
Maison >Périphériques technologiques >IA >40 % plus rapide que Transformer ! Meta lance un nouveau modèle Megabyte pour résoudre le problème de la perte de puissance de calcul
40 % plus rapide que Transformer ! Meta lance un nouveau modèle Megabyte pour résoudre le problème de la perte de puissance de calcul

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-30 20:04:581104parcourir
Transformer est sans aucun doute le modèle le plus populaire dans le domaine du machine learning ces dernières années.
Depuis qu'elle a été proposée dans l'article « Attention is All You Need » en 2017, cette nouvelle structure de réseau a explosé en tâches de traduction majeures et a créé de nombreux nouveaux records.
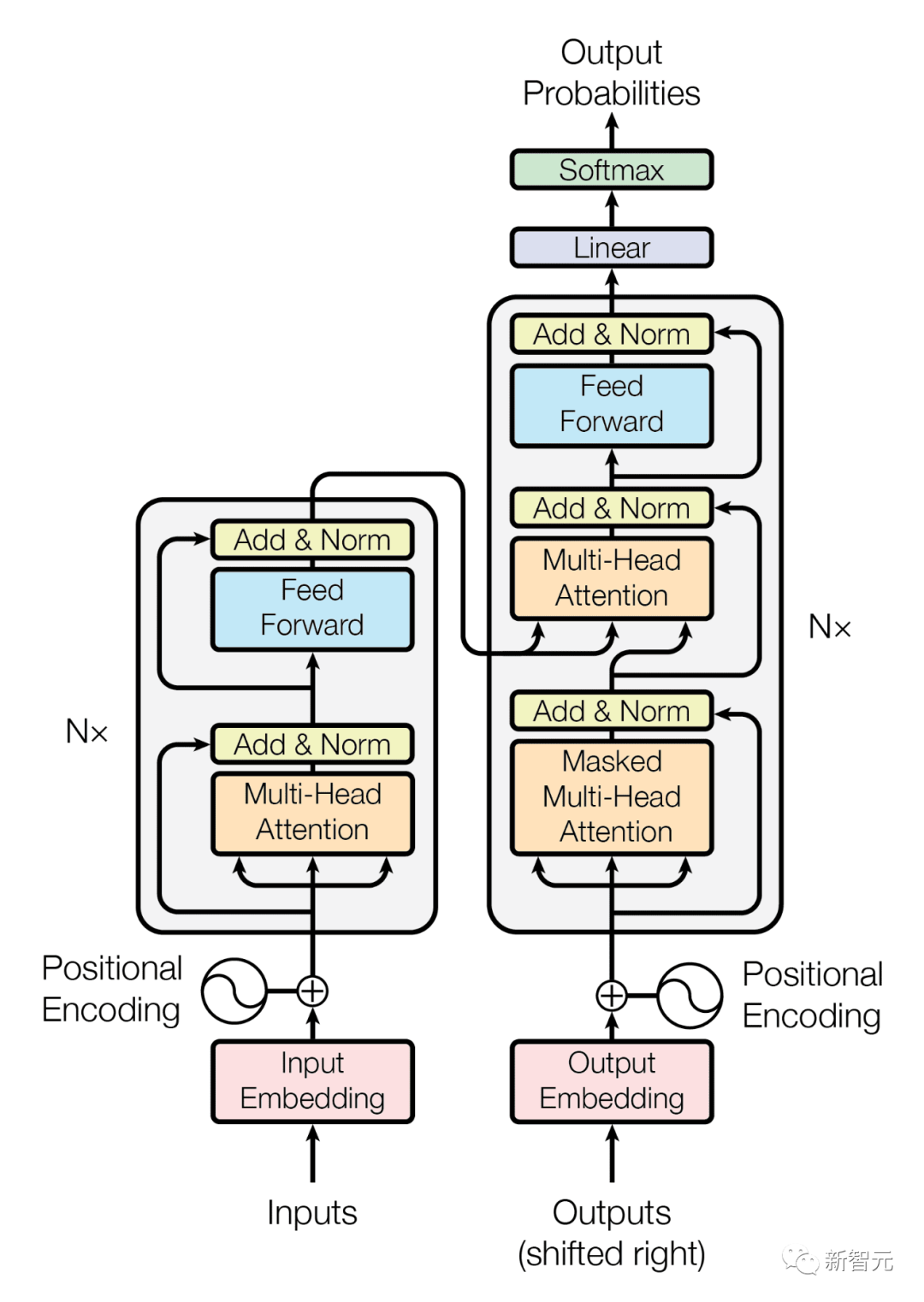
Mais Transformer a un défaut lors du traitement de longues séquences d'octets, c'est-à-dire une grave perte de puissance de calcul, et les derniers résultats des chercheurs Meta peuvent bien résoudre ce défaut.
Ils ont lancé une nouvelle architecture de modèle capable de générer plus d'un million de jetons dans plusieurs formats et de surpasser les capacités de l'architecture Transformer existante derrière des modèles tels que GPT-4.
Ce modèle s'appelle "Megabyte" et est une architecture de décodeur multi-échelle capable d'effectuer une différentiabilité de bout en bout sur des séquences de plus d'un million d'octets.

Lien papier : https://arxiv.org/abs/2305.07185
Pourquoi Megabyte est meilleur que Transformer Vous devez d'abord examiner les défauts de Transformer ?
Inconvénients de Transformer
Jusqu'à présent, plusieurs types de modèles d'IA générative hautes performances, tels que le GPT-4 d'OpenAI et le Bard de Google, sont tous des modèles basés sur l'architecture Transformer.
Mais l'équipe de recherche de Meta estime que l'architecture populaire du Transformer pourrait atteindre son seuil, les principales raisons étant deux défauts importants inhérents à la conception du Transformer :
- À mesure que la longueur des octets d'entrée et de sortie augmente, le coût l'attention personnelle augmente également rapidement, comme les fichiers de musique, d'image ou de vidéo d'entrée contiennent généralement plusieurs mégaoctets, cependant les décodeurs à grande échelle (LLM) n'utilisent généralement que quelques milliers de balises contextuelles
- réseau de rétroaction via une série de mathématiques Les opérations et les transformations aident les modèles de langage à comprendre et à traiter les mots, mais l'évolutivité est difficile à réaliser par position. Ces réseaux fonctionnent sur des groupes de caractères ou des positions de manière indépendante, ce qui entraîne une surcharge de calcul importante. Comparé à Transformer, le modèle Megabyte présente une architecture unique et différente, divisant les séquences d'entrée et de sortie en correctifs au lieu de jetons individuels.
Comme indiqué ci-dessous, dans chaque patch, le modèle d'IA local génère des résultats, tandis que le modèle global gère et coordonne la sortie finale de tous les patchs.
Tout d'abord, la séquence d'octets est divisée en patchs de taille fixe, à peu près similaires aux jetons. Ce modèle se compose de trois parties :
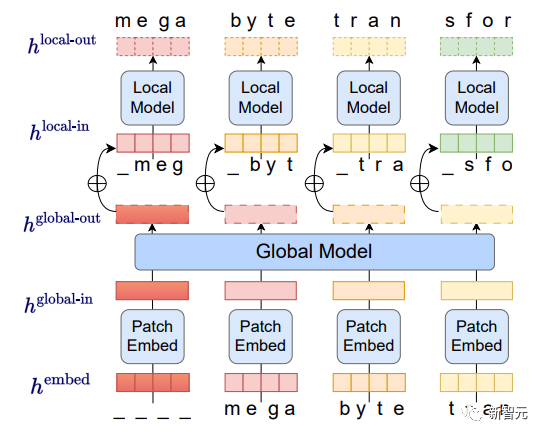
(1) intégration de patch : connecté sans perte. Chaque intégration d'octets. pour encoder simplement le patch
(2) Un modèle global : un grand transformateur autorégressif représenté par les patchs d'entrée et de sortie(3) Un modèle local : un mot prédit dans le patch Les chercheurs ont observé que la prédiction d'octets est relativement simple pour la plupart des tâches (comme compléter un mot à partir des premiers caractères), ce qui signifie qu'un grand réseau par octet n'est pas nécessaire et que des modèles plus petits peuvent être utilisés pour les prédictions internes.
Cette approche résout les problèmes d'évolutivité qui prévalent dans les modèles d'IA actuels. Le système de correctifs du modèle Megabyte permet à un seul réseau de rétroaction de s'exécuter sur des correctifs contenant plusieurs jetons, résolvant ainsi efficacement le problème de mise à l'échelle de l'auto-attention.
Parmi eux, l'architecture Megabyte a apporté trois améliorations majeures au Transformer pour la modélisation de séquences longues :
-Auto-attention sous-quadratique
Le travail des modèles de séquences longues s'est principalement concentré sur l'atténuation le coût quadratique de l'attention personnelle, tandis que Megabyte décompose les longues séquences en deux séquences plus courtes, ce qui reste réalisable même pour les longues séquences.
- Couches de rétroaction de patch (couches de rétroaction par patch)
Dans un modèle de taille GPT-3, plus de 98 % des FLOPS sont utilisés pour calculer les couches de rétroaction de position, et Megabyte utilise une grande rétroaction par couche de patch pour obtenir des modèles plus grands et plus performants au même coût. Avec une taille de patch de P, le convertisseur de base utilisera la même couche de rétroaction avec m paramètres P fois, et Megabyte pourra utiliser une couche avec des paramètres mP une fois au même coût.
- Parallélisme dans le décodage
Les transformateurs doivent effectuer tous les calculs en série pendant la génération, car l'entrée de chaque pas de temps est la sortie du pas de temps précédent, et le patch est généré en parallèle. Dit, Megabyte permet une plus grande parallélisme dans le processus de construction.
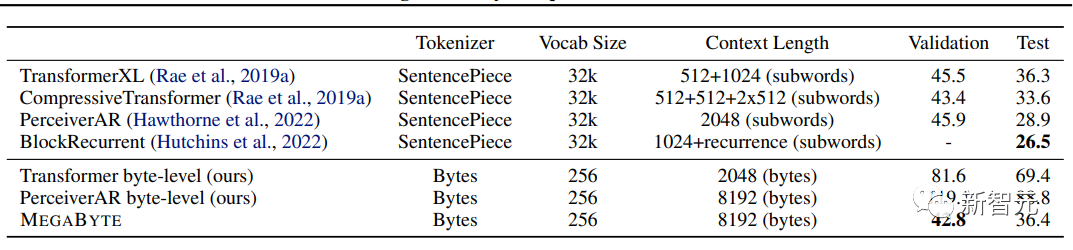
Par exemple, un modèle Megabyte avec 1,5 Mo de paramètres génère des séquences 40 % plus rapides qu'un 350MTransformer standard, tout en améliorant également la perplexité lors de l'entraînement avec la même quantité de calcul.
Megabyte surpasse de loin les autres modèles et fournit des résultats compétitifs avec les modèles sota formés sur les sous-mots
En comparaison, le GPT-4 d'OpenAI a une limite de 32 000 jetons, Claude d'Anthropic a une limite de 100 000 jetons.
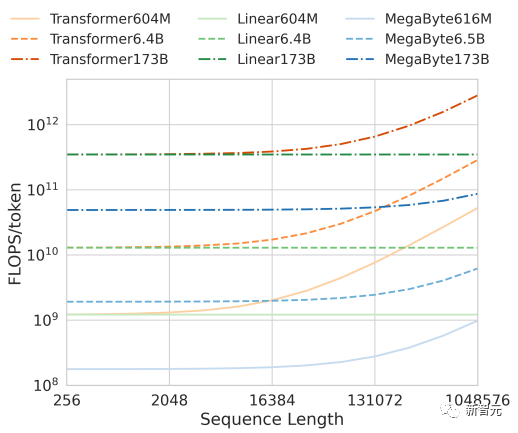
De plus, en termes d'efficacité de calcul, dans une plage de taille de modèle et de longueur de séquence fixe, Megabyte utilise moins de jetons que les transformateurs et les transformateurs linéaires de même taille, permettant l'utilisation de modèles plus grands au même coût de calcul.
Ensemble, ces améliorations nous permettent de former des modèles plus grands et plus performants avec le même budget de calcul, d'évoluer vers des séquences très longues et d'augmenter la vitesse de construction pendant le déploiement.
Que se passera-t-il dans le futur
Avec la course aux armements de l'IA qui bat son plein, les performances des modèles deviennent de plus en plus fortes et les paramètres de plus en plus élevés.
Alors que GPT-3.5 a été entraîné sur 175 milliards de paramètres, certains spéculent que le GPT-4, plus puissant, a été entraîné sur 1 000 milliards de paramètres.
Le PDG d'OpenAI, Sam Altman, a également récemment suggéré un changement de stratégie. Il a déclaré que l'entreprise envisageait d'abandonner la formation d'énormes modèles et de se concentrer sur d'autres optimisations de performances.
Il assimile l'avenir des modèles d'IA aux puces iPhone, alors que la plupart des consommateurs n'ont aucune idée des spécifications techniques d'origine.
Les méta-chercheurs pensent que leur architecture innovante arrive au bon moment, mais admettent qu'il existe d'autres moyens d'optimiser.
Par exemple, un modèle d'encodeur plus efficace utilisant la technologie de patching, un modèle de décodage qui divise la séquence en blocs plus petits et prétraite la séquence en un jeton compressé, etc., et peut étendre les capacités de l'architecture Transformer existante à construire une nouvelle génération de modèles.
L'ancien directeur de Tesla AI, Andrej Karpathy, a également pris position sur le journal, écrivant sur Twitter :
C'est très prometteur et tout le monde devrait espérer que nous pourrons abandonner la tokenisation dans les grands modèles et éliminer le besoin de ces séquences d'octets trop longues.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI