
Maison >Périphériques technologiques >IA >Pratique de l'algorithme d'apprentissage profond NIO
Pratique de l'algorithme d'apprentissage profond NIO

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-15 11:07:061756parcourir

1. Contexte commercial de NIO Power
1. Système de services énergétiques NIO
L'objectif de l'équipe commerciale de NIO Power est de construire un système de services énergétiques intelligents innovant à l'échelle mondiale basé sur la mise sous tension de l'Internet mobile La solution consiste à disposer d'un vaste réseau d'installations de recharge et d'échange et à s'appuyer sur la technologie cloud NIO pour créer un système de service énergétique « rechargeable, échangeable et évolutif » afin de fournir aux propriétaires de voitures des services de mise sous tension complets.

2. Défis liés au fonctionnement et à la maintenance des équipements
Les services d'exploitation et de maintenance des équipements NIO Power comprennent principalement les stations de remplacement d'énergie NIO, les super piles de recharge NIO, les piles de recharge domestique 2.0 de 7 kW et les piles de recharge domestique de 20 kW. bornes de recharge rapide Équipements de recharge et autres équipements; ce service fait actuellement face à de nombreux défis, notamment :
① S'assurer que l'équipement ne présente aucun risque pour la sécurité.
② Plaintes des utilisateurs : Mauvaise expérience de mise sous tension.
③ Le taux de réussite de la charge et de l'échange est réduit en raison d'une panne d'équipement.
④ Temps d'arrêt dû à une panne d'équipement.
⑤ Les coûts d'exploitation et d'entretien sont élevés.
2. Solution d'exploitation et de maintenance des équipements NIO Power
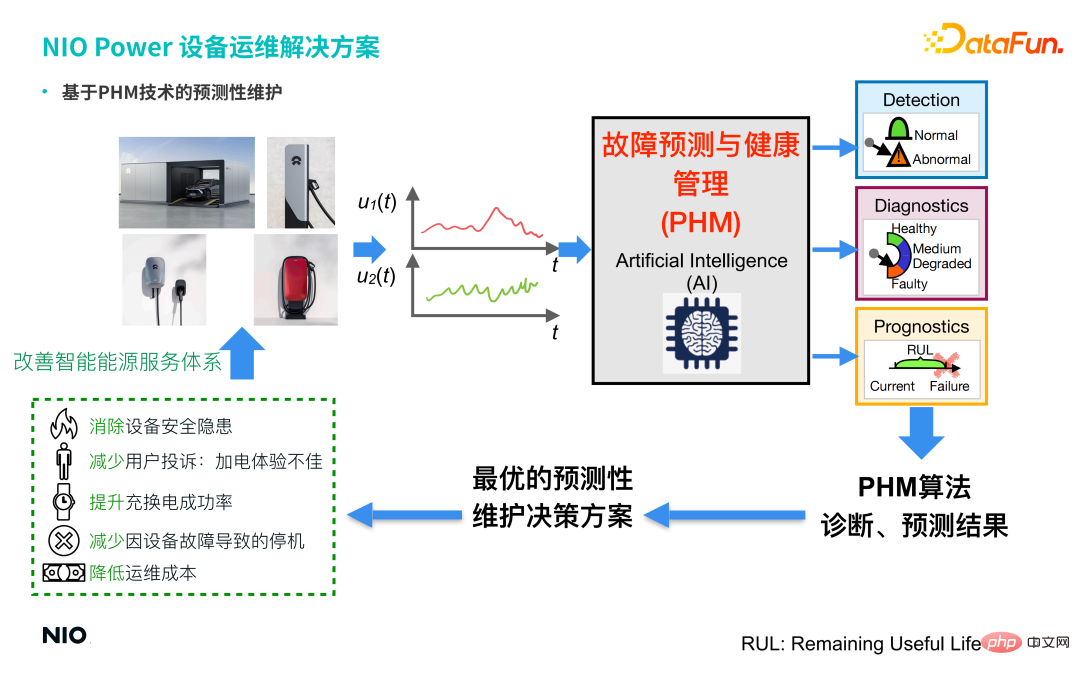
Les 4 principaux types d'équipements de charge et de décharge de l'entreprise (station d'échange d'énergie, super pile de recharge, pile de recharge domestique de 7 kW, domestique de 20 kW pile de charge rapide) contiennent tous deux un grand nombre de capteurs, de sorte que les données collectées par les capteurs en temps réel sont unifiées dans le NIO Energy Cloud pour un stockage et une gestion unifiés, et une technologie de maintenance prédictive basée sur PHM (Fault Prediction and Health Management) est introduit via une série d'algorithmes d'IA, tels que : GAN (Generative Adversarial Network) et Conceptor (Conceptor Network) peuvent obtenir la détection anormale et le diagnostic des défauts de l'équipement, et fournir la solution optimale de prise de décision en matière de maintenance prédictive pour l'équipement basée sur les résultats de prédiction du diagnostic, et émettre des travaux d'exploitation et de maintenance pertinents. Unique, réaliser :
① Éliminer les risques de sécurité des équipements.
② Réduisez les plaintes des utilisateurs concernant une mauvaise expérience de mise sous tension.
③ Améliorez le taux de réussite de la charge et de l'échange.
④ Réduisez les temps d'arrêt causés par une panne d'équipement.
⑤ Réduisez les coûts d'exploitation et de maintenance.
Par conséquent, l'introduction de la technologie et des algorithmes PHM a efficacement aidé l'entreprise à améliorer son système de service énergétique intelligent et à former une boucle fermée, améliorant et optimisant ainsi les capacités de service de NIO Power.
3. Les défis rencontrés par la technologie PHM
Les technologies PHM de pointe sont toutes basées sur la technologie d'intelligence artificielle basée sur les données. "Data-driven" s'appuie sur un grand nombre d'échantillons et d'étiquettes pour construire des modèles, et les modèles sont souvent idéaux. Ils sont construits sous la scène, mais la scène réelle n'est souvent pas idéale.
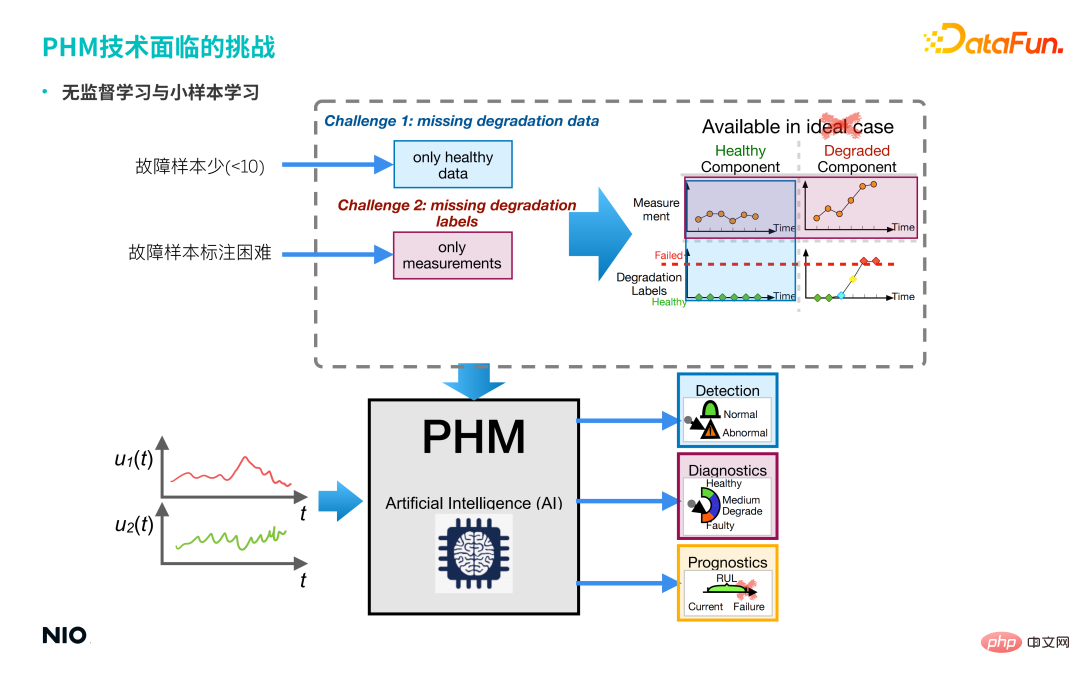
Comme le montre l'image ci-dessus, les scènes réelles ont souvent les caractéristiques suivantes :
① Il y a peu d'échantillons de défauts.
② Il est difficile d'étiqueter les échantillons de défauts.
Cela entraîne deux types de problèmes rencontrés dans ce scénario : l'un concerne les problèmes d'apprentissage non supervisés et l'autre concerne les problèmes d'apprentissage sur de petits échantillons.
4. Technologie de pointe PHM
En réponse à ces deux types de problèmes rencontrés dans des scénarios réels, nous avons proposé les technologies de pointe PHM suivantes et les avons appliquées dans les scénarios NIO Power.
1. Détection d'anomalies non supervisée basée sur un réseau contradictoire génératif (GAN)
(1) Structure GAN
Le réseau adverse génératif, proposé en 2014, est un type d'apprentissage non supervisé basé sur l'apprentissage profond. La technologie est principalement composée de deux sous-réseaux : le générateur et le discriminateur.
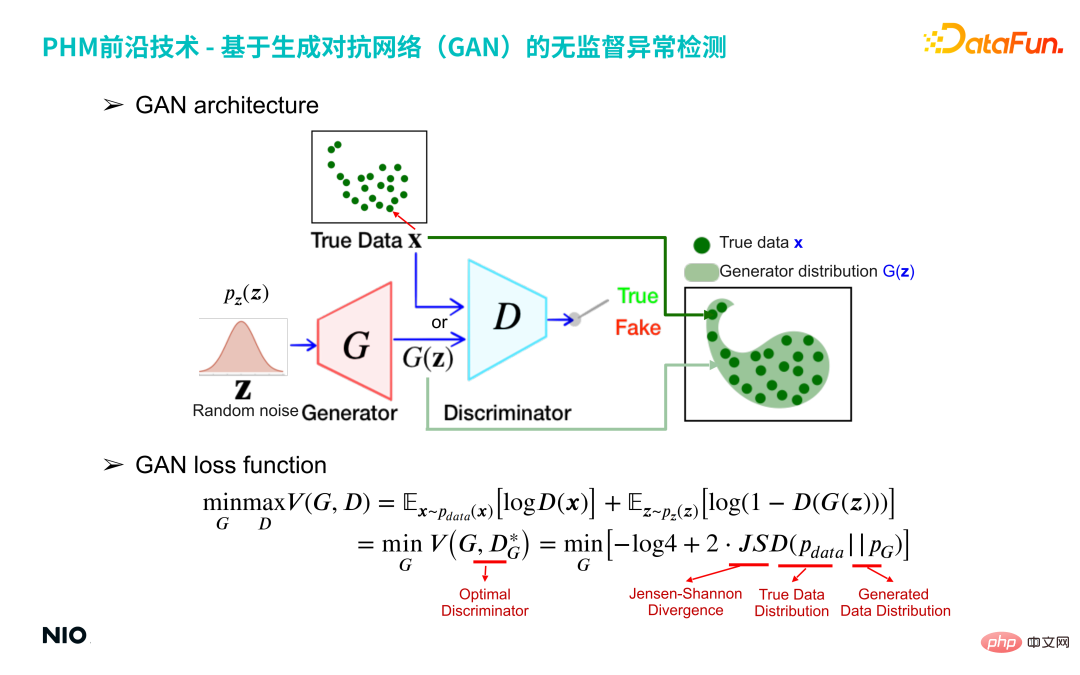
Le réseau G rouge sur l'image ci-dessus est le réseau générateur, et le réseau D bleu est le réseau discriminateur.
Réseau de générateurs entre une distribution de nombres aléatoires (telle que la distribution gaussienne) et génère une distribution spécifique spécifiée par l'utilisateur du point de vue de l'échantillon, 100 échantillons de données échantillonnés à partir de la distribution de nombres aléatoires sont saisis ; le réseau G, le réseau G mappera ces 100 échantillons dans le même espace que les données réelles pour former une distribution G(z), et utilisera le réseau discriminateur pour obtenir la différence entre les deux distributions G(z) et les données réelles X, Le réseau G est ensuite optimisé jusqu'à ce que la distribution G(z) soit proche de la distribution X des données réelles. Le réseau G produira ces 100 données et formera une distribution spécifique G(z). Le cœur du
réseau discriminateur est de construire la divergence approximative de Jensen-Shanon de la distribution G(z) et la distribution des données réelles x pour mesurer la différence entre la distribution générée et la distribution réelle . La divergence approximative de Jensen-Shanon est implémentée via un réseau de classification binaire standard basé sur l'entropie croisée binomiale, et la sortie du réseau discriminateur est une valeur continue de 0 à 1. Si la sortie est 1, on considère que l'échantillon d'entrée X provient de la distribution réelle ; si la sortie est 0, l'échantillon d'entrée X est considéré comme faux et faux ;
Dans la forme de formation du réseau GAN, les échantillons générés par le générateur tentent d'être proches de la distribution des échantillons réels, et le discriminateur essaie de distinguer les échantillons générés comme faux, afin de fournir au générateur un Jensen plus précis -Le gradient de la valeur de divergence de Shanon permet au générateur d'itérer dans une meilleure direction. En fin de compte, les deux forment une relation conflictuelle. Le générateur génère « désespérément » de fausses données, et le discriminateur « désespérément » distingue les vraies des fausses données d'entrée. Le réseau GAN finira par atteindre un état d'équilibre : la distribution des données générées G(z) couvre tout juste complètement la distribution de tous les échantillons réels X.
(2) Fonction de perte GAN
Comprendre le réseau GAN d'un point de vue mathématique peut être compris à partir de la fonction de perte. La fonction de perte peut utiliser la fonction de valeur V(G, D) pour optimiser simultanément les paramètres du réseau G et du réseau D via une optimisation minmax commune pour un réseau G donné, l'objectif d'optimisation est de minimiser la fonction de valeur, comme indiqué ; dans la formule suivante :
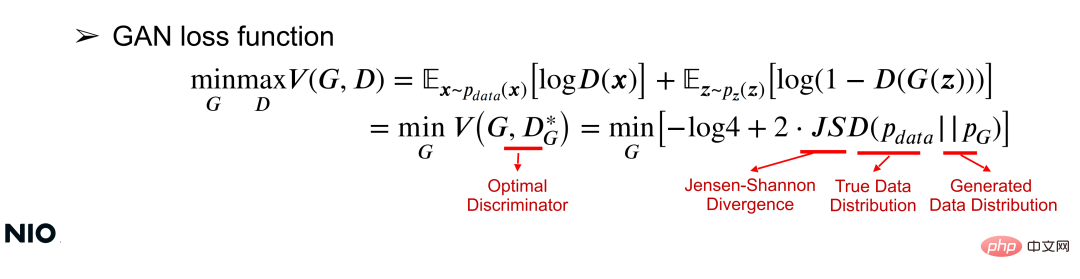
Dans la formule, JSD est le terme d'optimisation de base de la fonction de perte et est une mesure de la différence entre les deux distributions. Comme le montre la formule, l'essence de cette optimisation est de minimiser la différence de distribution entre X et G(z) ; plus la différence de distribution est petite, plus le réseau G est formé avec succès.
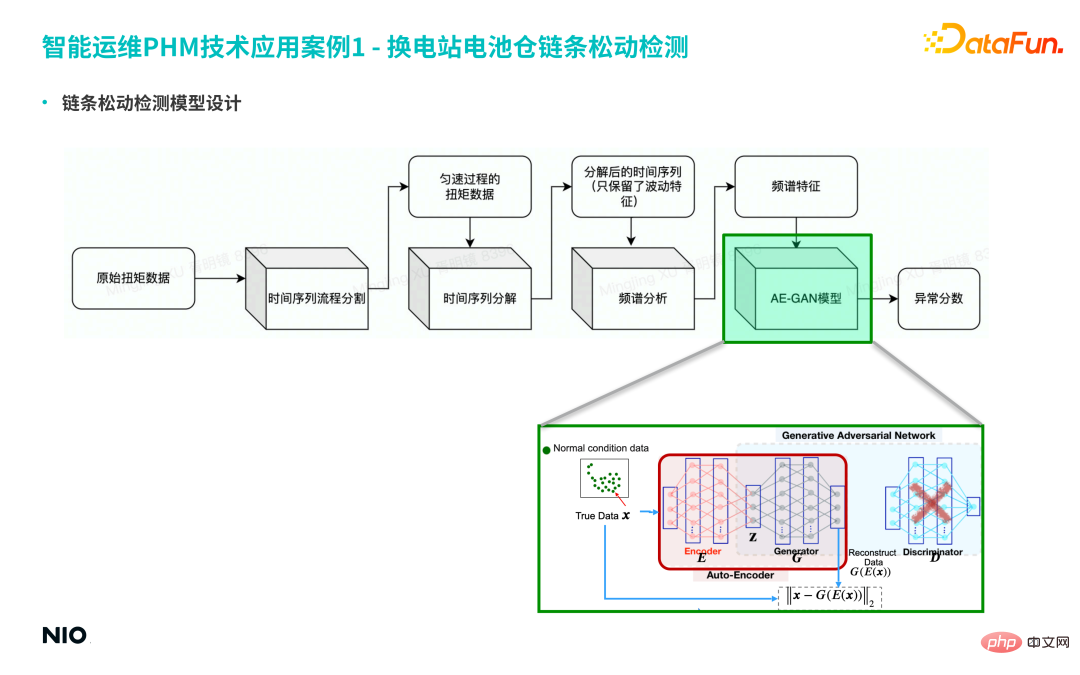
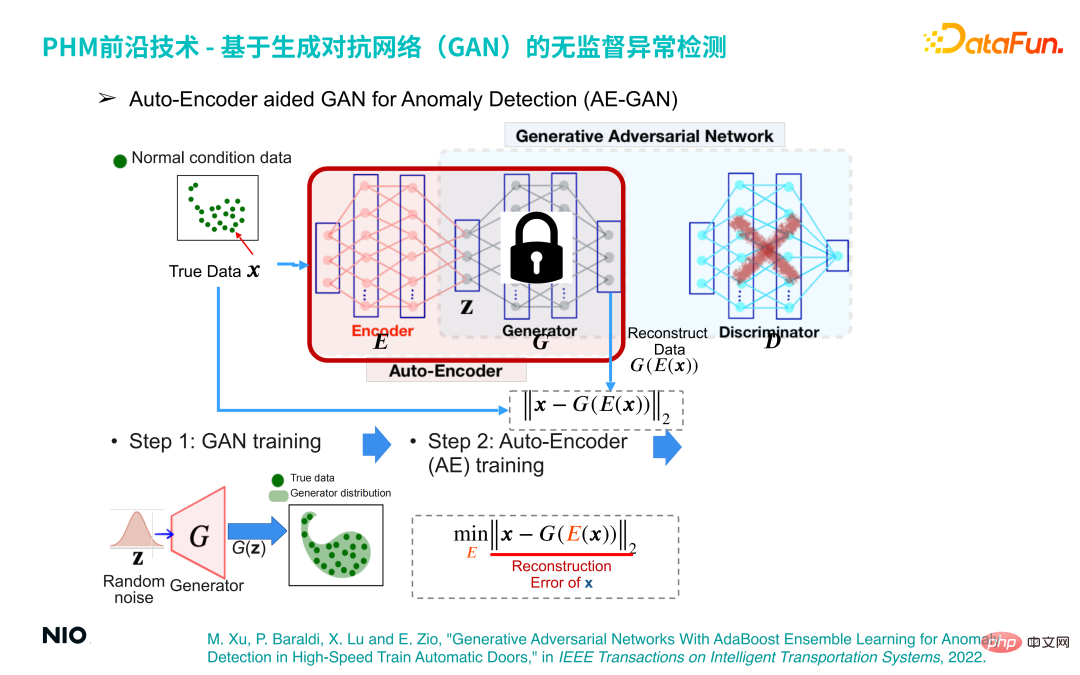
(3) GAN assisté par encodeur automatique pour la détection des anomalies (AE-GAN)
Basé sur le réseau GAN, l'auto-encodeur est introduit pour mettre en œuvre la détection d'anomalies des données de fonctionnement des équipements.
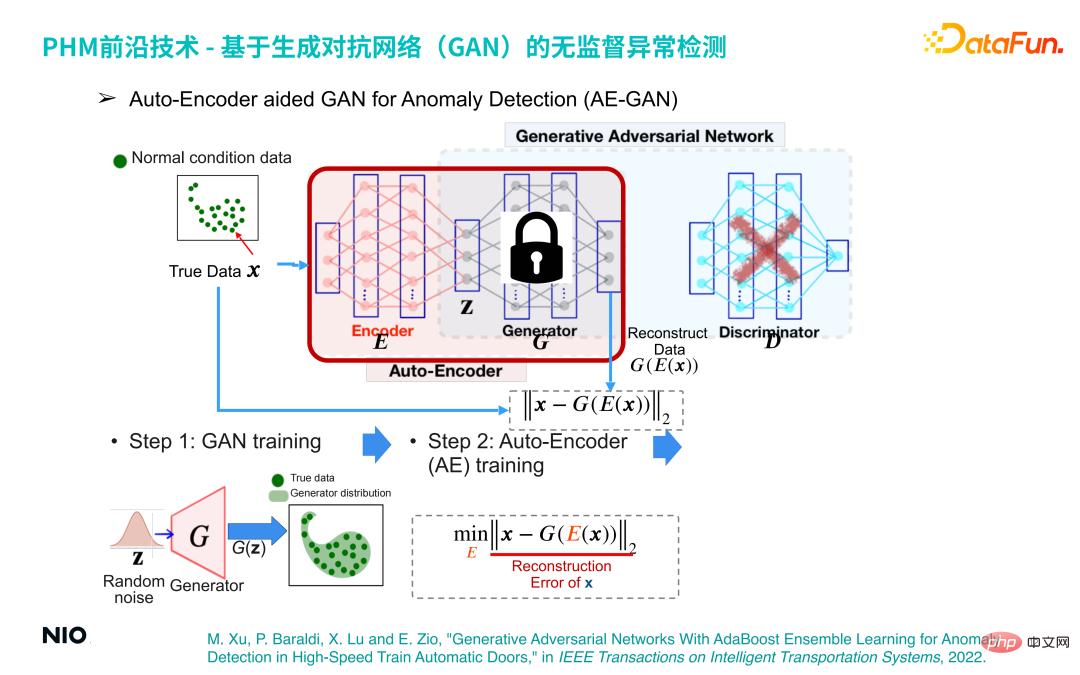
La méthode de mise en œuvre spécifique est la suivante :
La première étape consiste à construire un modèle GAN et à l'entraîner pour obtenir un réseau G, qui reconstruit simplement la distribution des données de fonctionnement des équipements.
La deuxième étape consiste à supprimer la partie réseau D du réseau GAN, à fixer les paramètres du réseau G et à introduire le réseau Encoder avant le réseau G de cette manière, le réseau Encoder et le réseau G sont combinés pour ; former un ensemble de réseaux Auto-Encoder standards. La fonction de perte de ce réseau est l'erreur de reconstruction.
De cette façon, nous pouvons compléter la détection des anomalies en optimisant le réseau Auto-Encoder. Le principe sous-jacent est le suivant : quel que soit l'échantillon d'entrée, les échantillons produits par le réseau Auto-Encoder seront dans l'échantillon normal. intervalle. Par conséquent, si l'échantillon d'entrée est un échantillon normal, l'échantillon généré et l'échantillon d'origine sont dans le même intervalle, donc l'erreur de reconstruction sera très faible voire proche de 0 et si l'échantillon d'entrée est un échantillon anormal, l'échantillon généré ; l'échantillon est toujours dans l'intervalle d'échantillonnage normal. Cela entraînera une erreur de reconstruction importante, par conséquent, l'erreur de reconstruction peut être utilisée pour déterminer si l'échantillon est normal ;
La troisième étape consiste à obtenir une série de scores d'erreur de reconstruction à travers un petit lot d'échantillons normaux et à utiliser sa valeur maximale comme seuil d'erreur de reconstruction pour la détection d'anomalies.
Ce principe a été entièrement discuté dans l'article, qui a été publié dans IEEE dans Transactions on Intelligent Transportation Systems en 2022. Les informations sur l'article sont les suivantes :
M Xu, P. Baraldi. , (Conceptor) diagnostic de défauts sur petit échantillon
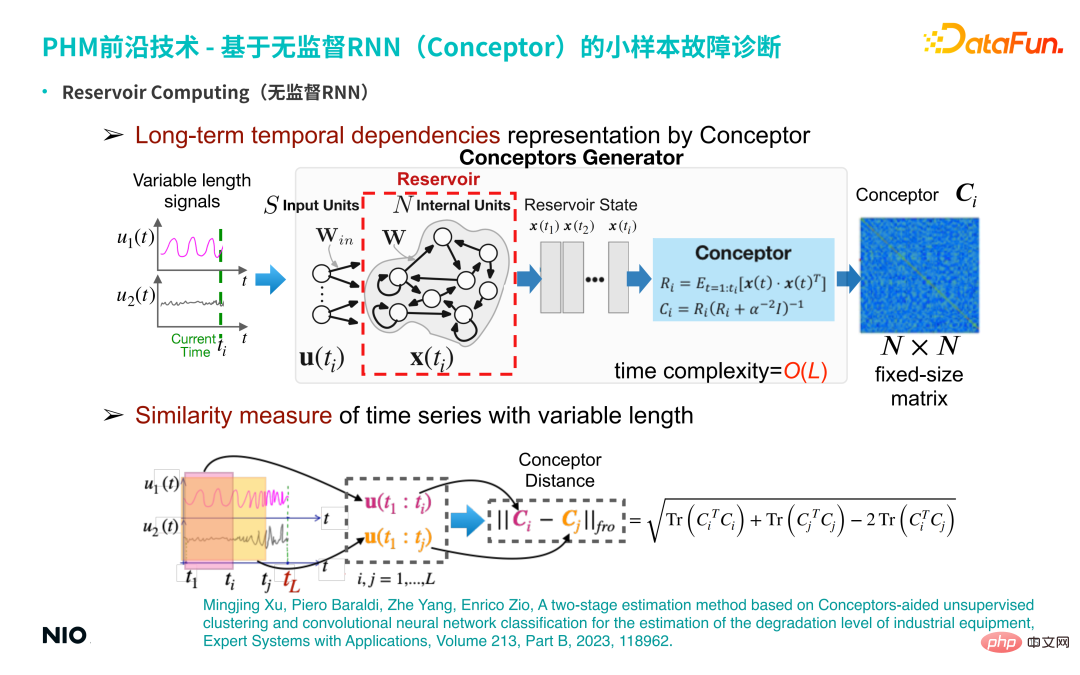
Le deuxième type de technologie que nous utilisons est une technologie de diagnostic de défauts sur petit échantillon RNN (nommé réseau de concepteurs : Conceptor) non supervisé.
(1) RNN non supervisé
Tout d'abord, nous présenterons le contexte de cette technologie - le RNN non supervisé. Par rapport au RNN ordinaire, la particularité du RNN non supervisé est que les poids de connexion des neurones dans la couche d'entrée du réseau et les poids de connexion des couches cachées sont initialisés de manière aléatoire et sont fixés pendant tout le processus de formation et d'inférence. Cela signifie que nous n'avons pas besoin d'entraîner les paramètres de poids de la couche d'entrée et de la couche cachée ; par conséquent, par rapport aux réseaux RNN ordinaires, nous pouvons définir les neurones de la couche cachée pour qu'ils soient très grands, de sorte que la période de mémoire et la capacité de mémoire du Le réseau sera s'il est très grand, la période de mémoire pour la série temporelle d'entrée sera plus longue. Les neurones de la couche cachée de ce RNN spécial non supervisé sont souvent appelés réservoir. 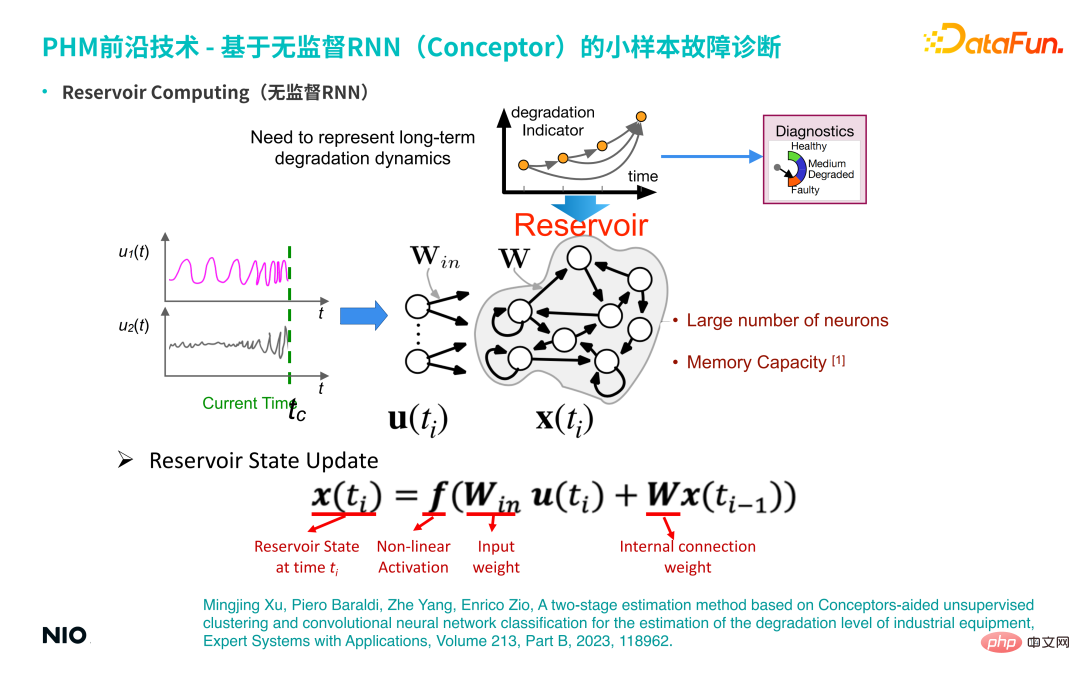
① Mise à jour de l'état du réservoir
La méthode de mise à jour de l'état est la même que la méthode de mise à jour RNN standard.② Représentation des dépendances temporelles à long terme par Conceptor
Développez une méthode d'apprentissage de représentation non supervisée basée sur ce RNN non supervisé. Plus précisément, saisissez une série temporelle multidimensionnelle de longueur variable et obtenez l'état des neurones cachés RNN de chaque pas de temps via Reservoir ; le cadre bleu clair dans la figure ci-dessus), une matrice conceptuelle de dimension N×N est obtenue. Entendu en termes d'algèbre linéaire, la signification de cette matrice est la suivante : lors du traitement des séries temporelles, pour chaque pas de temps, le signal de la série temporelle est projeté dans un espace à N dimensions (N correspond à l'échelle du neurone caché).
S'il y a ti Formez un nuage de points comme celui-ci. L'ellipsoïde du nuage de points peut être déconstruit en N mutuellement orthogonaux ; directions, et les vecteurs propres et les valeurs propres dans chaque direction sont obtenus. Le rôle de Conceptor est de capturer les valeurs propres et les vecteurs propres, et de normaliser les valeurs propres ; pour ces N vecteurs propres, il peut être compris comme N propriétés capturées dans la série chronologique (telles que la périodicité, la tendance, la volatilité et d'autres). caractéristiques de séries chronologiques complexes), c'est-à-dire l'extraction de caractéristiques implicites ; et toutes les informations sur les caractéristiques extraites sont conservées dans cette matrice à N dimensions (c'est-à-dire la matrice Concepteur, bleu foncé sur le côté droit de la figure au-dessus de la partie encadrée).
③ Mesure de similarité de séries temporelles à longueur variable
Selon les caractéristiques de base de la matrice, soustraire les matrices Concepteur des deux séries temporelles et extraire la norme de Frobenius pour obtenir le Concepteur des deux séries temporelles série Distance ; ce scalaire peut être utilisé pour caractériser la différence entre deux séries temporelles.
(2) Diagnostic de défauts sur petits échantillons basé sur Conceptor
Sur la base des fonctionnalités ci-dessus de Conceptor, il peut être utilisé pour effectuer une analyse de diagnostic de défauts sur petits échantillons.
 S'il existe un petit nombre d'échantillons de défauts réels (par exemple, il y a moins de 10 échantillons de défauts), toutes les séries temporelles correspondantes sont entrées dans le réseau Conceptor et agrégées pour former le correspondant matrice de concepts, comme la faute de cette catégorie Représentation abstraite des modèles ; de même, les échantillons normaux seront agrégés dans une matrice de concepts normale. Pendant les tests, utilisez la même méthode pour extraire la matrice conceptuelle correspondante de la série chronologique d'entrée et effectuez une analyse comparative avec les matrices conceptuelles des échantillons normaux et des échantillons anormaux pour calculer les différences conceptuelles correspondantes. Si la similarité entre l’échantillon d’entrée et la matrice conceptuelle d’un mode de défaillance spécifique est élevée, l’échantillon peut être considéré comme appartenant à ce mode de défaillance.
S'il existe un petit nombre d'échantillons de défauts réels (par exemple, il y a moins de 10 échantillons de défauts), toutes les séries temporelles correspondantes sont entrées dans le réseau Conceptor et agrégées pour former le correspondant matrice de concepts, comme la faute de cette catégorie Représentation abstraite des modèles ; de même, les échantillons normaux seront agrégés dans une matrice de concepts normale. Pendant les tests, utilisez la même méthode pour extraire la matrice conceptuelle correspondante de la série chronologique d'entrée et effectuez une analyse comparative avec les matrices conceptuelles des échantillons normaux et des échantillons anormaux pour calculer les différences conceptuelles correspondantes. Si la similarité entre l’échantillon d’entrée et la matrice conceptuelle d’un mode de défaillance spécifique est élevée, l’échantillon peut être considéré comme appartenant à ce mode de défaillance.
Cette méthode est également discutée en détail dans les articles suivants :
Mingjing Xu, Piero Baraldi, Zhe Yang, Enrico Zio, A two-stage estimation method based on Conceptors-aided nonsupervised clustering and convolutional classification des réseaux neuronaux pour l'estimation du niveau de dégradation des équipements industriels, Expert Systems with Applications, Volume 213, Part B, 2023, 118962. Surveillance par chaîne lâche du compartiment batterie dans la station d'échange d'énergie
(1) Contexte
La chaîne du compartiment de batterie dans la station d'échange d'énergie coopère avec le palan du compartiment de batterie pour soulever les batteries entrantes vers le compartiment de charge pour les charger. Si la chaîne est défectueuse, elle risque de se desserrer, voire de se casser, ce qui risque de coincer la batterie lors du transport vers le bac de chargement et d'empêcher sa mise dans le bac. De plus, si la chaîne se brise, la batterie tombera, provoquant des dommages à la batterie, voire des incendies.
Par conséquent, il est nécessaire de construire un modèle pour détecter à l'avance le desserrage de la chaîne, prévenir à l'avance l'apparition d'accidents de sécurité associés et minimiser le risque.
(2) Définition du problème
Les variables directement liées au relâchement de la chaîne sont principalement des signaux liés aux vibrations. Cependant, le coût de la collecte et du stockage des données de vibration est élevé, de sorte que la plupart des équipements ne collectent pas. vibrations.
En cas de données de vibration manquantes, le relâchement de la chaîne peut être détecté grâce au couple, à la position, à la vitesse et à d'autres signaux du moteur d'entraînement de la chaîne.
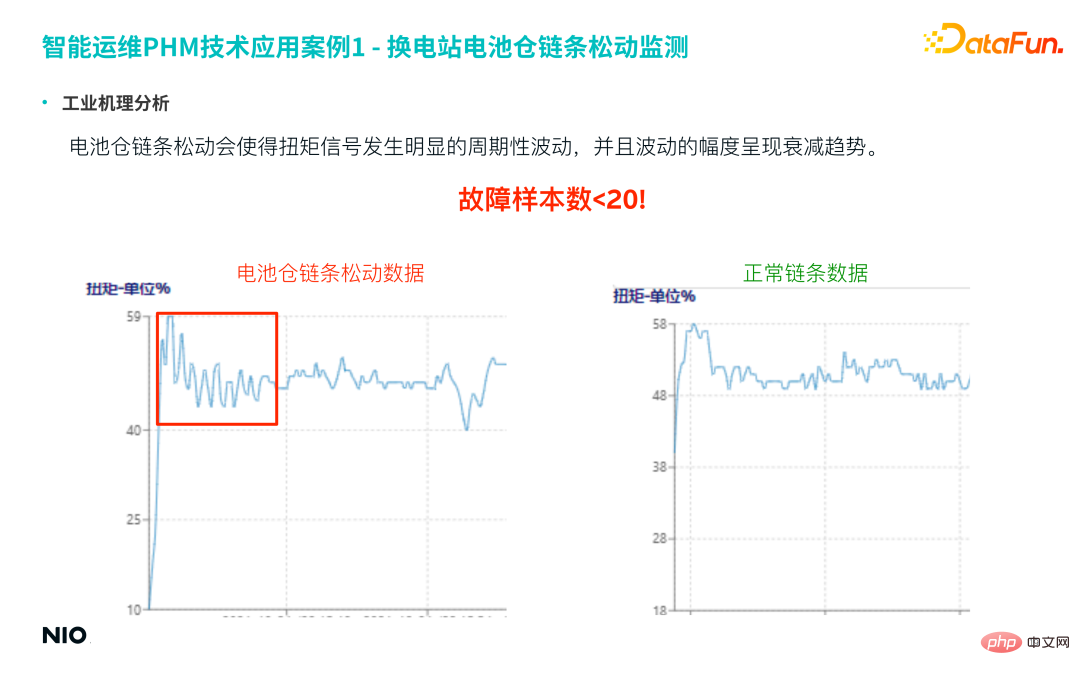
(3) Analyse du mécanisme industriel
En comparant les données de la chaîne lâche et les données de la chaîne normale dans la figure ci-dessous, on peut clairement voir que la chaîne lâche dans le compartiment de la batterie provoquera des fluctuations périodiques évidentes de le signal de couple, et l'amplitude des fluctuations montre une tendance d'atténuation.
Le nombre réel d'échantillons pour cette faille est très faible, moins de 20 échantillons cependant, ce type de faille est très important, donc la précision et le taux de rappel du modèle de prédiction sont très élevés.
(4) Conception du modèle de détection du relâchement de la chaîne
① Tout d'abord, divisez les données d'origine en séries chronologiques et extrayez les données de couple du processus uniforme pour la longue série chronologique.
② Décomposez ensuite la série temporelle et ne conservez que les caractéristiques de fluctuation de la série temporelle.
③ Effectuez ensuite une analyse spectrale sur la séquence et obtenez enfin les caractéristiques du spectre.
Cependant, il existe plus d'une bande de fréquences au moment de la panne, et les amplitudes dans différentes bandes de fréquences obéissent à des distributions spécifiques. Par conséquent, l'utilisation de méthodes traditionnelles pour les identifier a une faible précision et provoquera davantage de fausses alarmes. et alarme manquante. Par conséquent, le modèle AE-GAN est sélectionné pour capturer plus précisément la répartition spécifique des défauts en mode défaut, et enfin obtenir le score d'anomalie de l'équipement.
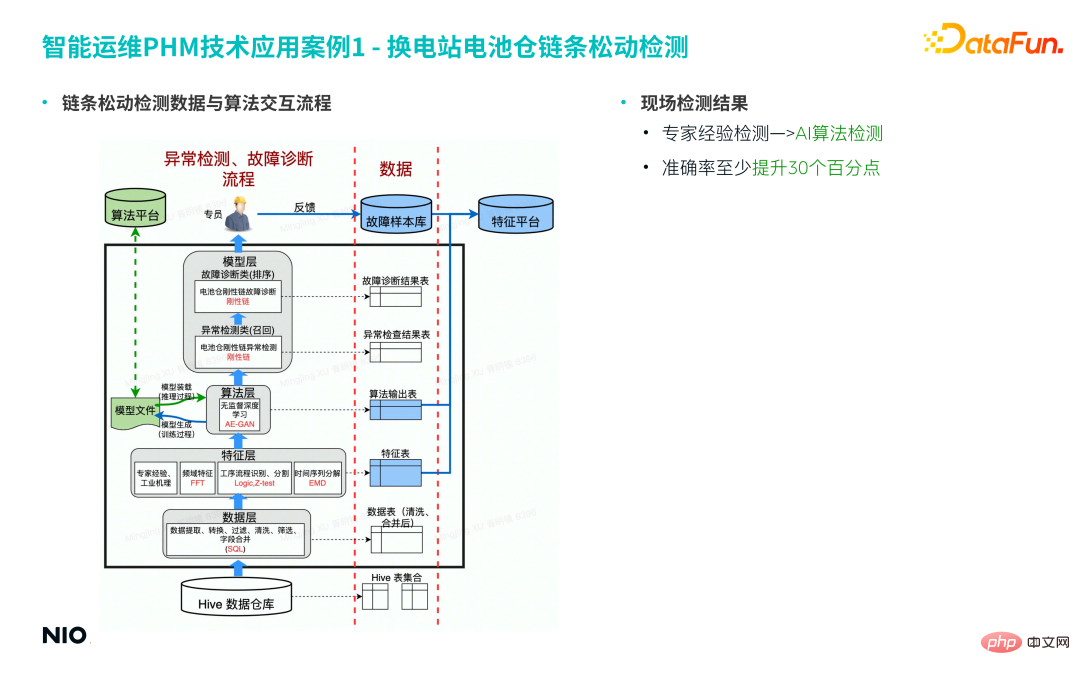
(5) Le processus d'interaction entre les données de détection du relâchement de la chaîne et l'algorithme
L'interaction entre les données de détection du relâchement et l'algorithme comprend principalement les couches suivantes : entrepôt de données, couche de données, couche de fonctionnalités, algorithme calque et calque modèle.
Parmi eux, la couche de fonctionnalités est principalement le module d'algorithme impliqué dans l'ingénierie des fonctionnalités mentionné ci-dessus. Dans ce cas, la couche d'algorithme utilise l'algorithme AE-GAN basé sur les résultats de score anormaux de la couche d'algorithme et les enregistrements de données ; le tableau des caractéristiques dans la couche de caractéristiques. D'autres jugements et décisions sont pris dans la couche modèle ; le bon de travail final est envoyé au spécialiste pour traitement ;
Sur la base du processus ci-dessus, la détection traditionnelle de l'expérience des experts est mise à niveau vers la détection par algorithme d'IA et le taux de précision est augmenté de plus de 30 %.
2. Diagnostic de défaut de détérioration de la pointe du pistolet à pile de surcharge
(1) Analyse du mécanisme industriel
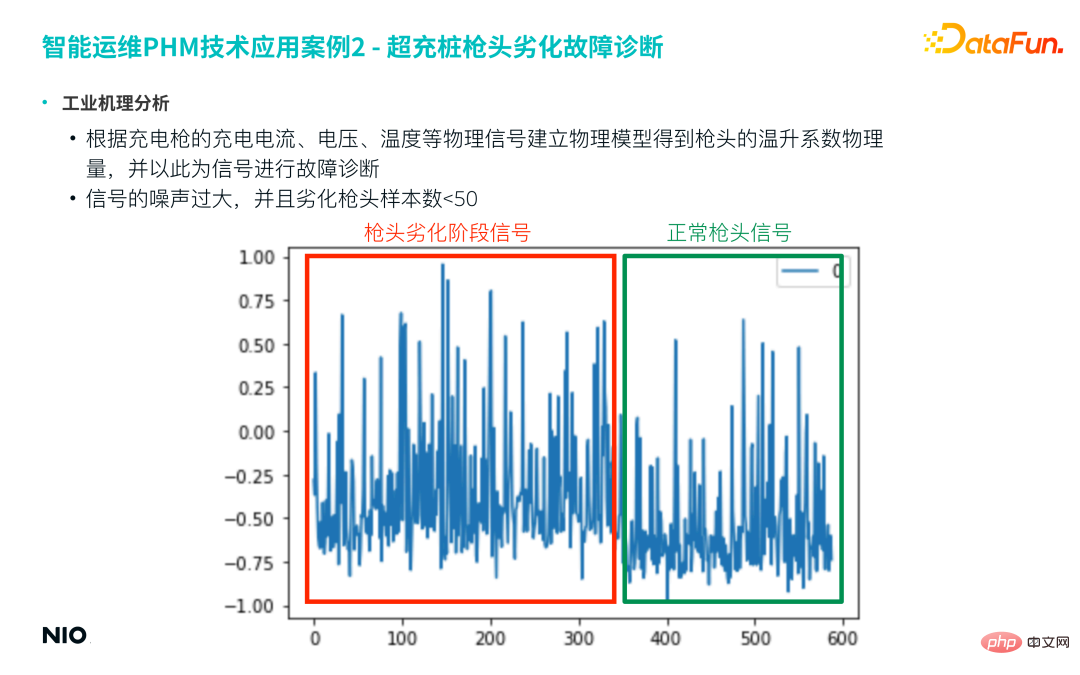
Tout d'abord, un modèle physique est établi en fonction du courant de charge, de la tension, de la température et d'autres signaux physiques de la charge. pistolet pour obtenir les caractéristiques de la pointe du pistolet. La quantité physique du coefficient d'élévation de température est utilisée comme signal caractéristique pour un diagnostic ultérieur des défauts. Cependant, ce type d'ingénierie de fonctionnalités basée sur la physique utilise généralement des fenêtres temporelles glissantes pour la génération de fonctionnalités et obtient finalement une nouvelle série temporelle car le résultat de ces fonctionnalités est souvent bruité ;
Prenons la figure suivante comme exemple. Ce projet sélectionne généralement une semaine ou un mois de données comme fenêtre temporelle pour obtenir une série chronologique caractéristique similaire à la figure ci-dessous. On peut voir sur la figure que le bruit de cette séquence est très important et qu'il est difficile de distinguer directement les échantillons dégradés des échantillons normaux.
De plus, dans les échantillons de pannes réelles, le nombre de pointes dégradées est souvent inférieur à 50.
Sur la base des deux raisons ci-dessus, le modèle Conceptor est introduit pour se débarrasser de l'expérience manuelle et capturer automatiquement les caractéristiques des séries chronologiques des échantillons dégradés via le modèle.
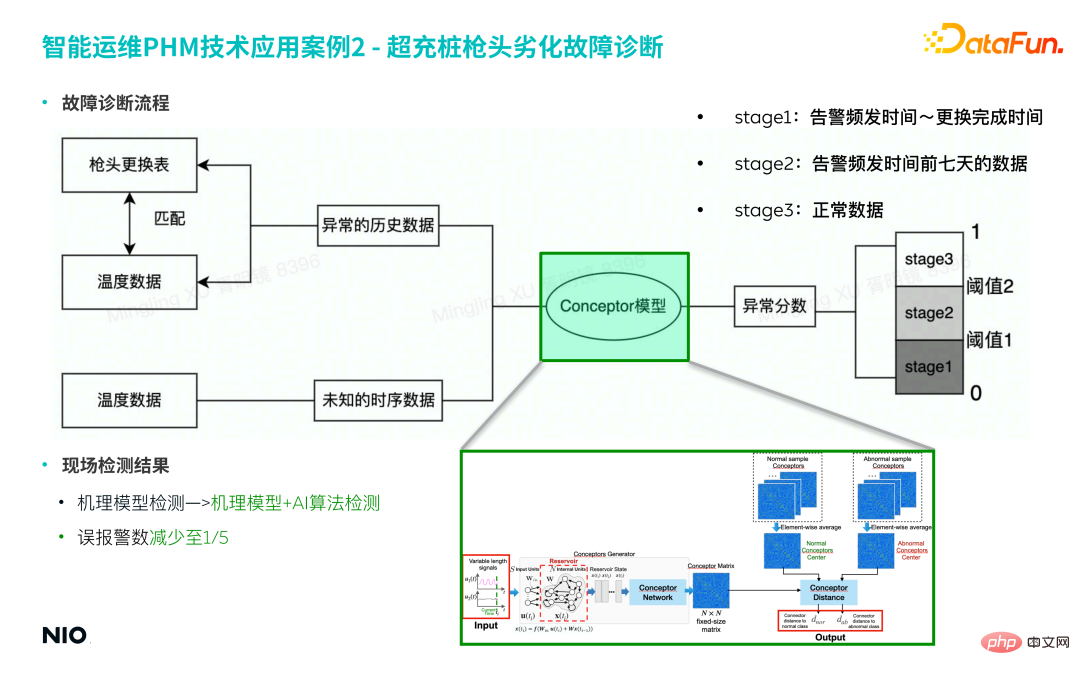
(2) Processus de diagnostic des défauts
① Collecter des données d'échantillon de défauts
- L'entreprise a mis en production des milliers de piles de surcharge, dont seulement des dizaines de piles de surcharge ont jamais été Remplacez la pointe du pistolet.
- Faites correspondre les données d'échantillon de défaut de la période correspondante en fonction de l'enregistrement de remplacement de la pointe du pistolet comme ensemble d'entraînement pour le modèle.
- Les données de défaut contiennent des séries temporelles en 6 dimensions et les longueurs des séries sont différentes.
② Construction du modèle
- Le mécanisme physique derrière cette faille est relativement complexe, donc la modélisation basée sur les connaissances préalables, l'expérience des experts et les mécanismes physiques est relativement difficile à mettre en œuvre, et le modèle est difficile à généraliser .
- La méthode du modèle Conceptor mentionnée dans cet article est basée sur une méthode purement basée sur les données et n'introduit aucune fonctionnalité d'extraction d'informations physiques préalable, ce qui peut réduire considérablement la complexité du modèle et améliorer l'efficacité de la modélisation.
- Utilisez la méthode du modèle Concepteur pour saisir les données de séries chronologiques multidimensionnelles de la période anormale dans le modèle afin d'obtenir la matrice de représentation conceptuelle correspondante.
a. Si vous saisissez 50 échantillons de défauts, vous obtiendrez 50 matrices de représentation de concepts
b Agrégez la moyenne de ces 50 matrices et multipliez-les par la matrice de représentation du mode de défaut ; . Centre de gravité, obtenez la matrice de représentation sous le mode défaut ;
c. Dans l'étape de test du modèle, calculez la matrice conceptuelle pour les données de test d'entrée, comparez-la avec la matrice de représentation du mode défaut ; puis obtenez le score d'anomalie.
③ Modèle d'alerte précoce
- 1) Sur la base des résultats du modèle, basés sur les règles d'alarme de 3 niveaux différents répartis à l'avance, des jugements sont portés selon différents degrés de détérioration, et enfin hiérarchisés précocement l'avertissement est obtenu.
Sur la base du processus ci-dessus, la méthode de détection du modèle de mécanisme traditionnel est mise à niveau vers un modèle de mécanisme combiné à la méthode de détection de l'algorithme d'IA, ce qui peut réduire le taux de fausses alarmes du modèle à 1/5 de l'original.
6. Séance de questions et réponses
Q1 : Dans le modèle AE-GAN, comment distinguer les échantillons normaux des échantillons anormaux ?
A1 : Pour le modèle AE-GAN entraîné, saisissez un échantillon dans l'auto-encodeur et obtenez l'erreur de reconstruction de l'échantillon, qui est le score d'anomalie si le score est inférieur au seuil spécifié, l'échantillon ; est considéré comme normal, et vice versa pour les échantillons anormaux. Le principe de l'utilisation de cette méthode est que toutes les données d'entraînement sont des exemples de données normales.
Q2 : Lors de la formation du réseau GAN, utilisez-vous un mélange de petits échantillons de données de panne et de données normales ? Comment équilibrer les deux données ?
A2 : Lors de la formation du réseau GAN, des données normales ou des données anormales dans un mode spécifique ne sont pas utilisées pour la formation, donc des problèmes tels qu'un déséquilibre d'échantillon ne se produiront pas. S'il existe un écart énorme entre les deux types d'échantillons de données dans les données réelles, un réseau GAN 1 sera généralement formé pour des échantillons normaux, puis un réseau GAN 2 sera formé pour un certain modèle fixe d'échantillons anormaux, et le les échantillons de test seront testés sur la base des erreurs de reconstruction des deux réseaux. Jugement final.
Q3 : L'effondrement du modèle se produira-t-il pendant la formation GAN ?
A3 : L'effondrement du mode est le problème principal rencontré dans la formation du modèle GAN. Premièrement, comprenez l’effondrement du mode et, deuxièmement, concentrez-vous sur les tâches principales de la formation GAN.
Mode effondrement est que les données générées par le générateur se concentrent sur une zone spécifique ; la raison en est que la définition de la fonction de perte dans le réseau GAN est ignorée. Au cours du processus de formation du réseau GAN, la perte du réseau G et la perte du réseau D sont généralement calculées séparément, et la fonction de perte conjointe des deux réseaux (c'est-à-dire la perte JSD dans la formule) est souvent ignorée. Si un effondrement du mode d'entraînement se produit, la perte JSD ne converge souvent pas ; par conséquent, la visualisation de la perte JSD pendant l'entraînement peut efficacement éviter l'effondrement du mode. C'est également la raison pour laquelle de nombreuses versions améliorées récentes des modèles GAN ont pu se démarquer et produire de meilleurs résultats. De plus, l'introduction d'astuces spécifiques dans les réseaux GAN standard peut également produire des effets similaires ;
Q4 : Quels sont les avantages de réparer aléatoirement la couche cachée de RNN ?
A4 : Pour les scénarios où il existe une énorme disparité entre les échantillons positifs et négatifs, si vous utilisez les modèles LSTM, RNN, GRNN et autres couramment utilisés, vous serez souvent confronté au problème de non-convergence de la fonction de perte ; par conséquent, la manière de traiter de tels problèmes est souvent non supervisée. À partir de l'apprentissage, le poids de la couche cachée du réseau principal est fixé de manière aléatoire et une méthode spécifique est utilisée pour régulariser les composants caractéristiques de la matrice conceptuelle générée ; Le paramètre de poids est aléatoire, les composants de représentation obtenus peuvent refléter les caractéristiques cachées de la série chronologique. Il suffit de distinguer de petits échantillons de scènes. Ce qui précède est l'avantage de la fixation aléatoire de la couche cachée RNN.
Q5 : Présentez la forme réseau du modèle Conceptor.
A5 : Le modèle est présenté dans l'image ci-dessous.
Parmi eux, la partie Réserve est fondamentalement la même que le réseau RNN ordinaire, la seule différence est que Win et W sont définis aléatoirement ( notez qu'ils ne sont générés qu'une seule fois de manière aléatoire ); par la suite, l'état caché du neurone à chaque pas de temps est calculé et mis à jour, et la matrice conceptuelle correspondante est obtenue. Ce qui précède est la version complète de Conceptor.
Q6 : Quel est le processus de formation du réseau Encoder dans AE-GAN ? Que sont l’entrée et la sortie ?
A6 : La figure ci-dessous est le processus de formation du réseau Encoder.
Tout d'abord, un GAN standard est formé, et sur cette base, les paramètres de la couche cachée dans le réseau G sont fixés puis un réseau Encoder est inséré devant le réseau G, et le deux réseaux sont connectés pour former un réseau Auto-Encoder. L'entrée du réseau Auto-Encoder est l'échantillon de données d'origine et la sortie est l'échantillon de données reconstruit. Le réseau AE-GAN identifie les données anormales en construisant des échantillons reconstruits.
Q7 : Existe-t-il des documents et des codes open source associés pour les deux méthodes décrites dans l'article ?
A7 : Veuillez consulter les chapitres pertinents de l'article pour plus de détails. Le code n'est pas encore open source.
Q8 : AE-GAN peut-il être utilisé pour la détection d'anomalies dans le champ de l'image ?
A8 : Il peut être utilisé. Cependant, par rapport aux signaux ordinaires, le champ d'image a des dimensions plus élevées, une distribution de données plus complexe et une plus grande quantité de données nécessaires à la formation. Par conséquent, s'il est utilisé pour la classification d'images et qu'il y a peu d'échantillons de données, l'effet du modèle sera compromis ; s'il est utilisé pour la détection d'anomalies, l'effet est toujours bon ;
Q9 : Quels sont les indicateurs d'évaluation pour la détection des anomalies ? Faux positifs et faux négatifs, et les deux évalués ensemble.
A9 : Les indicateurs d'évaluation les plus intuitifs sont le taux de faux positifs et le taux de faux négatifs. Des indicateurs plus scientifiques incluent le taux de rappel, le taux de précision, le score F, etc.
Q10 : Comment faire correspondre les caractéristiques des échantillons de défauts ?
A10 : S'il n'existe pas de moyen plus direct et plus rapide d'obtenir des caractéristiques de faille, une méthode purement basée sur les données est généralement utilisée pour extraire des échantillons de caractéristiques de faille. Généralement, un réseau d'apprentissage en profondeur est construit pour apprendre les caractéristiques clés de. des échantillons de défauts et est caractérisé comme une matrice conceptuelle.
Q11 : Comment l'algorithme PHM effectue-t-il la sélection du modèle ?
A11 : Pour un petit nombre d'échantillons, la méthode RNN non supervisée est généralement utilisée pour caractériser les caractéristiques des données. S'il existe un grand nombre d'échantillons normaux pour des problèmes de détection d'anomalies, le réseau AE-GAN peut être utilisé pour. mettre en œuvre.
Q12 : Comment identifier les anomalies à travers les deux types de matrices conceptuelles produites par RNN ?
A12 : La matrice conceptuelle produite par RNN peut être comprise comme l'ensemble de toutes les caractéristiques de la série temporelle d'entrée puisque les caractéristiques des données dans le même état sont similaires, la matrice conceptuelle de tous les échantillons dans cet état est ; moyenné et agrégé, c'est-à-dire faire abstraction de la matrice du centre de concepts dans ce type d'état pour la série temporelle d'entrée de l'état inconnu, en calculant sa matrice de concepts et en la comparant avec la matrice du centre de concepts, la matrice du centre de concepts avec la plus grande similarité ; est la catégorie correspondant aux données d’entrée.
Q13 : Comment définir le seuil d'anomalie dans le réseau AE-GAN ?
A13 : Après avoir terminé la formation réseau, utilisez un petit lot d'échantillons de données normaux pour calculer l'erreur de reconstruction et prenez la valeur maximale comme seuil.
Q14 : Le seuil d'anomalie dans le réseau AE-GAN sera-t-il mis à jour ?
A14 : Généralement, il ne sera pas mis à jour, mais si la distribution des données d'origine change (comme les conditions de fonctionnement, par exemple), le seuil devra peut-être être recyclé et des méthodes liées à l'apprentissage par transfert peuvent même être introduites dans le GAN. réseau. Affinez le seuil.
Q15 : Comment GAN forme-t-il les séries chronologiques ?
A15 : GAN n'entraîne généralement pas la série chronologique d'origine, mais entraîne les fonctionnalités extraites en fonction de la série chronologique d'origine.
Q16 : Par rapport au GAN traditionnel, quel est le rôle de l'introduction du GAN dans AE-GAN ? Quelles améliorations peuvent être obtenues ?
A16 : Le GAN traditionnel est également souvent utilisé pour la détection d'anomalies. AE-GAN a une analyse plus approfondie des principes du GAN, de sorte qu'il peut également éviter au maximum des problèmes tels que l'effondrement du mode et l'introduction de l'Auto-Encoder peut garantir que le principe de détection des anomalies est exécuté avec précision ; réduisant ainsi le taux de fausses alarmes.
Q17 : Y aura-t-il une augmentation globale des données de séries chronologiques des bornes de recharge pendant les vacances ? Comment éviter les erreurs de jugement ?
A17 : Le modèle de diagnostic de pannes est divisé en plusieurs niveaux. Les résultats de la couche modèle ne sont que la base de la couche décisionnelle et ne sont pas les résultats finaux. Ils sont généralement combinés avec d'autres logiques métier pour aider. jugement.
Q18 : Après le lancement du modèle, comment évaluer l'effet d'application de la détection d'anomalies non supervisée ?
A18 : Généralement sur la base des résultats de détection d'anomalies, des spécialistes techniques seront désignés pour confirmer sur la scène réelle.
Q19 : Essayez-vous d'utiliser les deux méthodes mentionnées dans l'article pour détecter des anomalies dans les batteries des stations d'échange de batteries ?
A19 : Des tentatives similaires sont en cours.
Q20 : Comment unifier la longueur des données de séries chronologiques ? Le remplissage avec 0 empêchera-t-il le dégradé de baisser ?
A20 : Le modèle Conceptor mentionné dans l'article peut gérer des séries temporelles de n'importe quelle longueur, il n'est donc pas nécessaire de remplir des 0, et il évite également le processus de "formation" des paramètres, ce qui permet d'éviter de tels problèmes.
Q21 : GAN souffera-t-il de surapprentissage ?
A21 : S'il n'est utilisé que dans le domaine de la détection d'anomalies, en effet, plus il y a de « surajustement », meilleures seront les performances du modèle. De plus, en raison du grand caractère aléatoire du réseau G du modèle GAN pendant le processus de formation, le surajustement ne se produit généralement pas.
Q22 : Lors de la formation d'un modèle GAN, quel est l'ordre de grandeur des données de formation utilisées ? Quel est le paramètre général pour obtenir de meilleurs résultats ?
A22 : Ce type de problème dépend généralement de la taille du réseau de neurones, des dimensions des neurones cachés, etc. De manière générale, pour un réseau neuronal à 2 couches avec 100 neurones par couche, le volume des données d'entraînement doit être de 1 à 2 ordres de grandeur supérieur à la dimension de la couche cachée afin d'obtenir de meilleurs résultats. il est également nécessaire d'utiliser quelques astuces pour éviter l'effondrement du mode.
Q23 : Les paramètres minimum unitaires cachés dans le modèle Conceptor sont fixes. Sont-ils définis sur la base de l'expérience d'un expert ? Comment le biais se compare-t-il à un RNN normal ? Quel est le volume d’étiquettes pour l’analyse des défaillances ? Comment quantifier la valeur commerciale ?
A23 : De nombreux modèles Conceptor actuellement en ligne utilisent le même ensemble de paramètres empiriques sans ajustement supplémentaire des paramètres. Selon l'expérience pratique, le réglage des paramètres pertinents de 10 à 100 a peu d'impact sur les résultats. La seule différence est le coût de calcul. . Si la taille de l'échantillon des données de défaut est petite et que vous souhaitez que les résultats soient plus précis, vous pouvez définir les paramètres sur 128, 256 ou même plus. En conséquence, le coût de calcul sera plus élevé. Le nombre d'étiquettes pour l'analyse des défauts est généralement compris entre 1 et 10. La quantification de la valeur commerciale est généralement mesurée par les fausses alarmes et les alarmes manquées, car les fausses alarmes et les alarmes manquées peuvent être directement converties en impacts quantitatifs sur la valeur commerciale.
Q24 : Comment déterminer l'heure de démarrage du défaut, la précision et le taux de rappel ?
A24 : La méthode Concepteur peut être utilisée pour former plusieurs matrices de concepts en utilisant des fenêtres de croissance temporelle ; et le regroupement spectral des matrices de concepts peut être utilisé pour déterminer le moment d'apparition du défaut. Voir les articles connexes dans le chapitre Concepteur pour plus de détails.
Q25 : Un grand nombre de données normales ont-elles la même valeur ? Le modèle apprendra-t-il les mêmes échantillons à plusieurs reprises ?
A25 : Dans des scénarios réels, en raison des différentes conditions de fonctionnement des équipements, les données normales varient souvent considérablement.
Q26 : Quelles caractéristiques de défauts conviennent au GAN et quelles caractéristiques de défauts conviennent au RNN ?
A26 : Il est difficile de diviser clairement les scénarios d'utilisation spécifiques de ces deux modèles ; d'une manière générale, le GAN est meilleur pour résoudre de tels problèmes avec une distribution de données spéciale et difficile à caractériser par des réseaux de classification, tandis que le RNN non supervisé est plus approprié. pour traiter des problèmes sur de petits échantillons.
Q27 : Le modèle mentionné dans cet article peut-il être utilisé dans des scénarios spéciaux tels que la « détection de violation du personnel » ?
A27 : Pour les scénarios spécifiques à un domaine, si des connaissances spécifiques à un domaine peuvent être introduites pour extraire des fonctionnalités d'ordre élevé, cela est généralement possible si seules des images sont utilisées pour la détection, si la taille de l'échantillon d'image est grande et peut représentent un comportement normal, alors le problème peut être transformé en détection de scène de segmentation de domaine CV, qui peut être détectée à l'aide du modèle mentionné dans cet article.
Q28 : Concepteur Distance est-il un jugement de similarité ? Est-ce que ça s'apprend avec des paramètres ?
A28 : C'est sans paramètre.
Q29 : Dois-je entraîner un modèle pour chaque défaut ?
A29 : Cela dépend du scénario spécifique, y compris les exigences du modèle, la taille de l'échantillon de défauts, la complexité de la distribution, etc. Si la similarité des formes d'onde temporelles de deux défauts est très élevée, il n'est généralement pas nécessaire de former un modèle distinct. Il vous suffit de créer un modèle multi-classification pour déterminer la limite de classification si les données forment les deux modes de défaut. sont très différents, vous pouvez utiliser le modèle GAN pour mettre à jour les données.
Q30 : Quel est le temps et le coût de formation du modèle ?
A30 : Le modèle Conceptor a un coût de formation très faible et peut être utilisé pour extraire des fonctionnalités ; le temps de formation du modèle GAN est relativement plus long, mais pour les données tabulaires structurées courantes, le temps de formation ne sera pas trop long.
Q31 : Lors de l'entraînement du modèle, à quoi ressemble l'ensemble d'entraînement des échantillons normaux ? Lors du découpage de fenêtres coulissantes de séries chronologiques, existe-t-il un nombre minimum de fois recommandé pour chaque sous-ensemble de séries chronologiques ?
A31 : Les deux modèles eux-mêmes n'ont aucune exigence concernant le nombre d'échantillons positifs et négatifs ; compte tenu du temps de formation du modèle, des milliers d'échantillons représentatifs sont généralement sélectionnés pour la formation. Il n'y a généralement pas de recommandation de nombre minimum pour le nombre de fois dans un sous-ensemble de synchronisation.
Q32 : Quelle est la dimension approximative de la matrice de caractéristiques obtenue par le réseau RNN ?
A32 : La dimension de la matrice de caractéristiques est directement liée au nombre de neurones cachés. S'il y a N neurones cachés, la dimension de la matrice de caractéristiques est N×N. Compte tenu de la complexité du modèle et de l'efficacité du calcul, N n'est généralement pas trop grand et une valeur de réglage couramment utilisée est 32.
Q33 : Pourquoi ne pas utiliser le discriminateur du GAN comme classificateur ? Le discriminateur n'apprend que les données normales et les données anormales seront classées comme fausses données. Quels sont les inconvénients de cette approche ?
A33 : Selon le principe du GAN, le réseau D est utilisé pour distinguer les échantillons normaux et les faux échantillons ; si les faux échantillons sont entraînés à un état de « corps complet », ils seront très proches des échantillons normaux, ce qui en fera Il est difficile de distinguer les échantillons normaux des échantillons anormaux et le réseau AE-GAN suppose que les échantillons normaux et les échantillons anormaux ont un certain degré de discrimination, ce qui constitue la base théorique de l'utilisation d'AE-GAN.
Q34 : Comment le modèle d'apprentissage sur petits échantillons garantit-il la capacité de généralisation ?
A34 : La capacité de généralisation du modèle doit être basée sur une hypothèse a priori : toutes les failles du même type ont une distribution de données similaire. Si la distribution de données de défauts similaires est très différente, il est généralement nécessaire de subdiviser davantage les catégories de défauts pour garantir la capacité de généralisation du modèle.
Q35 : Comment effectuer un prétraitement des données sur les données d'entrée ?
A35 : Pour les deux modèles mentionnés dans l'article, les données doivent seulement être normalisées.
Q36 : Comment le GAN se compare-t-il aux directions traditionnelles non supervisées telles que la forêt d'isolement et l'AE ?
A36 : Grâce à l'exhaustivité de la théorie, GAN peut décrire plus complètement la distribution des échantillons de données normaux, construisant ainsi une limite de décision plus complète. Cependant, les méthodes telles que l'AE ordinaire, la forêt isolée et le SVM à une classe n'ont pas d'exhaustivité théorique et ne peuvent pas construire une limite de décision plus complète.
Q37 : Si le discriminateur peut à peine faire la distinction entre les échantillons normaux et les faux échantillons à un stade ultérieur, alors la partie GAN aura peu d'importance. AE-GAN dégénérera-t-il en AE à ce moment-là ?
A37 : Si le discriminateur est effectivement incapable d'identifier les échantillons normaux et les faux échantillons, on voit de côté que l'entraînement du générateur est très réussi dans l'étape de détection des anomalies, seul le générateur est utilisé et ; le discriminateur n’est pas utilisé. Le générateur du réseau GAN est d'une grande importance, donc AE-GAN ne dégénérera pas en AE. Il peut être compris comme une version améliorée d'AE, qui est un AE régularisé.
Q38 : Avez-vous essayé d'utiliser Transformer au lieu de RNN ?
A38 : Dans les scénarios avec de petits échantillons et des exigences d'interprétabilité élevées, aucune tentative de ce type n'a encore été effectuée et des tentatives similaires pourraient être faites ultérieurement.
Q39 : Quelle est la différence entre AE-GAN et VAE ?
A39 : VAE est également une méthode couramment utilisée pour la détection d'anomalies. VAE utilise une distribution gaussienne antérieure dans la couche cachée et modifie la forme de la distribution gaussienne antérieure pour l'adapter aux données réelles, rendant les deux distributions équivalentes ; cependant, VAE utilise la fonction de perte est la divergence KL au lieu de la divergence JSD, et la divergence KL est asymétrique et peut ne pas fonctionner correctement dans des exemples complexes.
Q40 : Y aura-t-il un bruit de données important ou manquant dans les caractéristiques du signal pendant l'expérience ? Quelles sont les meilleures méthodes de nettoyage des fonctionnalités ?
A40 : Le boîtier du pistolet de chargement dans l'article est un cas de bruit important. Certaines méthodes de décomposition basées sur des séries chronologiques peuvent décomposer les éléments périodiques, les éléments de tendance, les éléments de bruit, etc. dans la série chronologique, les caractéristiques manquantes peuvent être traitées à l'aide de méthodes de données incomplètes.
Q41 : Des stratégies d'amélioration telles que l'APA peuvent-elles être ajoutées à la formation ?
A41 : En prenant GAN comme exemple, l'amélioration des échantillons est principalement réalisée en ajoutant du bruit, et la stratégie d'amélioration APA n'est pas utilisée.
Q42 : Dans la deuxième étape de 4.1.(3), si la plage normale s'étend sur un grand intervalle, s'il y a 3 échantillons 1, 2 et 3, les échantillons 1 et 2 sont des échantillons normaux et l'échantillon 3 est des échantillons anormaux ; l'échantillon 1 et l'échantillon 2 sont situés des deux côtés de la plage normale, et l'échantillon 3 est situé non loin de l'échantillon 1 mais a dépassé la plage normale. L'erreur de reconstruction entre les échantillons 1 et 2 sera alors supérieure à. celle des échantillons 1 et 3 ?
A42 : Les références fournies dans cet article contiennent de nombreux exemples extrêmes. Par exemple, l'exemple que vous avez cité est un exemple typique de boule à deux gaussiennes. AE-GAN peut résoudre ce type de problème.
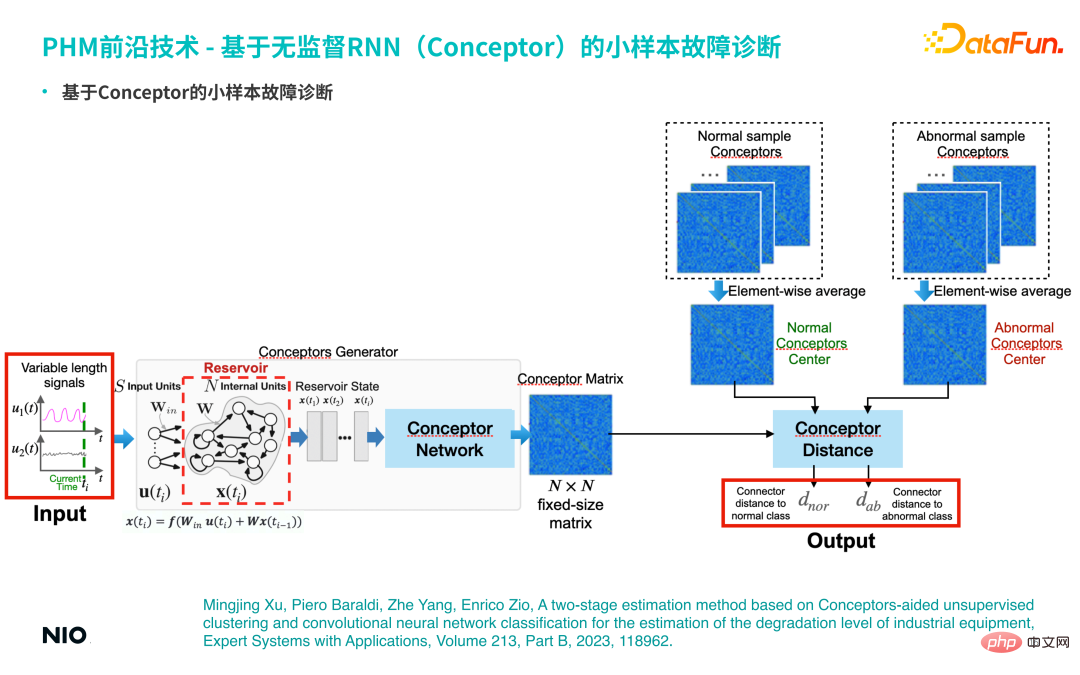 S'il existe un petit nombre d'échantillons de défauts réels (par exemple, il y a moins de 10 échantillons de défauts), toutes les séries temporelles correspondantes sont entrées dans le réseau Conceptor et agrégées pour former le correspondant matrice de concepts, comme la faute de cette catégorie Représentation abstraite des modèles ; de même, les échantillons normaux seront agrégés dans une matrice de concepts normale. Pendant les tests, utilisez la même méthode pour extraire la matrice conceptuelle correspondante de la série chronologique d'entrée et effectuez une analyse comparative avec les matrices conceptuelles des échantillons normaux et des échantillons anormaux pour calculer les différences conceptuelles correspondantes. Si la similarité entre l’échantillon d’entrée et la matrice conceptuelle d’un mode de défaillance spécifique est élevée, l’échantillon peut être considéré comme appartenant à ce mode de défaillance.
S'il existe un petit nombre d'échantillons de défauts réels (par exemple, il y a moins de 10 échantillons de défauts), toutes les séries temporelles correspondantes sont entrées dans le réseau Conceptor et agrégées pour former le correspondant matrice de concepts, comme la faute de cette catégorie Représentation abstraite des modèles ; de même, les échantillons normaux seront agrégés dans une matrice de concepts normale. Pendant les tests, utilisez la même méthode pour extraire la matrice conceptuelle correspondante de la série chronologique d'entrée et effectuez une analyse comparative avec les matrices conceptuelles des échantillons normaux et des échantillons anormaux pour calculer les différences conceptuelles correspondantes. Si la similarité entre l’échantillon d’entrée et la matrice conceptuelle d’un mode de défaillance spécifique est élevée, l’échantillon peut être considéré comme appartenant à ce mode de défaillance. (2) Définition du problème

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI