
Maison >Périphériques technologiques >IA >Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba
Le secret d'une recommandation précise : explication détaillée du modèle de rappel impartial d'adaptation de domaine découplé d'Alibaba

- 王林avant
- 2023-06-05 08:55:021219parcourir

1. Introduction à la scène
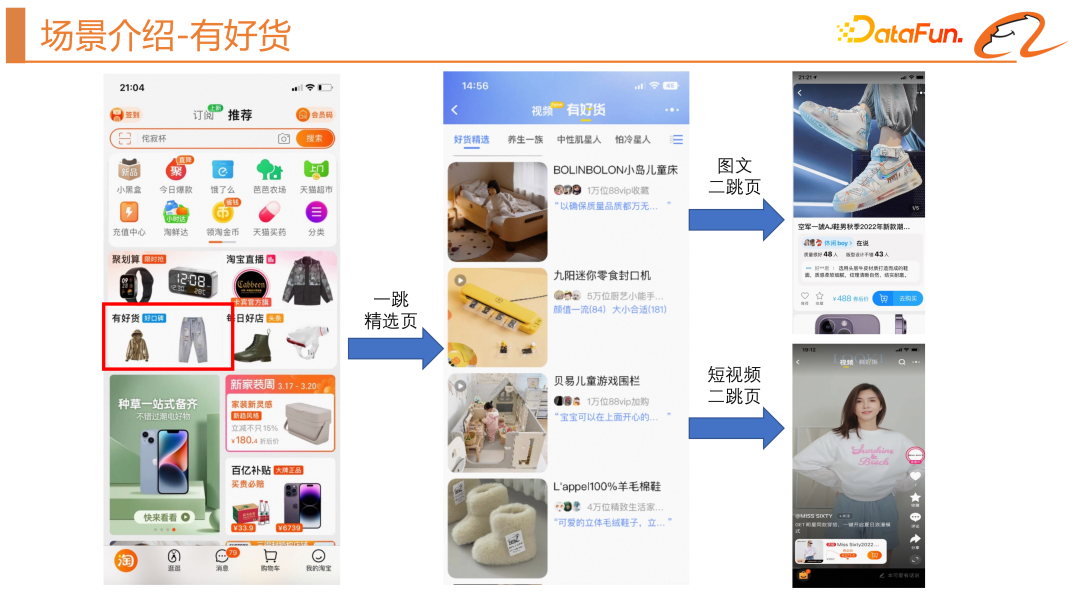
Tout d'abord, présentons le scénario impliqué dans cet article - le scénario « de bons produits sont disponibles ». Son emplacement se trouve dans la grille à quatre carrés de la page d'accueil de Taobao, qui est divisée en une page de sélection à un saut et une page d'acceptation à deux sauts. Il existe deux formes principales de pages d'hébergement, l'une est une page d'hébergement de graphiques et de textes, et l'autre est une courte page d'hébergement de vidéos. L’objectif de ce scénario est principalement de fournir aux utilisateurs des biens satisfaisants et de stimuler la croissance du GMV, exploitant ainsi davantage l’offre d’experts.
2. Qu'est-ce que le biais de popularité et pourquoi
Continuer Allons Venons-en au sujet de cet article, le biais de popularité. Qu’est-ce que le biais de popularité ? Pourquoi un biais de popularité se produit-il ?
1. Quel est le biais de popularité #
L'écart de popularité a de nombreux alias , comme
Effet Matthew, salle cocon d'information, 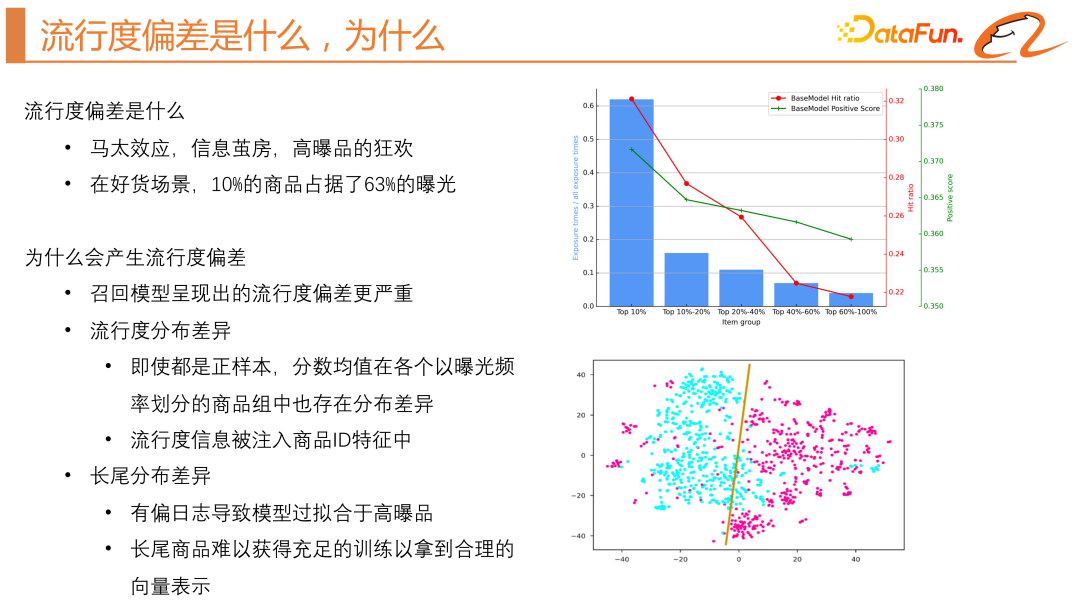 Intuitivement parlant, c'est un produit hautement explosif Carnaval, plus le produit est populaire, plus il est facile d'être exposé. Cela se traduira par des produits à longue traîne de haute qualité ou de nouveaux produits créés par des experts n'ayant pas la chance d'être exposés. Il y a deux inconvénients principaux. Le premier point est le manque de personnalisation des utilisateurs. Le deuxième point est que les nouveaux produits créés par les experts ne reçoivent pas suffisamment de visibilité, ce qui réduit le sentiment de participation des experts. le biais de popularité.
Intuitivement parlant, c'est un produit hautement explosif Carnaval, plus le produit est populaire, plus il est facile d'être exposé. Cela se traduira par des produits à longue traîne de haute qualité ou de nouveaux produits créés par des experts n'ayant pas la chance d'être exposés. Il y a deux inconvénients principaux. Le premier point est le manque de personnalisation des utilisateurs. Le deuxième point est que les nouveaux produits créés par les experts ne reçoivent pas suffisamment de visibilité, ce qui réduit le sentiment de participation des experts. le biais de popularité.
Comme le montre le graphique à barres bleues sur le côté droit de l'image ci-dessus, les 10 % de produits les plus exposés représentaient pour 63% du total sur un certain jour d'exposition, ce qui prouve que l'effet Matthew est très grave lorsqu'il y a de bons produits.
2. Pourquoi le biais de popularité se produit-il
Suivant ? Nous attribuons la raison pour laquelle le biais de popularité se produit. Tout d’abord, nous devons clarifier pourquoi nous effectuons le travail d’atténuation des biais de popularité dans la troncature des rappels. Le modèle de classement correspond au CTR du produit et ses échantillons de formation incluent des échantillons positifs et des échantillons négatifs. Les produits avec un CTR plus élevé sont plus susceptibles d'être exposés. Mais au stade du rappel, nous utilisons généralement le modèle à deux tours. Ses échantillons négatifs sont généralement générés de deux manières. La première est un échantillonnage négatif aléatoire global et la seconde est un échantillonnage négatif intra-lot. Idem Un lot prend d'autres journaux d'exposition d'échantillons positifs comme échantillons négatifs, il peut donc atténuer l'effet Matthew dans une certaine mesure. Cependant, grâce à des expériences, nous avons constaté que l'effet réel sur l'efficacité en ligne de l'échantillonnage négatif global serait meilleur. Cependant, l’échantillonnage négatif aléatoire global dans les systèmes de recommandation peut conduire à un biais de popularité car il ne fournit qu’un retour positif au modèle. Ce biais peut être attribué aux différences de répartition de la popularité et à l’interférence des connaissances antérieures, c’est-à-dire que les utilisateurs ont tendance à cliquer sur des éléments plus populaires. Par conséquent, le modèle peut recommander préférentiellement des articles populaires, quelle que soit leur pertinence. Nous avons également analysé les différences dans la répartition de la popularité, comme le montre la ligne verte à droite de la figure ci-dessus. En regroupant les éléments en fonction de la fréquence d'exposition et en calculant le score moyen des échantillons positifs pour chaque groupe, nous avons constaté que même si tous les échantillons sont des échantillons positifs, le score moyen diminue avec la diminution de la fréquence d'exposition. Il existe des différences dans la distribution de popularité et la distribution à longue traîne lors de la formation des modèles de système de recommandation. Le modèle aura tendance à injecter des informations de popularité dans les caractéristiques d’identification des éléments, ce qui entraînera des différences dans la répartition de la popularité. Le nombre de temps de formation obtenus par les produits hautement explosifs est beaucoup plus grand que celui des produits à longue traîne, ce qui rend le modèle sur-ajusté pour les produits hautement explosifs, et il est difficile pour les produits à longue traîne d'obtenir une formation suffisante et un vecteur raisonnable. représentation. Comme le montre le graphique TSN sur le côté droit de la figure ci-dessus, les points bleus représentent les vecteurs de produits des produits à forte exposition, tandis que les points rouges représentent les vecteurs de produits des produits à longue traîne, montrant une différence significative dans la distribution. Et comme le montre la ligne rouge sur le côté droit de la figure ci-dessus, le taux de réussite diminuera également à mesure que le nombre d'expositions diminuera. Par conséquent, nous attribuons le biais de popularité à la différence de distribution de popularité et à la différence de distribution à longue traîne.3. Solutions actuelles au biais de popularité
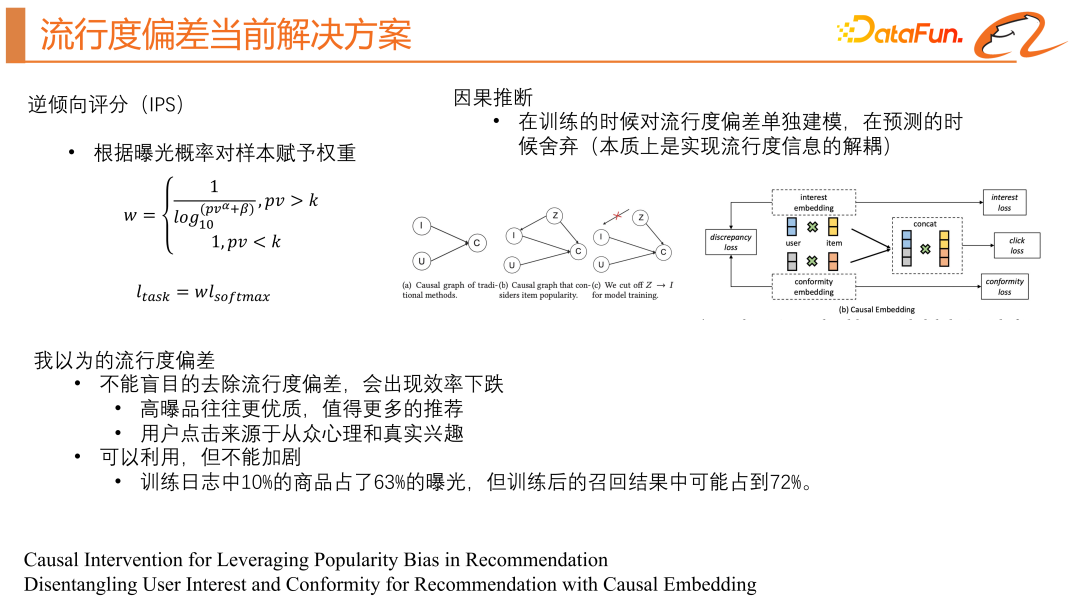
Les solutions actuelles de l'industrie comprennent principalement deux types, à savoir le score de propension inverse (IPS) et l'inférence causale.
1. Score de propension inverse (IPS)
En termes simples, cela signifie réduire le poids des produits à forte probabilité d'exposition dans la fonction de perte de tâche principale pour éviter une concentration excessive sur les produits à forte probabilité d'exposition, donc que l'ensemble du produit peut faire l'objet d'une attention plus égale à la distribution positive des échantillons. Cependant, cette méthode nécessite de prédire à l’avance la probabilité d’exposition, qui est instable et sujette à des défaillances ou à de grandes fluctuations.
2. Inférence causale
Nous devons construire un diagramme causal, où i représente les caractéristiques du produit, u représente les caractéristiques de l'utilisateur et c représente la probabilité de clic. Ce diagramme représente la saisie des caractéristiques de l'utilisateur et des caractéristiques du produit dans le. modèle , prédisez le taux de clics. Si nous prenons également en compte le biais de popularité dans ce modèle, représenté par z, cela affectera non seulement le taux de clics, mais également la représentation des caractéristiques du produit i. La méthode d'inférence causale consiste à essayer de bloquer l'impact de. z sur je.
La méthode la plus simple consiste à utiliser certaines caractéristiques statistiques du produit pour obtenir une tour de biais distincte. À ce stade, le modèle produira deux scores, l'un est le taux de clics réel et l'autre est le taux de clics réel. score de popularité du produit, en ligne Lors de la prévision, le score de popularité du produit sera supprimé pour obtenir un découplage de l'écart de popularité.
La deuxième méthode consiste à attribuer les clics des utilisateurs en deux catégories, l'une est l'intérêt collectif et l'autre l'intérêt réel, et à construire respectivement une formation conjointe des échantillons. Cela équivaut à obtenir deux modèles, un modèle pour obtenir le score d'intérêt du troupeau de l'utilisateur et un modèle pour obtenir le véritable score d'intérêt de l'utilisateur. L'inférence causale pose en fait des problèmes. Elle résout la différence de répartition de la popularité, mais elle ne peut pas résoudre le problème du manque de données de formation pour les produits à longue traîne. Les solutions actuelles tendent à éliminer les biais de popularité, mais cela n'est pas toujours bénéfique pour les systèmes de recommandation qui ont besoin de « l'effet Matthew » pour survivre. Par conséquent, nous recommandons de ne pas supprimer complètement le biais de popularité dans le système de recommandation, car les articles populaires sont généralement de meilleure qualité et les utilisateurs ont également à la fois une mentalité de troupeau et un réel intérêt. La suppression complète du biais de popularité affectera la satisfaction des utilisateurs. intérêts du troupeau. Le biais de popularité doit être utilisé de manière rationnelle sans l’exacerber.
4. Cadre de base du CD2AN
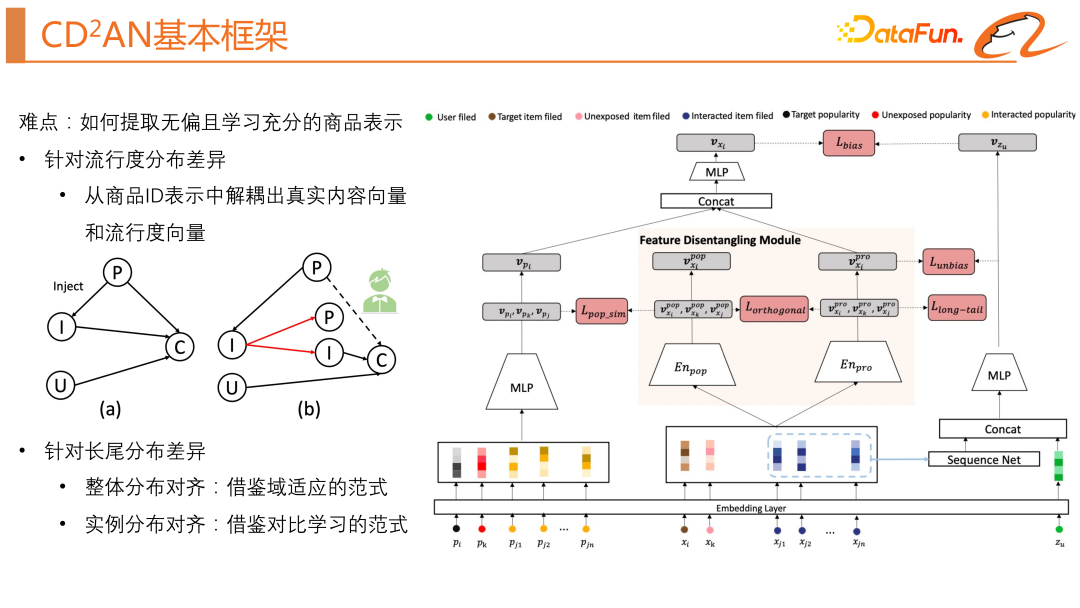
Le travail que nous explorons cette fois est de savoir comment utiliser rationnellement le biais de popularité. Pour utiliser raisonnablement le biais de popularité, nous devons résoudre une difficulté : " Comment extraire une représentation impartiale et entièrement apprise du produit ? " Pour remédier aux différences de répartition de la popularité, nous devons dissocier le vecteur de contenu réel et le vecteur de popularité de l'ID du produit. Pour résoudre les différences de distribution à longue traîne, nous nous appuyons sur le paradigme de l'adaptation de domaine pour aligner la distribution globale, et sur le paradigme de l'apprentissage contrastif pour aligner les distributions d'instances.
Présentons d'abord la structure de base du modèle de base. Le modèle de base est en fait un modèle classique à deux tours. Ensuite, nous présenterons en détail comment nous résolvons les deux problèmes mentionnés précédemment (différence de distribution de popularité et différence de distribution à longue traîne).
1. Le module de découplage des fonctionnalités atténue les différences dans la distribution de la popularité
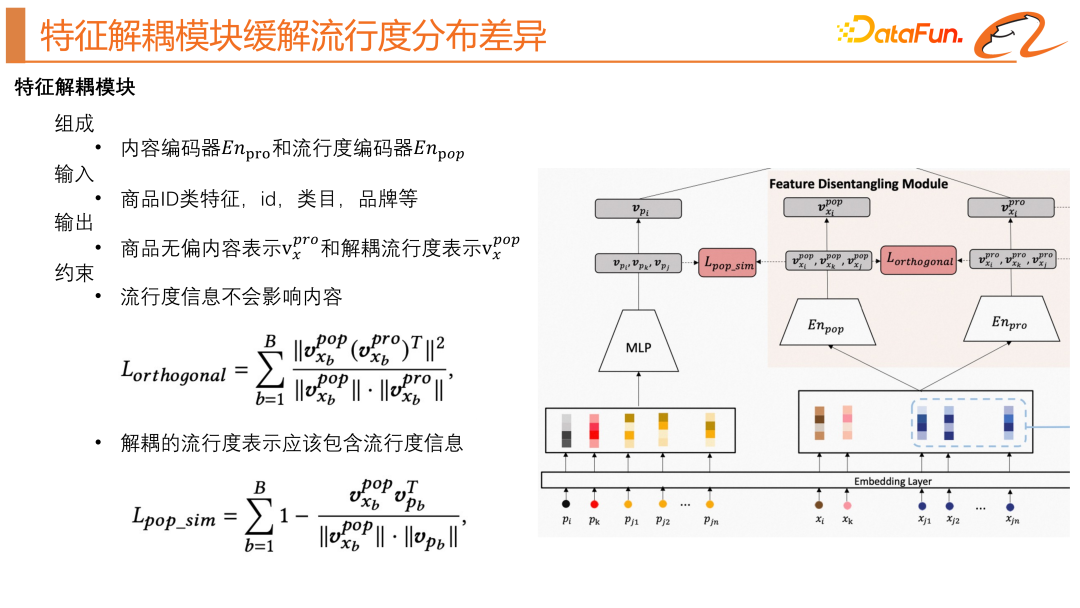
Le module de découplage des fonctionnalités est une solution proposée dans cet article pour résoudre le problème du biais de popularité dans les systèmes de recommandation. Ce module réduit l'impact de la popularité sur la représentation vectorielle d'élément en séparant les informations de popularité des informations d'attribut dans la représentation vectorielle d'élément. Plus précisément, ce module comprend un encodeur de popularité et un encodeur d'attribut, et apprend la représentation vectorielle d'attribut et de popularité de chaque élément grâce à une combinaison de perceptrons multicouches. L'entrée de ce module correspond aux caractéristiques d'attribut de l'article, telles que l'ID de l'article, la catégorie de l'article, la marque, etc., comme indiqué dans la partie droite de la structure du modèle ci-dessus. Il y aura ici deux contraintes, notamment la régularisation orthogonale et la régularisation de similarité de popularité, visant à séparer les informations de popularité des informations d'attribut d'élément. Parmi eux, grâce à la régularisation de similarité de popularité, le module est encouragé à aligner les informations de popularité intégrées dans les attributs de l'article avec les informations de popularité réelles, tandis que grâce à la régularisation orthogonale, le module est encouragé à conserver différentes informations dans l'encodage, obtenant ainsi des informations de degré de popularité séparées. et des informations d'attribut d'article.
Nous avons également besoin d'un module pour connaître la popularité réelle, comme le montre la partie gauche de la structure du modèle ci-dessus. Son entrée est principalement les caractéristiques statistiques du produit, puis il passe par un MLP pour obtenir le. véritable représentation de la popularité.
2. La régularisation atténue les différences de distribution
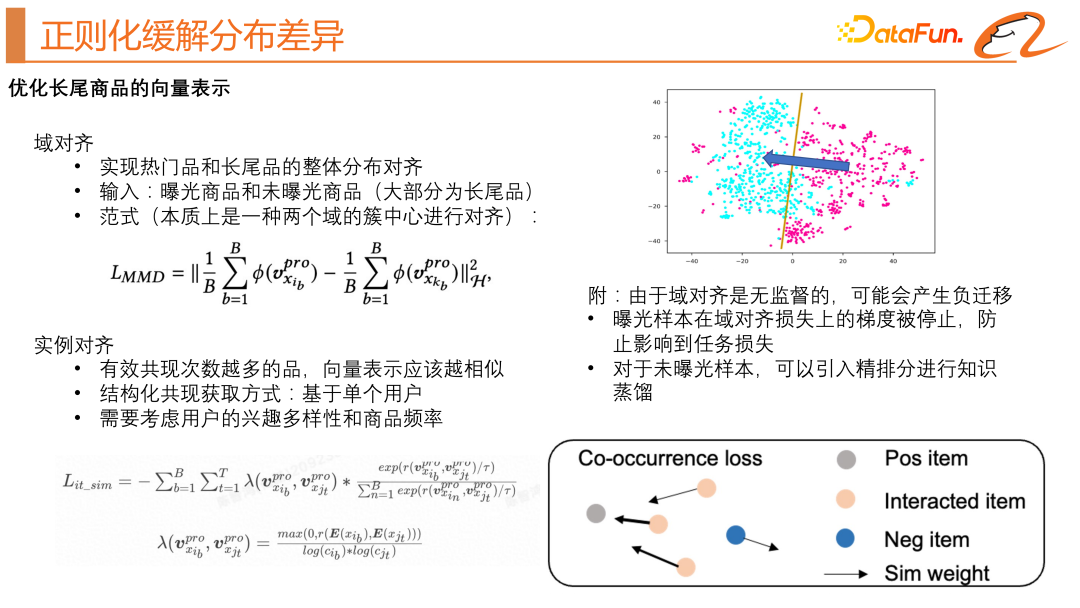
Ensuite, nous voulons résoudre le problème des différences de distribution à longue traîne.
Nous nous appuyons sur l'idée de l'apprentissage par transfert pour parvenir à l'alignement de la distribution des produits populaires et des produits à longue traîne. Dans le modèle original à deux tours, nous avons introduit un produit non exposé et utilisé la fonction de perte MMD (comme indiqué dans le coin supérieur gauche de la figure ci-dessus). Cette fonction de perte espère que le cluster est centré sur le domaine de produit populaire et la longue traîne. Les domaines de produits sont aussi proches que possible, comme indiqué ci-dessus. Comme le montre le diagramme schématique en haut à droite de la figure. Étant donné que ce type d'alignement de domaine n'est pas supervisé et peut produire un transfert négatif, nous avons effectué les optimisations suivantes : le gradient des échantillons exposés sur la perte d'alignement de domaine est arrêté pour éviter qu'il n'affecte la perte de tâche pour les échantillons non exposés, un classement fin est effectué ; introduction de la distillation des connaissances. Nous nous appuyons également sur l'idée d'alignement d'instances, dans l'espoir d'apprendre de meilleures représentations vectorielles de produits. L'idée principale est que plus les cooccurrences de produits sont efficaces, plus les représentations vectorielles seront similaires. La difficulté ici est de savoir comment construire la paire. Une telle paire existe naturellement dans la séquence de produits où l'utilisateur a un comportement passé. En prenant un utilisateur comme exemple, un échantillon contient la séquence de comportement d'un utilisateur et les produits cibles. Ensuite, le produit cible et chaque produit de la séquence de comportement de l'utilisateur peuvent former une paire co-occurrente. Sur la base de la fonction de perte d'apprentissage contrastive classique, nous prenons également en compte la diversité des intérêts de l'utilisateur et la fréquence des produits. La formule spécifique de la fonction de perte est visible dans la partie inférieure gauche de la figure ci-dessus.
Nous pouvons regarder un diagramme schématique intuitif, comme le montre le coin inférieur droit de la figure ci-dessus. Les points gris sont les produits cibles, les points orange sont la séquence de comportement de l'utilisateur et les points bleus sont les échantillons négatifs obtenus par notre. échantillonnage négatif aléatoire. Nous espérons apprendre de la méthode d'apprentissage contrastif pour contraindre chaque produit de la séquence de comportement de l'utilisateur à être proche du produit cible.
3. Formation conjointe biaisée et impartiale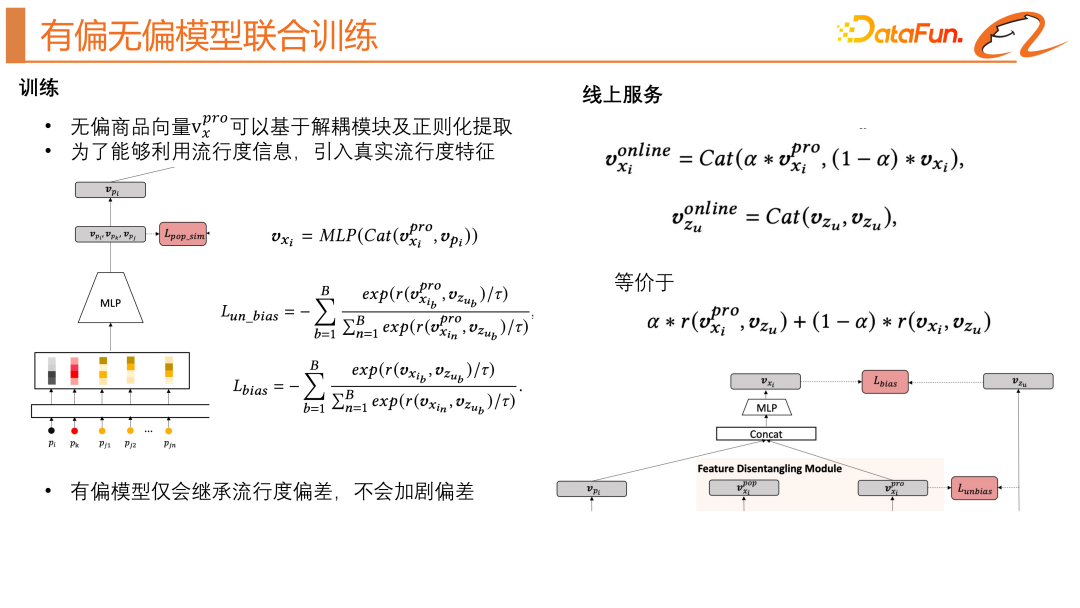
Le module ci-dessus obtient efficacement la représentation impartiale du contenu et la représentation découplée de la popularité du produit. Comment devrions-nous l'appliquer ? Nous utilisons la méthode de formation conjointe du modèle non biaisé et du modèle biaisé.Le vecteur de produit non biaisé peut être extrait sur la base du module de découplage et de la régularisation. Afin de pouvoir utiliser les informations de popularité, nous introduisons également la fonctionnalité de popularité, et le modèle biaisé le fera. hériter seulement Le biais de popularité n'exacerbe pas les préjugés. Pour la partie service en ligne, comme indiqué sur le côté droit de la figure ci-dessus, nous fusionnons la représentation impartiale du produit et la représentation biaisée du produit via le paramètre α pour obtenir la représentation du produit en ligne, afin que le produit puisse être rappelé via le vecteur utilisateur. α est l'ajustement Rappeler dans quelle mesure l'attention est accordée aux informations sur la popularité. #🎜🎜 #
4, hors ligne et expérience en ligne
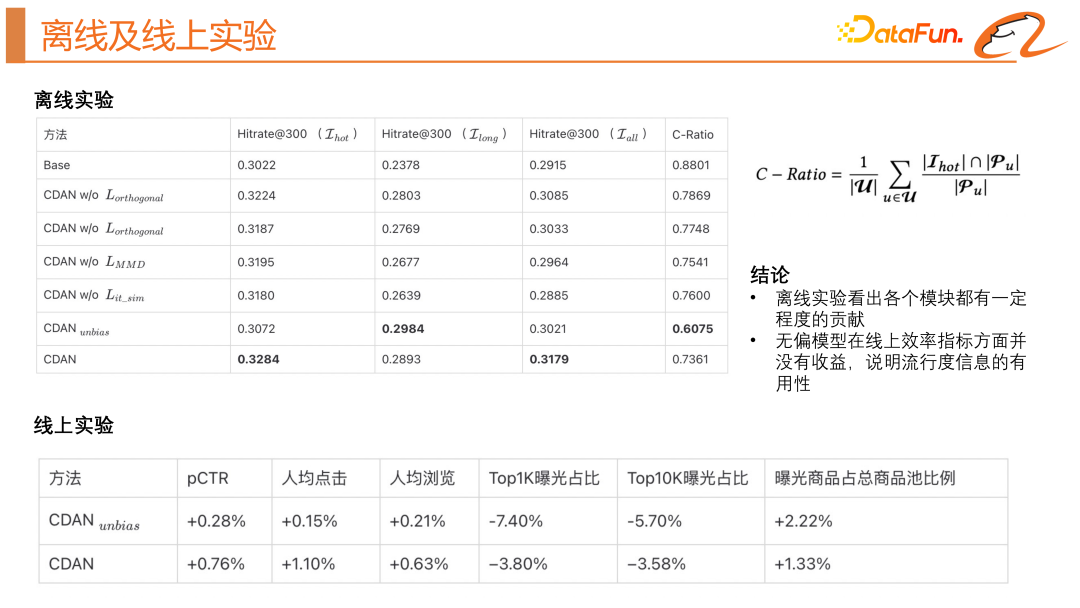
L'image ci-dessus montre les effets hors ligne et en ligne de ce modèle. Dans les expériences hors ligne, nous avons introduit l'indicateur C-Ratio pour mesurer combien d'éléments dans les résultats du rappel sont des éléments hautement exposés. Grâce à des expériences hors ligne, nous pouvons constater que chaque module contribue dans une certaine mesure. Le modèle impartial n’apporte aucun gain en termes d’indicateurs d’efficacité en ligne, ce qui indique que les informations sur la popularité sont utiles, et nous devons toujours utiliser un modèle biaisé pour utiliser les informations sur la popularité.
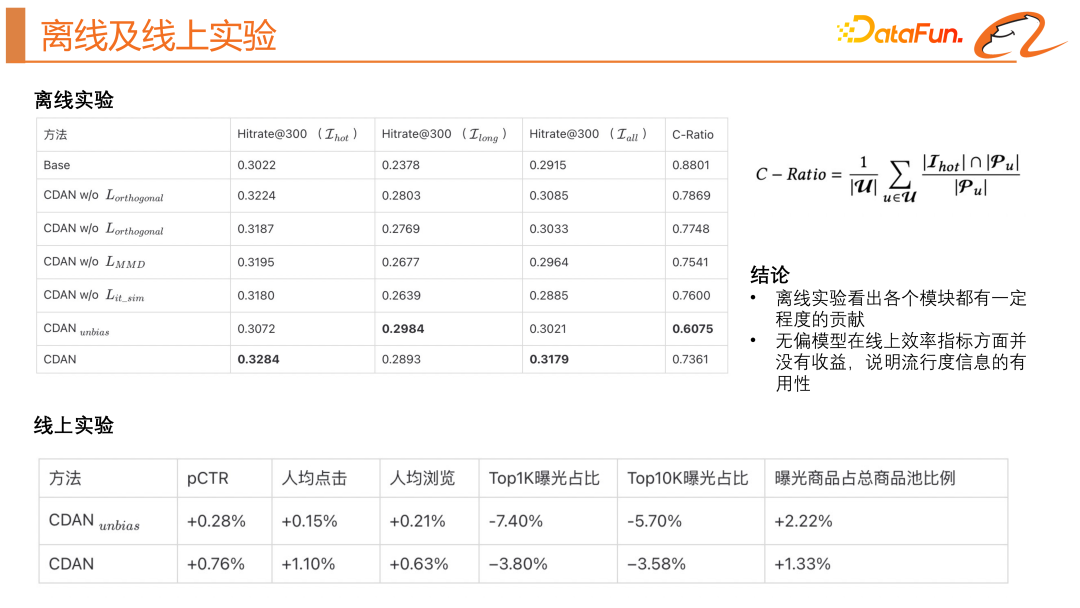
Enfin, nous avons réalisé un affichage visuel des résultats du modèle. Nous avons constaté que la nouvelle structure du modèle peut effectivement aligner la distribution des produits hautement explosifs et des produits à longue traîne. Le vecteur de représentation de popularité découplé et la représentation impartiale du contenu du produit n'ont presque aucune intersection, et les produits ayant le même objectif peuvent être plus proches. relations. En ajustant α, le modèle peut s'adapter de manière directionnelle aux intérêts suivants et aux intérêts réels de l'utilisateur.
Le titre de l'article partagé d'aujourd'hui est "Co-formation d'un réseau d'adaptation de domaine démêlé pour tirer parti des biais de popularité chez les recommandateurs".
5. Séance de questions-réponses
Q1 : Comment les échantillons non exposés sont-ils ajoutés à l'échantillon ? dans?
A1 : généré hors ligne, nous pouvons obtenir l'échantillon positif cible et la catégorie correspondante, puis échantillonner aléatoirement un certain nombre d'échantillons hors ligne. . Un produit de la même catégorie que l'échantillon positif cible est monté dans l'échantillon d'apprentissage.
Q2 : L'introduction d'échantillons similaires non exposés augmentera-t-elle la difficulté d'apprentissage ?
A2 : Les échantillons non exposés introduits n'ont pas d'étiquettes et sont distribués de manière non supervisée. Il peut y avoir un transfert négatif. Nous avons utilisé deux techniques pour résoudre ce problème : le gradient des échantillons exposés. sur la perte d'alignement de domaine est arrêtée pour éviter d'affecter la perte de tâches ; pour les échantillons non exposés, un classement fin peut être introduit pour la distillation des connaissances.Q3 : Est-ce que cela coûtera très cher d'obtenir des scores de classification fins pour des échantillons non exposés ?
A3 : Utilisez le modèle de classement fin pour noter l'échantillon hors ligne et utilisez-le comme fonctionnalité.
Q4 : Les échantillons non exposés sont-ils les échantillons non exposés de la collection fine ?
A4 : Non, il y a une forte probabilité qu'il s'agisse encore d'un produit hautement explosif. Nous utilisons les résultats d'un échantillonnage aléatoire dans le cadre global. même catégorie.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI