auteur a démontré la capacité de PandaGPT à comprendre différentes modalités, notamment les questions et réponses basées sur des images/vidéos, l'écriture créative basée sur des images/vidéos, le raisonnement basé sur des informations visuelles et auditives, etc. Voici quelques exemples. :
Audio:

Vidéo:

Par rapport à d'autres modèles de langage multimodal, la caractéristique la plus remarquable de PandaGPT est sa capacité à comprendre et à combiner naturellement des informations provenant de différentes modalités.
Vidéo + Audio :
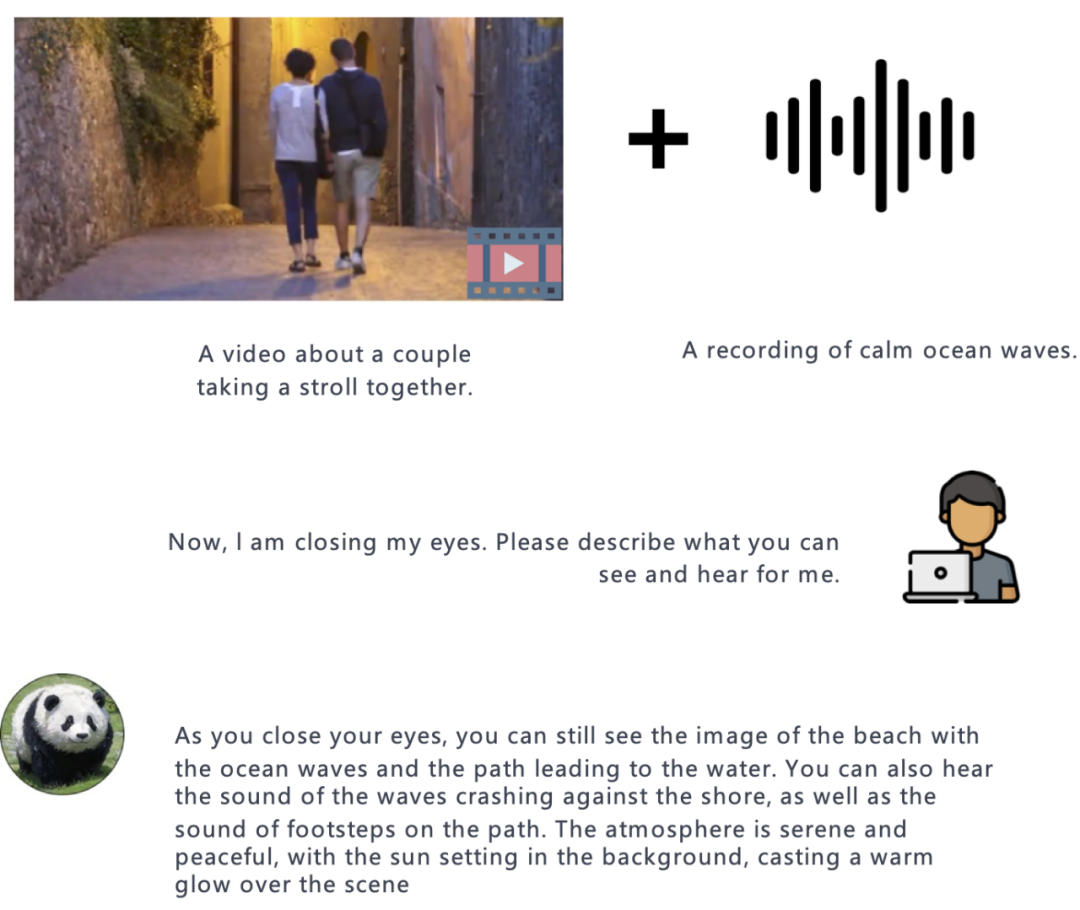
Image + Audio : Résumé
Les auteurs ont également résumé les nombreux problèmes de PandaGPT actuellement et les orientations de développement futures. Bien que PandaGPT ait une incroyable capacité à gérer plusieurs modalités et leurs combinaisons, il existe encore de nombreuses façons d'améliorer considérablement les performances de PandaGPT.
Les modes autres que le texte ne sont représentés que par un vecteur d'intégration, ce qui empêche le modèle de langage de comprendre les informations fines du modèle autres que le texte. Des recherches supplémentaires sur l’extraction de caractéristiques plus fines, telles que les mécanismes d’attention intermodaux, pourraient contribuer à améliorer les performances.
- PandaGPT autorise actuellement uniquement l'utilisation d'informations modales autres que le texte comme entrée. À l'avenir, ce modèle a le potentiel d'unifier l'ensemble de l'AIGC en un seul modèle, c'est-à-dire qu'un modèle peut effectuer simultanément des tâches telles que la génération d'images et de vidéos, la synthèse vocale et la génération de texte.
- De nouveaux critères de référence sont nécessaires pour évaluer la capacité à combiner les intrants multimodaux.
- PandaGPT peut également présenter certains défauts courants des modèles de langage existants, notamment les hallucinations, la toxicité et les stéréotypes.
- Enfin, les auteurs soulignent que PandaGPT n'est qu'un prototype de recherche et n'est pas encore prêt pour une application directe dans un environnement de production.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI