
Maison >Périphériques technologiques >IA >Scandaleux! Dernière recherche : 61 % des articles en anglais rédigés par des Chinois seront jugés comme générés par l'IA par le détecteur ChatGPT
Scandaleux! Dernière recherche : 61 % des articles en anglais rédigés par des Chinois seront jugés comme générés par l'IA par le détecteur ChatGPT

- 王林avant
- 2023-05-18 11:13:061104parcourir
Après que ChatGPT soit devenu populaire, il existe de nombreuses façons de l'utiliser.
Certaines personnes l'utilisent pour demander des conseils de vie, d'autres l'utilisent simplement comme moteur de recherche et certaines personnes l'utilisent pour rédiger des articles.
Thèse... ce n'est pas amusant à écrire.
Certaines universités aux États-Unis ont interdit aux étudiants d'utiliser ChatGPT pour rédiger leurs devoirs, et ont également développé un certain nombre de logiciels pour identifier et déterminer si les documents soumis par les étudiants sont générés par GPT.
Il y a un problème ici.
L'article de quelqu'un était à l'origine mal rédigé, mais l'IA qui a jugé le texte pensait qu'il avait été rédigé par un pair.
De plus, la probabilité que les articles en anglais rédigés par des Chinois soient jugés comme étant générés par l'IA atteint 61 %.

C'est... qu'est-ce que ça veut dire ? Frissons !
Les locuteurs non natifs n'en valent pas la peine ?
Actuellement, les modèles de langage génératifs se développent rapidement et ont en effet apporté de grands progrès à la communication numérique.
Mais il y a vraiment beaucoup d'abus.
Bien que les chercheurs aient proposé de nombreuses méthodes de détection pour distinguer le contenu généré par l'IA et le contenu généré par l'homme, l'équité et la stabilité de ces méthodes de détection doivent encore être améliorées.
À cette fin, les chercheurs ont évalué les performances de plusieurs détecteurs GPT largement utilisés à l'aide de travaux rédigés par des auteurs anglophones natifs et non natifs.
Les résultats de recherche montrent que ces détecteurs déterminent toujours de manière incorrecte les échantillons écrits par des locuteurs non natifs tels que générés par l'IA, alors que les échantillons écrits par des locuteurs natifs peuvent en principe être identifiés avec précision.
De plus, les chercheurs ont démontré que ce biais peut être atténué avec quelques stratégies simples et contourner efficacement les détecteurs GPT.
Qu'est-ce que cela signifie ? Cela montre que le détecteur GPT méprise les auteurs dont les compétences linguistiques ne sont pas très bonnes, ce qui est très ennuyeux.
Je ne peux m'empêcher de penser à ce jeu pour juger si l'IA est une personne réelle. Si l'adversaire est une personne réelle mais que vous devinez qu'il s'agit d'une IA, le système dira : « L'autre partie peut vous trouver offensant. ."
Pas assez complexe = génération IA ?
Les chercheurs ont obtenu 91 essais TOEFL provenant d'un forum sur l'éducation chinois et 88 essais rédigés par des élèves américains de huitième année à partir de l'ensemble de données de la Fondation Hewlett pour détecter 7 détecteurs GPT largement utilisés.
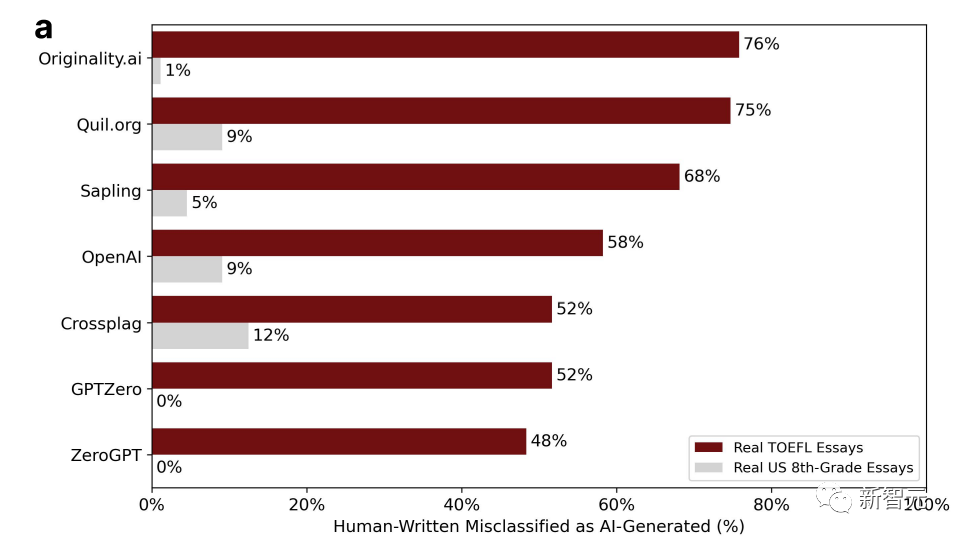
Le pourcentage dans le tableau représente la proportion d'"erreurs de jugement". Autrement dit, il a été écrit par un humain, mais le logiciel de détection pense qu'il a été généré par l'IA.
Vous pouvez constater que les données sont très disparates.
Parmi les sept détecteurs, la probabilité la plus élevée d'être mal jugé pour les essais rédigés par des élèves américains de huitième année n'est que de 12 %, et il existe deux GPT sans erreur de jugement.
Fondamentalement, plus de la moitié des essais du TOEFL sur les forums chinois sont mal jugés, et la probabilité la plus élevée d'erreur de jugement peut atteindre 76 %.
18 des 91 essais du TOEFL ont été jugés à l'unanimité comme étant générés par l'IA par les 7 détecteurs GPT, tandis que 89 des 91 essais ont été mal jugés par au moins un détecteur GPT.
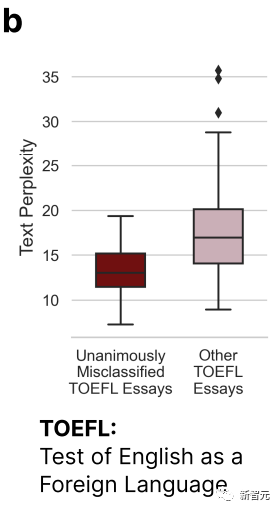
D'après l'image ci-dessus, nous pouvons voir que l'essai du TOEFL qui a été mal jugé par les 7 GPT est nettement moins complexe que les autres essais.
Cela confirme la conclusion du début : le détecteur GPT aura un certain biais contre les auteurs ayant une capacité d'expression linguistique limitée.
Par conséquent, les chercheurs pensent que le détecteur GPT devrait lire davantage d'articles écrits par des locuteurs non natifs. Ce n'est qu'avec plus d'échantillons que les biais pourront être éliminés.
Ensuite, les chercheurs ont jeté des essais TOEFL rédigés par des locuteurs non natifs dans ChatGPT pour enrichir la langue et imiter les habitudes d'utilisation des mots des locuteurs natifs.
Dans le même temps, en tant que groupe témoin, des compositions écrites par des enfants américains de huitième année ont également été lancées dans ChatGPT, et le langage a été simplifié pour imiter les caractéristiques d'écriture de locuteurs non natifs. L'image ci-dessous est le nouveau résultat du jugement après correction.
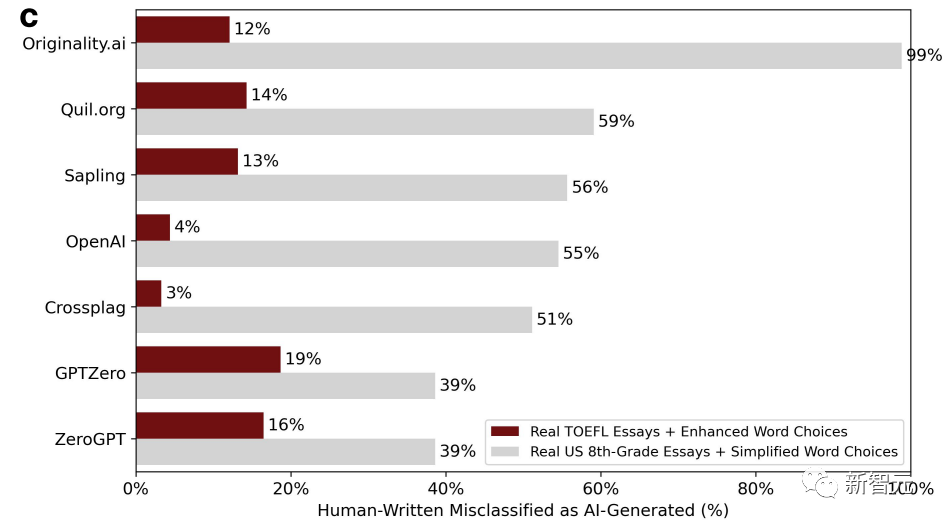
Nous pouvons constater que la situation a radicalement changé. Le taux d'erreurs d'évaluation des essais du TOEFL qui enrichissent la langue a chuté, jusqu'à 3 % et jusqu'à 19 %. Contrairement au taux de faux positifs précédent, qui était essentiellement supérieur à la moitié.
Au contraire, le taux d'erreur des essais rédigés par des enfants de huitième année est monté en flèche. Il existe même un détecteur GPT avec un taux d'erreur pouvant atteindre 99 %, ce qui correspond essentiellement à toutes les erreurs.
Parce que la variable de complexité des articles a changé.
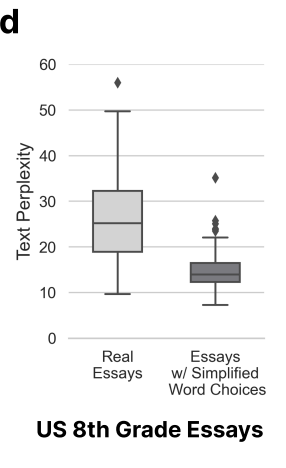
Ici, les chercheurs sont arrivés à la conclusion que les choses écrites par des locuteurs non natifs ne sont pas authentiques, sont peu complexes et sont facilement mal jugées.
Cela entraîne également un problème technique, mais aussi un problème de valeur. Utiliser la complexité pour déterminer si l’IA ou les humains en sont les auteurs est raisonnable, complet et rigoureux.
Le résultat ne l'est évidemment pas.
À en juger par la complexité, les locuteurs non natifs subissent une grande perte car ce sont des locuteurs non natifs (absurdité).
AI polonais = écrit par des humains ? ?
Les chercheurs pensent que l'amélioration de la diversité linguistique peut non seulement atténuer les préjugés à l'égard des locuteurs non natifs, mais également permettre au contenu généré par GPT de contourner les détecteurs GPT.
Pour prouver ce point, les chercheurs ont sélectionné des sujets de dissertation d'admission pour les candidatures universitaires américaines de 2022 à 2023, les ont saisis dans ChatGPT-3.5 et ont généré un total de 31 faux essais.
Le détecteur GPT était assez efficace au début, mais pas au second tour. En effet, lors du deuxième tour, les chercheurs ont jeté ces articles dans ChatGPT et les ont peaufinés, en utilisant un langage littéraire pour améliorer la qualité du texte.
De cette façon, la précision du détecteur GPT est passée de 100 % à 0 %. Comme indiqué ci-dessous :
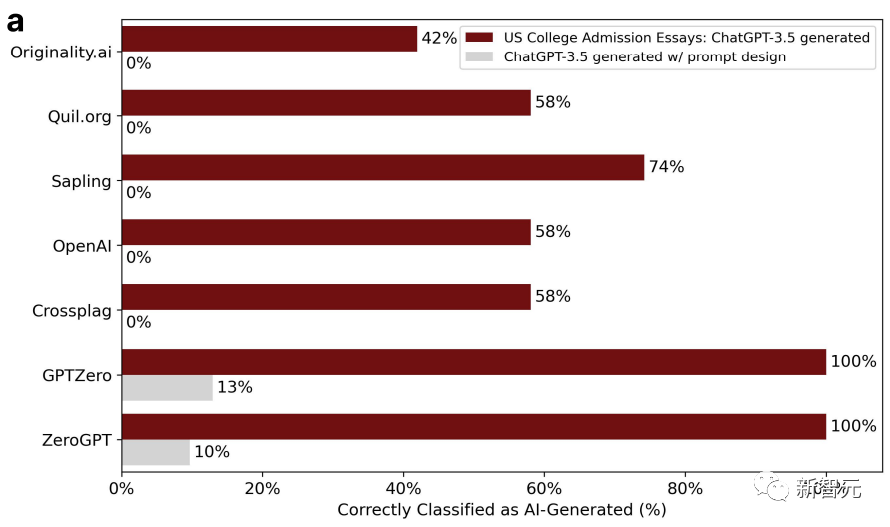
La complexité de l'article poli a également augmenté en conséquence.
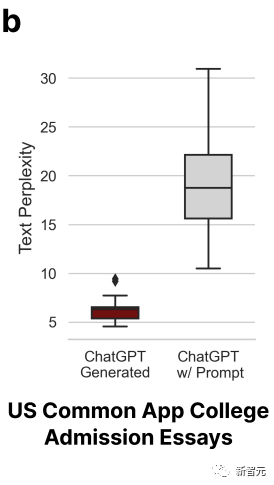
Dans le même temps, les chercheurs ont utilisé 145 sujets de rapports de projet finaux de l'Université de Stanford pour permettre à ChatGPT de générer des résumés.
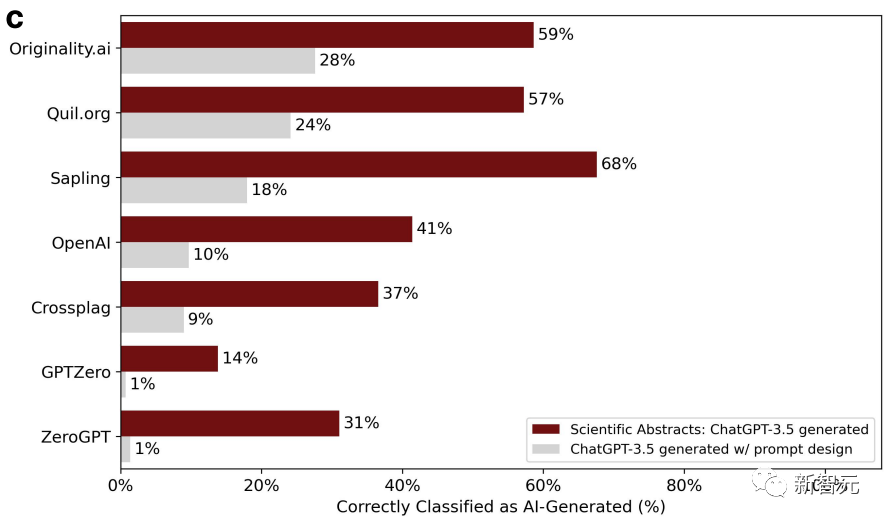
Résumé Après le polissage, la précision du jugement du détecteur continue de décliner.
Les chercheurs ont une fois de plus conclu que les articles raffinés sont facilement mal jugés et sont générés par l'IA. Deux tours valent mieux qu'un.
Détecteur GPT ? Encore un manque de pratique
En bref, dans l'ensemble, les différents détecteurs GPT semblent toujours incapables de saisir la différence la plus essentielle entre la génération d'IA et l'écriture humaine.
L'écriture populaire est également divisée en trois, six ou neuf niveaux. Il est déraisonnable de juger uniquement par la complexité.
Mis à part les facteurs de biais, la technologie elle-même doit également être améliorée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI