
Maison >base de données >Redis >Analyse d'un exemple d'optimisation Redis
Analyse d'un exemple d'optimisation Redis

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-06-01 08:38:05784parcourir
Dimension de la mémoire
Contrôlez la longueur de la clé
Les clés utilisent généralement des chaînes, et la structure de données sous-jacente des chaînes est SDS La structure SDS contiendra des informations de métadonnées telles que la longueur de la chaîne, la taille de l'espace alloué, etc. plus la longueur de la chaîne augmente, les métadonnées dans SDS occuperont également plus d'espace mémoire. Afin de réduire l'espace occupé par la clé, nous pouvons utiliser l'abréviation anglaise correspondante selon le nom de l'entreprise pour la représenter. Par exemple, l'utilisateur est représenté par u et le message est représenté par m.
Évitez de stocker bigkey
Nous devons faire attention à la fois à la longueur de la clé et à la taille de la valeur. Redis utilise un seul thread pour lire et écrire des données. Les opérations de lecture et d'écriture de bigkey bloqueront le thread et réduiront. l'efficacité du traitement de Redis.
Comment interroger bigkey
Nous pouvons utiliser la commande --bigkey pour afficher les informations bigkey occupées dans Redis. La commande spécifique est la suivante :
redis-cli -h 127.0.0.1 -p 6379 -a 'xxx' --bigkeys
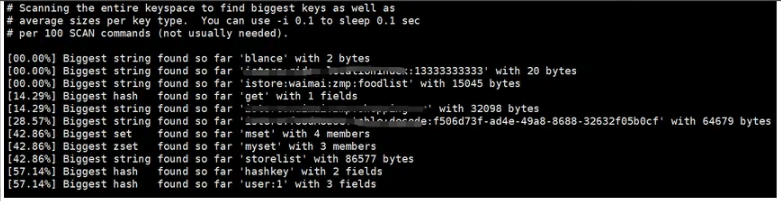
Comme le montre la figure ci-dessus, nous pouvons afficher. Redis La clé occupe 32098 octets et doit être optimisée.
Recommandation :
Si la clé est de type chaîne, il est recommandé que la taille de la valeur stockée dans la valeur soit d'environ 10 Ko.
Si la clé est de type List/Hash/Set/ZSet, il est recommandé que le nombre d'éléments stockés soit contrôlé en dessous de 10 000.
Choisissez le type de données approprié
Redis est optimisé pour le type de données stockées, et la mémoire est également optimisée en conséquence. Pour obtenir des informations pertinentes sur les résultats des données, vous pouvez vous référer aux articles précédents.
Par exemple : String et set utiliseront le codage entier lors du stockage des données int. Hash et ZSet utiliseront le stockage de liste compressée (ziplist) lorsque le nombre d'éléments est relativement petit, et seront convertis en tables de hachage et en tables de saut lorsqu'une quantité relativement importante de données est stockée.
Adoptez des méthodes de sérialisation et de compression efficaces
Les chaînes dans Redis sont stockées à l'aide de tableaux d'octets sécurisés en binaire, afin que nous puissions sérialiser l'entreprise en binaire et l'écrire sur Redis, mais utiliser une sérialisation différente. L'espace occupé varie. La sérialisation de Protostuff est plus efficace que la sérialisation intégrée de Java et prend moins de place. Afin de réduire l'utilisation de l'espace, nous pouvons compresser et stocker les formats de données JSON et XML. Les algorithmes de compression facultatifs incluent Gzip et Snappy.
Définissez la mémoire maximale et la stratégie d'élimination de Redis
Nous estimons la taille de la mémoire à l'avance en fonction de la quantité de données commerciales, afin d'éviter l'expansion continue de la mémoire Redis et l'occupation de trop de ressources.
Concernant la manière de définir la stratégie d'élimination, vous devez combiner les caractéristiques réelles de l'entreprise pour choisir :
volatile-lru / allkeys-lru : Prioriser la conservation des données récemment consultées
volatile- lfu / allkeys -lfu : Donner la priorité à la conservation des données les plus fréquemment consultées
volatile-ttl : Donner la priorité aux données expirantes qui sont sur le point d'expirer
-
volatile-random/allkeys-random : Éliminer aléatoirement les données
contrôler la taille de l'instance Redis
Il est recommandé que la taille de la mémoire d'une instance unique Redis soit définie entre 2 et 6 Go. Étant donné que les instantanés RDB et la synchronisation des données du cluster maître-esclave peuvent être effectués rapidement, le traitement des demandes normales ne sera pas bloqué.
Effacer régulièrement les fragments de mémoire
De nouvelles modifications fréquentes entraîneront une augmentation des fragments de mémoire, les fragments de mémoire doivent donc être effacés à temps.
Redis fournit la commande Info memory pour afficher les informations sur l'utilisation de la mémoire, comme suit :
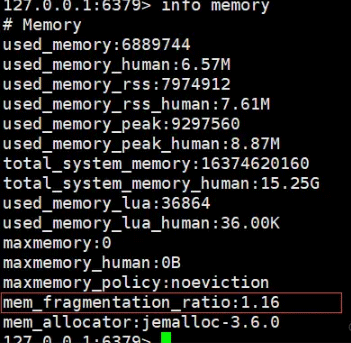
Explication :
used_memory_rss est l'espace mémoire physique réellement alloué à Redis par le système d'exploitation.
used_memory est l'espace réellement demandé par Redis pour sauvegarder les données.
mem_fragmentation_ratio=used_memory_rss/ used_memory
mem_fragmentation_ratio est supérieur à 1 mais inférieur à 1,5. Cette situation est raisonnable.
Si mem_fragmentation_ratio est supérieur à 1,5, cela signifie que le taux de fragmentation de la mémoire a atteint plus de 50%. Dans ce cas, il est généralement nécessaire de prendre certaines mesures pour réduire le taux de fragmentation de la mémoire. Les mesures spécifiques de nettoyage de la mémoire seront expliquées dans les articles suivants.
Dimension de performance
Il est interdit d'utiliser les commandes KEYS, FLUSHALL et FLUSHDB
KEYS correspond en fonction du contenu de la clé et renvoie des paires clé-valeur qui répondent aux conditions de correspondance. Cette commande nécessite une analyse complète de la table. de la table de hachage globale Redis, bloquant sérieusement le thread principal de Redis.
FLUSHALL supprime toutes les données de l'instance Redis. Si la quantité de données est importante, cela bloquera sérieusement le thread principal de Redis.
FLUSHDB, supprime les données de la base de données actuelle si la quantité de données est importante, cela bloquera le thread principal Redis.
Suggestions d'optimisation
Nous devons désactiver ces commandes en ligne. La méthode spécifique est que l'administrateur utilise la commande rename-command pour renommer ces commandes dans le fichier de configuration afin que le client ne puisse pas utiliser ces commandes.
慎用全量操作的命令
对于集合类型的来说,在未清楚集合数据大小的情况下,慎用查询集合中的全量数据,例如Hash的HetALL、Set的SMEMBERS命令、LRANGE key 0 -1 或者ZRANGE key 0 -1等命令,因为这些命令会对Hash或者Set类型的底层数据进行全量扫描,当集合数据量比较大时,会阻塞Redis的主线程。
优化建议:
当元素数据量较多时,可以用SSCAN、HSCAN 命令分批返回集合中的数据,减少对主线程的阻塞。
慎用复杂度过高命令
Redis执行复杂度过高的命令,会消耗更多的 CPU 资源,导致主线程中的其它请求只能等待。常见的复杂命令如下:SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE 等聚合类命令。
优化建议:
当需要执行排序、交集、并集操作时,可以在客户端完成,避免让Redis进行过多计算,从而影响Redis性能。
设置合适的过期时间
Redis通常用于保存热数据。热数据一般都有使用的时效性。因此,在数据存储的过程中,应根据业务对数据的使用时间合理地设置数据的过期时间。否则写入Redis的数据会一直占用内存,如果数据持续增增长,会达到机器的内存上限,造成内存溢出,导致服务崩溃。
采用批量命令代替个命令
当我们需要一次性操作多个key时,可以使用批量命令来处理,批量命令可以减少客户端与服务端的来回网络IO次数。
String或者Hash类型可以使用 MGET/MSET替代 GET/SET,HMGET/HMSET替代HGET/HSET
其它数据类型使用Pipeline命令,一次性打包发送多个命令到服务端执行。
Pipeline具体使用:
redisTemplate.executePipelined(new RedisCallback<String>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
for (int i = 0; i < 5; i++)
{
connection.set(("test:" + i).getBytes(), "test".getBytes());
}
return null;
}
});高可用维度
按照业务部署不同的实例
不同的业务线来部署 Redis 实例,这样当其中一个实例发生故障时,不会影响到其它业务。
避免单点问题
业务上根据实际情况采用主从、哨兵、集群方案,避免单点故障,影响业务的正常使用。
合理的设置相关参数
针对主从环境,我们需要合理设置相关参数,具体内容如下:
合理的设置repl-backlog参数:如果repl-backlog设置过小,当写流量比较大的场景下,主从复制中断可能会引发全量复制数据的风险。
合理设置slave client-output-buffer-limit:当从库复制发生问题时,过小的 buffer会导致从库缓冲区溢出,从而导致复制中断。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!