
Maison >développement back-end >Tutoriel Python >Comment utiliser ClickHouse en Python
Comment utiliser ClickHouse en Python

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-17 08:19:283310parcourir
ClickHouse est une base de données en colonnes (SGBD) open source qui a beaucoup attiré l'attention ces dernières années. Elle est principalement utilisée dans le domaine de l'analyse de données en ligne. (OLAP). Il a été lancé en 2016 Open source. À l'heure actuelle, la communauté nationale est en plein essor et les grands fabricants l'ont suivi et l'ont utilisé à grande échelle.
Les gros titres d'aujourd'hui utilisent ClickHouse en interne pour analyser le comportement des utilisateurs. Il existe des milliers de nœuds ClickHouse en interne, avec un maximum de 1 200 nœuds dans un seul cluster. des dizaines de PB, et le quotidien Les données originales sont augmentées d'environ 300 To.
Tencent utilise ClickHouse en interne pour l'analyse des données de jeu et a mis en place un système complet de surveillance et d'exploitation pour celui-ci.
Depuis l'essai de juillet 2018, Ctrip a migré 80% de son activité interne vers la base de données ClickHouse. Les données augmentent de plus d'un milliard chaque jour et près d'un million de requêtes sont effectuées.
Kuaishou utilise également ClickHouse en interne. La capacité de stockage totale est d'environ 10 Po, avec 200 To ajoutés chaque jour, et 90 % des requêtes durent moins de 3 S.
À l'étranger, il existe des centaines de nœuds dans Yandex utilisés pour analyser le comportement des clics des utilisateurs, et des sociétés de premier plan telles que CloudFlare et Spotify les utilisent également.
ClickHouse a été initialement développé pour développer YandexMetrica, la deuxième plus grande plateforme d'analyse Web au monde. Il est utilisé en permanence comme élément central du système depuis de nombreuses années.
1. À propos des pratiques d'utilisation de ClickHouse
Tout d'abord, passons en revue quelques concepts de base :
OLTP: Il s'agit d'une base de données relationnelle traditionnelle, qui opère principalement des ajouts, des suppressions, des modifications et des requêtes, et met l'accent sur la cohérence des transactions, comme les systèmes bancaires et les systèmes de commerce électronique.OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。OLAP
OLAP : Il s'agit d'une base de données de type entrepôt qui lit principalement les données, effectue des analyses de données complexes, se concentre sur l'aide à la décision technique et fournit résultat intuitif et simple.
1.1. ClickHouse est utilisé dans les scénarios d'entrepôt de données- ClickHouse est une base de données en colonnes, plus adaptée aux scénarios OLAP.
- La grande majorité sont des requêtes de lecture
- Les données sont présentées par lots assez volumineux (> ; 1000 lignes ) mis à jour au lieu d'une seule ligne ou pas du tout mis à jour ;
- Les données ajoutées à la base de données ne peuvent pas être modifiées.
- Pour les lectures, extrayez quelques lignes de la base de données, mais seulement un petit sous-ensemble de colonnes.
- Tableau large, c'est-à-dire que chaque table contient un grand nombre de colonnes
- Il y en a relativement peu requêtes (généralement des centaines de requêtes par seconde ou moins par serveur
Les données dans les colonnes sont relativement petites : des nombres et des chaînes courtes (par exemple 60 octets par URL)
- #🎜 🎜#Nécessite des performances élevées lors du traitement d'une seule requête Débit (jusqu'à des milliards de lignes par seconde par serveur) #Faibles exigences de cohérence des données
- Chaque requête a une grande table. A part lui, tout le monde est petit.
- Le résultat de la requête est nettement plus petit que les données sources. En d'autres termes, les données sont filtrées ou agrégées afin que les résultats tiennent dans la RAM d'un seul serveur
- 1.2. Outil client DBeaver L'outil client est dbeaver, et. le site officiel est https://dbeaver.io/.
- dbeaver est un outil de base de données universel gratuit et open source (GPL) pour les développeurs et les administrateurs de bases de données. [Encyclopédie Baidu]
- L'objectif principal de ce projet est d'améliorer la facilité d'utilisation, nous avons donc spécialement conçu et développé un outil de gestion de base de données. Gratuit, multiplateforme, basé sur un framework open source et permet l'écriture de diverses extensions (plug-ins).
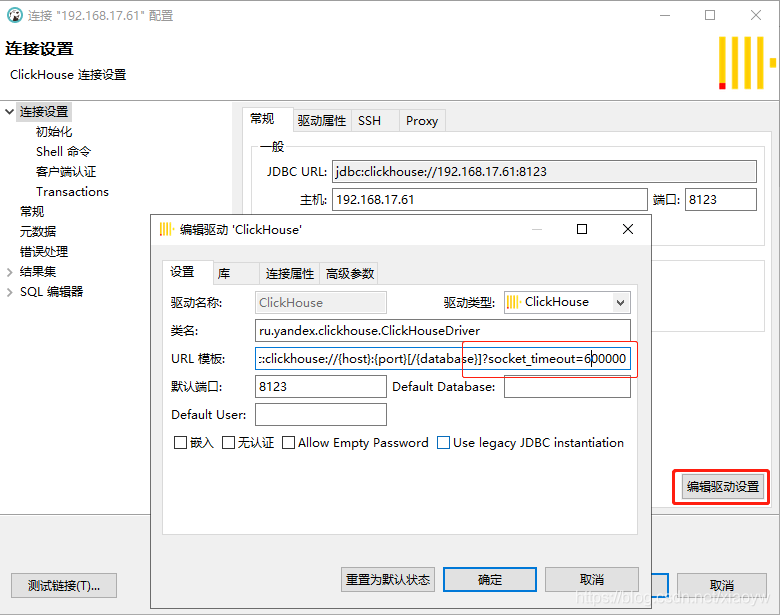
- Créez et configurez une nouvelle connexion via "Base de données" dans le menu de l'interface d'opération, comme indiqué dans la figure ci-dessous, sélectionnez et téléchargez le pilote ClickHouse (pas de pilote par défaut ).
- La configuration de DBeaver est basée sur Jdbc L'URL et le port par défaut généraux sont les suivants :
jdbc:clickhouse://192.168.17.61:8123
Comme indiqué dans le figure ci-dessous.
Lorsque vous utilisez DBeaver pour vous connecter à Clickhouse pour une requête, la connexion ou la requête expire parfois. À ce stade, vous pouvez ajouter et définir le paramètre socket_timeout dans les paramètres de connexion pour résoudre le problème. jdbc:clickhouse://{host}:{port}[/{database}]?socket_timeout=600000
 Brève description de l'environnement : # 🎜🎜 #
Brève description de l'environnement : # 🎜🎜 #
 Afin d'analyser le comportement commercial des clients, dans des conditions de ressources limitées, les détails des transactions sont extraits et compilés par jour et par point de négociation dans les enregistrements de transactions, comme le montre la figure ci-dessous.
Afin d'analyser le comportement commercial des clients, dans des conditions de ressources limitées, les détails des transactions sont extraits et compilés par jour et par point de négociation dans les enregistrements de transactions, comme le montre la figure ci-dessous.
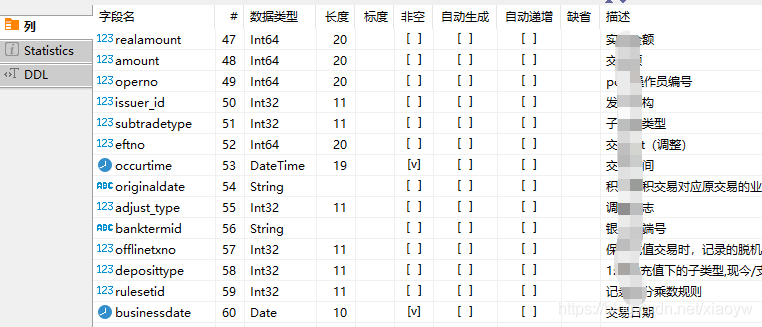
其中,在ClickHouse上,交易数据结构由60个列(字段)组成,截取部分如下所示:
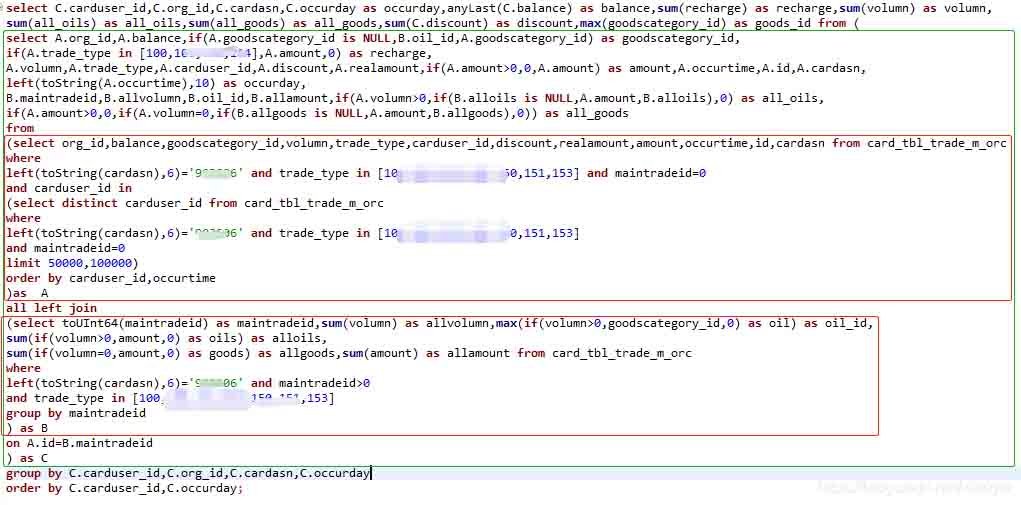
针对频繁出现“would use 10.20 GiB , maximum: 9.31 GiB”等内存不足的情况,基于ClickHouse的SQL,编写了提取聚合数据集SQL语句,如下所示。
大约60s返回结果,如下所示:

2. Python使用ClickHouse实践
2.1. ClickHouse第三方Python驱动clickhouse_driver
ClickHouse没有提供官方Python接口驱动,常用第三方驱动接口为clickhouse_driver,可以使用pip方式安装,如下所示:
pip install clickhouse_driver
Collecting clickhouse_driver
Downloading https://files.pythonhosted.org/packages/88/59/c570218bfca84bd0ece896c0f9ac0bf1e11543f3c01d8409f5e4f801f992/clickhouse_driver-0.2.1-cp36-cp36m-win_amd64.whl (173kB)
100% |████████████████████████████████| 174kB 27kB/s
Collecting tzlocal<3.0 (from clickhouse_driver)
Downloading https://files.pythonhosted.org/packages/5d/94/d47b0fd5988e6b7059de05720a646a2930920fff247a826f61674d436ba4/tzlocal-2.1-py2.py3-none-any.whl
Requirement already satisfied: pytz in d:\python\python36\lib\site-packages (from clickhouse_driver) (2020.4)
Installing collected packages: tzlocal, clickhouse-driver
Successfully installed clickhouse-driver-0.2.1 tzlocal-2.1使用的client api不能用了,报错如下:
File "clickhouse_driver\varint.pyx", line 62, in clickhouse_driver.varint.read_varint
File "clickhouse_driver\bufferedreader.pyx", line 55, in clickhouse_driver.bufferedreader.BufferedReader.read_one
File "clickhouse_driver\bufferedreader.pyx", line 240, in clickhouse_driver.bufferedreader.BufferedSocketReader.read_into_buffer
EOFError: Unexpected EOF while reading bytes
Python驱动使用ClickHouse端口9000。
ClickHouse服务器和客户端之间的通信有两种协议:http(端口8123)和本机(端口9000)。DBeaver驱动配置使用jdbc驱动方式,端口为8123。
ClickHouse接口返回数据类型为元组,也可以返回Pandas的DataFrame,本文代码使用的为返回DataFrame。
collection = self.client.query_dataframe(self.query_sql)
2.2. 实践程序代码
由于我本机最初资源为8G内存(现扩到16G),以及实际可操作性,分批次取数据保存到多个文件中,每个文件大约为1G。
# -*- coding: utf-8 -*-
'''
Created on 2021年3月1日
@author: xiaoyw
'''
import pandas as pd
import json
import numpy as np
import datetime
from clickhouse_driver import Client
#from clickhouse_driver import connect
# 基于Clickhouse数据库基础数据对象类
class DB_Obj(object):
'''
192.168.17.61:9000
ebd_all_b04.card_tbl_trade_m_orc
'''
def __init__(self, db_name):
self.db_name = db_name
host='192.168.17.61' #服务器地址
port ='9000' #'8123' #端口
user='***' #用户名
password='***' #密码
database=db_name #数据库
send_receive_timeout = 25 #超时时间
self.client = Client(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
#self.conn = connect(host=host, port=port, database=database) #, send_receive_timeout=send_receive_timeout)
def setPriceTable(self,df):
self.pricetable = df
def get_trade(self,df_trade,filename):
print('Trade join price!')
df_trade = pd.merge(left=df_trade,right=self.pricetable[['occurday','DIM_DATE','END_DATE','V_0','V_92','V_95','ZDE_0','ZDE_92',
'ZDE_95']],how="left",on=['occurday'])
df_trade.to_csv(filename,mode='a',encoding='utf-8',index=False)
def get_datas(self,query_sql):
n = 0 # 累计处理卡客户数据
k = 0 # 取每次DataFrame数据量
batch = 100000 #100000 # 分批次处理
i = 0 # 文件标题顺序累加
flag=True # 数据处理解释标志
filename = 'card_trade_all_{}.csv'
while flag:
self.query_sql = query_sql.format(n, n+batch)
print('query started')
collection = self.client.query_dataframe(self.query_sql)
print('return query result')
df_trade = collection #pd.DataFrame(collection)
i=i+1
k = len(df_trade)
if k > 0:
self.get_trade(df_trade, filename.format(i))
n = n + batch
if k == 0:
flag=False
print('Completed ' + str(k) + 'trade details!')
print('Usercard count ' + str(n) )
return n
# 价格变动数据集
class Price_Table(object):
def __init__(self, cityname, startdate):
self.cityname = cityname
self.startdate = startdate
self.filename = 'price20210531.csv'
def get_price(self):
df_price = pd.read_csv(self.filename)
......
self.price_table=self.price_table.append(data_dict, ignore_index=True)
print('generate price table!')
class CardTradeDB(object):
def __init__(self,db_obj):
self.db_obj = db_obj
def insertDatasByCSV(self,filename):
# 存在数据混合类型
df = pd.read_csv(filename,low_memory=False)
# 获取交易记录
def getTradeDatasByID(self,ID_list=None):
# 字符串过长,需要使用'''
query_sql = '''select C.carduser_id,C.org_id,C.cardasn,C.occurday as
......
limit {},{})
group by C.carduser_id,C.org_id,C.cardasn,C.occurday
order by C.carduser_id,C.occurday'''
n = self.db_obj.get_datas(query_sql)
return n
if __name__ == '__main__':
PTable = Price_Table('湖北','2015-12-01')
PTable.get_price()
db_obj = DB_Obj('ebd_all_b04')
db_obj.setPriceTable(PTable.price_table)
CTD = CardTradeDB(db_obj)
df = CTD.getTradeDatasByID()返回本地文件为:
3. 小结一下
ClickHouse运用于OLAP场景时,拥有出色的查询速度,但需要具备大内存支持。Python第三方clickhouse-driver 驱动基本满足数据处理需求,如果能返回Pandas DataFrame最好。
ClickHouse和Pandas聚合都是非常快的,ClickHouse聚合函数也较为丰富(例如文中anyLast(x)返回最后遇到的值),如果能通过SQL聚合的,还是在ClickHouse中完成比较理想,把更小的结果集反馈给Python进行机器学习。
操作ClickHouse删除指定数据
def info_del2(i):
client = click_client(host='地址', port=端口, user='用户名', password='密码',
database='数据库')
sql_detail='alter table SS_GOODS_ORDER_ALL delete where order_id='+str(i)+';'
try:
client.execute(sql_detail)
except Exception as e:
print(e,'删除商品数据失败')在进行数据删除的时候,python操作clickhou和mysql的方式不太一样,这里不能使用以往常用的%s然后添加数据的方式,必须完整的编辑一条语句,如同上面方法所写的一样,传进去的参数统一使用str类型
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!