
Maison >Périphériques technologiques >IA >Les États-Unis ont dépensé 2,6 milliards de dollars américains en intelligence artificielle... Ils devraient achever la construction du NAIRR d'ici 6 ans
Les États-Unis ont dépensé 2,6 milliards de dollars américains en intelligence artificielle... Ils devraient achever la construction du NAIRR d'ici 6 ans

- 王林avant
- 2023-06-03 17:36:071326parcourir
L'intelligence artificielle est une technologie stratégique à la tête d'un nouveau cycle de révolution technologique et de changement industriel. De nombreux résultats de recherche et données montrent que les États-Unis sont à la pointe du monde en matière de recherche scientifique fondamentale, d'innovation technologique et d'applications industrielles de l'intelligence artificielle. Des indicateurs tels que les articles de haut niveau sur l'intelligence artificielle, le nombre d'éminents universitaires, le nombre d'entreprises d'intelligence artificielle et. l'ampleur des investissements est en avance sur celle des autres pays.
Le gouvernement américain attache une grande importance à l'innovation et au développement de la technologie de l'intelligence artificielle. Conformément à la National AI Initiative Act de 2020, le Congrès exige que la National Science Foundation (NSF) et le Bureau de la politique scientifique et technologique (OSTP) de la Maison Blanche forment un groupe de travail pour étudier et formuler la politique des États-Unis en janvier 2023. La feuille de route pour la construction d'infrastructures du NAIRR (Artificial Intelligence Research Resource) consolide l'avantage concurrentiel des États-Unis dans le domaine de l'intelligence artificielle, élargit les possibilités pour toutes les parties aux États-Unis d'obtenir des ressources clés en matière d'intelligence artificielle et d'éducation, et stimule davantage l'innovation et l'innovation en matière d'intelligence artificielle aux États-Unis. prospérité économique.
Le contexte et l'importance de la construction du NAIRR aux États-Unis
Contexte de la construction
Le gouvernement américain estime que son avance dans le domaine de l’intelligence artificielle est remise en question et que son avantage concurrentiel risque d’être affaibli. Il y a deux problèmes principaux : Premièrement, les investissements dans la R&D en intelligence artificielle et les ressources pédagogiques sont inégalement répartis. Les données de recherche montrent que du point de vue des investissements, le montant des investissements du secteur privé dans l'intelligence artificielle aux États-Unis a plus que doublé entre 2020 et 2021, mais que le nombre de nouvelles entreprises d'intelligence artificielle est en baisse du point de vue des talents et de la démographie ; race des diplômés américains du doctorat en intelligence artificielle La répartition, la répartition par sexe et la proportion réelle de la population sont assez différentes, ce qui limitera l'innovation et le développement de l'intelligence artificielle. Deuxièmement, les institutions de recherche scientifique disposent de ressources informatiques et de données insuffisantes. Du point de vue de la puissance de calcul, les plates-formes de puissance de calcul les plus avancées appartiennent à des institutions privées de premier plan, et les instituts de recherche scientifique manquent de plates-formes de puissance de calcul pour soutenir la recherche et le développement de l'intelligence artificielle du point de vue des ressources de données, les principales ressources de données pour ; La formation sur les modèles d'intelligence artificielle appartient à des institutions privées et à des plateformes Internet à grande échelle. Bien que le gouvernement américain continue d'ouvrir les données, elles sont encore insuffisantes pour la recherche sur l'intelligence artificielle.
Le groupe de travail a souligné que le manque de ressources suffisantes pour la recherche en intelligence artificielle limitera l'écosystème américain d'innovation en intelligence artificielle, conduisant à la concentration des meilleurs talents des instituts de recherche universitaires vers un petit nombre d'entreprises riches en ressources. à long terme, cela affectera la compétitivité et l’innovation des États-Unis. En janvier 2023, après 18 mois de sollicitation publique d'avis et de discussions, le groupe de travail a officiellement proposé un plan de construction et prévu de solliciter 2,6 milliards de dollars américains en fonds de construction, d'exploitation et de maintenance. Il prévoit d'achever les travaux de construction du NAIRR en quatre phases. d'ici 6 ans, en se concentrant sur la réalisation de quatre objectifs majeurs : rassembler des ressources pour promouvoir l'innovation en recherche, améliorer la diversité des talents, améliorer les capacités des ressources de base et promouvoir le développement d'une intelligence artificielle fiable.
Importance
NAIRR, en tant qu'infrastructure de recherche sur l'intelligence artificielle, est ouverte aux écoles de recherche américaines, aux étudiants et aux organisations à but non lucratif. Elle fournit des ressources de recherche fondamentales telles que des ressources informatiques, des données de haute qualité et des outils pédagogiques. la clé de la coopération américaine en matière de recherche en intelligence artificielle pour consolider son avantage compétitif international.
En termes de construction écologique, le gouvernement américain s'appuiera sur le NAIRR pour unir les départements gouvernementaux internes concernés et les instituts de recherche scientifique afin de mener conjointement des recherches coopératives et la construction de ressources dans le domaine de l'intelligence artificielle afin de former un vaste écosystème coopératif. Les services et fonctions du NAIRR sont illustrés à la figure 1.
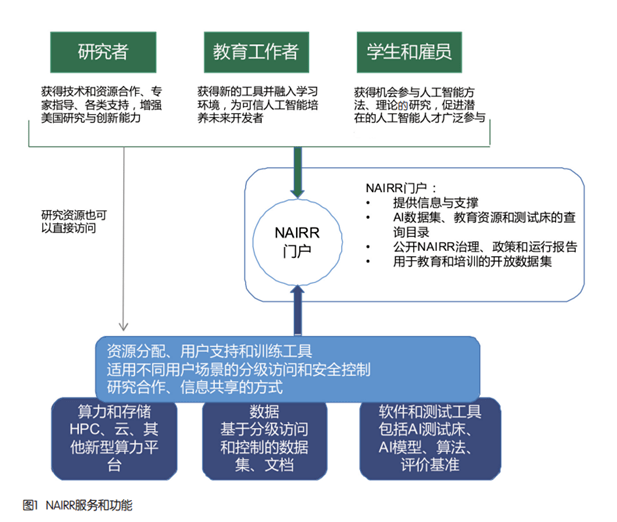
En termes de données, le NAIRR regroupera les données des ministères fédéraux et mènera une coopération en matière de services de données avec diverses institutions du secteur. Le premier consiste à promouvoir l’agrégation, le développement et l’utilisation de ressources de données d’intelligence artificielle à grande échelle. Il rassemblera et connectera les ressources de données à grande échelle qui ont été open source par les agences fédérales américaines, les instituts de recherche universitaires et les géants de la technologie pour devenir la référence. la plus grande plateforme de services de ressources de données d'intelligence artificielle aux États-Unis. Par exemple, les National Institutes of Health des États-Unis ont publié plus de 36 Po de données de séquençage génétique, et la National Oceanic and Atmospheric Administration a publié plus de 10 Po de données météorologiques et environnementales. Le deuxième est de promouvoir l’amélioration des capacités de gestion des données et de gouvernance de l’intelligence artificielle. Les ensembles de données d'intelligence artificielle sont très fragmentés. Chaque ensemble de données prend en charge des tâches et des domaines de recherche spécialisés. Il existe un manque de normes unifiées pour l'annotation et la gouvernance des données, ce qui rend la gestion des données difficile. Le NAIRR favorisera l’établissement de normes unifiées pour l’agrégation des données, normalisera les formats de description des données et promouvra l’agrégation de ressources de données multipartites. Le troisième est de promouvoir le développement et l’utilisation de ressources de données grâce à une collaboration multipartite. L'entité opérationnelle exploitera la communauté des ensembles de données d'intelligence artificielle et encouragera la communauté à développer et à créer activement des ressources de données précieuses que le NAIRR pourra utiliser. Les entités opérationnelles fourniront également des services de recherche de données pour faciliter l’interrogation des données ouvertes des agences fédérales et des ressources de données provenant de fournisseurs de services tiers.
En termes de puissance de calcul, NAIRR unira ses forces avec les principales sociétés américaines de plates-formes cloud de calcul d'intelligence artificielle pour construire une plate-forme de puissance de calcul et prévoit de se connecter aux plates-formes cloud de géants de la technologie tels que Google, Microsoft et Amazon, ainsi que des agences fédérales telles que la US Natural Science Foundation et la plateforme cloud des National Institutes of Health des États-Unis. La plateforme propose différents niveaux de modèles de service et de contenu pour les universités, les instituts de recherche, les étudiants et les start-ups, y compris une variété de services et de ressources tels que des données, de la puissance de calcul, des bancs d'essai et des outils logiciels. Une fois terminés, les ressources informatiques du NAIRR comprendront des superordinateurs prenant en charge la formation de modèles d'apprentissage automatique à l'échelle d'au moins un billion de paramètres, ainsi que des ressources de cloud computing, des processeurs, des GPU et des réseaux à haut débit.
Une fois l'infrastructure NAIRR établie et exploitée de manière stable, d'une part, elle continuera à élargir la coopération avec les ministères gouvernementaux et les institutions privées, à élargir la portée des services et des utilisateurs de la plateforme et, d'autre part, à promouvoir les expériences réussies ; Promouvoir la formulation de normes et de spécifications pertinentes et participer aux échanges et à la coopération internationaux. Servir de plate-forme de base permettant aux États-Unis et à leurs alliés et partenaires de promouvoir la recherche coopérative et le partage de données.
Plan de construction américain NAIRR
Les États-Unis prévoient de mobiliser le gouvernement fédéral et les institutions privées pour collaborer grâce à une approche systématique visant à établir une infrastructure de ressources de recherche en intelligence artificielle pour la recherche universitaire.
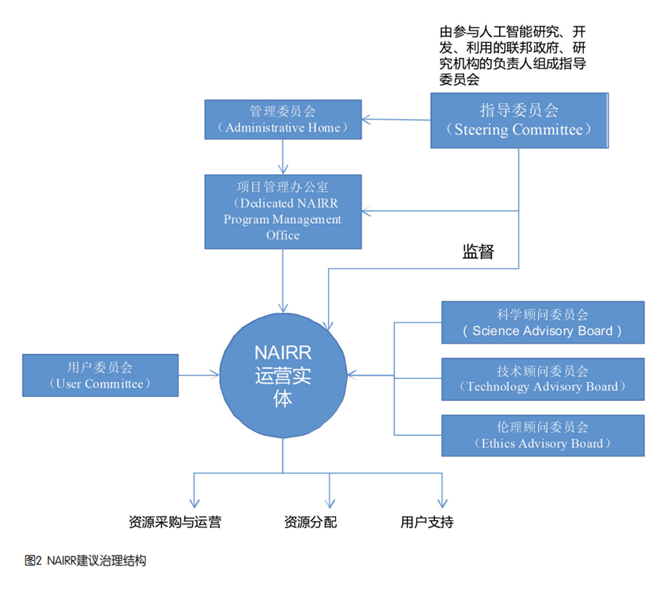
Tout d’abord, planifiez et construisez un système de gouvernance de plateforme avec une participation multipartite. La structure de gouvernance proposée par le NAIRR est présentée à la figure 2. Le plan recommande d'établir un système de gouvernance avec une participation multipartite des ministères gouvernementaux et d'établir une série d'institutions responsables telles qu'un comité de pilotage, un comité de gestion, un bureau de gestion de projet, une entité opérationnelle et un comité consultatif pour coordonner la coopération. Établir un comité directeur, composé de représentants de divers ministères et organismes du gouvernement fédéral. Il s'agit de l'organe décisionnel le plus élevé au niveau national pour la planification globale et les objectifs stratégiques du NAIRR. Il représente divers ministères pour promouvoir l'investissement dans les ressources nationales dans le domaine du NAIRR. intelligence artificielle. Un comité de gestion est établi pour guider et gérer les entités opérationnelles de la plateforme, ainsi que pour fournir des fonds et des ressources connexes. Le plan propose que NSF assume les responsabilités du comité de gestion. Mettre en place un bureau de gestion de projet pour coopérer avec le comité de pilotage dans la gestion quotidienne et l'évaluation des entités opérationnelles. Le Congrès américain a approuvé le financement du Project Management Office pour soutenir la gestion de projet, le développement et le déploiement du portail, le soutien conjoint, la formation et le support aux utilisateurs. Créer une entité opérationnelle indépendante des ministères gouvernementaux et chargée de formuler des objectifs de développement spécifiques pour le NAIRR, d'organiser la construction de la plateforme et la gestion quotidienne des opérations, et de formuler un système d'allocation des ressources transparent, équitable et raisonnable pour répondre aux besoins de diverses institutions de recherche en intelligence artificielle. et les utilisateurs. Un comité scientifique, un comité technique, un comité d'éthique et un comité d'utilisateurs composés d'experts dans de multiples domaines ont été créés pour fournir une aide à la décision pour la construction du NAIRR.
La seconde consiste à fournir des fonds dédiés à l’exploitation et à la construction des infrastructures du NAIRR. Le plan de construction propose de demander un financement de 2,6 milliards de dollars sur six ans, dont 2,25 milliards de dollars seront utilisés pour acheter de la puissance de calcul de la plate-forme, des outils logiciels et des ressources de données auprès des fournisseurs de services. Les dépenses quotidiennes de l'organisation exploitante s'élèveront à 370 dollars. millions de dollars, et 30 millions de dollars supplémentaires seront utilisés pour l'évaluation de la situation des infrastructures. Toutes les agences fédérales impliquées dans la recherche et le développement de l’intelligence artificielle devraient participer à la gestion du projet du NAIRR. Les investissements en R&D des ministères fédéraux dans le domaine de l’intelligence artificielle peuvent toujours être achetés et développés par chaque agence seule ou en coopération, mais ils doivent être gérés et fournis par l’intermédiaire de l’infrastructure du NAIRR.
Troisièmement, l'infrastructure NAIRR est construite par phases, augmentant les ressources informatiques selon les besoins et favorisant l'agrégation des ressources de données. La construction de la plate-forme est divisée en quatre étapes : lancement du projet, construction, opération d'essai et exploitation continue. La phase d'exploitation expérimentale pourra prendre en charge 50 000 utilisateurs et pourra regrouper et utiliser les données existantes des agences fédérales et des agences privées. Après un fonctionnement stable, il prendra en charge 150 000 utilisateurs et établira une communauté de coopération plus large en matière de ressources de données. Le NAIRR développera des ressources de données pour faciliter l'utilisation des données en formulant des normes d'agrégation de données, en développant des coopératives de données et en fournissant des services de recherche de données.
Dans la nouvelle situation, l'importance de constituer des ressources de base pour la recherche en intelligence artificielle est devenue de plus en plus importante
Actuellement, de nouvelles technologies et applications de l'intelligence artificielle émergent constamment. La recherche et la formation d'une nouvelle génération de grands modèles d'intelligence artificielle représentés par le grand modèle de langage ChatGPT nécessitent le support de ressources informatiques et de données à plus grande échelle, et nécessitent un un investissement unique en R&D. Le seuil de puissance de calcul de la plate-forme pour la formation de grands modèles d'intelligence artificielle est extrêmement élevé, et les institutions ordinaires ne peuvent pas se permettre d'énormes dépenses de R&D et de fonctionnement. Les recherches d'OpenAI soulignent que la puissance de calcul requise pour la formation des modèles d'intelligence artificielle a augmenté de façon exponentielle. De 2012 à 2018, la puissance de calcul consommée pour la formation des modèles d'IA a été multipliée par 300 000. La puissance de calcul requise pour former GPT3 atteint 3 640 pfs par jour (soit une efficacité de 1 PetaFLOP/s pendant 3 640 jours), et le coût de formation devrait atteindre 1,4 million de dollars par fois. Certaines organisations estiment que le coût d'investissement initial de ChatGPT est d'environ 1,4 million de dollars. 800 millions de dollars.
En termes d'ensembles de données d'intelligence artificielle, avec la recherche et le développement de grands modèles pré-entraînés, la taille des ensembles de données nécessaires à la formation a encore considérablement augmenté. La taille des données est passée de millions ou de dizaines de millions dans le passé à. des centaines de millions. Les ensembles de données actuellement utilisés dans la formation de grands modèles proviennent principalement d'Internet, notamment de bases de données telles que Wikipédia, de sites de réseaux sociaux, de revues publiques, de livres, d'articles et de codes. Certaines études ont souligné que « les données d'entraînement deviendront l'une des plus grandes contraintes à l'industrialisation des grands modèles. D'un point de vue plus profond, les grands modèles ont encore divers problèmes de gouvernance en termes de données d'entraînement, tels que la collecte de données et l'étiquetage qui prennent du temps. -consommateur, laborieux et coûteux, et la qualité des données est difficile. Les garanties et la diversification des données sont insuffisantes pour couvrir les cas de « longue traîne » et les cas extrêmes, et il existe des problèmes tels que la protection de la vie privée et la partialité des données dans l'acquisition, l'utilisation et le partage de données spécifiques. données. « Les chercheurs étrangers estiment que l'échelle globale des données linguistiques augmente à un taux de 7 %. ; La croissance des données linguistiques de haute qualité est soumise à des facteurs tels que la taille de la population et le développement économique, avec une croissance de 4 %. à 5%. Les données de haute qualité pour la formation de grands modèles linguistiques seront « épuisées » d'ici 2027.
Résumé
La puissance de calcul et les ressources de données sont les éléments de base de la recherche sur les technologies d’intelligence artificielle. Alors que l’intelligence artificielle entre dans l’ère du « grand modèle », la puissance de calcul et les capacités de données sont devenues des facteurs limitants pour la recherche et la formation sur les modèles algorithmiques. L'infrastructure NAIRR en construction aux États-Unis est propice à la résolution des nouveaux défis rencontrés par l'innovation et le développement actuels de la technologie de l'intelligence artificielle, et revêt une certaine importance de référence pour la Chine. Mon pays devrait renforcer la planification et la coordination globales et accélérer la construction de. l'infrastructure informatique et les ressources de données de base, et développer le marché des éléments de données, encourager la collecte et la circulation des ressources de données et promouvoir la recherche technologique de base et l'innovation applicative de l'intelligence artificielle.
FIN
Auteur : Lu Yapeng, Wang Weiguo, Centre de recherche sur les données, Académie chinoise des technologies de l'information et des communications
Editeur/Formateur : Gai Beibei
Évalué par : Shu Wenqiong
Producteur : Liu Qicheng
Les likes et les vues sont tous ici
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI