
Maison >Périphériques technologiques >IA >Dix minutes pour comprendre la logique technique et l'évolution de ChatGPT (vie passée, vie présente)
Dix minutes pour comprendre la logique technique et l'évolution de ChatGPT (vie passée, vie présente)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-30 15:00:081347parcourir
0, Avant-propos
Le 30 novembre, OpenAI a lancé un chatbot IA appelé ChatGPT, disponible en test gratuit par le public. Il est devenu populaire sur l'ensemble du réseau en quelques jours seulement.
À en juger par les multiples promotions sur les gros titres et les comptes publics, il peut non seulement écrire du code, vérifier les bugs, mais aussi écrire des romans et planifier des jeux, y compris écrire des applications pour les écoles, etc. Il semble être tout-puissant .
Dans un esprit de science (bon) et d'apprentissage (étrange), j'ai pris le temps de tester et de vérifier ChatGPT, et **de comprendre pourquoi ChatGPT est si "fort"**.
Étant donné que l'auteur n'a pas étudié l'IA professionnellement et a une énergie limitée, il n'y aura plus de chapitres techniques approfondis comme AI-003 dans peu de temps. Comprendre 001 et 002 est déjà au-delà C'est dans. la portée des gens ordinaires mangeurs de melon.
Il y aura de nombreux termes techniques dans cet article, et je vais essayer de réduire la difficulté de les comprendre.
Par ailleurs, comme je ne suis pas un professionnel de l'IA, merci de nous signaler toute erreur ou omission.
Remerciements : Je suis très reconnaissant aux deux talentueux étudiants X et Z pour leur avis, notamment à X pour son professionnalisme
1 Qu'est-ce que GPT#🎜🎜 ##. 🎜🎜#ChatGPTIl contient deux mots, l'un est Chat, ce qui signifie que vous pouvez avoir une conversation. Un autre mot est GPT.
GPTLe nom complet est Generative Pre-Trained Transformer (modèle de transformateur génératif de pré-formation).
Vous pouvez y voir un total de 3 mots, Génératif, Pré-entraîné et Transformateur.
Certains lecteurs remarqueront peut-être que je n'ai pas traduit le chinois pour Transformer ci-dessus.
Parce que Transformateur est un terme technique, s'il est traduit dur, c'est un transformateur. Mais il est facile de perdre le sens original, il vaut donc mieux ne pas le traduire.
J'expliquerai plus en détail Transformer dans le chapitre 3 ci-dessous.
2. Chronologie de l'évolution technologique de GPT
L'historique de développement de GPT depuis sa création jusqu'à nos jours est le suivant :
En juin 2017, Google a publié un article "L'attention est tout ce dont vous avez besoin", a d'abord proposé le modèle Transformer, qui est devenu la base du développement de GPT. Adresse de l'article : https://arxiv.org/abs/1706.03762
En juin 2018, OpenAI a publié l'article "Improving Language Understanding by Generative Pre-Training" (Améliorer la compréhension du langage grâce à la pré-formation générative) ), a d’abord proposé le modèle GPT (Generative Pre-Training). Adresse papier : https://paperswithcode.com/method/gpt.
En février 2019, OpenAI a publié l'article « Les modèles de langage sont des apprenants multitâches non supervisés » (le modèle de langage doit être un apprenant multitâche non supervisé) et a proposé le modèle GPT-2. Adresse de l'article : https://paperswithcode.com/method/gpt-2
En mai 2020, OpenAI a publié l'article « Les modèles linguistiques sont des apprenants peu nombreux » (le modèle linguistique devrait être un petit nombre de des échantillons (quelques coups) d'apprenants, ont proposé le modèle GPT-3 Adresse : https://paperswithcode.com/method/gpt-3
Fin février 2022, OpenAI a publié l'article. "Former des modèles de langage pour suivre les instructions avec des commentaires humains" (Utiliser le flux d'instructions de retour humain pour former des modèles de langage), a annoncé l'adresse du modèle d'instruction GPT : https://arxiv.org/abs/2203.02155
#🎜🎜. #Novembre 2022. Le 30, OpenAI a lancé le modèle ChatGPT et l'a fourni à des fins d'essai, qui est devenu populaire sur l'ensemble du réseau. Voir : AI-001 - Que peut faire le chatbot populaire ChatGPT 3. , T-Transformer de GPT (2017) Dans la section 1, nous avons dit que Transformer n'a pas de traduction appropriée Mais Transformomer est le plus important dans GPT (Generative Pre -Training Transformateur). Les mots-clés les plus basiques (Remarque : le Transformer de GPT est simplifié par rapport au Transformer original du papier de Google, seule la partie Décodeur est conservée, voir section 4.3 de cet article) #🎜 🎜#3.1. La clé est d'être bon, ou d'être une bonne personne ?
Le plus important est d'être bon, ou d'être un être humain ? 🎜#Une réponse légèrement plus sûre est : ni bon ni humain ; à la fois bon et humain
Eh bien, c'est un peu alambiqué, alors développons cela en termes humains : sémantiquement, l'accent est mis sur le bien ; sur la base et le principe, l'accent est mis sur les gens
3.2 Désolé, vous êtes une bonne personne
Développons un peu, puis « Je suis désolé, vous. êtes une bonne personne ». zhihu.com/p/82312421).
Si vous comprenez, vous pouvez ignorer mon prochain contenu sur Transformomer et passer directement au chapitre 4. Si vous ne le comprenez pas bien, vous pouvez lire ma compréhension, qui peut vous concerner.
3.3.1. Défauts majeurs du modèle RNN de la génération précédenteAvant la sortie du modèle Transformer, le modèle RNN (réseau de neurones récurrent ) était typique. L'architecture du modèle NLP est basée sur RNN et il existe d'autres variantes de modèles (en ignorant son nom, cela n'a plus d'importance après la sortie du Transformer), mais ils ont tous les mêmes problèmes et ne peuvent pas être bien résolus.
Le principe de base de RNN est de parcourir chaque vecteur de mot de gauche à droite (par exemple, c'est un chien), de conserver les données de chaque mot, et chaque mot suivant dépend du précédent. mot.
L'enjeu clé du RNN : il doit être calculé de manière séquentielle et séquentielle. Vous pouvez imaginer qu'un livre ou un article contient un grand nombre de mots, mais en raison de la dépendance de la séquence, il ne peut pas être parallélisé, donc l'efficacité est très faible.
Ce n'est peut-être pas facile à comprendre pour tout le monde. Laissez-moi vous donner un exemple (compréhension simplifiée, qui peut être légèrement différente de la situation réelle) :
Dans la boucle RNN, la phrase Vous êtes un homme bon, comment le calculer ?
1), Vous et Vous êtes un homme bon, calculez et obtenez le résultat $Vous
2), basé sur $Vous, puis utilisez Are et Vous êtes un homme bon, calculez $Are
3), en fonction de $You, $Are, continuez à calculer $a
4), et ainsi de suite, Calculez $ est, $bon, $homme, et enfin terminer le calcul complet de tous les éléments de Tu es un homme bon
Comme vous pouvez le voir, le processus de calcul est un par un, un calcul séquentiel, un seul pipeline, et le suivant Le processus dépend du processus précédent, il est donc très lent. En juin, Google a publié l'article "L'attention est tout ce dont vous avez besoin", proposant pour la première fois le modèle Transformer, qui est devenu la base du développement. de GPT. Adresse papier : https://arxiv.org/abs/1706.03762
Vous pouvez savoir grâce à son titre « L'attention est tout ce dont vous avez besoin » que Transfomer prône en fait « Tous en attention ». Alors c'est quoi l'Attention ?
Dans le journal "L'attention est tout ce dont vous avez besoin", vous pouvez voir sa définition comme suit :
L'auto-attention, parfois appelée interne L'attention est une attention mécanisme qui associe différentes positions d’une même séquence afin de calculer une représentation de la séquence. L'attention personnelle a été utilisée avec succès dans diverses tâches telles que la compréhension en lecture, le résumé abstrait, l'inclusion de discours et l'apprentissage de la représentation de phrases indépendante de la tâche. 🎜#La compréhension simple est que la corrélation entre les mots est décrite par le vecteur d'attention. Par exemple, vous êtes un homme bon(Vous êtes une bonne personne). Lorsque l'IA analyse votre vecteur d'attention, elle peut l'analyser comme ceci : De votre êtes. a Dans la phrase « homme bon », calculée via le mécanisme d'attention, la probabilité de corrélation d'attention entre vous et vous (vous) est la plus élevée (0,7, 70 %). Après tout, vous (vous) êtes vous (vous) en premier ; donc Toi, le vecteur d'attention de Toi est 0.7Le vecteur d'attention de Toi et de l'homme (personne) est lié deuxièmement (0.5, 50%), tu (toi) est une personne (homme), donc Tu ,man's Le vecteur d'attention est de 0,5
La corrélation d'attention entre vous et le bien (le bien) est à nouveau (0,4, 40%). Sur la base des êtres humains, vous êtes toujours une bonne (bonne) personne. . Ainsi, la valeur du vecteur d'attention de You,good est de 0,4 You,areLa valeur du vecteur de You,a est de 0,2.
You,areLa valeur du vecteur de You,a est de 0,2.
Donc, la liste finale des vecteurs d'attention de You est [0.7, 0.3, 0.2, 0.4, 0.5] (uniquement des exemples dans cet article).
3.4. La description de la valeur de l'attention et du transformateur dans l'article Dans l'article, la description de l'attention et du transformateur par Google , met principalement l'accent sur la dépendance séquentielle des modèles traditionnels. Le modèle Transformer peut remplacer le modèle récursif actuel et réduire la dépendance séquentielle à l'égard des entrées et des sorties.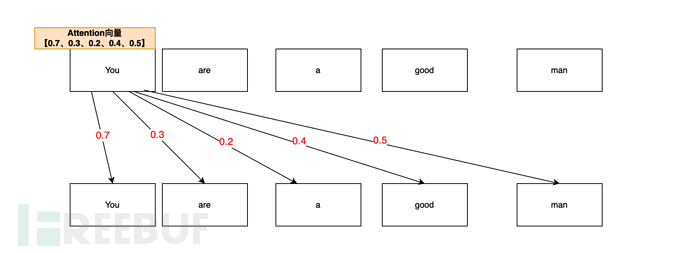 3.5. La signification profonde du mécanisme Transformer
3.5. La signification profonde du mécanisme Transformer
 3.5.1. Se débarrasser des ensembles de données d'annotation manuelles (réduire considérablement le nombre de travaux manuels)
3.5.1. Se débarrasser des ensembles de données d'annotation manuelles (réduire considérablement le nombre de travaux manuels)
Cet obstacle clé est : dans le passé, si nous voulons Pour former un modèle d'apprentissage en profondeur, nous devons utiliser de grands ensembles de données étiquetés à grande échelle pour la formation. Ces ensembles de données nécessitent un étiquetage manuel, ce qui est extrêmement coûteux. 


De cette manière, de nombreux articles prêts à l'emploi, pages Web, Zhihu Q&A, Baidu Zhizhi, etc. données annotées naturelles collectées (en un mot, cela permet d'économiser de l'argent).
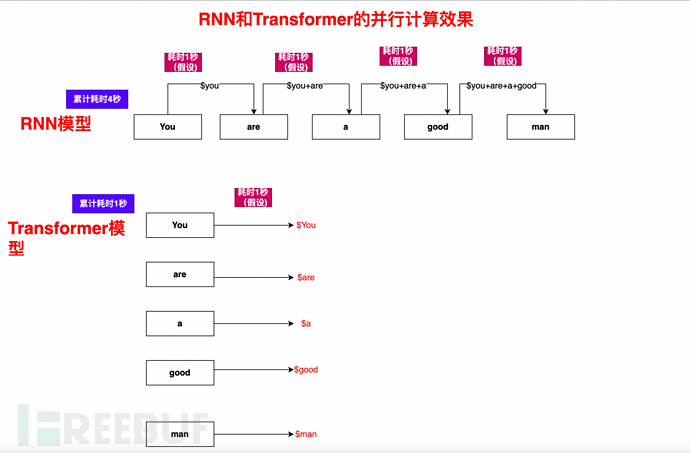
3.5.2. Transformez le calcul séquentiel en calcul parallèle, réduisant considérablement le temps de formation
En plus de l'annotation manuelle, en 3.3.1 Le Les principales lacunes du RNN mentionnées dans la sous-section sont les problèmes de calcul séquentiel et de pipeline unique.
Le mécanisme d'Auto-Attention, combiné au mécanisme de masque et à l'optimisation de l'algorithme, permet de calculer en parallèle un article, une phrase et un paragraphe.
Prenons comme exemple Tu es un homme bon. Tu peux voir que autant d'ordinateurs qu'il y a, à quelle vitesse le Transformateur peut être :
 #. 🎜🎜##🎜 🎜#
#. 🎜🎜##🎜 🎜#

 4, GPT (Pré-Formation Générative)-Juin 2018
4, GPT (Pré-Formation Générative)-Juin 2018
 4.1.1 Par exemple,
4.1.1 Par exemple,
Par exemple, c'est comme si nous élevions un enfant est divisé en deux étapes :
1), étape d'auto-apprentissage à grande échelle (auto-apprentissage de 10 millions de livres, pas de professeur) : Fournir une puissance de calcul suffisante à l'IA et laisser il soit basé sur le mécanisme d’auto-apprentissage. 2), étape d'orientation à petite échelle (enseignement de 10 livres) : à partir de 10 livres, tirer des conclusions sur "trois" # 🎜🎜#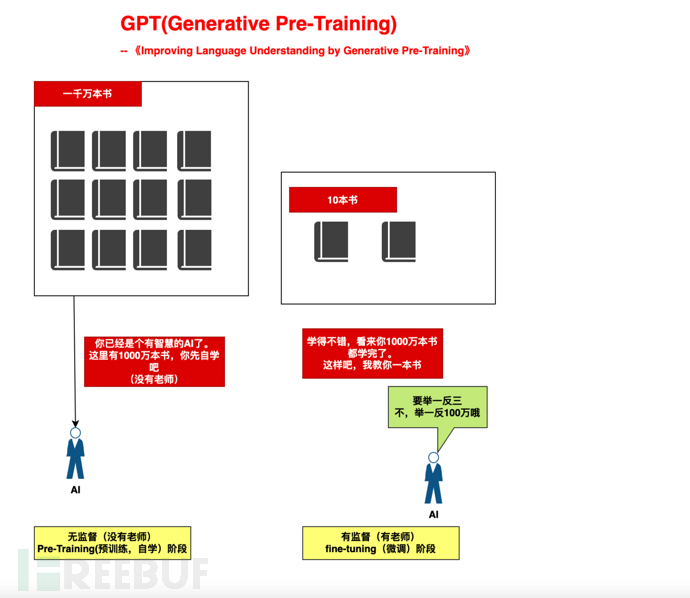
4.1.2. Description du début de l'article Accédez à l'explication du modèle GPT sur l'apprentissage supervisé et l'annotation manuelle des données. 
4.2. Proposition de base 2 du modèle GPT - Génératif
En machine learning, il existe un discriminant Il y en a deux différences entre modèle discriminant et modèle génératif.
GPT (Generative Pre-Training), comme son nom l'indique, utilise un modèle génératif. 
# 🎜🎜 #
Cela n'est peut-être pas facile à comprendre rien qu'en regardant ce qui précède, voici donc une explication supplémentaire. Ce qui précède signifie, en supposant qu'il y a 4 échantillons :
Ensuite, la caractéristique du Modèle Génératif est que la probabilité n'est pas groupée (calculez la probabilité au sein de l'échantillon et divisez-la par la somme des échantillons. Par exemple, dans le tableau ci-dessus, on constate qu'il y a un total de). 1 x=1 et y=0, on considère donc que x= 1, la probabilité de y=0 est de 1/4 (le nombre total d'échantillons est de 4).
De même, il y a un total de 2 x=2, y=0, alors la probabilité de x=2, y=0 est de 2/4.

Les caractéristiques du modèle discriminatif sont* *Regroupement de probabilités calcul (calculer la probabilité au sein du groupe et diviser par la somme au sein du groupe)**. En prenant le tableau ci-dessus comme exemple, il y a un total de 1 échantillon pour x=1 et y=0, et un total de 2 échantillons pour le groupe de x=1, donc la probabilité est de 1/2.
De même, il y a un total de 2 x=2, y=0. Et en même temps, il y a 2 échantillons dans le groupe avec x=2, alors la probabilité de x=2, y=0 est 2/2=1 (soit 100 %).

4.3. Amélioration du modèle GPT par rapport au Transfomer d'origine
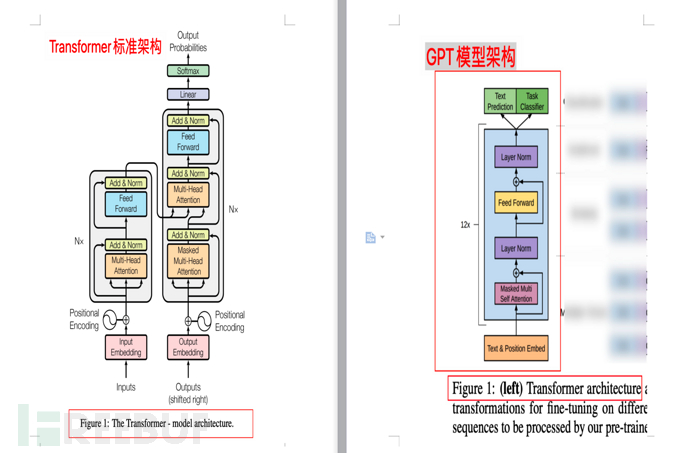
Ce qui suit est la description du modèle GPT formé avec un décodeur à 12 couches uniquement (décodeur uniquement, sans encodeur), ce qui rend le modèle plus simple.
Remarque 1 : Le Transformer original du document Google « Attention is all you need » contient deux parties : Encoder et Decoder. La première (Encoder) correspond à la traduction, et la seconde (Decoder) correspond à la génération.
Remarque 2 : Google a construit un modèle BERT (Représentations d'encodeur bidirectionnel à partir de transformateurs, Représentations d'encodeur bidirectionnel à partir de transformateurs) avec l'encodeur comme noyau. L'intérieur bidirectionnel signifie que BERT utilise à la fois le contexte supérieur et inférieur pour prédire les mots, de sorte que BERT est mieux à même de gérer les tâches de compréhension du langage naturel (NLU).
Note 3 : Le point principal de cette section est que GPT est basé sur Transformer, mais par rapport à Transformer, le modèle est simplifié, l'Encodeur est supprimé et seul le Décodeur est conservé. Dans le même temps, par rapport à la prédiction de contexte de BERT (bidirectionnelle), GPT préconise d'utiliser uniquement le contexte du mot pour prédire le mot (unidirectionnel), ce qui rend le modèle plus simple, plus rapide à calculer, plus adapté à la génération extrême, et donc GPT est meilleur dans le traitement. La tâche de génération de langage naturel (NLG) est ce que nous avons découvert dans AI-001 - ce que ChatGPT, le chatbot populaire sur Internet, peut faire est très doué pour écrire des « compositions » et inventer des mensonges. . Après avoir compris ce paragraphe, vous n’avez pas besoin de lire le reste de cette section.
Note 4 : Du point de vue de la simulation d'humains, le mécanisme du GPT ressemble davantage à de vrais humains. Parce que les êtres humains déduisent également ce qui suit (c'est-à-dire ce qui suit) sur la base de ce qui précède (ce qui est dit auparavant). Les soi-disant mots prononcés sont comme de l'eau versée. Les êtres humains ne peuvent pas ajuster les mots précédents en fonction de ce qui est dit plus tard. Même s'ils disent Faux, les gros mots blessent le cœur des gens, et on ne peut y remédier et les expliquer qu'en se basant sur les mots prononcés (ci-dessus).

4.3.1. Comparaison des diagrammes d'architecture
La figure suivante montre la comparaison entre l'architecture du modèle Transformer et l'architecture du modèle GPT (extraite des articles « L'attention est tout ce dont vous avez besoin » et « Améliorer la compréhension du langage en Pré-formation générative" respectivement)
4.4. Échelle de formation du modèle GPT
Comme mentionné précédemment, le modèle génératif est plus propice à la pré-formation de grands ensembles de données, alors quelle taille d'ensemble de données GPT utilise-t-il ?
Comme mentionné dans l'article, il utilise un ensemble de données appelé BooksCorpus, qui contient plus de 7 000 livres inédits.

5, GPT-2 (février 2019)
En février 2019, OpenAI a publié l'article "Les modèles de langage sont des apprenants multitâches non supervisés" (le modèle de langage doit être un apprenant multitâche non supervisé), proposant des modèles GPT -2. Adresse de l'article : https://paperswithcode.com/method/gpt-2
5.1. Modifications fondamentales du modèle GPT-2 par rapport à GPT-1
Comme mentionné précédemment, les propositions fondamentales de GPT incluent Générative (générative), Pré-formation. Parallèlement, la formation GPT comporte deux étapes :
1), étape d'auto-apprentissage à grande échelle (Pré-Formation, auto-apprentissage de 10 millions de livres, pas de professeur) : Fournir une puissance de calcul suffisante à l'IA et laissez-le apprendre par lui-même en fonction du mécanisme d'attention.
2), étape d'orientation à petite échelle (mise au point, enseignement de 10 livres) : sur la base de 10 livres, tirer des conclusions sur "trois"
Lorsque GPT-2, OpenAI fournira une mise au point supervisée- étape de réglage Il a été retiré directement et transformé en un modèle non supervisé.
Dans le même temps, un mot-clé **multitâche (multitâche)** a été ajouté, qui peut également être vu dans le nom de l'article "Les modèles de langage sont des apprenants multitâches non supervisés" (le modèle de langage doit être un apprenant multitâche non supervisé ) .

5.2.Pourquoi un tel ajustement ? Essayer de résoudre le problème du zéro-shot
Pourquoi GPT-2 est-il ajusté comme ça ? À en juger par la description de l'article, il s'agit d'essayer de résoudre le zéro-shot (problème d'apprentissage du zéro-shot)**.
Quel est le problème du zero-shot (apprentissage zéro-shot) ? Cela peut être simplement compris comme une capacité de raisonnement. Cela signifie que face à des choses inconnues, l’IA peut les reconnaître automatiquement, c’est-à-dire qu’elle a la capacité de raisonner.
Par exemple, avant d'aller au zoo, on dit aux enfants qu'un animal ressemblant à un cheval, qui est noir et blanc comme un panda et qui a des rayures noires et blanches, est un zèbre. les enfants peuvent trouver correctement le zèbre.
5.3. Comment comprendre le multitâche ?
Dans le ML traditionnel, si vous souhaitez entraîner un modèle, vous avez besoin d'un ensemble de données annotées spéciales pour entraîner une IA spéciale.
Par exemple, pour entraîner un robot capable de reconnaître les images de chiens, vous avez besoin d'1 million d'images étiquetées avec des chiens. Après l'entraînement, l'IA sera capable de reconnaître les chiens. Cette IA est une IA dédiée, aussi appelée mono-tâche.
Et le multitâche prône le multitâche non pas pour former une IA dédiée, mais pour alimenter des données massives, n'importe quelle tâche peut être accomplie.
5.4, données GPT-2 et échelle de formation
L'ensemble de données a été augmenté à 8 millions de pages Web et d'une taille de 40 Go.

Le modèle lui-même atteint également un maximum de 1,5 milliard de paramètres, et le Transformer est empilé sur 48 couches. Une analogie simple revient à simuler 1,5 milliard de neurones humains (juste un exemple, pas tout à fait équivalent).

6, GPT-3 (mai 2020)
En mai 2020, OpenAI a publié l'article « Les modèles de langage » sont Few-Shot Learners" (le modèle linguistique doit être un apprenant en quelques étapes), et le modèle GPT-3 est proposé. Adresse de l'article : https://paperswithcode.com/method/gpt-3
6.1, progression de l'effet révolutionnaire de GPT-3
C'est ainsi que l'effet est décrit dans l'article :
1. GPT-3 montre de solides performances en traduction, en réponse aux questions et en remplissage, tout en étant capable de déchiffrer des mots, d'utiliser de nouveaux mots dans des phrases ou d'effectuer des calculs à 3 chiffres.
2. GPT-3 peut générer des échantillons d'articles d'actualité que les humains ne peuvent plus distinguer.
Comme indiqué ci-dessous :

6.2 Les principaux changements de GPT-3 par rapport à GPT-2
. #🎜 🎜# Il a été mentionné plus tôt que GPT-2 poursuivait un apprentissage zéro-shot non supervisé (apprentissage zéro-shot), mais en fait, dans l'article GPT-2, OpenAI a également déclaré que les résultats n'avaient pas répondu aux attentes. Cela doit évidemment être ajusté, c'est pourquoi GPT-3 a apporté les ajustements pertinents. Cela ressort également du titre « Les modèles linguistiques sont des apprenants peu nombreux » (le modèle linguistique doit être un apprenant de quelques coups). Pour parler franchement, le zéro-shot (apprentissage zéro-shot) n'est pas fiable.
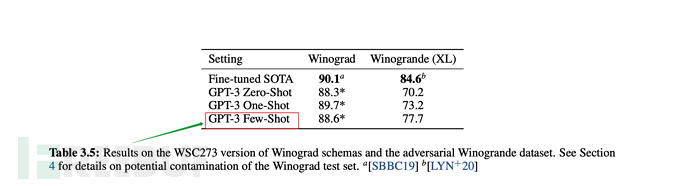
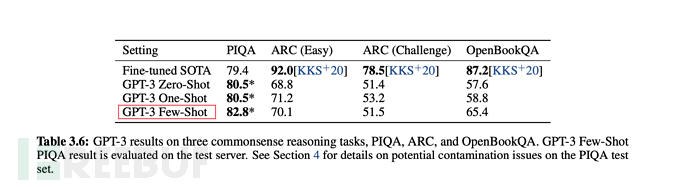
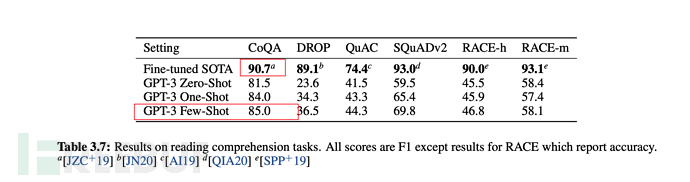
# 🎜 🎜#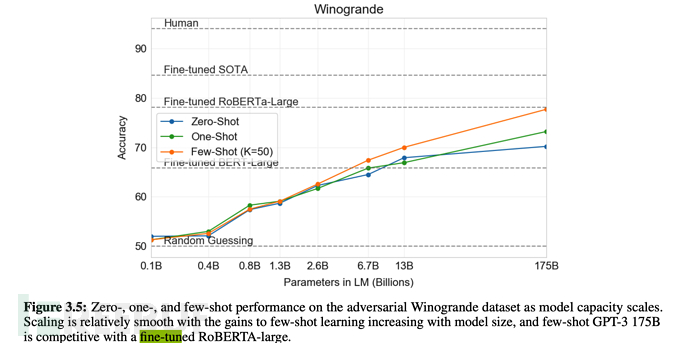 6.3, échelle de formation GPT-3
6.3, échelle de formation GPT-3
GPT-3 utilise 45 To de texte compressé avant le filtrage, et il reste encore 570 Go de données massives après le filtrage.
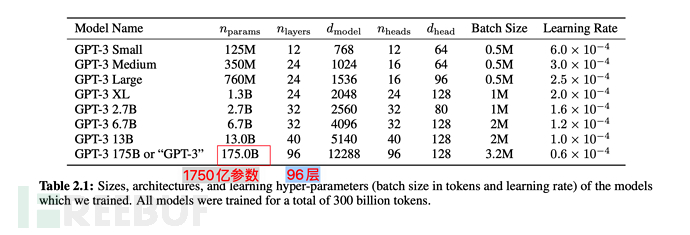
 En termes de paramètres du modèle, il est passé de 1,5 milliard en GPT-2 à 175 milliards, soit une augmentation de plus de 110 fois le Transformer ; La couche est également passée de 48 à 96.
En termes de paramètres du modèle, il est passé de 1,5 milliard en GPT-2 à 175 milliards, soit une augmentation de plus de 110 fois le Transformer ; La couche est également passée de 48 à 96.
7. Instruction GPT (février 2022)
Fin février 2022, OpenAI a publié le document "Former des modèles de langage pour suivre des instructions avec un retour humain" (en utilisant le flux d'instructions de retour humain pour former des modèles de langage), annonçant Instruction Modèle GPT. Adresse papier : https://arxiv.org/abs/2203.02155
7.1. Modifications fondamentales de l'instruction GPT par rapport à GPT-3
L'instruction GPT est une série d'optimisation améliorée basée sur GPT-3, elle est donc également appelée GPT. - 3.5.
Comme mentionné précédemment, GPT-3 prône l'apprentissage en quelques étapes tout en insistant sur l'apprentissage non supervisé.
Mais en fait, l'effet de quelques tirs est évidemment pire que la méthode de supervision fine.
Alors que devons-nous faire ? Revenir à la mise au point pour superviser la mise au point ? Apparemment non.
OpenAI donne une nouvelle réponse : basé sur GPT-3, entraînez un modèle de récompense (modèle de récompense) basé sur un retour manuel (RHLF), puis utilisez le modèle de récompense (modèle de récompense, RM) pour entraîner le modèle d'apprentissage.
Oh mon Dieu, je suis si jeune. . Il est temps d’utiliser des machines (IA) pour former des machines (IA). .

7.2. Les étapes de formation de base de l'instruction GPT
L'instruction GPT comprend 3 étapes au total :
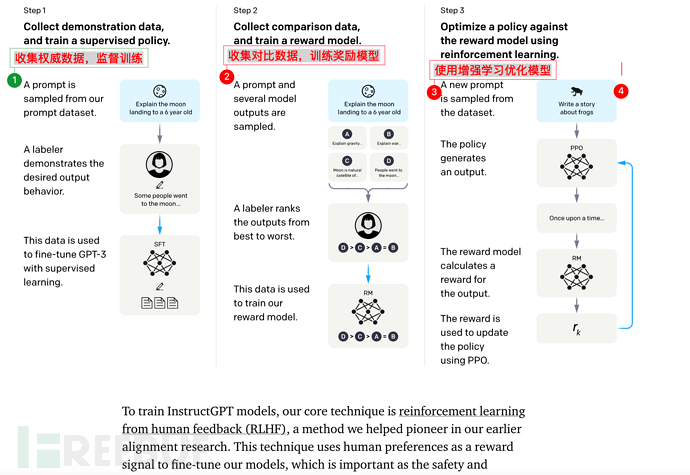
1), effectuer un **réglage fin (réglage précis de la supervision)** sur GPT-3. .
2), puis former un modèle de récompense (RM)
3), et enfin optimiser SFT grâce à l'apprentissage par renforcement


Il est à noter que les étapes 2 et 3 sont tout à fait possibles. Des itérations et des boucles sont effectuées plusieurs fois.
7.3. L'échelle de formation de l'instruction GPT
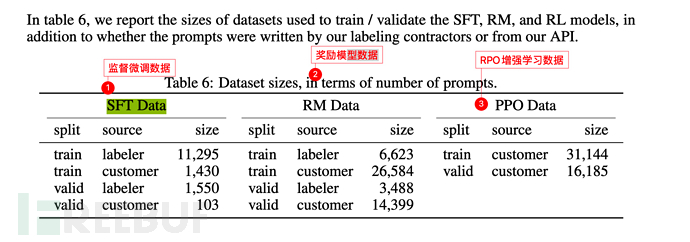
L'échelle de données de base est la même que celle de GPT-3 (voir section 6.3), mais 3 étapes y sont ajoutées (mise au point supervisée SFT, modèle de récompense de formation et modèle de récompense). optimisation améliorée de l'apprentissage (RPO) .
L'étiqueteur dans l'image ci-dessous fait référence au **étiqueteur** employé par ou lié à OpenAI.
Et client fait référence à l'utilisateur appelant de l'API GPT-3 (c'est-à-dire d'autres chercheurs en apprentissage automatique, programmeurs, etc.).
Après le lancement de ChatGPT cette fois, on dit qu'il y a plus d'un million d'utilisateurs, et chacun de nous est son client. Il est donc prévisible que lorsque GPT-4 sera publié dans le futur, son échelle de clientèle augmentera. être d'au moins un million.
8. ChatGPT (novembre 2022)
Le 30 novembre 2022, OpenAI a lancé le modèle ChatGPT et proposé des essais, qui sont devenus populaires sur l'ensemble du réseau.
Voir : AI-001 - Ce que le chatbot populaire ChatGPT peut faire
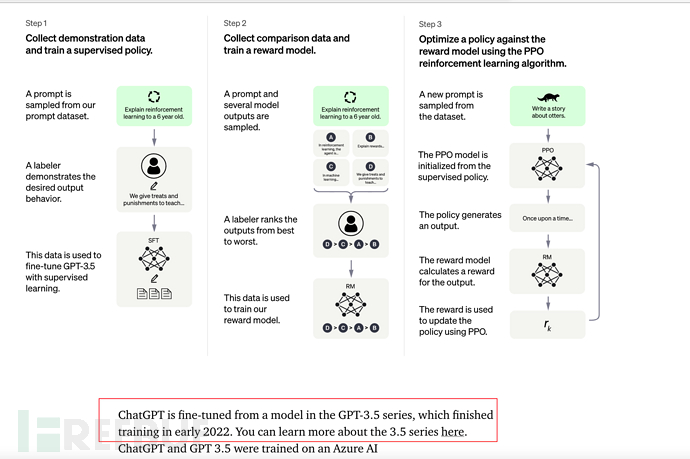
8.1, ChatGPT et Instruction GPT
ChatGPT et InstructionGPT sont essentiellement de la même génération. Ils ajoutent simplement Chat sur la base d'InstructionGPT. La fonction est également ouverte. au public pour des tests et une formation afin de générer des données annotées plus efficaces.
8.2. [Important, il est recommandé de parcourir la vidéo recommandée ci-dessous] Du point de vue de la compréhension intuitive humaine, nous compléterons les principes fondamentaux de ChatGPT
Vous pouvez vous référer à la vidéo « Comment est créé ChatGPT ? " par Li Hongyi, professeur à l'Université nationale de Taiwan. Processus de socialisation GPT" est très bien expliqué.
https://www.inside.com.tw/article/30032-chatgpt-possible-4-steps-training
GPT est une génération à sens unique, c'est-à-dire que ce qui suit est généré sur la base de ce qui précède.
Par exemple, il y a une phrase :
Donnez votre contribution au modèle GPT Bonjour, le mot suivant est pour venir vous chercher, d'accord ? Vous êtes beau? Es-tu si grand ? À quel point es-tu belle ? Attendez, GPT calculera une probabilité et donnera la probabilité la plus élevée comme réponse.
Et ainsi de suite, si une commande (ou une invite) est donnée, ChatGPT calculera également ce qui suit (réponse) en fonction de ce qui précède (invite), et sélectionnera en même temps la probabilité la plus élevée de répondre ci-dessus.
Comme indiqué ci-dessous :
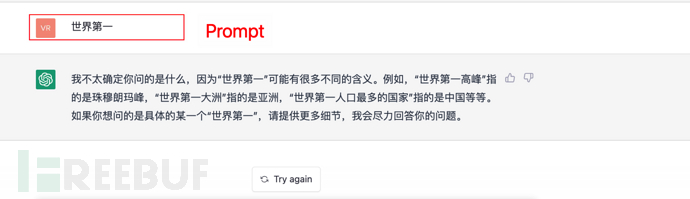
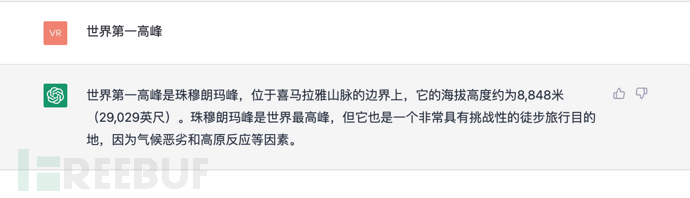
9.
1) En 2017, Google a publié l'article « L'attention est tout ce dont vous avez besoin » et a proposé le modèle Transformer, qui a ouvert la voie au GPT.
2), En juin 2018, OpenAI a publié le modèle de pré-formation génératif GPT, qui a été formé via le grand ensemble de données BooksCorpus (7 000 livres), et a préconisé une pré-formation à grande échelle et non supervisée ( pré-formation) + mise au point supervisée (mise au point) pour la construction du modèle.
3), En février 2019, OpenAI a publié le modèle GPT-2, élargissant encore l'échelle de formation (en utilisant un ensemble de données de 40 Go avec un maximum de 1,5 milliard de paramètres). Dans le même temps, en termes d'idées, le processus de mise au point est supprimé et l'accent est mis sur le zéro-shot (apprentissage zéro-shot) et le multitâche (multi-tâches). Mais au final, l’effet zéro-shot est nettement inférieur au réglage fin.
4), En mai 2020, OpenAI a publié le modèle GPT-3, élargissant encore **l'échelle de formation (en utilisant un ensemble de données de 570 Go et 175 milliards de paramètres)**. En même temps, il adopte un modèle d'apprentissage en quelques coups (petit nombre d'échantillons) et obtient d'excellents résultats. Bien entendu, le réglage fin a été comparé simultanément dans l’expérience, et l’effet était légèrement pire que le réglage fin.
5), En février 2022, OpenAI a publié le modèle Instruction GPT Cette fois, il est principalement basé sur GPT-3, ajoutant un lien de réglage fin supervisé (Supervised Fine-tuning), et basé. à ce sujet, le modèle de récompense est en outre ajouté pour optimiser le modèle d'apprentissage grâce à l'apprentissage amélioré RPO via le modèle de formation RM.
6), Le 30 novembre 2022, OpenAI a publié le modèle ChatGPT, qui peut être compris comme un InstructionGPT après plusieurs cycles de formation itérative, et sur cette base, une fonction de dialogue Chat a été ajoutée.
10. Futur (GPT-4 ou ?)
À en juger par divers signes, GPT-4 pourrait être dévoilé en 2023 ? Quelle sera sa puissance ?
Dans le même temps, l'effet de ChatGPT a attiré beaucoup d'attention dans l'industrie. Je pense que davantage de modèles de formation basés sur GPT et leurs applications fleuriront à l'avenir.
Attendons de voir ce que l'avenir nous réserve.
Quelques références
ai.googleblog.com/2017/08/transformer-novel-neural-network.html
https:// arxiv .org/abs/1706.03762
https://paperswithcode.com/method/gpt
https://paperswithcode.com/method/gpt-2#🎜🎜 #
https://paperswithcode.com/method/gpt-3https://arxiv.org/abs/2203.02155https://zhuanlan . zhihu.com/p/464520503https://zhuanlan.zhihu.com/p/82312421https://cloud.tencent.com/developer/article / 1656975https://cloud.tencent.com/developer/article/1848106https://zhuanlan.zhihu.com/p/353423931# 🎜🎜#https://zhuanlan.zhihu.com/p/353350370
https://juejin.cn/post/6969394206414471175
https://zhuanlan. .com/p/266202548
https://en.wikisensitivity.org/wiki/Generative_model
https://zhuanlan.zhihu.com/p /67119176#🎜 🎜#
https://zhuanlan.zhihu.com/p/365554706https://cloud.tencent.com/developer/article/1877406https://zhuanlan.zhihu.com/p/34656727https://zhuanlan.zhihu.com/p/590311003
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Tout ce que vous devez savoir sur les utilisateurs de ChatGPT-4
- La vraie création 3D est là, vous devez utiliser vos mains pour faire des gestes ! L'IA ne peut pas prendre mon travail cette fois, n'est-ce pas ?
- La version Google de ChatGPT est soudainement lancée en version bêta publique ! Les résultats du test proprement dit sont ici. La demande d'expérience est acceptée rapidement.
- Pour lutter contre ChatGPT, Google lance la version bêta de Bard