

 Périphériques technologiquesIADieu restaure les objets complexes et les détails haute fréquence, la synthèse de vue haute fidélité 4K-NeRF est là
Périphériques technologiquesIADieu restaure les objets complexes et les détails haute fréquence, la synthèse de vue haute fidélité 4K-NeRF est là
L'ultra haute résolution est saluée par de nombreux chercheurs comme une norme pour l'enregistrement et l'affichage d'images et de vidéos de haute qualité. Par rapport aux résolutions inférieures (format HD 1K), les scènes capturées à haute résolution ont généralement des détails très clairs. amplifié par de petites taches. Cependant, l’application de cette technologie au traitement d’images et à la vision par ordinateur pose encore de nombreux défis.
Dans cet article, des chercheurs d'Alibaba se concentrent sur de nouvelles tâches de synthèse de vues et proposent un cadre appelé 4K-NeRF. Sa méthode de rendu de volume basée sur NeRF peut atteindre une haute fidélité avec une composition de vues 4K ultra-haute.

Adresse papier : https://arxiv.org/abs/2212.04701
Page d'accueil du projet : https://github.com/frozoul/4K-NeRF
Sans plus loin, jetons un coup d'œil à l'effet d'abord (les vidéos suivantes ont été sous-échantillonnées, veuillez vous référer au projet original pour la vidéo 4K originale).
Méthodes
Voyons ensuite comment la recherche a été menée.
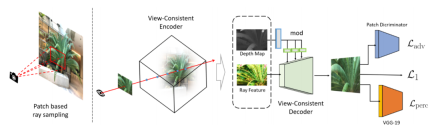
Pipeline 4K-NeRF (comme indiqué ci-dessous) : utilisez la technologie d'échantillonnage de rayons basée sur des patchs pour former conjointement VC-Encoder (View-Consistent) (basé sur DEVO) pour coder des informations géométriques tridimensionnelles dans un espace de résolution inférieure, puis grâce à un décodeur VC, un rendu haute fréquence, de qualité fine et de haute qualité et une amélioration de la cohérence de la vue sont obtenus.
L'étude instancie l'encodeur sur la base de la formule définie dans DVGO [32] et apprend une représentation basée sur une grille de voxels pour coder explicitement la géométrie :
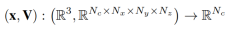
Pour chaque Pour chaque point d'échantillonnage, l'interpolation trilinéaire d'estimation de la densité est équipée d'une fonction d'activation softplus pour générer la valeur de densité volumique du point :

La couleur est estimée à l'aide d'un petit MLP :

Dans ce De cette manière, la valeur caractéristique de chaque rayon (ou pixel) peut être obtenue en accumulant les caractéristiques des points d'échantillonnage le long de la ligne définie r :
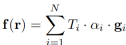
Afin de mieux utiliser la géométrie intégrée dans les propriétés du VC-Encoder, l'étude a également généré une carte de profondeur en estimant la profondeur de chaque rayon r le long de l'axe du rayon échantillonné. La carte de profondeur estimée fournit un guide solide sur la structure tridimensionnelle de la scène générée par l'encodeur ci-dessus :
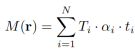
Le réseau transmis ensuite est obtenu en empilant plusieurs blocs de convolution (ni en utilisant une normalisation non paramétrique ni Créé à l'aide d'opérations de sous-échantillonnage) et d'opérations de suréchantillonnage entrelacées. En particulier, au lieu de simplement concaténer la caractéristique F et la carte de profondeur M, cette étude joint le signal de profondeur de la carte de profondeur et l'injecte dans chaque bloc via une transformation apprise pour moduler les activations de blocs.

Différent du mécanisme au niveau des pixels des méthodes NeRF traditionnelles, la méthode étudiée dans cette étude vise à capturer les informations spatiales entre les rayons (pixels). Par conséquent, la stratégie d’échantillonnage aléatoire des rayons dans NeRF ne convient pas ici. Par conséquent, cette étude propose une stratégie de formation à l’échantillonnage de rayons basée sur des patchs pour faciliter la capture de la dépendance spatiale entre les caractéristiques des rayons. Lors de l'entraînement, l'image de la vue d'entraînement est d'abord divisée en patchs p de taille N_p×N_p pour garantir que la probabilité d'échantillonnage sur les pixels est uniforme. Lorsque la dimension de l'espace image ne peut pas être divisée avec précision par la taille du patch, le patch doit être tronqué jusqu'au bord pour obtenir un ensemble de patchs d'entraînement. Ensuite, un (ou plusieurs) patchs sont sélectionnés au hasard dans l'ensemble, et les rayons des pixels du patch forment un mini-lot pour chaque itération.
Pour résoudre le problème du flou ou du lissage excessif des effets visuels sur les détails fins, cette recherche ajoute la perte contradictoire et la perte de perception pour régulariser la synthèse des détails fins. La perte de perception  estime la similarité entre le patch prédit
estime la similarité entre le patch prédit  et la vérité terrain p dans l'espace des fonctionnalités via un réseau VGG à 19 couches pré-entraîné :
et la vérité terrain p dans l'espace des fonctionnalités via un réseau VGG à 19 couches pré-entraîné :

L'étude utilise  perte Au lieu de MSE pour superviser la reconstruction des détails à haute fréquence
perte Au lieu de MSE pour superviser la reconstruction des détails à haute fréquence
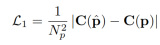
De plus, l'étude a également ajouté une perte MSE auxiliaire, et la fonction de perte totale finale a la forme suivante :

Effet expérimental
Analyse qualitative
L'expérience a comparé le 4K-NeRF avec d'autres modèles. On peut voir que les méthodes basées sur le NeRF ordinaire présentent différents degrés de perte de détails et de flou. En revanche, le 4K-NeRF offre un rendu photoréaliste de haute qualité de ces détails complexes et haute fréquence, même sur des scènes avec un champ de vision d'entraînement limité.


Analyse quantitative
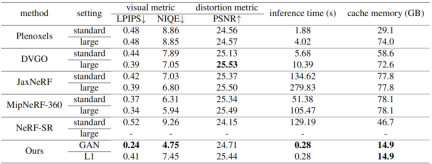
Cette étude a été comparée à plusieurs méthodes actuelles sur la base de données 4k, notamment Plenoxels, DVGO, JaxNeRF, MipNeRF-360 et NeRF-SR. L'expérience utilise non seulement les indicateurs d'évaluation de la récupération d'image à titre de comparaison, mais fournit également un temps d'inférence et une mémoire cache pour une référence d'évaluation complète. Les résultats sont les suivants :

Bien que les résultats ne soient pas très différents des résultats de certaines méthodes dans certains indicateurs, grâce à leur méthode basée sur les voxels, ils ont atteint des performances étonnantes en termes d'efficacité de raisonnement et de coût de mémoire. , permettant de restituer une image 4K en 300 ms.
Résumé et perspectives futures
Cette étude explore les capacités de NeRF en matière de modélisation des détails fins, proposant un nouveau cadre pour améliorer son expressivité dans la récupération de détails fins cohérents avec la vue dans des scènes à des résolutions extrêmement élevées. En outre, cette recherche introduit également une paire de modules codeurs-décodeurs qui maintiennent la cohérence géométrique, modélisent efficacement les propriétés géométriques dans les espaces inférieurs et utilisent des corrélations locales entre les fonctionnalités sensibles à la géométrie pour obtenir des vues dans un espace à grande échelle. Le cadre de formation à l'échantillonnage basé sur l'échantillonnage permet également à la méthode d'intégrer la supervision à partir d'une régularisation orientée perceptron. Cette recherche espère intégrer les effets du cadre dans la modélisation de scènes dynamiques, ainsi que dans les tâches de rendu neuronal comme orientations futures.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

 Dançon: mouvement structuré pour affiner nos filets neuronaux humainsApr 27, 2025 am 11:09 AM
Dançon: mouvement structuré pour affiner nos filets neuronaux humainsApr 27, 2025 am 11:09 AMLes scientifiques ont largement étudié les réseaux de neurones humains et plus simples (comme ceux de C. elegans) pour comprendre leur fonctionnalité. Cependant, une question cruciale se pose: comment adapter nos propres réseaux de neurones pour travailler efficacement aux côtés de nouvelles IA
 La nouvelle fuite de Google révèle des modifications d'abonnement pour Gemini AIApr 27, 2025 am 11:08 AM
La nouvelle fuite de Google révèle des modifications d'abonnement pour Gemini AIApr 27, 2025 am 11:08 AMGémeaux de Google Avancé: nouveaux niveaux d'abonnement à l'horizon Actuellement, l'accès à Gemini Advanced nécessite un plan premium de 19,99 $ / mois / mois. Cependant, un rapport Android Authority fait allusion aux changements à venir. Code dans le dernier Google P
 Comment l'accélération de l'analyse des données résout le goulot d'étranglement caché de l'IAApr 27, 2025 am 11:07 AM
Comment l'accélération de l'analyse des données résout le goulot d'étranglement caché de l'IAApr 27, 2025 am 11:07 AMMalgré le battage médiatique entourant les capacités avancées de l'IA, un défi important se cache dans les déploiements d'IA d'entreprise: les goulots d'étranglement du traitement des données. Alors que les PDG célèbrent les progrès de l'IA, les ingénieurs se débattent avec des temps de requête lents, des pipelines surchargés, un
 Markitdown MCP peut convertir n'importe quel document en Markdowns!Apr 27, 2025 am 09:47 AM
Markitdown MCP peut convertir n'importe quel document en Markdowns!Apr 27, 2025 am 09:47 AMLa gestion des documents ne consiste plus à ouvrir des fichiers dans vos projets d'IA, il s'agit de transformer le chaos en clarté. Des documents tels que les PDF, les PowerPoints et les mots inondent nos workflows sous toutes les formes et taille. Récupération structurée
 Comment utiliser Google ADK pour la construction d'agents? - Analytique VidhyaApr 27, 2025 am 09:42 AM
Comment utiliser Google ADK pour la construction d'agents? - Analytique VidhyaApr 27, 2025 am 09:42 AMExploitez la puissance du kit de développement d'agent de Google (ADK) pour créer des agents intelligents avec des capacités du monde réel! Ce tutoriel vous guide à travers la construction d'agents conversationnels en utilisant ADK, soutenant divers modèles de langue comme Gemini et GPT. W
 Utilisation de SLM sur LLM pour une résolution de problèmes efficace - Analytics VidhyaApr 27, 2025 am 09:27 AM
Utilisation de SLM sur LLM pour une résolution de problèmes efficace - Analytics VidhyaApr 27, 2025 am 09:27 AMrésumé: Le modèle de petit langage (SLM) est conçu pour l'efficacité. Ils sont meilleurs que le modèle de grande langue (LLM) dans des environnements déficientes en ressources, en temps réel et sensibles à la confidentialité. Le meilleur pour les tâches basées sur la mise au point, en particulier lorsque la spécificité du domaine, la contrôlabilité et l'interprétabilité sont plus importantes que les connaissances générales ou la créativité. Les SLM ne remplacent pas les LLM, mais ils sont idéaux lorsque la précision, la vitesse et la rentabilité sont essentielles. La technologie nous aide à réaliser plus avec moins de ressources. Il a toujours été un promoteur, pas un chauffeur. De l'ère de la machine à vapeur à l'ère des bulles Internet, la puissance de la technologie se situe dans la mesure où elle nous aide à résoudre des problèmes. L'intelligence artificielle (IA) et plus récemment l'IA génératrice ne font pas exception
 Comment utiliser les modèles Google Gemini pour les tâches de vision par ordinateur? - Analytique VidhyaApr 27, 2025 am 09:26 AM
Comment utiliser les modèles Google Gemini pour les tâches de vision par ordinateur? - Analytique VidhyaApr 27, 2025 am 09:26 AMExploiter la puissance de Google Gemini pour la vision par ordinateur: un guide complet Google Gemini, un chatbot d'IA de premier plan, étend ses capacités au-delà de la conversation pour englober de puissantes fonctionnalités de vision informatique. Ce guide détaille comment utiliser
 Gemini 2.0 Flash vs O4-Mini: Google peut-il faire mieux qu'Openai?Apr 27, 2025 am 09:20 AM
Gemini 2.0 Flash vs O4-Mini: Google peut-il faire mieux qu'Openai?Apr 27, 2025 am 09:20 AMLe paysage de l'IA de 2025 est électrisant avec l'arrivée de Gemini 2.0 Flash de Google et O4-Mini d'OpenAI. Ces modèles de pointe, lancés à quelques semaines, offrent des fonctionnalités avancées comparables et des scores de référence impressionnants. Cette comparaison approfondie


Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Dreamweaver Mac
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)

Adaptateur de serveur SAP NetWeaver pour Eclipse
Intégrez Eclipse au serveur d'applications SAP NetWeaver.

MinGW - GNU minimaliste pour Windows
Ce projet est en cours de migration vers osdn.net/projects/mingw, vous pouvez continuer à nous suivre là-bas. MinGW : un port Windows natif de GNU Compiler Collection (GCC), des bibliothèques d'importation et des fichiers d'en-tête librement distribuables pour la création d'applications Windows natives ; inclut des extensions du runtime MSVC pour prendre en charge la fonctionnalité C99. Tous les logiciels MinGW peuvent fonctionner sur les plates-formes Windows 64 bits.

PhpStorm version Mac
Le dernier (2018.2.1) outil de développement intégré PHP professionnel

