
Maison >Périphériques technologiques >IA >En double-tuant OpenAI en termes d'échelle et de performances, Meta Voice atteint le niveau LLaMA ! Le modèle MMS open source reconnaît plus de 1 100 langues
En double-tuant OpenAI en termes d'échelle et de performances, Meta Voice atteint le niveau LLaMA ! Le modèle MMS open source reconnaît plus de 1 100 langues

- PHPzavant
- 2023-05-24 16:25:061357parcourir
En termes de voix, Meta a franchi une nouvelle étape au niveau LLaMA.
Aujourd'hui, Meta lance un projet vocal multilingue à grande échelle appelé MMS qui va révolutionner la technologie vocale.
MMS prend en charge plus de 1000 langues, est formé avec la Bible et a un taux d'erreur qui n'est que la moitié de celui de l'ensemble de données Whisper.
Avec un seul modèle, Meta a construit une Tour de Babel.
De plus, Meta a choisi de rendre tous les modèles et codes open source, dans l'espoir de contribuer à protéger la diversité des langues du monde.

Le modèle précédent pouvait couvrir environ 100 langues, mais cette fois, le MMS a directement augmenté ce nombre de 10 à 40 fois plus!
Plus précisément, Meta a ouvert des modèles de reconnaissance/synthèse vocale multilingues dans plus de 1 100 langues et des modèles de reconnaissance vocale dans plus de 4 000 langues.
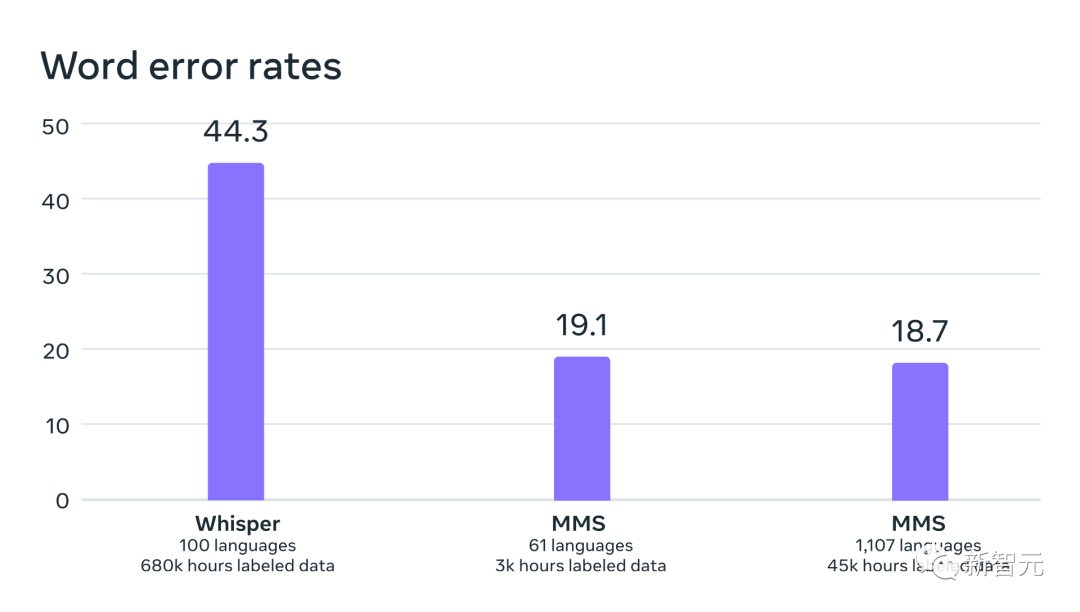
Par rapport à OpenAI Whisper, le modèle ASR multilingue prend en charge 11 fois plus de langues, mais le taux d'erreur moyen sur 54 langues est inférieur à la moitié de FLEURS.
De plus, après avoir étendu l'ASR à autant de langues, il n'y a qu'une très légère dégradation des performances.
Adresse papier : https://research.facebook.com/publications/scaling-speech-technology-to-1000-linguals/#🎜🎜 #
Protégez les langues en voie de disparition, le MMS augmente la reconnaissance vocale 40 foisLaissez la machine avoir la capacité de reconnaître et de générer de la parole, permettant ainsi à plus de personnes obtenir des informations.
Cependant, générer des modèles d'apprentissage automatique de haute qualité pour ces tâches nécessite de grandes quantités de données étiquetées, telles que des milliers d'heures d'audio et de transcriptions - pour la plupart des langues. de telles données n’existent tout simplement pas.
Les modèles de reconnaissance vocale existants ne couvrent qu'une centaine de langues, ce qui ne représente qu'une petite partie des plus de 7 000 langues connues sur la planète. Il est inquiétant de constater que la moitié de ces langues risquent de disparaître d’ici notre vivant.
Dans le projet Massively Multilingual Speech (MMS), les chercheurs ont combiné wav2vec 2.0 (le travail pionnier de Meta dans l'apprentissage auto-supervisé) et un nouvel ensemble de données pour surmonter certains défis.
Cet ensemble de données fournit des données étiquetées pour plus de 1 100 langues et des données non étiquetées pour près de 4 000 langues.

Grâce à une formation multilingue, wav2vec 2.0 apprend les unités phonétiques utilisées dans plusieurs langues# 🎜🎜 #
Certaines de ces langues, comme le tatuyo, ne comptent que quelques centaines de locuteurs, et pour la plupart des langues de l'ensemble de données, la technologie vocale n'a tout simplement pas fonctionné exister avant.Les résultats montrent que les performances du modèle MMS sont meilleures que celles du modèle existant, et le nombre de langues couvertes est 10 fois supérieur à celui du modèle existant.
Meta s'est toujours concentré sur le travail multilingue : sur le texte, le projet NLLB de Meta a étendu la traduction multilingue à 200 langues, tandis que le projet MMS a étendu la technologie vocale à davantage de langues.
La Bible résout l'énigme des ensembles de données vocales
Collecter des données audio dans des milliers de langues n'est pas une affaire simple, et c'est aussi le problème de Meta premier défi auquel les chercheurs sont confrontés.Vous devez savoir que le plus grand ensemble de données vocales existant ne couvre que 100 langues au maximum. Pour surmonter ce problème, les chercheurs se sont tournés vers des textes religieux comme la Bible.
De tels textes ont été traduits dans de nombreuses langues différentes, utilisés dans le cadre de recherches approfondies et divers enregistrements publics ont été réalisés.
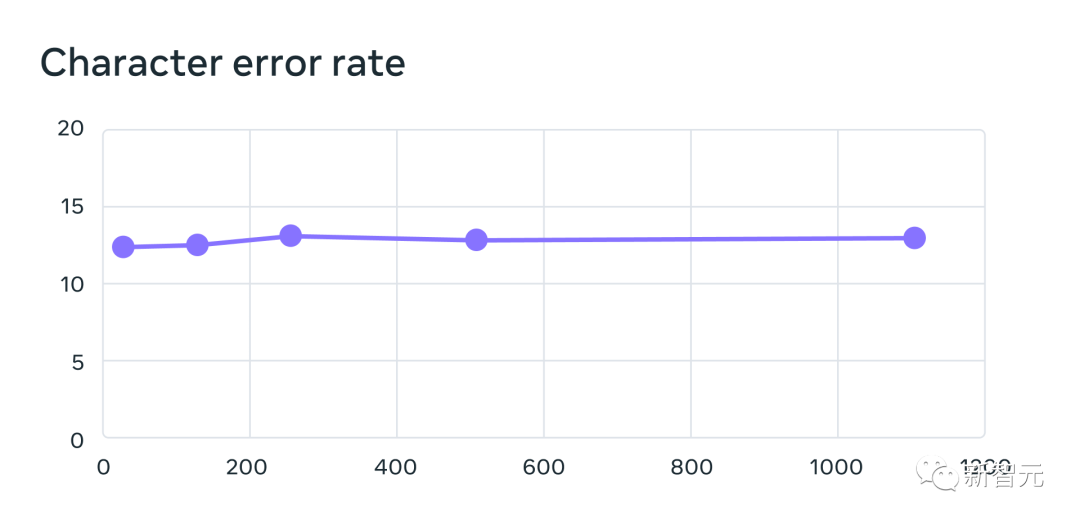
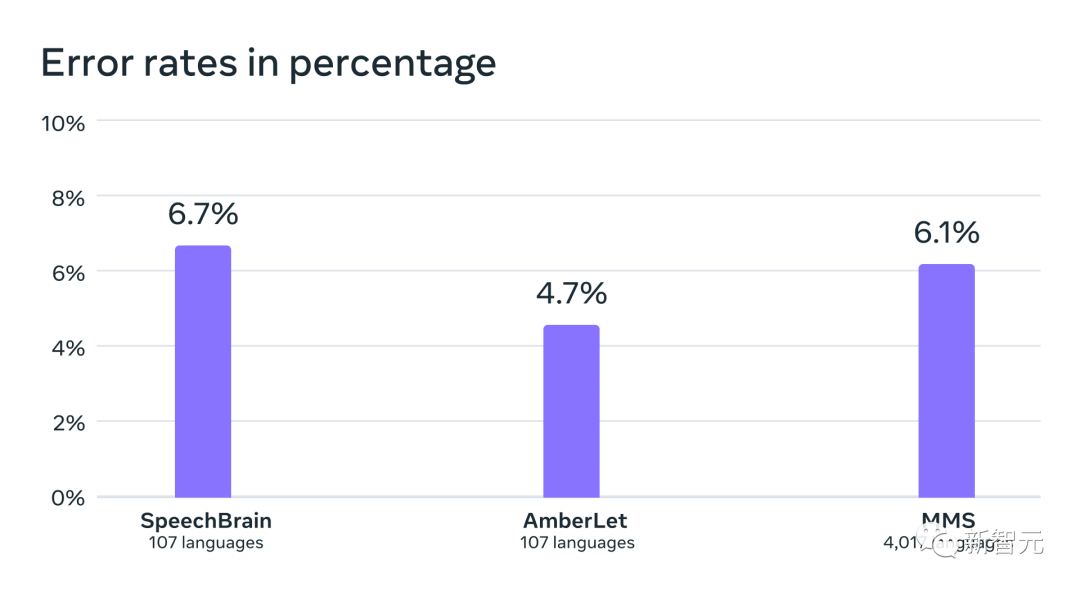
À cette fin, les chercheurs Meta ont spécialement créé un ensemble de données de lecture du Nouveau Testament dans plus de 1 100 langues, fournissant en moyenne 32 heures de données par langue. Couplés à des enregistrements non étiquetés de diverses autres lectures religieuses, les chercheurs ont augmenté le nombre de langues disponibles à plus de 4 000. Un modèle de reconnaissance vocale automatique entraîné sur des données MMS, avec des taux d'erreur similaires pour les locuteurs masculins et féminins sur le benchmark FLEURS Ces données sont généralement prononcées par des hommes, mais le modèle a tout aussi bien fonctionné sur les voix masculines et féminines. Et, même si le contenu des enregistrements était religieux, cela n'a pas trop orienté le modèle vers la production d'un langage plus religieux. Les chercheurs pensent que cela est dû au fait qu'ils ont utilisé une méthode de classification temporelle connexionniste, beaucoup plus restrictive que les grands modèles de langage ou les modèles séquence à séquence utilisés pour la reconnaissance vocale. Les chercheurs ont d'abord prétraité les données pour améliorer leur qualité et permettre leur utilisation par des algorithmes d'apprentissage automatique. Pour ce faire, les chercheurs ont formé un modèle d'alignement sur des données existantes dans plus de 100 langues et ont utilisé ce modèle avec un algorithme d'alignement forcé efficace qui peut traiter en 20 minutes ou plus l'enregistrement du temps. Les chercheurs ont répété ce processus plusieurs fois et ont effectué une dernière étape de filtrage de validation croisée basée sur la précision du modèle pour supprimer les données potentiellement mal alignées. Pour permettre à d'autres chercheurs de créer de nouveaux ensembles de données vocales, les chercheurs ont ajouté l'algorithme d'alignement à PyTorch et publié le modèle d'alignement. Actuellement, il existe 32 heures de données pour chaque langue, mais cela ne suffit pas pour entraîner les modèles traditionnels de reconnaissance vocale supervisée. C'est pourquoi les chercheurs entraînent des modèles sur wav2vec 2.0, ce qui peut réduire considérablement la quantité de données annotées nécessaires pour entraîner un modèle. Plus précisément, les chercheurs ont formé le modèle auto-supervisé sur environ 500 000 heures de données vocales dans plus de 1 400 langues, soit près de cinq fois plus que par le passé. Les chercheurs peuvent ensuite affiner le modèle pour des tâches vocales spécifiques, telles que la reconnaissance vocale multilingue ou la reconnaissance linguistique. Pour mieux comprendre les performances des modèles formés sur des données vocales multilingues à grande échelle, les chercheurs les ont évalués sur des ensembles de données de référence existants. Les chercheurs ont utilisé un modèle wav2vec 2.0 à paramètre 1B pour former un modèle de reconnaissance vocale multilingue pour plus de 1 100 langues. Les performances diminuent à mesure que le nombre de langues augmente, mais cette diminution est légère - de 61 langues à 1107 langues, le taux d'erreur de caractère n'augmente que d'environ 0,4%, mais la couverture linguistique augmente de plus de 18 fois. Taux d'erreur pour 61 langues FLEURS d'un système de reconnaissance multilingue entraîné à l'aide de données MMS lors de l'augmentation du nombre de langues prises en charge par chaque système de 61 à 1 107. Des taux d'erreur plus élevés indiquent des performances inférieures Dans une comparaison pomme-pomme avec Whisper d'OpenAI, les chercheurs ont découvert que les modèles formés sur les données vocales massivement multilingues avaient près de la moitié du taux d'erreur sur les mots, mais que la parole massivement multilingue en couvrait 11 fois plus. langues que Whisper. D'après les données, nous pouvons voir que par rapport aux meilleurs modèles vocaux actuels, le modèle de Meta fonctionne très bien. Comparaison des taux d'erreur de mots entre OpenAI Whisper et Massively Multilingual Speech sur 54 langues FLEURS# 🎜 🎜# Ensuite, les chercheurs ont formé un modèle d'identification de langue (LID) pour plus de 4 000 langues en utilisant leurs propres ensembles de données ainsi que des ensembles de données existants tels que FLEURS et CommonVoice, et l'ont réalisé sur FLEURS LID. évalué sur la tâche. Les faits ont prouvé que même s'il prend en charge près de 40 fois plus de langues, les performances restent très bonnes. Précision de la reconnaissance linguistique sur le benchmark VoxLingua-107 des travaux existants, pris en charge Il y en a un peu plus 100 langues et MMS prend en charge plus de 4 000 langues. Les chercheurs ont également construit des systèmes de synthèse vocale pour plus de 1 100 langues. Cependant, cette fonctionnalité constitue un avantage pour la création de systèmes de synthèse vocale, c'est pourquoi les chercheurs ont formé des systèmes similaires pour plus de 1 100 langues. Les résultats montrent que la qualité de la parole produite par ces systèmes n'est pas mauvaise. L'avenir appartient à un modèle unique Les chercheurs de Meta sont satisfaits des résultats, mais comme pour toutes les technologies émergentes d'IA, Meta est actuellement Le modèle n'est pas parfait. Dans le même temps, Meta estime que la coopération des géants de l'IA est cruciale pour le développement d'une technologie d'IA responsable. De nombreuses langues du monde risquent de disparaître, et les limites de la technologie actuelle de reconnaissance vocale et de génération de parole ne feront qu'accélérer cette tendance. Les chercheurs envisagent un monde où la technologie a l'effet inverse, encourageant les gens à garder leur langue vivante car ils peuvent accéder à l'information et utiliser la technologie en parlant leur langue préférée. Le projet de parole multilingue à grande échelle est une étape importante dans cette direction. À l'avenir, les chercheurs espèrent augmenter encore la couverture linguistique, prendre en charge davantage de langues et même trouver des moyens de gérer les dialectes. Vous savez, les dialectes ne sont pas simples pour la technologie vocale existante. L'objectif ultime de Meta est de permettre aux utilisateurs d'accéder plus facilement aux informations et d'utiliser les appareils dans leur langue préférée. Enfin, les chercheurs Meta ont également envisagé un scénario futur dans lequel un seul modèle peut résoudre plusieurs tâches vocales dans toutes les langues. Actuellement, bien que Meta entraîne des modèles distincts pour la reconnaissance vocale, la synthèse vocale et la reconnaissance du langage, les chercheurs pensent qu'à l'avenir, un seul modèle pourra accomplir toutes ces tâches , et plus encore. 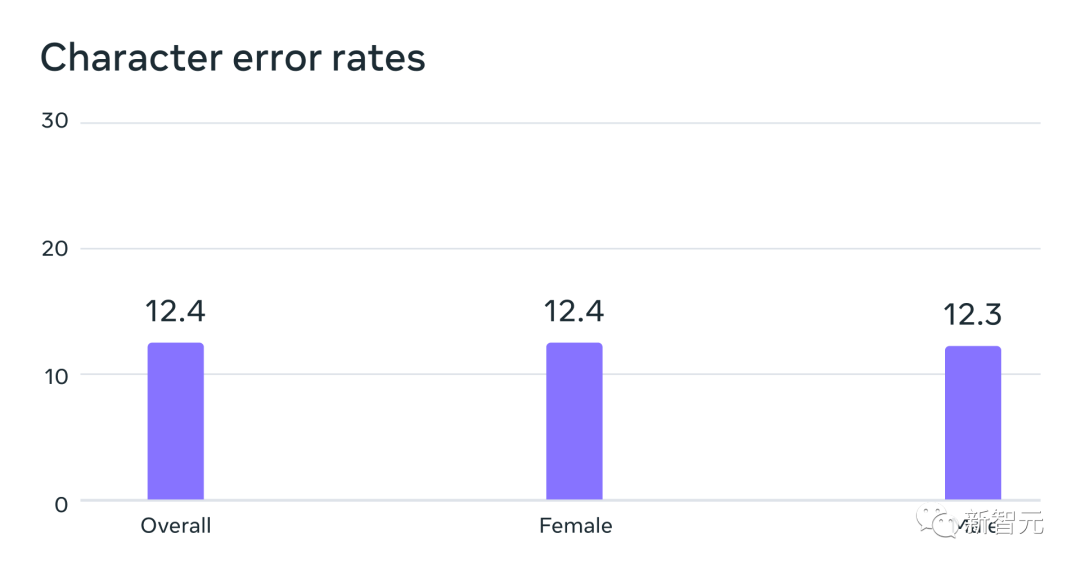
Plus le modèle est gros, mieux il peut se battre ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI