
Maison >Périphériques technologiques >IA >AI large base, la réponse à l'ère des grands modèles
AI large base, la réponse à l'ère des grands modèles

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-11 16:25:271074parcourir
1. La naissance de Wen Xinyiyan
"Wen Xinyiyan a suivi une formation sur le plus grand cluster GPU haute performance dans le domaine de l'IA du pays."
Dès juin 2021, afin de répondre aux besoins des futurs grands modèles Pour la formation tâches, Baidu Intelligent Cloud a commencé à planifier la construction d'un nouveau cluster GPU hautes performances. En collaboration avec NVIDIA, il a achevé la conception d'une architecture réseau IB pouvant accueillir plus de 10 000 cartes. Chaque carte GPU entre les nœuds du cluster est connectée. via le réseau IB, et la construction du cluster sera achevée en avril 2022, fournissant une puissance de calcul de niveau EFLOPS à un seul cluster.
En mars 2023, Wen Xinyiyan est né sur ce cluster haute performance et continue d'itérer de nouvelles capacités. Actuellement, la taille de ce cluster continue de croître.
Dr. Junjie Lai, directeur général des solutions et de l'ingénierie chez NVIDIA Chine : les clusters GPU interconnectés par des réseaux IB à haut débit sont une infrastructure clé à l'ère des grands modèles. Le plus grand cluster GPU/IB hautes performances sur le marché national du cloud computing, construit conjointement par NVIDIA et Baidu Intelligent Cloud, accélérera la plus grande percée de Baidu dans le domaine des grands modèles.
2. Conception de cluster haute performance
Un cluster haute performance n'est pas une simple accumulation de puissance de calcul. Il nécessite également une conception et une optimisation spéciales pour faire ressortir la puissance de calcul globale du cluster.
Dans la formation distribuée, les GPU communiqueront en permanence entre et au sein des machines. Tout en utilisant des réseaux hautes performances tels que IB et RoCE pour fournir des services à haut débit et à faible latence pour la communication inter-machines, il est également nécessaire de concevoir spécialement les connexions réseau internes des serveurs et la topologie de communication dans le réseau de cluster pour répondre aux exigences de communication des exigences de formation des grands modèles.
Pour parvenir à une optimisation ultime de la conception, il faut une compréhension approfondie de ce que chaque opération de la tâche d'IA signifie pour l'infrastructure. Différentes stratégies parallèles dans la formation distribuée, c'est-à-dire comment diviser les modèles, les données et les paramètres, produiront différentes exigences en matière de communication de données. Par exemple, le parallélisme des données et le parallélisme des modèles introduiront un grand nombre d'opérations Allreduce intra-machine et inter-machine. respectivement, et le parallélisme expert produira des opérations All2All inter-machines, le parallélisme hybride 4D introduira des opérations de communication générées par diverses stratégies parallèles.
À cette fin, Baidu Smart Cloud optimise la conception des serveurs autonomes et des réseaux de cluster pour créer des clusters GPU hautes performances.
En termes de serveurs autonomes, le super ordinateur IA X-MAN de Baidu Smart Cloud a désormais évolué vers sa quatrième génération. X-MAN 4.0 établit une communication inter-cartes hautes performances pour les GPU, fournissant 134 Go/s de bande passante Allreduce au sein d'une seule machine. Il s'agit actuellement du produit serveur de Baidu avec le plus haut degré de personnalisation et les matériaux les plus spécialisés. Dans la liste MLCommons 1.1, X-MAN 4.0 se classe TOP2 en termes de performances matérielles autonomes avec la même configuration.
En termes de réseau de cluster, une architecture Clos à trois couches optimisée pour la formation de grands modèles est spécialement conçue pour assurer les performances et l'accélération du cluster lors des formations à grande échelle. Par rapport à la méthode traditionnelle, cette architecture a été optimisée avec huit rails pour minimiser le nombre de sauts dans la communication entre toute carte portant le même numéro dans différentes machines, et prend en charge le fonctionnement Allreduce de la même carte avec la plus grande proportion de trafic réseau dans la formation en IA. Services réseau à haut débit et à faible latence.
Cette architecture réseau peut prendre en charge des clusters à très grande échelle avec un maximum de 16 000 cartes. Cette échelle est la plus grande échelle de tous les réseaux de boîtiers réseau IB à ce stade. Les performances du réseau du cluster sont stables et cohérentes à un niveau de 98 %, ce qui est proche d'un état de communication stable. Vérifiés par l'équipe d'algorithmes de grands modèles, des centaines de milliards de tâches de formation de modèles ont été soumises sur ce cluster à très grande échelle, et l'efficacité globale de la formation pour la même taille de machine était 3,87 fois supérieure à celle du cluster de génération précédente.
Cependant, la création de clusters hétérogènes à grande échelle et hautes performances n'est que la première étape pour réussir la mise en œuvre de grands modèles. Pour garantir la réussite des tâches de formation de grands modèles d’IA, une optimisation plus systématique des logiciels et du matériel est nécessaire.
3. Les défis de la formation sur les grands modèles
Au cours des dernières années, la taille des paramètres des grands modèles augmentera de 10 fois chaque année. Vers 2020, un modèle comportant des centaines de milliards de paramètres sera considéré comme un grand modèle. D’ici 2022, il faudra déjà des centaines de milliards de paramètres pour être appelé un grand modèle.
Avant les grands modèles, la formation d'un modèle d'IA était généralement suffisante avec une seule carte sur une seule machine ou plusieurs cartes sur une seule machine. Le cycle de formation variait de quelques heures à plusieurs jours. Désormais, afin de compléter la formation de grands modèles avec des centaines de milliards de paramètres, la formation distribuée sur de grands clusters avec des centaines de serveurs et des milliers de cartes GPU/XPU est devenue indispensable, et le cycle de formation a également été étendu à plusieurs mois.
Afin d'entraîner GPT-3 avec 175 milliards de paramètres (300 milliards de données de jetons), 1 bloc d'A100 prend 32 ans avec un calcul de performance maximale à demi-précision, et 1024 blocs d'A100 prennent 34 jours avec une utilisation des ressources de 45 %. Bien entendu, même si le temps n'est pas pris en compte, un A100 ne peut pas entraîner un modèle avec une échelle de paramètres de 100 milliards, car les paramètres du modèle ont dépassé la capacité mémoire d'une seule carte.
Pour effectuer une formation sur de grands modèles dans un environnement de formation distribué, le cycle de formation est raccourci de plusieurs décennies à des dizaines de jours pour une seule carte. Il est donc nécessaire de surmonter divers défis tels que les murs informatiques, les murs de mémoire vidéo et les murs de communication. que toutes les ressources du cluster peuvent être pleinement utilisées pour accélérer le processus de formation et raccourcir le cycle de formation.
Le mur de calcul fait référence à l'énorme différence entre la puissance de calcul d'une seule carte et la puissance de calcul totale du modèle. L'A100 dispose d'une puissance de calcul sur une seule carte de seulement 312 TFLOPS, tandis que le GPT-3 nécessite une puissance de calcul totale de 314 ZFLOP, soit une différence de 9 ordres de grandeur.
Le mur de mémoire vidéo fait référence au fait qu'une seule carte ne peut pas stocker complètement les paramètres d'un grand modèle. Les 175 milliards de paramètres du GPT-3 nécessitent à eux seuls 700 Go de mémoire vidéo (chaque paramètre est calculé sur 4 octets), tandis que le GPU NVIDIA A100 ne dispose que de 80 Go de mémoire vidéo.
L'essence du mur informatique et du mur de mémoire vidéo est la contradiction entre la capacité limitée d'une seule carte et les énormes exigences de stockage et de calcul du modèle. Cela peut être résolu grâce à une formation distribuée, mais après une formation distribuée, vous rencontrerez le problème du mur de communication.
Mur de communication, principalement parce que chaque unité de calcul du cluster nécessite une synchronisation fréquente des paramètres dans le cadre d'une formation distribuée, et les performances de communication affecteront la vitesse de calcul globale. Si le mur de communication n’est pas bien géré, il est probable que le cluster s’agrandisse et que l’efficacité de la formation diminue. Le franchissement réussi du mur de communication se reflète dans la forte évolutivité du cluster, c'est-à-dire que la capacité d'accélération multi-cartes du cluster correspond à l'échelle. Le taux d'accélération linéaire de plusieurs cartes est un indicateur permettant d'évaluer les capacités d'accélération de plusieurs cartes dans un cluster. Plus la valeur est élevée, mieux c'est.
Ces murs commencent à apparaître lors des entraînements multi-machines et multi-cartes. À mesure que les paramètres du grand modèle deviennent de plus en plus grands, la taille du cluster correspondant devient également de plus en plus grande et ces trois murs deviennent de plus en plus hauts. Dans le même temps, lors de la formation à long terme de grands clusters, des pannes d'équipement peuvent survenir, ce qui peut affecter ou interrompre le processus de formation.
4. Le processus de formation des grands modèles
De manière générale, du point de vue de l'infrastructure, l'ensemble du processus de formation des grands modèles peut être grossièrement divisé en deux étapes :
Phase 1 : Stratégie parallèle et optimisation de la formation
Soumettre à la formation Après avoir construit le grand modèle, le cadre d'IA examinera de manière exhaustive des informations telles que la structure du grand modèle et les capacités du cluster de formation, formulera une stratégie de formation parallèle pour cette tâche de formation et complétera l'IA. placement des tâches. Ce processus consiste à démonter le modèle et à placer la tâche, c'est-à-dire comment désassembler le grand modèle et comment placer les pièces démontées dans chaque GPU/XPU du cluster.
Pour les tâches d'IA destinées à s'exécuter dans GPU/XPU, le framework d'IA entraînera conjointement le cluster à effectuer une optimisation de lien complet au niveau de l'exécution d'une carte unique et de la communication du cluster, accélérant ainsi l'efficacité opérationnelle de chaque tâche d'IA pendant l'exécution. processus de formation de grands modèles, y compris le chargement des données, le calcul de l'opérateur, la stratégie de communication, etc. Par exemple, les opérateurs ordinaires exécutant des tâches d'IA sont remplacés par des opérateurs hautes performances optimisés, et des stratégies de communication qui s'adaptent à la stratégie parallèle actuelle et aux capacités du réseau de cluster de formation sont fournies.
Phase 2 : Gestion des ressources et planification des tâches
La tâche de formation du grand modèle commence à s'exécuter selon la stratégie parallèle formulée ci-dessus, et le cluster de formation fournit diverses ressources hautes performances pour la tâche d'IA. Par exemple, dans quel environnement la tâche d'IA s'exécute-t-elle, comment fournir un amarrage de ressources pour la tâche d'IA, quelle méthode de stockage la tâche d'IA utilise-t-elle pour lire et enregistrer les données, quel type d'installations réseau le GPU utilise-t-il ? /XPU communique via, etc.
Dans le même temps, pendant le processus opérationnel, le cluster de formation se combinera avec le cadre d'IA pour fournir un environnement fiable pour la formation à long terme de grands modèles grâce à une tolérance élastique aux pannes et d'autres méthodes. Par exemple, comment observer et percevoir l'état d'exécution de diverses ressources et tâches d'IA dans le cluster, etc., et comment planifier les ressources et les tâches d'IA lorsque le cluster change, etc.
Du démantèlement des deux étapes ci-dessus, nous pouvons constater que l'ensemble du processus de formation des grands modèles repose sur la coopération étroite du cadre d'IA et du cluster de formation pour achever la percée des trois murs et assurer conjointement l'efficacité et stabilité de la formation des grands modèles.
5. Intégration full-stack, "AI Big Base" accélère la formation des grands modèles
Combinée à des années d'accumulation de technologies et de pratique d'ingénierie dans les domaines de l'IA et des grands modèles, Baidu a lancé une infrastructure d'IA full-stack auto-développée " AI" fin 2022 "Big Base", y compris la pile technologique à trois couches "chip - frame - model", dispose de technologies clés auto-développées et de produits de pointe à tous les niveaux, correspondant au noyau Kunlun, PaddlePaddle et Wenxin large modèles respectivement.
Sur la base de ces trois couches de pile technologique, Baidu Smart Cloud a lancé deux principales plates-formes d'ingénierie d'IA, « AI Middle Platform » et « Baidu Baige·AI Heterogeneous Computing Platform » pour améliorer l'efficacité au niveau du développement et des ressources respectivement. la percée des trois murs et accélérer le processus de formation.
Parmi eux, la « AI middle platform » s'appuie sur le framework IA pour développer des stratégies parallèles et des environnements optimisés pour le processus de formation des grands modèles, couvrant l'ensemble du cycle de vie de la formation. « Baidu Baige » réalise une activation efficace des puces et assure la gestion de diverses ressources d'IA et capacités de planification de tâches.
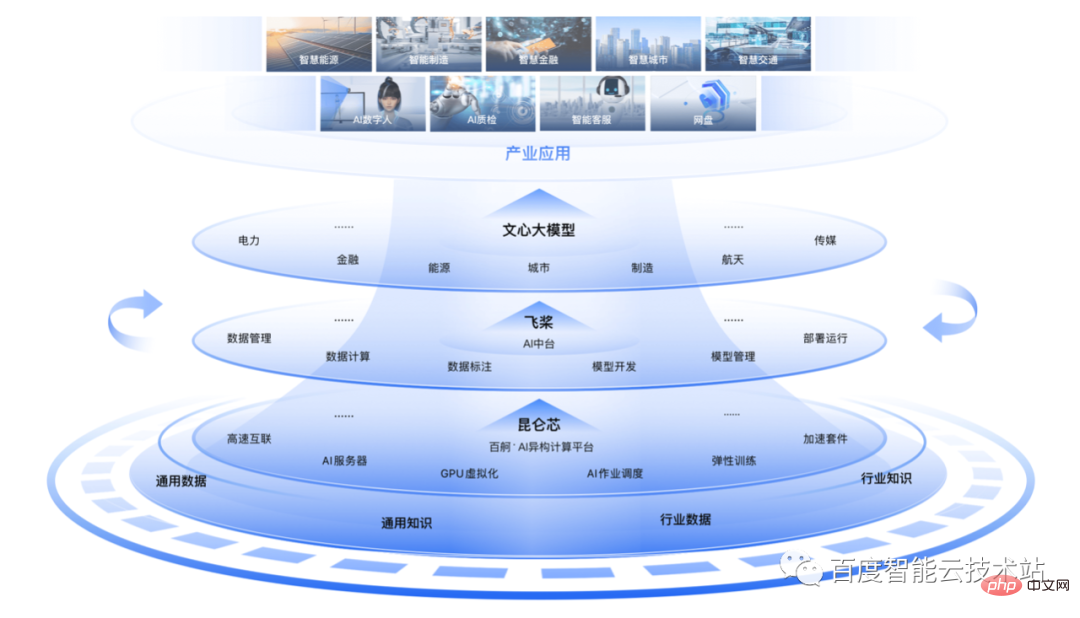
La « AI Big Base » de Baidu a réalisé une intégration complète et une optimisation du système de la pile technologique à chaque couche, terminé la construction de l'intégration technologique de Yunhezhi et peut réaliser une optimisation et une optimisation de bout en bout de la formation sur les grands modèles s'accélère.
Hou Zhenyu, vice-président du groupe Baidu : La formation sur grands modèles est un projet systématique. La taille du cluster, le temps de formation et le coût ont tous beaucoup augmenté par rapport au passé. Sans optimisation full-stack, il serait difficile de garantir la réussite de la formation de grands modèles. Les investissements techniques et les pratiques d'ingénierie de Baidu dans les grands modèles au fil des années nous ont permis d'établir un ensemble complet de capacités de pile logicielle pour accélérer la formation des grands modèles.
Ensuite, nous combinerons les deux étapes du processus de formation des grands modèles mentionnés ci-dessus pour décrire comment chaque couche de la pile technologique de la « AI Big Base » s'intègre l'une à l'autre et optimise le système pour atteindre l'objectif de bout en bout. -fin de la formation sur les grands modèles. Fin de l'optimisation et de l'accélération.
5.1 Stratégie parallèle et optimisation de la formation
Découpage de modèle
Flying Paddle peut fournir de riches stratégies parallèles telles que le parallélisme des données, le parallélisme des modèles, le parallélisme des pipelines, le regroupement et le découpage des paramètres et le parallélisme expert pour la formation de grands modèles. Ces stratégies parallèles peuvent répondre aux besoins de formation de grands modèles avec des paramètres allant de milliards à des centaines de milliards, voire des milliards, réalisant ainsi des percées dans les murs de mémoire informatique et vidéo. En avril 2021, Feipiao a été le premier du secteur à proposer une stratégie parallèle hybride 4D, capable de prendre en charge la formation de centaines de milliards de grands modèles à compléter au niveau mensuel.
Conscience de la topologie
Baidu Baige dispose de capacités de connaissance de la topologie des clusters spécialement préparées pour les scénarios de formation de grands modèles, y compris la connaissance de l'architecture intra-nœud, la connaissance de l'architecture inter-nœuds, etc., telles que la puissance de calcul, le CPU et le GPU/XPU dans chaque serveur, méthodes de liaison GPU/XPU et GPU/XPU, ainsi que méthodes de liaison réseau GPU/XPU et GPU/XPU entre les serveurs et d'autres informations.
Parallèle automatique
Avant que la tâche de formation de grand modèle ne commence à s'exécuter, Feipiao peut former un graphe de ressources distribuées unifié pour le cluster basé sur la capacité de connaissance de la topologie de la plateforme Baidu Baige. Dans le même temps, la pagaie volante forme une vue de calcul logique unifiée basée sur le grand modèle à entraîner.
Sur la base de ces deux images, Feipiao recherche automatiquement la stratégie optimale de segmentation du modèle et de combinaison matérielle pour le modèle, et alloue les paramètres du modèle, les gradients et l'état de l'optimiseur aux différents GPU/XPU selon la stratégie de placement complet de l'IA. tâches pour améliorer les performances de la formation.
Par exemple, placer des tâches d'IA parallèles de modèle sur différents GPU sur le même serveur, et ces GPU sont liés via le NVSwitch à l'intérieur du serveur. Placez des tâches d'IA parallèles aux données et au pipeline sur des GPU du même nombre sur différents serveurs, et ces GPU sont liés via IB ou RoCE. Grâce à cette méthode de placement des tâches d'IA selon le type de tâches d'IA, les ressources du cluster peuvent être utilisées efficacement et la formation de grands modèles peut être accélérée.
Formation adaptative de bout en bout
Pendant l'exécution de la tâche de formation, si le cluster change, comme une panne de ressource, ou si la taille du cluster change, Baidu Baige effectuera un remplacement tolérant aux pannes ou une expansion et une contraction élastiques. Les emplacements des nœuds participant au calcul ayant changé, le mode de communication entre eux peut ne plus être optimal. Flying Paddle peut ajuster automatiquement les stratégies de segmentation du modèle et de placement des tâches d'IA en fonction des dernières informations sur le cluster. Parallèlement, Baidu Baige finalise la planification des tâches et ressources correspondantes.
La vue unifiée des ressources et de calcul de Fei Paddle et ses capacités parallèles automatiques, combinées aux capacités de planification élastique de Baidu Baige, permettent de réaliser une formation distribuée adaptative de bout en bout de grands modèles, couvrant l'ensemble du cycle de vie de la formation en cluster.
Il s'agit d'une interaction approfondie entre le cadre d'IA et la plate-forme de puissance de calcul hétérogène de l'IA. Il réalise l'optimisation du système de la trinité puissance de calcul, cadre et algorithme, prend en charge la formation automatique et flexible de grands modèles, et a une amélioration des performances de 2,1 fois dans les tests réels de bout en bout. Garantit l'efficacité de la formation à grande échelle.
Optimisation de la formation
Après avoir terminé le fractionnement du modèle et le placement des tâches d'IA, pendant le processus de formation, afin de garantir que les opérateurs peuvent accélérer les calculs sur divers frameworks d'IA grand public et diverses cartes informatiques telles que Flying Paddle et Pytorch , Baidu Baige Une suite d'accélération de l'IA est intégrée à la plateforme. La suite d'accélération de l'IA comprend l'accélération du stockage de la couche de données, la bibliothèque d'accélération de la formation et de l'inférence AIAK, qui optimise l'ensemble du lien à partir des dimensions du chargement des données, du calcul du modèle, de la communication distribuée et d'autres dimensions.
Parmi eux, l'optimisation du chargement des données et du calcul du modèle peut améliorer efficacement l'efficacité opérationnelle d'une seule carte ; l'optimisation de la communication distribuée, combinée à des réseaux hautes performances tels que le cluster IB ou RoCE et une topologie de communication spécialement optimisée, ainsi que stratégies raisonnables de placement de tâches d'IA, travaillez ensemble pour résoudre les problèmes de mur de communication.
Le taux d'accélération multi-cartes de Baidu Baige dans un cluster à l'échelle d'un kilo-carte a atteint 90 %, permettant à la puissance de calcul globale du cluster d'être pleinement libérée.
Dans les résultats des tests de MLPerf Training v2.1 publiés en novembre 2022, les résultats de performances d'entraînement du modèle soumis par Baidu à l'aide de Fei Paddle plus Baidu Baige se sont classés premiers au monde sous la même configuration GPU, avec un temps d'entraînement de bout en bout. et formation Le débit dépasse le framework NGC PyTorch.
5.2 Gestion des ressources et planification des tâches
Gestion des ressources
Baidu Baige peut fournir diverses ressources informatiques, réseau, de stockage et autres ressources d'IA, y compris le serveur bare metal élastique Baidu Taihang BBC, le réseau IB, le réseau RoCE, le stockage de fichiers parallèle PFS, le stockage d'objets BOS, le stockage de lac de données Accélérer divers ressources de cloud computing adaptées à la formation de grands modèles tels que RapidFS.
Lorsqu'une tâche est en cours d'exécution, ces ressources hautes performances peuvent être raisonnablement combinées pour améliorer encore l'efficacité des opérations d'IA et réaliser une accélération informatique des tâches d'IA tout au long du processus. Avant le début de la tâche d'IA, les données de formation dans le BOS de stockage d'objets peuvent être réchauffées et les données peuvent être chargées dans l'accélération du stockage du lac de données RapidFS via le réseau élastique RDMA. Le réseau élastique RDMA peut réduire la latence de communication de 2 à 3 fois par rapport aux réseaux traditionnels et accélère la lecture des données des tâches d'IA sur la base d'un stockage haute performance. Enfin, les calculs des tâches d'IA sont effectués via le serveur bare metal élastique Baidu Taihang hautes performances BBC ou le serveur cloud BCC.
Tolérance élastique aux pannes
Lors de l'exécution d'une tâche d'IA, elle nécessite non seulement des ressources hautes performances, mais garantit également la stabilité du cluster et minimise l'apparition de pannes de ressources pour éviter d'interrompre la formation. Cependant, les pannes de ressources ne peuvent pas être absolument évitées. Le cadre d'IA et le cluster de formation doivent garantir conjointement que la tâche de formation peut être récupérée à partir de son état le plus récent après avoir été interrompue, fournissant ainsi un environnement fiable pour la formation à long terme des grands. modèles.
ECCL, la bibliothèque de collections hétérogènes auto-développée par Baidu, prend en charge la communication entre les cœurs Kunlun et d'autres puces hétérogènes, et prend en charge la perception des nœuds lents et des nœuds défectueux. Grâce à l'élasticité des ressources et à la stratégie de tolérance aux pannes de Baidu Baige, les nœuds lents et les nœuds défectueux sont éliminés, et la dernière topologie d'architecture est renvoyée à Feipiao pour réorganiser les tâches et attribuer les tâches de formation correspondantes à d'autres XPU/GPU afin d'assurer une exécution fluide. efficacement.
6. L'inclusivité de l'IA à l'ère des grands modèles
Les grands modèles sont une technologie marquante pour que l'intelligence artificielle évolue vers l'intelligence générale. La bonne maîtrise des grands modèles est une réponse incontournable sur la voie des mises à niveau intelligentes. La puissance de calcul à très grande échelle et l’optimisation logicielle intégrée full-stack sont les meilleures réponses à cette question incontournable.
Afin d'aider la société et l'industrie à former rapidement leurs propres grands modèles et à saisir l'opportunité de l'époque, Baidu Intelligent Cloud a lancé fin 2022 le Yangquan Intelligent Computing Center, équipé des capacités full-stack du « AI Big » de Baidu. Base", qui peut fournir 4 EFLOPS de données hétérogènes. Puissance de calcul. Il s’agit actuellement du centre de données le plus grand et le plus avancé technologiquement d’Asie.
À l'heure actuelle, Baidu Intelligent Cloud a ouvert toutes les capacités de « AI Big Base » au monde extérieur, réalisant une IA inclusive à l'ère des grands modèles, via des nuages centraux dans diverses régions, des nuages de périphérie BEC et des clusters informatiques locaux LCC. , cloud privé ABC Stack, etc. Livrés sous diverses formes, la société et l'industrie peuvent facilement obtenir des services intelligents.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI