
Maison >base de données >tutoriel mysql >Quelle est l'architecture logique à trois niveaux de MySQL ?
Quelle est l'architecture logique à trois niveaux de MySQL ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-03 12:46:121629parcourir
Architecture logique à trois niveaux MySQL
L'architecture du moteur de stockage de MySQL sépare le traitement des requêtes du stockage/récupération de données. Voici le schéma d'architecture logique de MySQL :
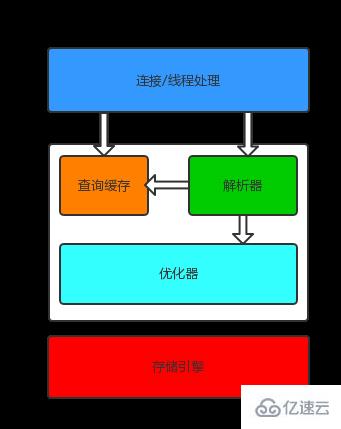
1 La première couche est responsable de la gestion des connexions, de l'authentification des autorisations, de la sécurité, etc.
Chaque connexion client correspond à un thread sur le serveur. Un pool de threads est maintenu sur le serveur pour éviter de créer et de détruire un thread pour chaque connexion. Lorsqu'un client se connecte à un serveur MySQL, le serveur l'authentifie. L'authentification peut être effectuée via un nom d'utilisateur et un mot de passe, ou via un certificat SSL. Une fois l'authentification de connexion réussie, le serveur vérifiera également si le client a le pouvoir d'exécuter une certaine requête.
2. La deuxième couche est chargée d'analyser la requête
compiler SQL et de l'optimiser (comme ajuster l'ordre de lecture de la table, sélectionner les index appropriés, etc.). Pour les instructions SELECT, avant d'analyser la requête, le serveur vérifiera d'abord le cache de requête si le résultat de la requête correspondant peut y être trouvé, le résultat de la requête sera renvoyé directement sans avoir besoin d'analyser la requête, d'optimiser, etc. Les procédures stockées, les déclencheurs, les vues, etc. sont tous implémentés dans cette couche.
3. La troisième couche est le moteur de stockage
Le moteur de stockage est responsable du stockage des données dans MySQL, de l'extraction des données, du démarrage d'une transaction, etc. Le moteur de stockage communique avec la couche supérieure via des API. Ces API masquent les différences entre les différents moteurs de stockage, rendant ces différences transparentes pour le processus de requête de la couche supérieure. Le moteur de stockage n'analysera pas SQL.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!