
Maison >développement back-end >Tutoriel Python >Dessiner des graphiques de visualisation dynamique avec Python, c'est tellement cool !
Dessiner des graphiques de visualisation dynamique avec Python, c'est tellement cool !

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-24 12:01:062544parcourir

Le storytelling est une compétence cruciale pour les data scientists. Afin d’exprimer nos idées et de convaincre les autres, nous devons communiquer efficacement. Et de belles visualisations sont un excellent outil pour cette tâche.
Cet article présentera 5 techniques de visualisation non traditionnelles qui peuvent rendre vos histoires de données plus belles et plus efficaces. La bibliothèque graphique Plotly de Python sera utilisée ici, vous permettant de générer sans effort des graphiques animés et des graphiques interactifs.
Installez le module
Si vous n'avez pas encore installé Plotly, exécutez simplement la commande suivante dans votre terminal pour terminer l'installation :
pip install plotly
Visualisation de graphiques dynamiques
Lorsque l'on étudie l'évolution de tel ou tel indicateur, on implique souvent données temporelles. L'outil d'animation Plotly permet aux utilisateurs de regarder les données changer au fil du temps avec une seule ligne de code, comme indiqué ci-dessous :
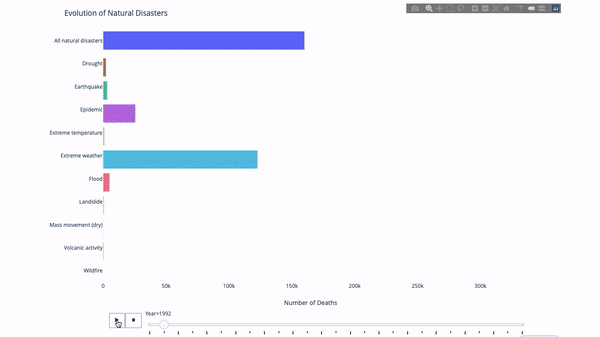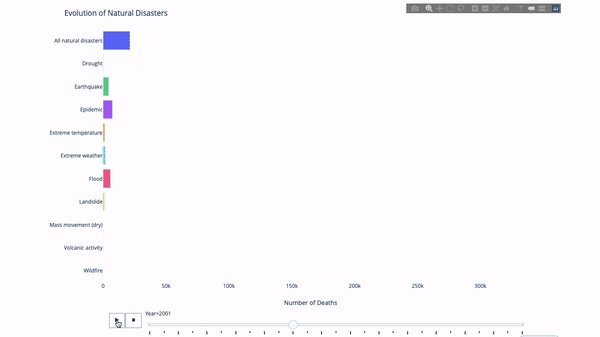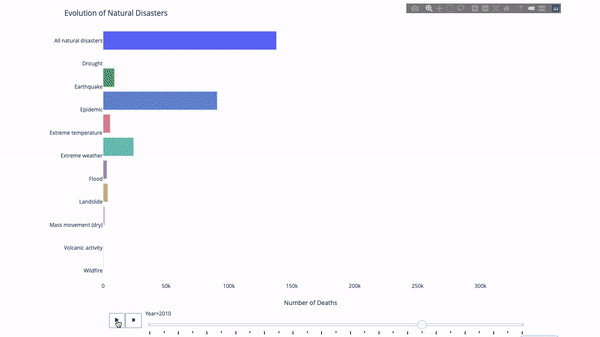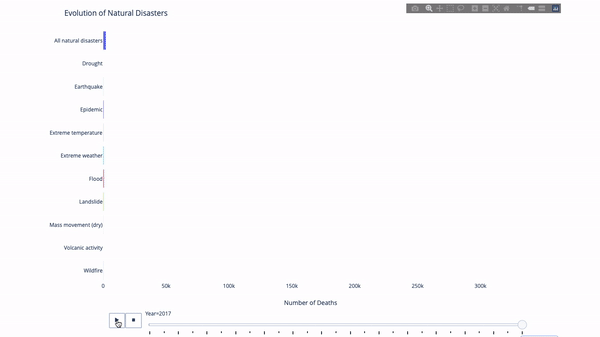
Le code est le suivant :
import plotly.express as px from vega_datasets import data df = data.disasters() df = df[df.Year > 1990] fig = px.bar(df, y="Entity", x="Deaths", animation_frame="Year", orientation='h', range_x=[0, df.Deaths.max()], color="Entity") # improve aesthetics (size, grids etc.) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)', title_text='Evolution of Natural Disasters', showlegend=False) fig.update_xaxes(title_text='Number of Deaths') fig.update_yaxes(title_text='') fig.show()
Tant que vous disposez d'une variable temporelle sur laquelle filtrer, alors presque tous les graphiques feront l'affaire. Voici un exemple d'animation d'un graphique à nuages de points :
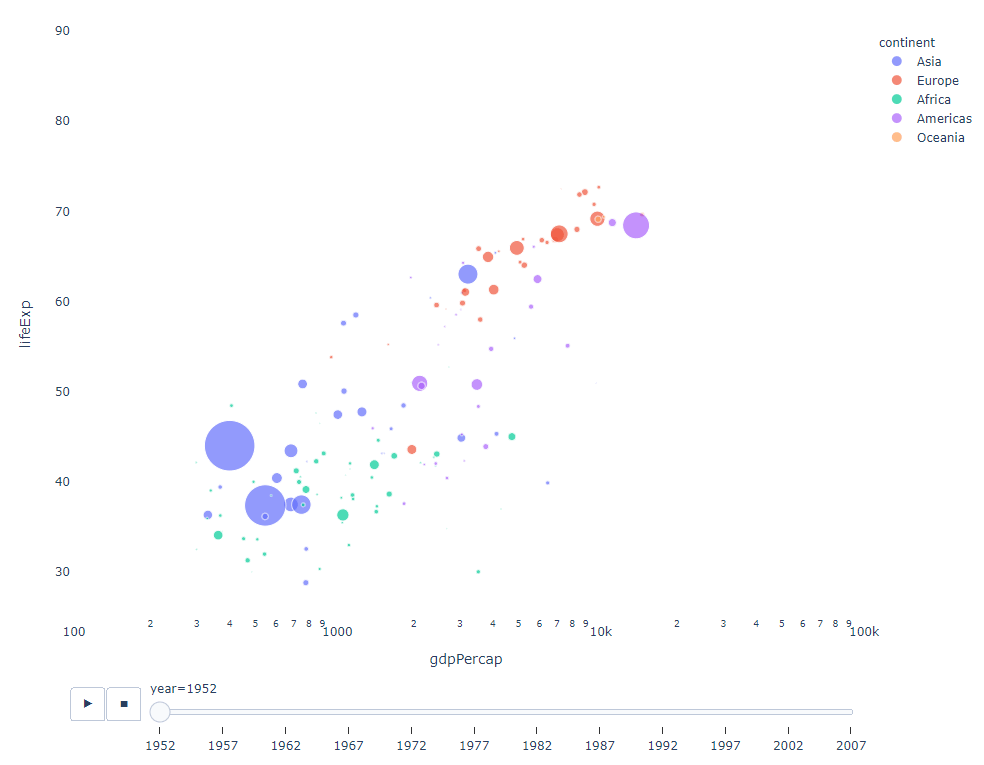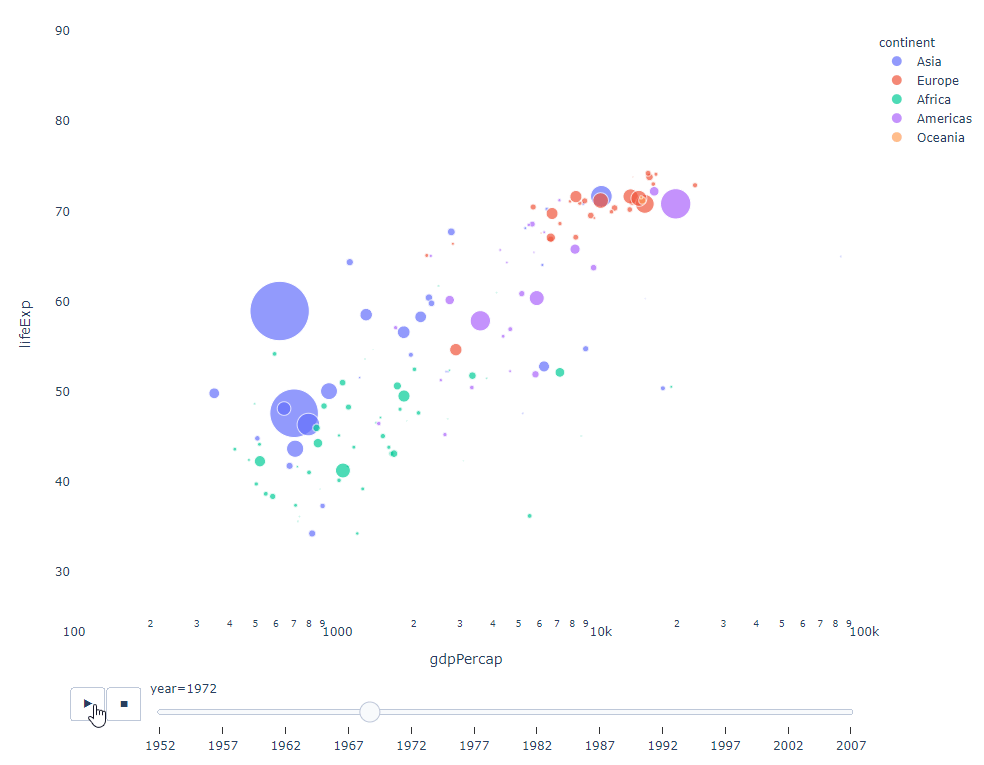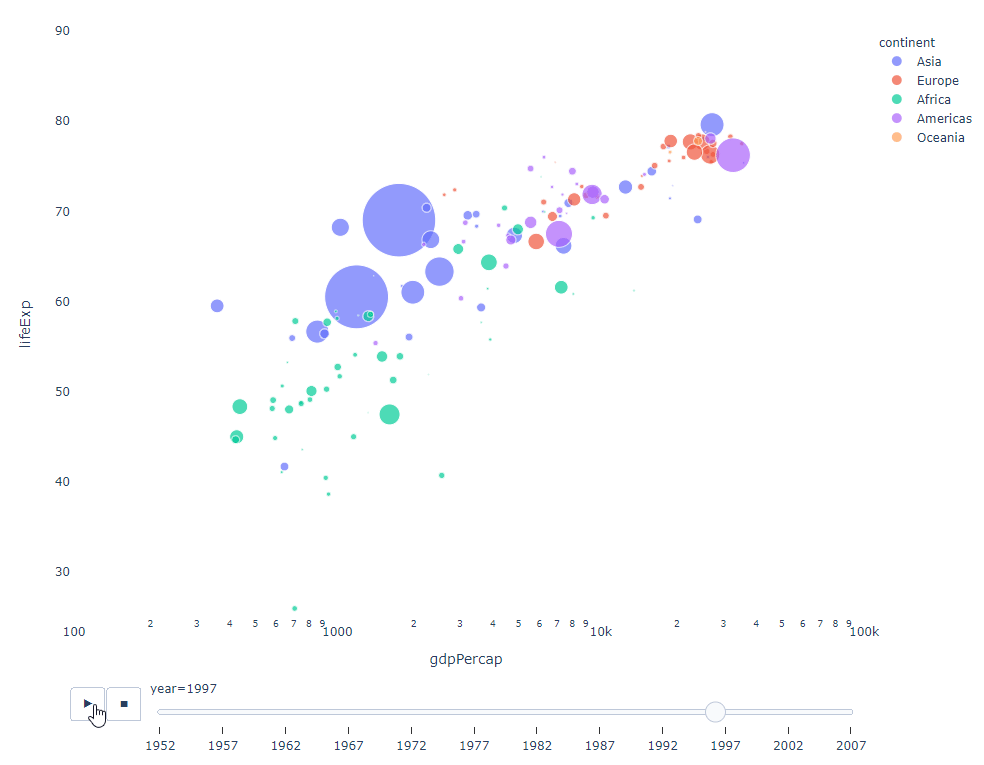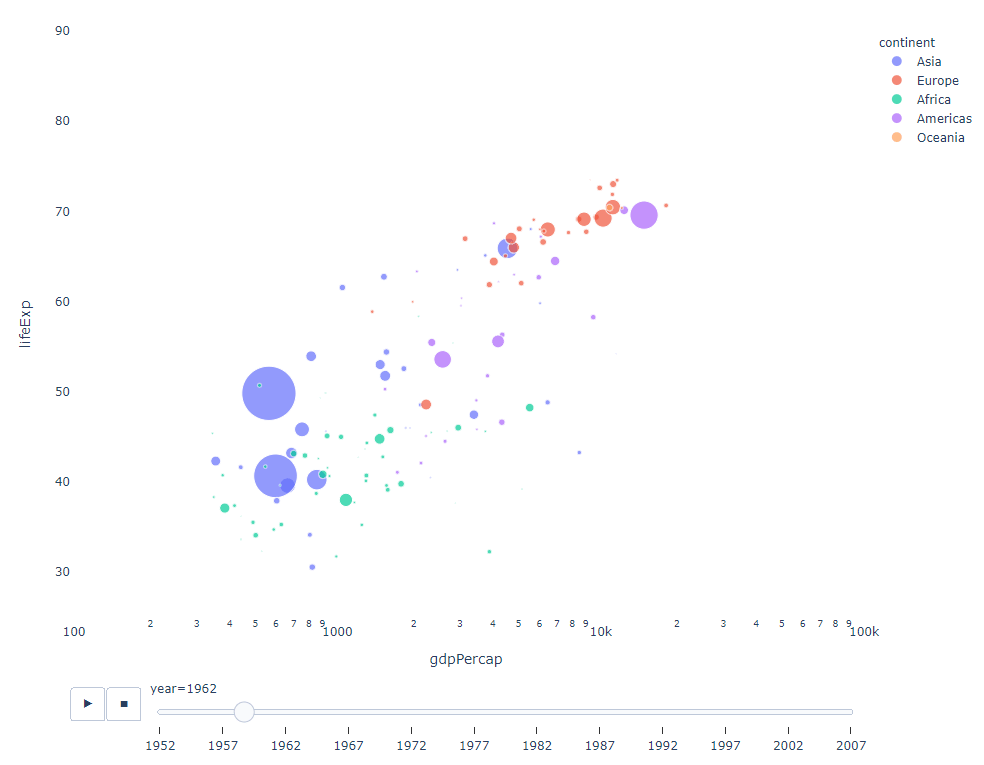
import plotly.express as px df = px.data.gapminder() fig = px.scatter( df, x="gdpPercap", y="lifeExp", animation_frame="year", size="pop", color="continent", hover_name="country", log_x=True, size_max=55, range_x=[100, 100000], range_y=[25, 90], # color_continuous_scale=px.colors.sequential.Emrld ) fig.update_layout(width=1000, height=800, xaxis_showgrid=False, yaxis_showgrid=False, paper_bgcolor='rgba(0,0,0,0)', plot_bgcolor='rgba(0,0,0,0)')
Graphique Sunburst
Un graphique Sunburst est un excellent moyen de visualiser un groupe par instruction. Si vous souhaitez décomposer une quantité donnée en une ou plusieurs variables catégorielles, utilisez une carte solaire.
Supposons que nous souhaitions ventiler les données de pourboire moyennes en fonction du sexe et de l'heure de la journée, alors cette double déclaration groupe par peut être affichée plus efficacement grâce à la visualisation qu'à un tableau.
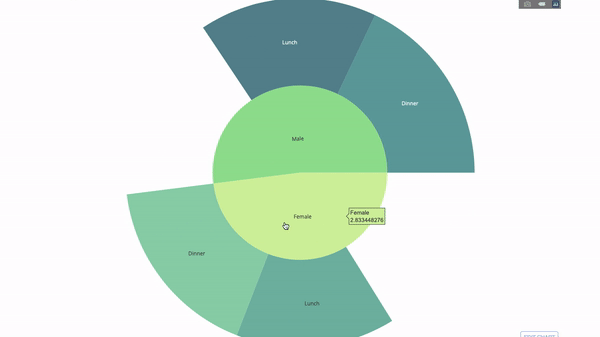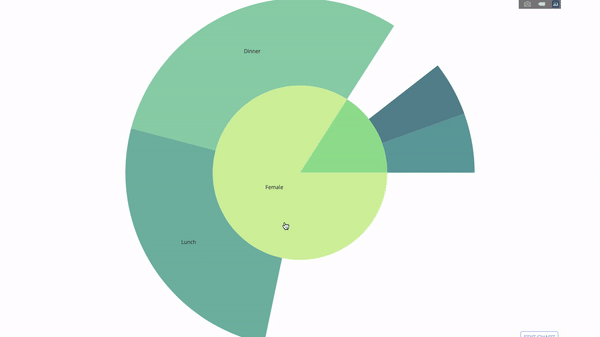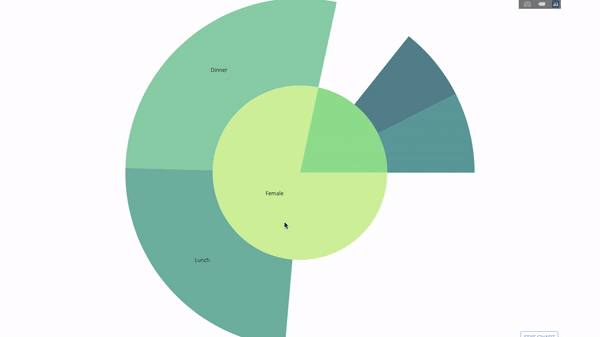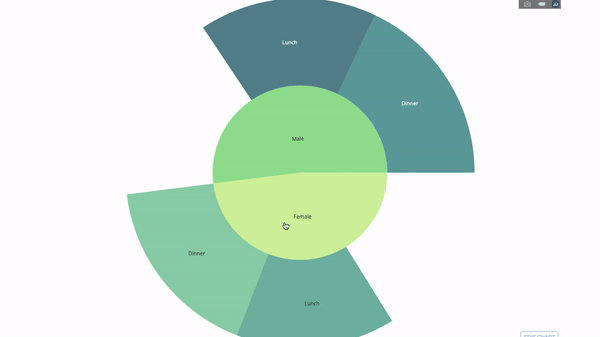
Ce graphique est interactif, vous permettant de cliquer et d'explorer les catégories par vous-même. Il vous suffit de définir toutes vos catégories, de déclarer la hiérarchie entre elles (voir le paramètre parents dans le code ci-dessous) et d'attribuer les valeurs correspondantes, ce qui dans notre cas est la sortie de l'instruction group by.
import plotly.graph_objects as go
import plotly.express as px
import numpy as np
import pandas as pd
df = px.data.tips()
fig = go.Figure(go.Sunburst(
labels=["Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch '],
parents=["", "", "Female", "Female", 'Male', 'Male'],
values=np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex', 'time']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
Maintenant, nous ajoutons une couche supplémentaire à cette hiérarchie :
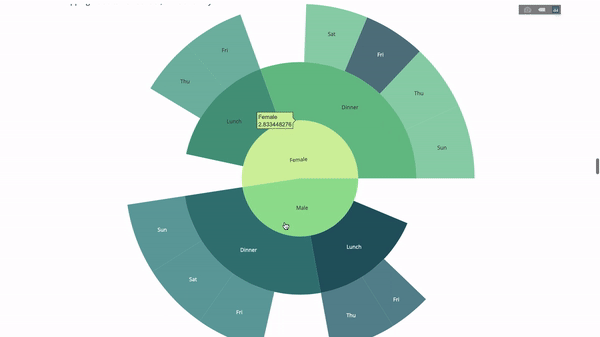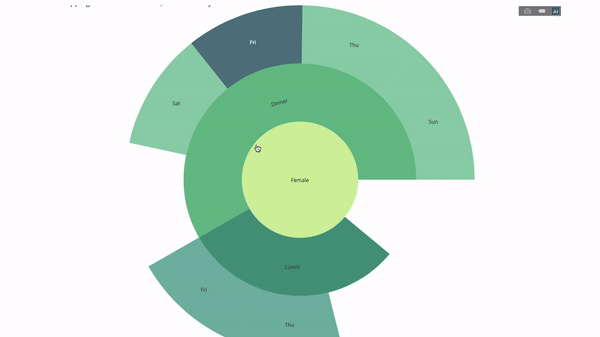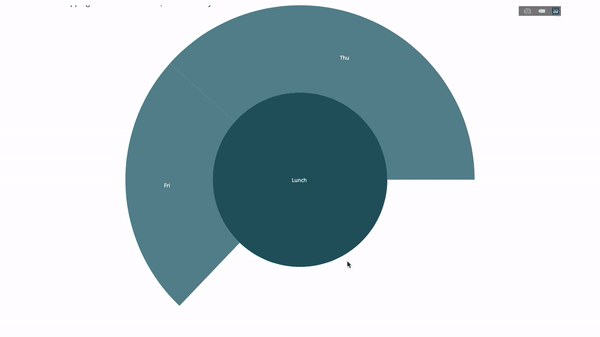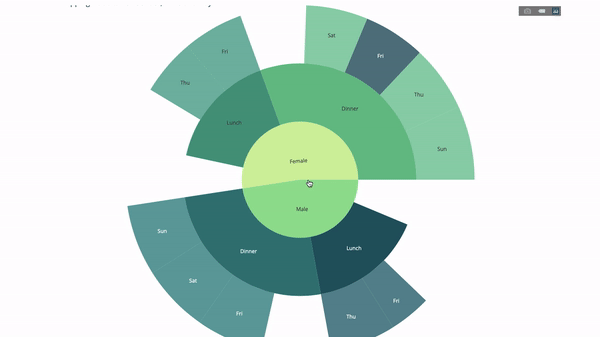
Pour ce faire, nous ajoutons les valeurs d'une autre instruction group by impliquant trois variables catégorielles.
import plotly.graph_objects as go
import plotly.express as px
import pandas as pd
import numpy as np
df = px.data.tips()
fig = go.Figure(go.Sunburst(labels=[
"Female", "Male", "Dinner", "Lunch", 'Dinner ', 'Lunch ', 'Fri', 'Sat',
'Sun', 'Thu', 'Fri ', 'Thu ', 'Fri', 'Sat', 'Sun', 'Fri ', 'Thu '
],
parents=[
"", "", "Female", "Female", 'Male', 'Male',
'Dinner', 'Dinner', 'Dinner', 'Dinner',
'Lunch', 'Lunch', 'Dinner ', 'Dinner ',
'Dinner ', 'Lunch ', 'Lunch '
],
values=np.append(
np.append(
df.groupby('sex').tip.mean().values,
df.groupby(['sex',
'time']).tip.mean().values,
),
df.groupby(['sex', 'time',
'day']).tip.mean().values),
marker=dict(colors=px.colors.sequential.Emrld)),
layout=go.Layout(paper_bgcolor='rgba(0,0,0,0)',
plot_bgcolor='rgba(0,0,0,0)'))
fig.update_layout(margin=dict(t=0, l=0, r=0, b=0),
title_text='Tipping Habbits Per Gender, Time and Day')
fig.show()
Graphiques à pointeurs
Les graphiques à pointeurs sont juste pour le look. Utilisez ce type de graphique pour rendre compte des indicateurs de réussite tels que les KPI et montrer à quel point ils sont proches de vos objectifs.
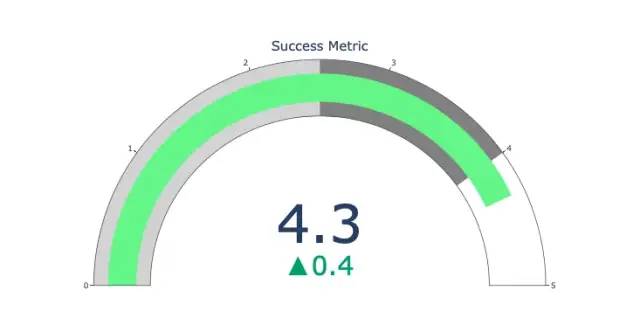
import plotly.graph_objects as go
fig = go.Figure(go.Indicator(
domain = {'x': [0, 1], 'y': [0, 1]},
value = 4.3,
mode = "gauge+number+delta",
title = {'text': "Success Metric"},
delta = {'reference': 3.9},
gauge = {'bar': {'color': "lightgreen"},
'axis': {'range': [None, 5]},
'steps' : [
{'range': [0, 2.5], 'color': "lightgray"},
{'range': [2.5, 4], 'color': "gray"}],
}))
fig.show()
Sankey Plot
Une autre façon d'explorer la relation entre les variables catégorielles est le tracé de coordonnées parallèles suivant. Vous pouvez faire glisser, déposer, mettre en surbrillance et parcourir les valeurs à tout moment, ce qui est parfait pour les présentations.
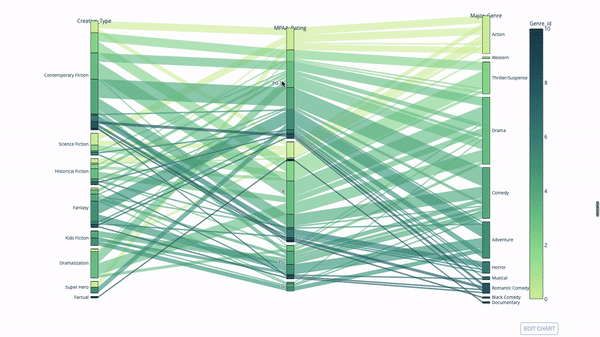
Le code est le suivant :
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_categories( df, dimensions=['MPAA_Rating', 'Creative_Type', 'Major_Genre'], color="Genre_id", color_continuous_scale=px.colors.sequential.Emrld, ) fig.show()
Tracé de coordonnées parallèles
Le tracé de coordonnées parallèles est un dérivé du graphique ci-dessus. Ici, chaque chaîne représente une seule observation. Il s'agit d'une méthode qui peut être utilisée pour identifier les valeurs aberrantes (lignes simples éloignées du reste des données), les clusters, les tendances et les variables redondantes (par exemple, si deux variables ont des valeurs similaires à chaque observation, elles se trouvera sur la même ligne horizontale, un outil utile pour indiquer la présence de redondance).
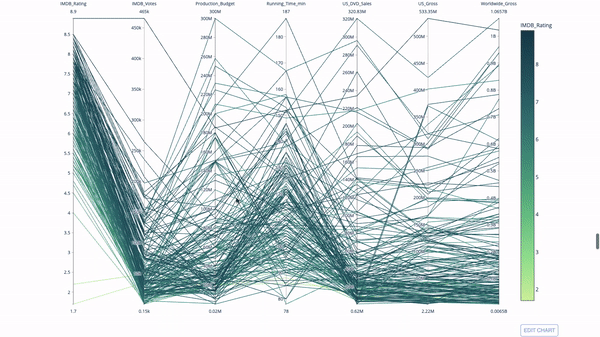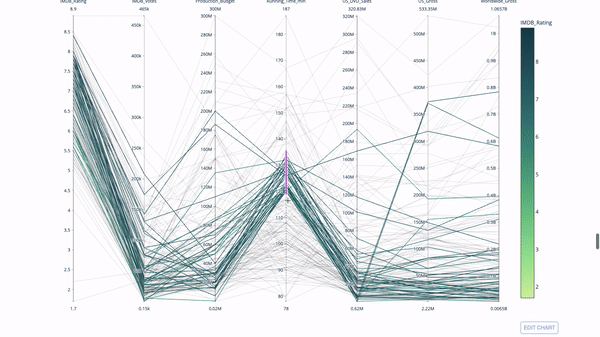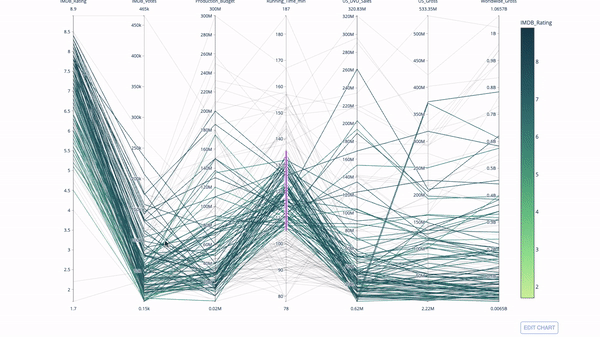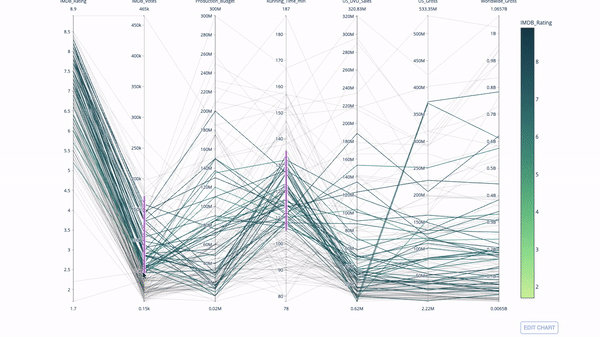
Le code est le suivant :
import plotly.express as px from vega_datasets import data import pandas as pd df = data.movies() df = df.dropna() df['Genre_id'] = df.Major_Genre.factorize()[0] fig = px.parallel_coordinates( df, dimensions=[ 'IMDB_Rating', 'IMDB_Votes', 'Production_Budget', 'Running_Time_min', 'US_Gross', 'Worldwide_Gross', 'US_DVD_Sales' ], color='IMDB_Rating', color_continuous_scale=px.colors.sequential.Emrld) fig.show()
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!