
Maison >Périphériques technologiques >IA >Convertir des séries chronologiques en problème de classification
Convertir des séries chronologiques en problème de classification

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-18 22:12:201329parcourir
Cet article utilisera le trading d'actions comme exemple. Nous utilisons des modèles d’IA pour prédire si une action augmentera ou diminuera le lendemain. Dans ce contexte, trois algorithmes de classification, XGBoost, Random Forest et Logistic Classifier, sont comparés. Un autre objectif de l'article est la préparation des données. Comment devons-nous transformer les données pour que le modèle puisse les traiter.

Cet article suivra les étapes du modèle de processus CRISP-DM et utilisera une approche structurée pour résoudre l'analyse de rentabilisation. CRISP-DM est une méthode largement utilisée dans l'analyse latente et est souvent utilisée dans la construction de projets de science des données.
L'autre chose est que nous utiliserons le package Python openbb. Ce package comprend certaines sources de données du secteur financier et est très simple à utiliser.
La première étape consiste à installer les bibliothèques nécessaires :
<code>pip install pandas numpy “openbb[all]” swifter scikit-learn</code>
Compréhension commerciale
Nous devons d'abord comprendre le problème que nous voulons résoudre. Dans notre exemple, le problème peut être défini comme suit :
<code>预测股票代码 AAPL 的股价第二天会上涨还是下跌。</code>
Ensuite, nous devons considérer quoi. type de machine que nous avons sous la main Le problème de l'apprentissage des modèles. Nous voulons prédire si le titre augmentera ou diminuera le lendemain. Nous avons donc affaire ici à un problème de classification binaire dans lequel nous voulons prédire si un titre va augmenter (avec une valeur de 1) ou baisser (avec une valeur de 0) le lendemain. Dans un problème de classification, nous prédisons une classe. Dans notre cas, il s’agit d’une classification binaire des classes 0 et 1.
Compréhension et préparation des données
La phase de compréhension des données se concentre sur l'identification, la collecte et l'analyse d'ensembles de données. Dans un premier temps, nous téléchargeons les données boursières Apple. Voici comment procéder en utilisant openbb :
<code>data = openbb.stocks.load(symbol = 'AAPL',start_date = '2023-01-01',end_date = '2023-04-01',monthly = False) data</code>
Ce code télécharge des données entre le 01/01/2023 et le 01/04/2023. Les données téléchargées contiennent les informations suivantes :
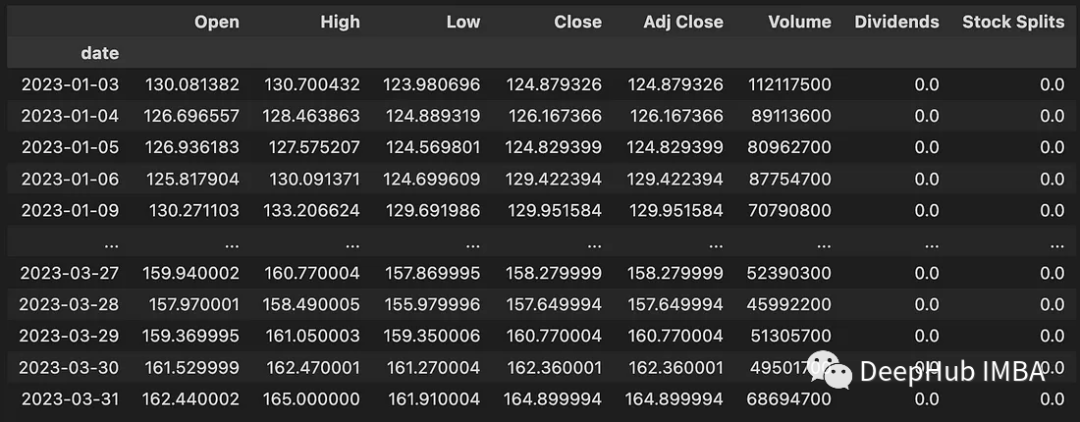
- Ouvert : prix d'ouverture quotidien en USD
- Haut : prix le plus élevé du jour (USD)
- Bas : prix le plus bas du jour (USD)
- Fermeture : quotidien cours de clôture de l'USD
- Adj Close : cours de clôture ajusté lié aux dividendes ou aux fractionnements d'actions
- Volume : nombre d'actions négociées
- Dividendes : dividendes payés
- Splits d'actions : exécutions de fractionnements d'actions
Nous avons téléchargé les données, mais les données ne sont pas encore disponibles. Ne convient pas à la modélisation de modèles de classification. Les données doivent donc encore être préparées pour la modélisation. Il est donc nécessaire de développer une fonction permettant de télécharger les données puis de convertir les données pour la modélisation. Le code suivant montre cette fonctionnalité :
<code>def get_training_data(symbol, start_date, end_date, monthly_bool=True, lookback=10): data = openbb.stocks.load( symbol = symbol, start_date = start_date, end_date = end_date, monthly = monthly_bool) data = get_label(data) data_up_down = data['up_down'].to_numpy() training_data = get_sequence_data(data_up_down, lookback) return training_data</code>
La première fonction incluse ici est get_label() :
<code>def encoding(n): if n > 0: return 1 else: return 0 def get_label(data): data['Delta'] = data['Close'] - data['Open'] data['up_down'] = data['Delta'].swifter.apply(lambda d: encoding(d)) return data</code>
Son travail principal est de calculer la différence entre le cours de clôture et le cours d'ouverture. Nous marquons tous les jours où le cours de l’action a augmenté à 1 et tous les jours où le cours de l’action a baissé à 0. La colonne supplémentaire up_down indique si le cours de l'action a augmenté ou diminué à une date spécifique. La fonction Swifter.apply() est utilisée ici à la place de pandas apply() car Swifter fournit une prise en charge multicœur.
La deuxième fonction est get_sequence_data(). Le paramètre lookback spécifie combien de jours dans le passé sont inclus dans la prévision. Le code get_sequence_data() est le suivant :
<code>def get_sequence_data(data_up_down, lookback): shape = (data_up_down.shape[0] - lookback + 1, lookback) strides = data_up_down.strides + (data_up_down.strides[-1],) return np.lib.stride_tricks.as_strided(data_up_down, shape=shape, strides=strides)</code>
Cette fonction accepte deux paramètres : data_up_down et lookback. Il renvoie un nouveau tableau NumPy représentant une vue par fenêtre glissante du tableau data_up_down avec la taille de fenêtre spécifiée, déterminée par l'argument lookback. Pour illustrer le fonctionnement de cette fonction, regardons un petit exemple.
<code>get_sequence_data(np.array([1, 2, 3, 4, 5, 6]), 3)</code>
Les résultats sont les suivants :
<code>array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])</code>
Ci-dessous, nous téléchargeons les données du stock Apple et les transformons pour la modélisation. Nous utilisons une fenêtre rétrospective de 10 jours.
<code>data = get_training_data(symbol = 'AAPL', start_date = '2023-01-01', end_date = '2023-04-01', monthly_bool = False, lookback=10) pd.DataFrame(data).to_csv("data/data_aapl.csv")</code>
Les données sont prêtes, commençons à modéliser et évaluer le modèle.
Modélisation
Lisez les données et générez des données de test et de formation.
<code>data = pandas.read_csv("./data/data_aapl.csv") X=data.iloc[:,:-1] Y=data.iloc[:,-1] X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=4284, stratify=Y)</code>
Régression logistique :
Ce classificateur est un modèle linéaire et est souvent utilisé comme modèle de base. Nous utilisons l'implémentation de scikit-learn :
<code>model_lr = LogisticRegression(random_state = 42) model_lr.fit(X_train,y_train) y_pred = model_lr.predict(X_test)</code>
XGBoost :
XGBoost est une implémentation d'arbres de décision améliorés par gradient conçus pour la vitesse et les performances. Il appartient à l'algorithme de renforcement des arbres, qui connecte en séquence de nombreux classificateurs d'arbres faibles.
<code>model_xgb = XGBClassifier(random_state = 42) model_xgb.fit(X_train, y_train) y_pred = model_xgb.predict(X_test)</code>
Forêt aléatoire :
La forêt aléatoire construit plusieurs arbres de décision. La méthode Bagging est appelée un type d’apprentissage d’ensemble car elle utilise plusieurs apprenants interconnectés pour l’apprentissage. L'acronyme « bagging » signifie agrégation bootstrap. L'implémentation de scikit-learn est également utilisée ici :
<code>model_rf = RandomForestClassifier(random_state = 42) model_rf.fit(X_train, y_train) y_pred = model_rf.predict(X_test)</code>
Évaluation
Après la modélisation et l'entraînement du modèle, nous devons évaluer ses performances sur les données de test. Le rappel, la précision et le F1-Score sont utilisés pour mesurer les métriques. Le tableau ci-dessous montre les résultats.
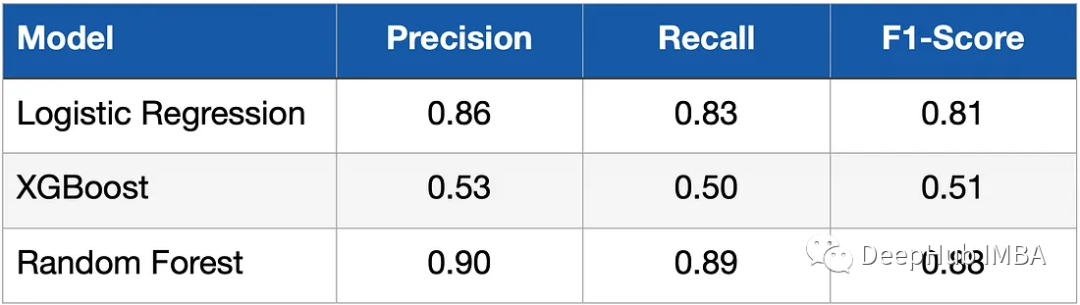
Vous pouvez voir que le classificateur logistique (régression logistique) et la forêt aléatoire ont obtenu des résultats nettement meilleurs que le modèle XGBoost. Quelle en est la raison ? En effet, les données sont relativement simples, avec seulement quelques dimensions d'entités, et la longueur des données est également très petite, et tous nos modèles n'ont pas été réglés.
Résumé
L'objectif principal de notre article est de présenter comment convertir la série chronologique des cours boursiers en un problème de classification, et de démontrer comment utiliser la fonction fenêtre pendant le traitement des données pour convertir la série temporelle dans une séquence, comme pour le modèle, il n'y a pas beaucoup de réglage, donc pour l'évaluation des effets, plus le modèle est simple, meilleures sont ses performances.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI