
Maison >Périphériques technologiques >IA >Comment affiner le LLM avec un seul GPU pour contourner les limitations de puissance de calcul ? Ceci est un tutoriel sur l'algorithme 'Gradient Accumulation'
Comment affiner le LLM avec un seul GPU pour contourner les limitations de puissance de calcul ? Ceci est un tutoriel sur l'algorithme 'Gradient Accumulation'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-22 20:25:041116parcourir
Depuis que les grands modèles sont devenus une tendance en vogue, les GPU sont devenus une denrée rare. Les réserves de nombreuses entreprises peuvent ne pas être suffisantes, encore moins celles des développeurs individuels. Existe-t-il un moyen d’utiliser la puissance de calcul pour entraîner des modèles plus efficacement ?
Dans un blog récent, Sebastian Raschka a présenté la méthode « d'accumulation de gradient », qui peut utiliser une taille de lot plus grande pour entraîner le modèle lorsque la mémoire GPU est limitée, en contournant les limitations matérielles.

Avant cela, Sebastian Raschka a également partagé un article qui utilise des stratégies d'entraînement multi-GPU pour accélérer le réglage fin de grands modèles de langage, y compris des mécanismes tels que le partage de modèle ou de tenseur, qui distribuent les poids des modèles. et des calculs sur différents appareils pour contourner les limitations de mémoire GPU.
Affiner le modèle BLOOM pour la classification
Supposons que nous souhaitions adopter un grand modèle de langage récemment pré-entraîné pour gérer les tâches en aval telles que la classification de texte. Ensuite, nous pourrions choisir d'utiliser le modèle BLOOM alternatif open source de GPT-3, en particulier la version BLOOM avec "seulement" 560 millions de paramètres - il devrait pouvoir s'insérer sans problème dans la RAM d'un GPU traditionnel (Google Colab est une version gratuite dispose d'un GPU avec 15 Go de RAM).
Une fois que vous commencerez, vous risquez de rencontrer des problèmes : la mémoire augmentera rapidement lors de l'entraînement ou de la mise au point. La seule façon d’entraîner ce modèle est avec une taille de lot de 1.

Le code permettant d'affiner BLOOM pour la tâche de classification cible en utilisant une taille de lot de 1 (taille du lot = 1) est le suivant. Vous pouvez également télécharger le code complet sur la page du projet GitHub :
https://github.com/rasbt/gradient-accumulation-blog/blob/main/src/1_batchsize-1.py
Vous pouvez utilisez ceci Le code est copié et collé directement dans Google Colab, mais le fichier local_dataset_utilities.py qui l'accompagne doit également être glissé et déposé dans le même dossier à partir duquel certains utilitaires d'ensemble de données ont été importés.
<code># pip install torch lightning matplotlib pandas torchmetrics watermark transformers datasets -Uimport osimport os.path as opimport timefrom datasets import load_datasetfrom lightning import Fabricimport torchfrom torch.utils.data import DataLoaderimport torchmetricsfrom transformers import AutoTokenizerfrom transformers import AutoModelForSequenceClassificationfrom watermark import watermarkfrom local_dataset_utilities import download_dataset, load_dataset_into_to_dataframe, partition_datasetfrom local_dataset_utilities import IMDBDatasetdef tokenize_text (batch):return tokenizer (batch ["text"], truncatinotallow=True, padding=True, max_length=1024)def train (num_epochs, model, optimizer, train_loader, val_loader, fabric):for epoch in range (num_epochs):train_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch_idx, batch in enumerate (train_loader):model.train ()### FORWARD AND BACK PROPoutputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"]) fabric.backward (outputs ["loss"])### UPDATE MODEL PARAMETERSoptimizer.step ()optimizer.zero_grad ()### LOGGINGif not batch_idx % 300:print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Batch {batch_idx:04d}/{len (train_loader):04d}"f"| Loss: {outputs ['loss']:.4f}")model.eval ()with torch.no_grad ():predicted_labels = torch.argmax (outputs ["logits"], 1)train_acc.update (predicted_labels, batch ["label"])### MORE LOGGINGmodel.eval ()with torch.no_grad ():val_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in val_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)val_acc.update (predicted_labels, batch ["label"])print (f"Epoch: {epoch+1:04d}/{num_epochs:04d}"f"| Train acc.: {train_acc.compute ()*100:.2f}%"f"| Val acc.: {val_acc.compute ()*100:.2f}%")train_acc.reset (), val_acc.reset ()if __name__ == "__main__":print (watermark (packages="torch,lightning,transformers", pythnotallow=True))print ("Torch CUDA available?", torch.cuda.is_available ())device = "cuda" if torch.cuda.is_available () else "cpu"torch.manual_seed (123)# torch.use_deterministic_algorithms (True)############################# 1 Loading the Dataset##########################download_dataset ()df = load_dataset_into_to_dataframe ()if not (op.exists ("train.csv") and op.exists ("val.csv") and op.exists ("test.csv")):partition_dataset (df)imdb_dataset = load_dataset ("csv",data_files={"train": "train.csv","validation": "val.csv","test": "test.csv",},)############################################ 2 Tokenization and Numericalization#########################################tokenizer = AutoTokenizer.from_pretrained ("bigscience/bloom-560m", max_length=1024)print ("Tokenizer input max length:", tokenizer.model_max_length, flush=True)print ("Tokenizer vocabulary size:", tokenizer.vocab_size, flush=True)print ("Tokenizing ...", flush=True)imdb_tokenized = imdb_dataset.map (tokenize_text, batched=True, batch_size=None)del imdb_datasetimdb_tokenized.set_format ("torch", columns=["input_ids", "attention_mask", "label"])os.environ ["TOKENIZERS_PARALLELISM"] = "false"############################################ 3 Set Up DataLoaders#########################################train_dataset = IMDBDataset (imdb_tokenized, partition_key="train")val_dataset = IMDBDataset (imdb_tokenized, partition_key="validation")test_dataset = IMDBDataset (imdb_tokenized, partition_key="test")train_loader = DataLoader (dataset=train_dataset,batch_size=1,shuffle=True,num_workers=4,drop_last=True,)val_loader = DataLoader (dataset=val_dataset,batch_size=1,num_workers=4,drop_last=True,)test_loader = DataLoader (dataset=test_dataset,batch_size=1,num_workers=2,drop_last=True,)############################################ 4 Initializing the Model#########################################fabric = Fabric (accelerator="cuda", devices=1, precisinotallow="16-mixed")fabric.launch ()model = AutoModelForSequenceClassification.from_pretrained ("bigscience/bloom-560m", num_labels=2)optimizer = torch.optim.Adam (model.parameters (), lr=5e-5)model, optimizer = fabric.setup (model, optimizer)train_loader, val_loader, test_loader = fabric.setup_dataloaders (train_loader, val_loader, test_loader)############################################ 5 Finetuning#########################################start = time.time ()train (num_epochs=1,model=model,optimizer=optimizer,train_loader=train_loader,val_loader=val_loader,fabric=fabric,)end = time.time ()elapsed = end-startprint (f"Time elapsed {elapsed/60:.2f} min")with torch.no_grad ():model.eval ()test_acc = torchmetrics.Accuracy (task="multiclass", num_classes=2).to (fabric.device)for batch in test_loader:outputs = model (batch ["input_ids"],attention_mask=batch ["attention_mask"],labels=batch ["label"])predicted_labels = torch.argmax (outputs ["logits"], 1)test_acc.update (predicted_labels, batch ["label"])print (f"Test accuracy {test_acc.compute ()*100:.2f}%")</code>
L'auteur a utilisé Lightning Fabric car il permet aux développeurs de modifier de manière flexible le nombre de GPU et les stratégies de formation multi-GPU lors de l'exécution de ce code sur différents matériels. Il permet également d'activer un entraînement de précision mixte en ajustant simplement le drapeau de précision. Dans ce cas, un entraînement de précision mixte peut multiplier par trois la vitesse d’entraînement et réduire les besoins en mémoire d’environ 25 %.
Le code principal présenté ci-dessus est exécuté dans la fonction principale (si le contexte __name__ == "__main__") Même si un seul GPU est utilisé, il est recommandé d'utiliser l'environnement d'exécution PyTorch pour effectuer une formation multi-GPU. . Ensuite, les trois parties de code suivantes contenues dans if __name__ == "__main__" sont responsables du chargement des données :
# 1 Charger l'ensemble de données
# 2 Tokenisation et numérisation
# 3 Configurer le data Loader
La section 4 est l'initialisation du modèle, puis dans la section 5 Finetuning, la fonction de train est appelée. C'est là que les choses commencent à devenir intéressantes. Dans la fonction train (...), une boucle PyTorch standard est implémentée. La version annotée de la boucle d'entraînement de base ressemble à ceci :
Le problème avec la taille du lot 1 (taille du lot = 1) est que la mise à jour du dégradé deviendra très déroutante et difficile, comme indiqué ci-dessous lors de l'entraînement du modèle basé sur le perte d'entraînement par fluctuation et ce que vous voyez dans les mauvaises performances des ensembles de tests :
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0969Epoch: 0001/0001 | Batch 24000/35000 | Loss: 1.9902Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0395Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.2546Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.1128Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.2661Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0044Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0468Epoch: 0001/0001 | Batch 26400/35000 | Loss: 1.7139Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.9570Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.1857Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0090Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.9790Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0503Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.2625Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.1010Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0009Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0234Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.8394Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.9497Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.1437Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.1317Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0073Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.7393Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0512Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.1337Epoch: 0001/0001 | Batch 32400/35000 | Loss: 1.1875Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.2727Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.1545Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0022Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.2681Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.2467Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0620Epoch: 0001/0001 | Batch 34500/35000 | Loss: 2.5039Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0131Epoch: 0001/0001 | Train acc.: 75.11% | Val acc.: 78.62%Time elapsed 69.97 minTest accuracy 78.53%</code>
Comme il n'y a pas beaucoup de GPU disponibles pour le partitionnement tensoriel, que peut-on faire pour entraîner des modèles avec des lots de plus grande taille ?
Une solution est l'accumulation de gradient, qui peut être utilisée pour modifier la boucle d'entraînement mentionnée précédemment.
什么是梯度积累?
梯度累积是一种在训练期间虚拟增加批大小(batch size)的方法,当可用的 GPU 内存不足以容纳所需的批大小时,这非常有用。在梯度累积中,梯度是针对较小的批次计算的,并在多次迭代中累积(通常是求和或平均),而不是在每一批次之后更新模型权重。一旦累积梯度达到目标「虚拟」批大小,模型权重就会使用累积梯度进行更新。
参考下面更新的 PyTorch 训练循环:
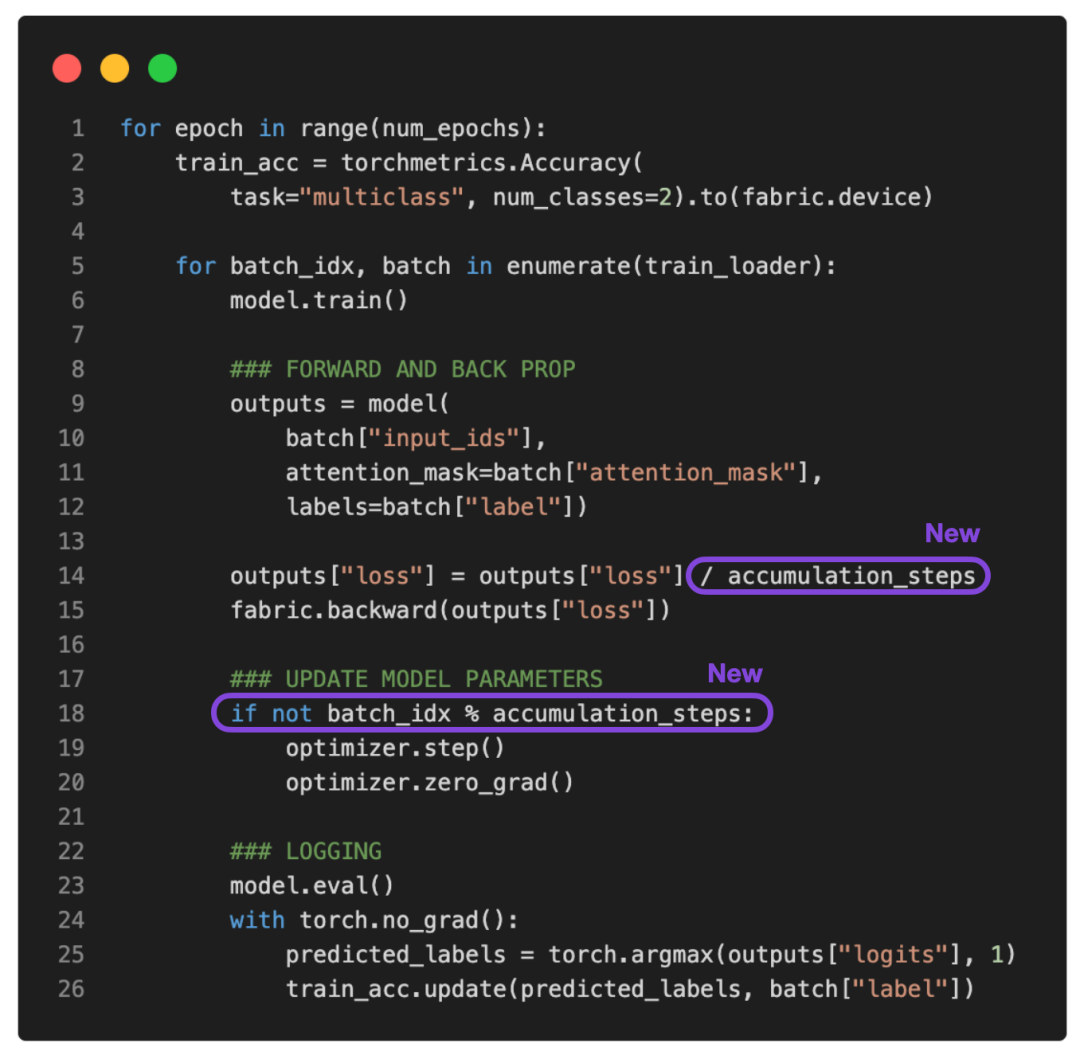
如果将 accumulation_steps 设置为 2,那么 zero_grad () 和 optimizer.step () 将只会每隔一秒调用一次。因此,使用 accumulation_steps=2 运行修改后的训练循环与将批大小(batch size)加倍具有相同的效果。
例如,如果想使用 256 的批大小,但只能将 64 的批大小放入 GPU 内存中,就可以对大小为 64 的四个批执行梯度累积。(处理完所有四个批次后,将获得相当于单个批大小为 256 的累积梯度。)这样能够有效地模拟更大的批大小,而无需更大的 GPU 内存或跨不同设备的张量分片。
虽然梯度累积可以帮助我们训练具有更大批量大小的模型,但它不会减少所需的总计算量。实际上,它有时会导致训练过程略慢一些,因为权重更新的执行频率较低。尽管如此,它却能帮我们解决限制问题,即批大小非常小时导致的更新频繁且混乱。
例如,现在让我们运行上面的代码,批大小为 1,需要 16 个累积步骤(accumulation steps)来模拟批大小等于 16。
输出如下:
<code>...torch : 2.0.0lightning : 2.0.0transformers: 4.27.2Torch CUDA available? True...Epoch: 0001/0001 | Batch 23700/35000 | Loss: 0.0168Epoch: 0001/0001 | Batch 24000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 24300/35000 | Loss: 0.0152Epoch: 0001/0001 | Batch 24600/35000 | Loss: 0.0003Epoch: 0001/0001 | Batch 24900/35000 | Loss: 0.0623Epoch: 0001/0001 | Batch 25200/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 25500/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 25800/35000 | Loss: 0.0047Epoch: 0001/0001 | Batch 26100/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 26400/35000 | Loss: 0.1016Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0021Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0060Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0001Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0426Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0025Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0000Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0495Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0164Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0067Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0037Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0013Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0112Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0053Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0012Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1365Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0210Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0374Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0341Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.0259Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0005Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4792Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0003Epoch: 0001/0001 | Train acc.: 78.67% | Val acc.: 87.28%Time elapsed 51.37 minTest accuracy 87.37%</code>
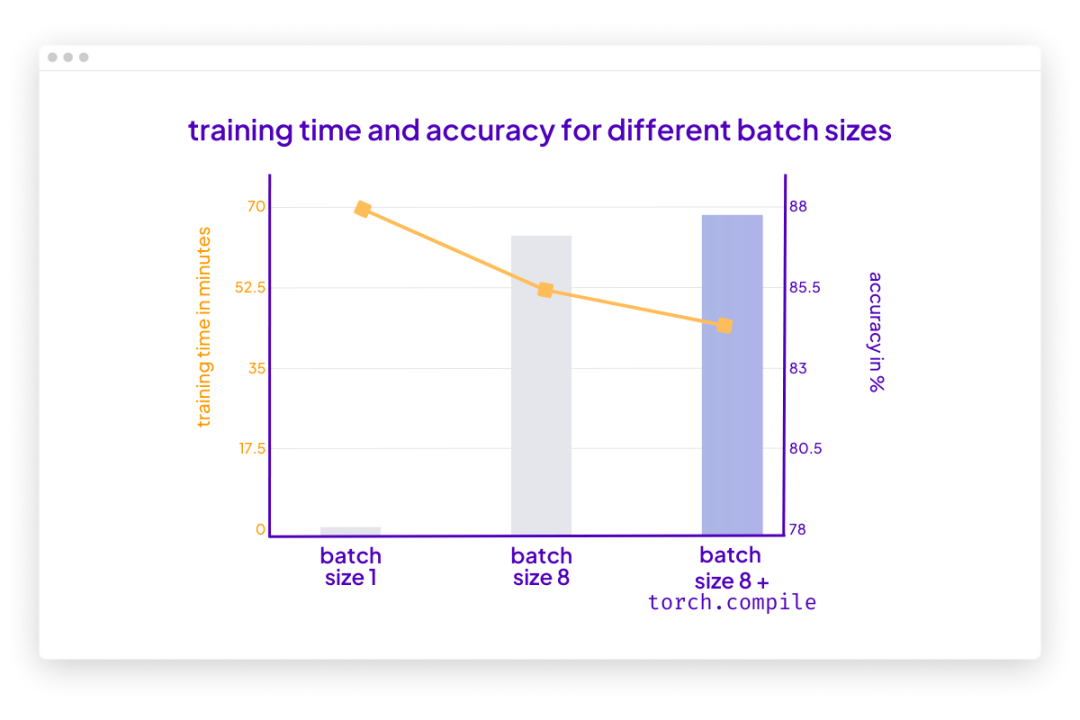
根据上面的结果,损失的波动比以前小了。此外,测试集性能提升了 10%。由于只迭代了训练集一次,因此每个训练样本只会遇到一次。训练用于 multiple epochs 的模型可以进一步提高预测性能。
你可能还会注意到,这段代码的执行速度也比之前使用的批大小为 1 的代码快。如果使用梯度累积将虚拟批大小增加到 8,仍然会有相同数量的前向传播(forward passes)。然而,由于每八个 epoch 只更新一次模型,因此反向传播(backward passes)会很少,这样可更快地在一个 epoch(训练轮数)内迭代样本。
结论
梯度累积是一种在执行权重更新之前通过累积多个小的批梯度来模拟更大的批大小的技术。该技术在可用内存有限且内存中可容纳批大小较小的情况下提供帮助。
但是,首先请思考一种你可以运行批大小的场景,这意味着可用内存大到足以容纳所需的批大小。在那种情况下,梯度累积可能不是必需的。事实上,运行更大的批大小可能更有效,因为它允许更多的并行性且能减少训练模型所需的权重更新次数。
总之,梯度累积是一种实用的技术,可以用于降低小批大小干扰信息对梯度更新准确性的影响。这是迄今一种简单而有效的技术,可以让我们绕过硬件的限制。
PS:可以让这个运行得更快吗?
没问题。可以使用 PyTorch 2.0 中引入的 torch.compile 使其运行得更快。只需要添加一些 model = torch.compile,如下图所示:
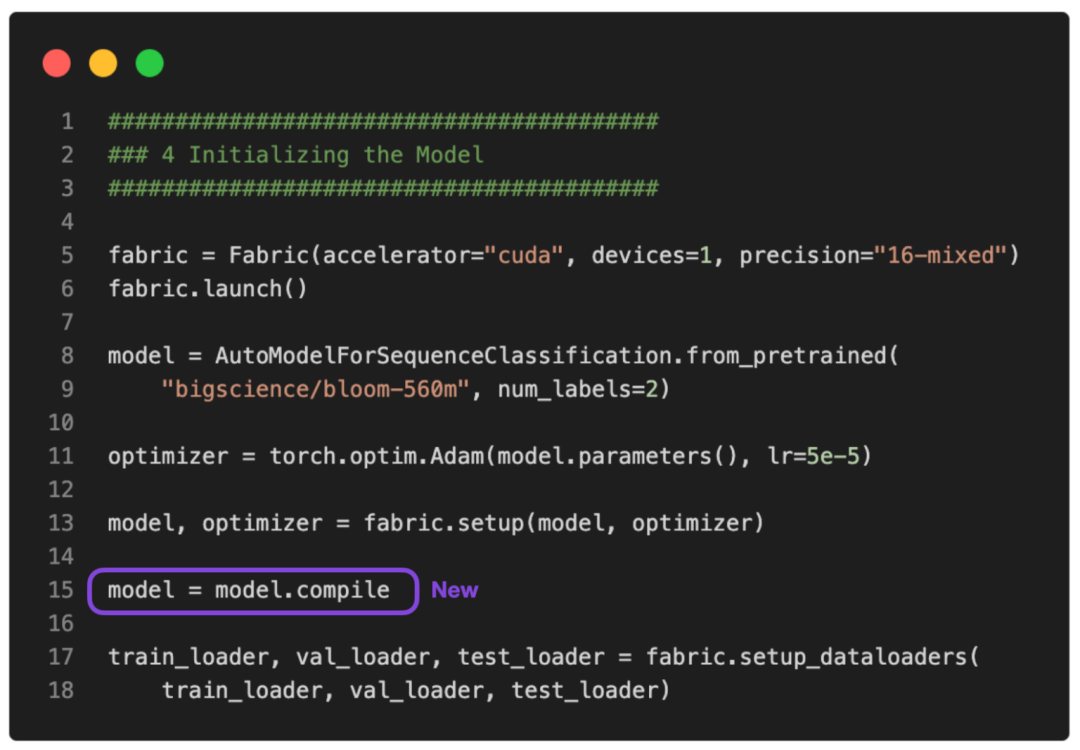
GitHub 上提供了完整的脚本。
在这种情况下,torch.compile 在不影响建模性能的情况下又减少了十分钟的训练时间:
<code>poch: 0001/0001 | Batch 26400/35000 | Loss: 0.0320Epoch: 0001/0001 | Batch 26700/35000 | Loss: 0.0010Epoch: 0001/0001 | Batch 27000/35000 | Loss: 0.0006Epoch: 0001/0001 | Batch 27300/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 27600/35000 | Loss: 0.0157Epoch: 0001/0001 | Batch 27900/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 28200/35000 | Loss: 0.0540Epoch: 0001/0001 | Batch 28500/35000 | Loss: 0.0035Epoch: 0001/0001 | Batch 28800/35000 | Loss: 0.0016Epoch: 0001/0001 | Batch 29100/35000 | Loss: 0.0015Epoch: 0001/0001 | Batch 29400/35000 | Loss: 0.0008Epoch: 0001/0001 | Batch 29700/35000 | Loss: 0.0877Epoch: 0001/0001 | Batch 30000/35000 | Loss: 0.0232Epoch: 0001/0001 | Batch 30300/35000 | Loss: 0.0014Epoch: 0001/0001 | Batch 30600/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 30900/35000 | Loss: 0.0004Epoch: 0001/0001 | Batch 31200/35000 | Loss: 0.0062Epoch: 0001/0001 | Batch 31500/35000 | Loss: 0.0032Epoch: 0001/0001 | Batch 31800/35000 | Loss: 0.0066Epoch: 0001/0001 | Batch 32100/35000 | Loss: 0.0017Epoch: 0001/0001 | Batch 32400/35000 | Loss: 0.1485Epoch: 0001/0001 | Batch 32700/35000 | Loss: 0.0324Epoch: 0001/0001 | Batch 33000/35000 | Loss: 0.0155Epoch: 0001/0001 | Batch 33300/35000 | Loss: 0.0007Epoch: 0001/0001 | Batch 33600/35000 | Loss: 0.0049Epoch: 0001/0001 | Batch 33900/35000 | Loss: 0.1170Epoch: 0001/0001 | Batch 34200/35000 | Loss: 0.0002Epoch: 0001/0001 | Batch 34500/35000 | Loss: 0.4201Epoch: 0001/0001 | Batch 34800/35000 | Loss: 0.0018Epoch: 0001/0001 | Train acc.: 78.39% | Val acc.: 86.84%Time elapsed 43.33 minTest accuracy 87.91%</code>
请注意,与之前相比准确率略有提高很可能是由于随机性。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI