
Maison >Périphériques technologiques >IA >Un examen de la technologie des algorithmes de perception visuelle de la conduite autonome
Un examen de la technologie des algorithmes de perception visuelle de la conduite autonome

- 王林avant
- 2023-05-10 21:37:131780parcourir
La perception de l'environnement est le premier maillon de la conduite autonome et le lien entre le véhicule et l'environnement. La performance globale d’un système de conduite autonome dépend en grande partie de la qualité du système de perception. Actuellement, il existe deux voies technologiques principales pour la technologie de détection environnementale :
① Solution de fusion multi-capteurs basée sur la vision, le représentant typique est Tesla
② Solutions techniques basées sur Lidar et autres capteurs assistées, typiques ; des représentants tels que Google, Baidu, etc.
Nous présenterons les principaux algorithmes de perception visuelle dans la perception environnementale. Sa couverture de tâches et ses domaines techniques sont présentés dans la figure ci-dessous. Nous sommes divisés en deux sections pour trier respectivement le contexte et la direction des algorithmes de perception visuelle 2D et 3D.
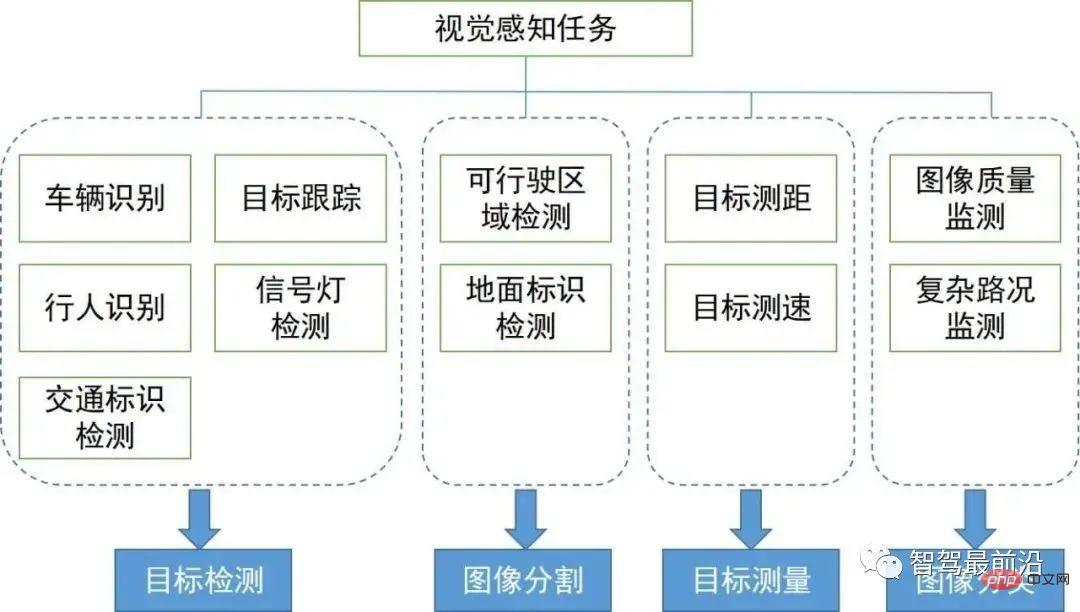
Dans cette section, nous introduisons d'abord des algorithmes de perception visuelle 2D à partir de plusieurs tâches largement utilisées en conduite autonome, notamment la détection et le suivi de cibles 2D basés sur des images ou des vidéos, et la segmentation sémantique de scènes 2D. . Ces dernières années, l'apprentissage profond est entré dans divers domaines de la perception visuelle et a obtenu de bons résultats. Nous avons donc trié certains algorithmes classiques d'apprentissage profond.
01 Détection de cible
1.1 Détection en deux étapes
Les deux étapes signifient qu'il existe deux processus pour réaliser la détection, l'un consiste à extraire la zone de l'objet, l'autre à classer et à classifier. identifier la zone avec CNN Par conséquent, la « deux étapes » est également appelée détection de cible basée sur la proposition de région (Proposition de région). Les algorithmes représentatifs incluent la série R-CNN (R-CNN, Fast R-CNN, Faster R-CNN), etc.
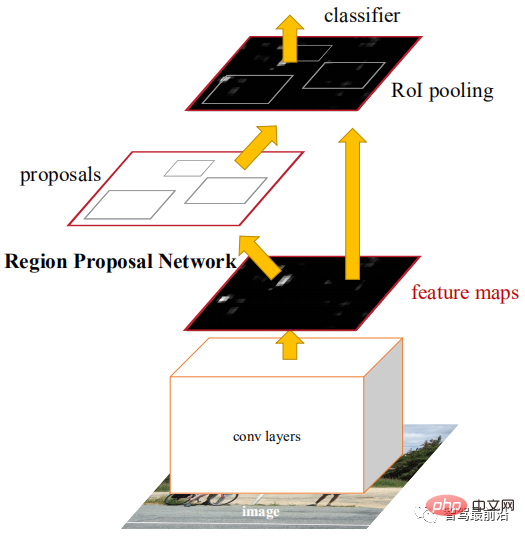
Faster R-CNN est le premier réseau de détection de bout en bout. Dans la première étape, un réseau de proposition de région (RPN) est utilisé pour générer des cadres candidats basés sur la carte de caractéristiques, et ROIPooling est utilisé pour aligner la taille des caractéristiques candidates. Dans la deuxième étape, une couche entièrement connectée est utilisée pour le raffinement ; classification et régression. L'idée d'Anchor est proposée ici pour réduire la difficulté de calcul et augmenter la vitesse. Chaque position de la carte de caractéristiques générera des ancres de différentes tailles et formats d'image, qui sont utilisées comme référence pour la régression du cadre d'objet. L'introduction d'Anchor permet à la tâche de régression de ne traiter que des changements relativement mineurs, de sorte que l'apprentissage du réseau sera plus facile. La figure ci-dessous est le schéma de structure du réseau de Faster R-CNN.
La première étape de CascadeRCNN est exactement la même que Faster R-CNN, et la deuxième étape utilise plusieurs couches RoiHead pour la mise en cascade. Les travaux ultérieurs tournent principalement autour de quelques améliorations du réseau mentionné ci-dessus ou d'un mélange de travaux antérieurs, avec quelques améliorations révolutionnaires.
1.2 Détection en une seule étape
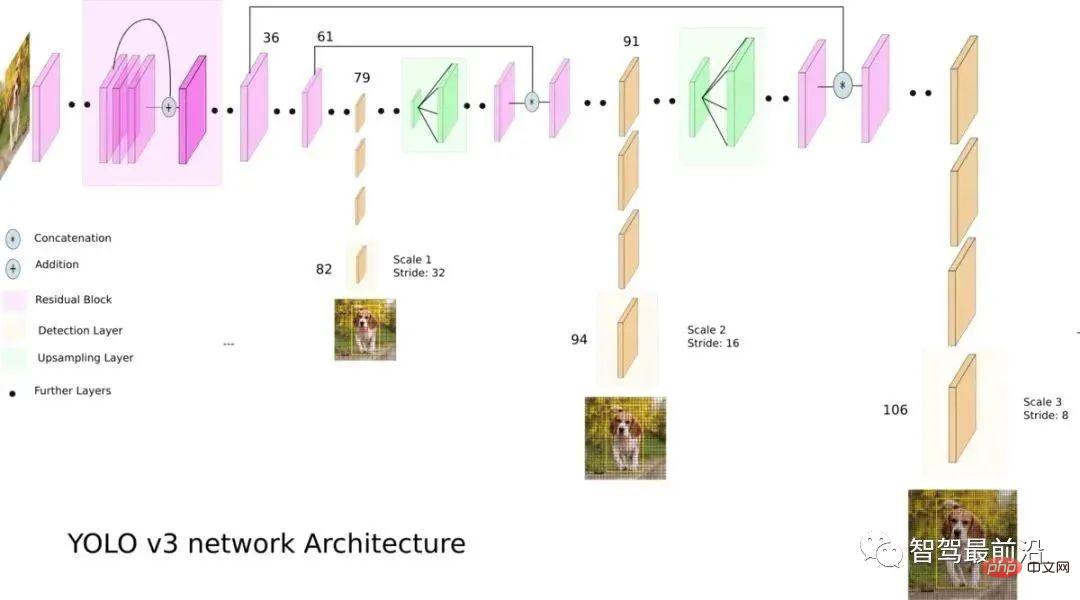
Par rapport à l'algorithme en deux étapes, l'algorithme en une seule étape n'a besoin d'extraire les caractéristiques qu'une seule fois pour obtenir la détection de la cible. Son algorithme de vitesse est plus rapide et sa précision générale est légèrement. inférieur. Le travail pionnier de ce type d'algorithme est YOLO, qui a ensuite été amélioré par SSD et Retinanet. L'équipe qui a proposé YOLO a intégré ces astuces qui aident à améliorer les performances dans l'algorithme YOLO, et a ensuite proposé 4 versions améliorées YOLOv2 ~ YOLOv5. Bien que la précision de la prédiction ne soit pas aussi bonne que celle de l'algorithme de détection de cible en deux étapes, YOLO est devenu le courant dominant de l'industrie en raison de sa vitesse d'exécution plus rapide. La figure suivante est le diagramme de structure du réseau de YOLOv3.
1.3 Détection sans ancre (pas de détection d'ancre)
Ce type de méthode représente généralement l'objet sous forme de points clés, et CNN est utilisé pour renvoyer les positions de ces points clés . Le point clé peut être le point central (CenterNet), le point d'angle (CornerNet) ou le point représentatif (RepPoints) du cadre de l'objet. CenterNet convertit le problème de détection de cible en un problème de prédiction du point central, c'est-à-dire en utilisant le point central de la cible pour représenter la cible et en obtenant le cadre rectangulaire de la cible en prédisant le décalage, la largeur et la hauteur du point central de la cible.
Heatmap représente les informations de classification, et chaque catégorie générera une Heatmap distincte. Pour chaque Heatmap, lorsqu'une certaine coordonnée contient le point central de la cible, un point clé sera généré au niveau de la cible. Nous utilisons un cercle gaussien pour représenter l'ensemble du point clé. La figure suivante montre les détails spécifiques.

RepPoints propose de représenter l'objet comme un ensemble de points représentatif et de s'adapter aux changements de forme de l'objet par convolution déformable. L'ensemble de points est finalement converti en un cadre d'objet et utilisé pour calculer la différence par rapport à l'annotation manuelle.
1.4 Détection de transformateur
Qu'il s'agisse d'une détection de cible à un ou deux étages, qu'Anchor soit utilisé ou non, le mécanisme d'attention n'est pas bien utilisé. En réponse à cette situation, Relation Net et DETR utilisent Transformer pour introduire le mécanisme d'attention dans le domaine de la détection de cibles. Relation Net utilise Transformer pour modéliser la relation entre différentes cibles, incorpore les informations sur les relations dans les fonctionnalités et réalise l'amélioration des fonctionnalités. DETR propose une nouvelle architecture de détection de cible basée sur Transformer, ouvrant une nouvelle ère de détection de cible. La figure suivante est le processus algorithmique de DETR. Tout d'abord, CNN est utilisé pour extraire les caractéristiques de l'image, puis Transformer est utilisé pour modéliser la relation spatiale globale. .Enfin, nous obtenons La sortie de est mise en correspondance avec une annotation manuelle via un algorithme de correspondance de graphiques bipartis.
La précision dans le tableau ci-dessous utilise mAP sur la base de données MSCOCO comme indicateur, tandis que la vitesse est mesurée par FPS. Par rapport à certains des algorithmes ci-dessus, il existe de nombreux choix différents dans la conception structurelle du. réseau (comme des tailles d'entrée différentes, des réseaux backbone différents, etc.) et les plates-formes matérielles de mise en œuvre de chaque algorithme sont également différentes, de sorte que la précision et la vitesse ne sont pas complètement comparables. Seul un résultat approximatif est répertorié ici pour votre référence.
02 Suivi de cible
Dans les applications de conduite autonome, l'entrée est constituée de données vidéo, et de nombreuses cibles doivent être prises en compte, telles que les véhicules, les piétons, les vélos, etc. Il s’agit donc d’une tâche typique de suivi d’objets multiples (MOT). Pour les tâches MOT, le framework le plus populaire actuellement est le suivi par détection, et son processus est le suivant :
① Le détecteur cible obtient la sortie de l'image cible sur une seule image image
② ; Les caractéristiques de la cible incluent généralement les caractéristiques visuelles et les caractéristiques de mouvement ;
③ Calculer la similarité entre les détections de cibles provenant d'images adjacentes en fonction des caractéristiques pour déterminer la probabilité qu'elles proviennent de la même cible ; similarités La détection d'objets dans des images adjacentes correspond et les objets de la même cible se voient attribuer le même ID.
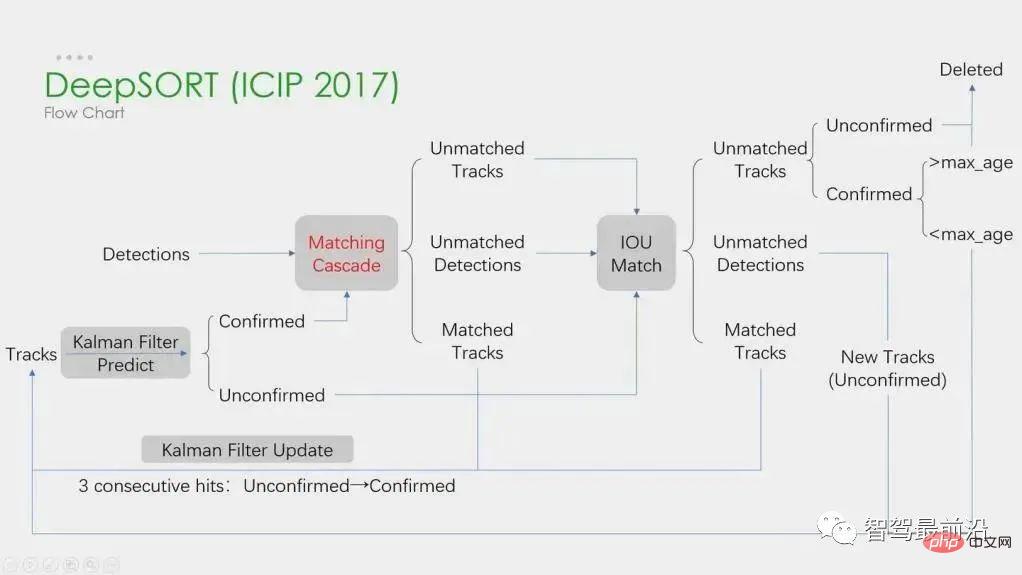
Le deep learning est appliqué dans les quatre étapes ci-dessus, mais les deux premières étapes sont les principales. À l’étape 1, l’application de l’apprentissage profond consiste principalement à fournir des détecteurs d’objets de haute qualité, c’est pourquoi des méthodes plus précises sont généralement choisies. SORT est une méthode de détection de cible basée sur Faster R-CNN et utilise l'algorithme de filtre de Kalman + l'algorithme hongrois pour améliorer considérablement la vitesse de suivi multi-cibles et atteindre la précision de SOTA. Elle est également largement utilisée dans les applications pratiques. algorithme. À l’étape 2, l’application du deep learning repose principalement sur l’utilisation de CNN pour extraire les caractéristiques visuelles des objets. La plus grande fonctionnalité de DeepSORT est d'ajouter des informations d'apparence et d'emprunter le module ReID pour extraire les fonctionnalités d'apprentissage en profondeur, réduisant ainsi le nombre de commutateurs d'identification. L'organigramme global est le suivant :
 De plus, il existe également un cadre de détection et de suivi simultanés. Tel que le CenterTrack représentatif, issu de l'algorithme de détection sans ancre à une étape CenterNet introduit auparavant. Par rapport à CenterNet, CenterTrack ajoute l'image RVB de l'image précédente et la Heatmap du centre de l'objet comme entrées supplémentaires, et ajoute une branche Offset pour l'association entre les images précédentes et suivantes. Par rapport au suivi par détection en plusieurs étapes, CenterTrack utilise un réseau pour mettre en œuvre les étapes de détection et de correspondance, améliorant ainsi la vitesse du MOT.
De plus, il existe également un cadre de détection et de suivi simultanés. Tel que le CenterTrack représentatif, issu de l'algorithme de détection sans ancre à une étape CenterNet introduit auparavant. Par rapport à CenterNet, CenterTrack ajoute l'image RVB de l'image précédente et la Heatmap du centre de l'objet comme entrées supplémentaires, et ajoute une branche Offset pour l'association entre les images précédentes et suivantes. Par rapport au suivi par détection en plusieurs étapes, CenterTrack utilise un réseau pour mettre en œuvre les étapes de détection et de correspondance, améliorant ainsi la vitesse du MOT.
03 Segmentation sémantique
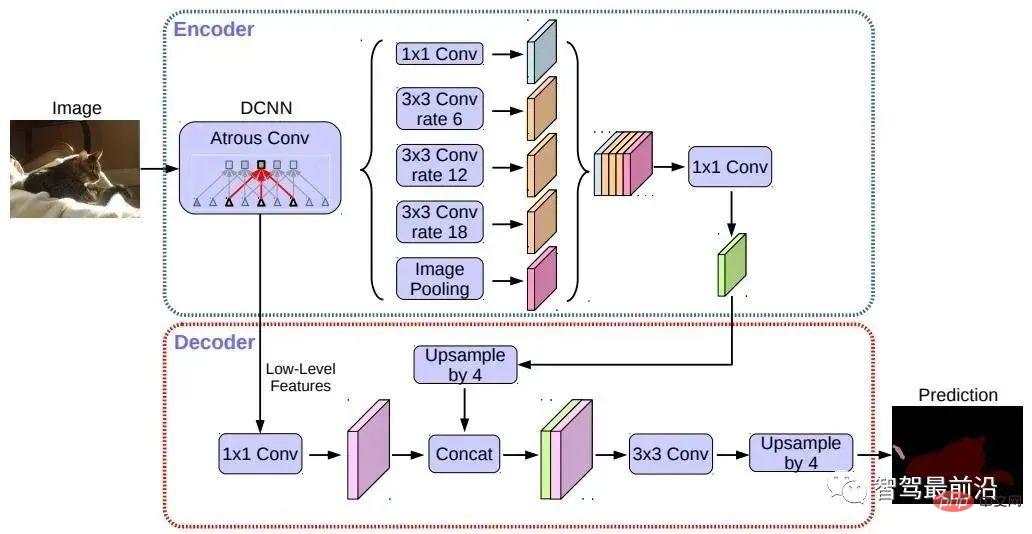
La segmentation sémantique est utilisée à la fois dans les tâches de détection de lignes de voie et de détection de zones carrossables de la conduite autonome. Les algorithmes représentatifs incluent les séries FCN, U-Net, DeepLab, etc. DeepLab utilise une convolution dilatée et une structure ASPP (Atrous Spatial Pyramid Pooling) pour effectuer un traitement multi-échelle sur l'image d'entrée. Enfin, le champ aléatoire conditionnel (CRF) couramment utilisé dans les méthodes de segmentation sémantique traditionnelles est utilisé pour optimiser les résultats de segmentation. La figure ci-dessous représente la structure du réseau de DeepLab v3+.
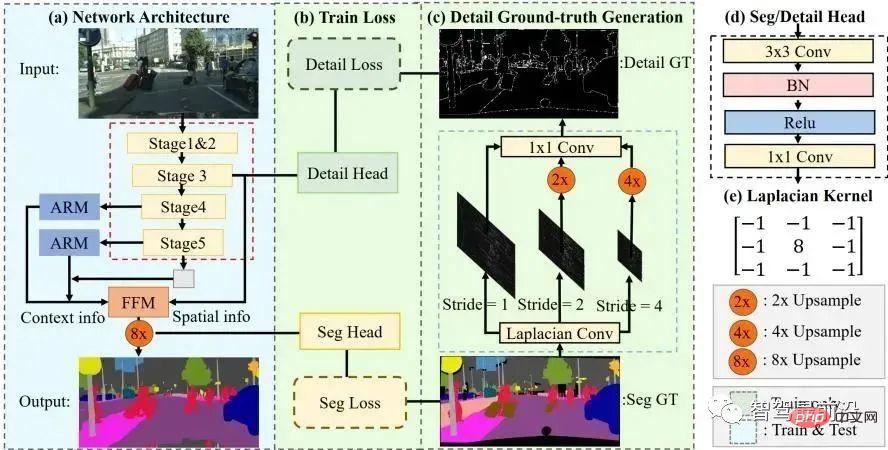
L'algorithme STDC a adopté ces dernières années une structure similaire à l'algorithme FCN, supprimant la complexité de l'U- Structure du décodeur d'algorithme net. Mais en même temps, dans le processus de sous-échantillonnage du réseau, le module ARM est utilisé pour fusionner en continu les informations provenant de cartes de caractéristiques de différentes couches, évitant ainsi les défauts de l'algorithme FCN qui ne prend en compte que les relations entre pixels uniques. On peut dire que l'algorithme STDC atteint un bon équilibre entre vitesse et précision, et qu'il peut répondre aux exigences en temps réel du système de conduite autonome. Le flux de l'algorithme est présenté dans la figure ci-dessous.
Nous présenterons ensuite les scènes 3D essentielles à la conduite autonome Perception . Étant donné que les informations sur la profondeur, la taille tridimensionnelle de la cible, etc. ne peuvent pas être obtenues en perception 2D, ces informations sont la clé permettant au système de conduite autonome de porter des jugements corrects sur l'environnement. Le moyen le plus direct d’obtenir des informations 3D consiste à utiliser le LiDAR. Cependant, le LiDAR présente également des inconvénients, tels qu'un coût plus élevé, des difficultés de production en série de produits de qualité automobile, un impact plus important des conditions météorologiques, etc. Par conséquent, la perception 3D basée uniquement sur des caméras reste une direction de recherche très significative et précieuse. Ensuite, nous trierons quelques algorithmes de perception 3D basés sur les monoculaires et les binoculaires.
04 Perception 3D monoculaire
Percevoir l'environnement 3D à partir d'une seule image de caméra est un mal- problème posé, mais peut être résolu grâce à des hypothèses géométriques (telles que des pixels au sol), des connaissances préalables ou des informations supplémentaires (telles que l'estimation de la profondeur). Cette fois, nous présenterons les algorithmes pertinents à partir des deux tâches de base de la conduite autonome (détection de cible 3D et estimation de la profondeur). #🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜#4.1 Test de cible 3D#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜## 🎜🎜 #
Représente la conversion (pseudo-lidar) : La détection d'autres véhicules environnants par des capteurs visuels rencontre généralement des problèmes tels que l'occlusion et l'impossibilité de mesurer les distances. La vue en perspective peut être convertie en vue à vol d'oiseau. .Représentation de figures. Deux méthodes de transformation sont présentées ici. La première est la cartographie en perspective inverse (IPM), qui suppose que tous les pixels sont au sol et que les paramètres externes de la caméra sont précis. À ce stade, la transformation homographique peut être utilisée pour convertir l'image en BEV, puis une méthode basée sur la cartographie en perspective inverse (IPM). Le réseau YOLO est utilisé pour détecter le cadre au sol de la cible. La seconde est Orthogonal Feature Transform (OFT), qui utilise ResNet-18 pour extraire les caractéristiques de l'image en perspective. Des caractéristiques basées sur des voxels sont ensuite générées par accumulation de caractéristiques basées sur des images sur les régions de voxels projetées. Les caractéristiques voxels sont ensuite pliées verticalement pour produire des caractéristiques de plan de sol orthogonales. Enfin, un autre réseau descendant similaire à ResNet est utilisé pour la détection d'objets 3D. Ces méthodes ne conviennent qu’aux véhicules et piétons proches du sol.Pour les cibles non terrestres telles que les panneaux de signalisation et les feux de circulation, des pseudo-nuages de points peuvent être générés grâce à l'estimation de la profondeur pour la détection 3D. Le pseudo-LiDAR utilise d'abord les résultats de l'estimation de la profondeur pour générer des nuages de points, puis applique directement le détecteur de cible 3D basé sur le lidar pour générer un cadre cible 3D. Le flux de l'algorithme est présenté dans la figure ci-dessous, #🎜🎜. #
# 🎜🎜#
Contraintes géométriques 2D/3D : régressez la projection du centre 3D et de la profondeur de l'instance approximative et utilisez les deux pour estimer une position 3D approximative. Le travail pionnier est Deep3DBox, qui utilise pour la première fois les caractéristiques de l'image dans une zone cible 2D pour estimer la taille et l'orientation de la cible. Ensuite, la position 3D du point central est résolue via une contrainte géométrique 2D/3D. Cette contrainte est que la projection du cadre cible 3D sur l'image est étroitement entourée par le cadre cible 2D, c'est-à-dire qu'au moins un point de coin du cadre cible 3D peut être trouvé de chaque côté du cadre cible 2D. Grâce à la taille et à l'orientation prédites précédemment, combinées aux paramètres d'étalonnage de la caméra, la position 3D du point central peut être calculée. Les contraintes géométriques entre les zones cibles 2D et 3D sont illustrées dans la figure ci-dessous. Shift R-CNN combine la boîte cible 2D obtenue précédemment, la boîte cible 3D et les paramètres de la caméra en tant qu'entrée basée sur Deep3DBox, et utilise un réseau entièrement connecté pour prédire une position 3D plus précise. 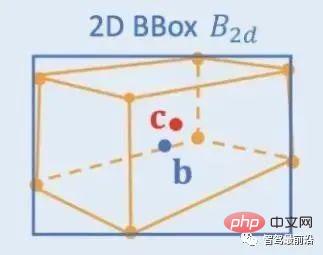
Générer directement une 3DBox : cette méthode part de boîtes candidates cibles 3D denses et note toutes les boîtes candidates à travers les caractéristiques de l'image 2D. La boîte candidate avec un score élevé est le résultat final. Un peu similaire à la méthode traditionnelle de fenêtre coulissante dans la détection de cibles. L'algorithme représentatif Mono3D génère d'abord des boîtes candidates 3D denses en fonction de la position antérieure de la cible (la coordonnée z est au sol) et de sa taille. Une fois que ces images candidates 3D sont projetées sur les coordonnées de l'image, elles sont notées en intégrant les caractéristiques sur l'image 2D, puis un deuxième cycle de notation est effectué via CNN pour obtenir l'image cible 3D finale.
M3D-RPN est une méthode basée sur l'ancrage qui définit les ancres 2D et 3D. L'ancre 2D est obtenue grâce à un échantillonnage dense sur l'image, et l'ancre 3D est déterminée grâce à la connaissance préalable des données de l'ensemble d'entraînement (telles que la moyenne de la taille réelle de la cible). M3D-RPN utilise également à la fois la convolution standard et la convolution Depth-Aware. Le premier a une invariance spatiale et le second divise les lignes (coordonnées Y) de l'image en plusieurs groupes. Chaque groupe correspond à une profondeur de scène différente et est traité par différents noyaux de convolution. Les méthodes d’échantillonnage dense ci-dessus nécessitent beaucoup de calculs. SS3D utilise une détection en une seule étape plus efficace, comprenant un CNN pour générer des représentations redondantes de chaque objet pertinent dans l'image et les estimations d'incertitude correspondantes, ainsi qu'un optimiseur de boîte englobante 3D. FCOS3D est également une méthode de détection en une seule étape. La cible de régression ajoute un centre 2,5D supplémentaire (X, Y, Profondeur) obtenu en projetant le centre du cadre cible 3D sur l'image 2D.
4.2 Estimation de la profondeur
Qu'il s'agisse de la détection de cible 3D mentionnée ci-dessus ou d'une autre tâche importante de la perception de la conduite autonome - la segmentation sémantique, s'étendant de la 2D à la 3D, la parcimonie est plus ou moins appliquée ou dense. informations de profondeur. L'importance de l'estimation de la profondeur monoculaire va de soi. Son entrée est une image et la sortie est une image de même taille constituée de la valeur de profondeur de la scène correspondant à chaque pixel. L'entrée peut également être une séquence vidéo, utilisant des informations supplémentaires apportées par le mouvement de la caméra ou de l'objet pour améliorer la précision de l'estimation de la profondeur.
Par rapport à l'apprentissage supervisé, la méthode non supervisée d'estimation de la profondeur monoculaire ne nécessite pas la construction d'un ensemble de données de vérité terrain difficile et est moins difficile à mettre en œuvre. Les méthodes non supervisées d’estimation de profondeur monoculaire peuvent être divisées en deux types : basées sur des séquences vidéo monoculaires et basées sur des paires d’images stéréo synchronisées.
Le premier repose sur l'hypothèse de caméras en mouvement et de scènes statiques. Dans cette dernière méthode, Garg et al. Sur cette base, Godard et al. est constamment perdu, affectant le traitement des détails en profondeur et la clarté des bords. Pour atténuer ce problème, Godard et al. ont introduit une perte multi-échelle pleine résolution, qui a efficacement réduit les trous noirs et les artefacts de réplication de texture dans les zones à faible texture. Cependant, cette amélioration de la précision reste encore limitée.
Récemment, certains modèles basés sur Transformer ont émergé dans un flux incessant, visant à obtenir le champ de réception global de l'ensemble de la scène, ce qui est également très approprié pour les tâches intensives d'estimation de profondeur. Dans le DPT supervisé, il est proposé d'utiliser un transformateur et une structure multi-échelle pour assurer simultanément la précision locale et la cohérence globale de la prédiction. La figure suivante est le diagramme de structure du réseau.
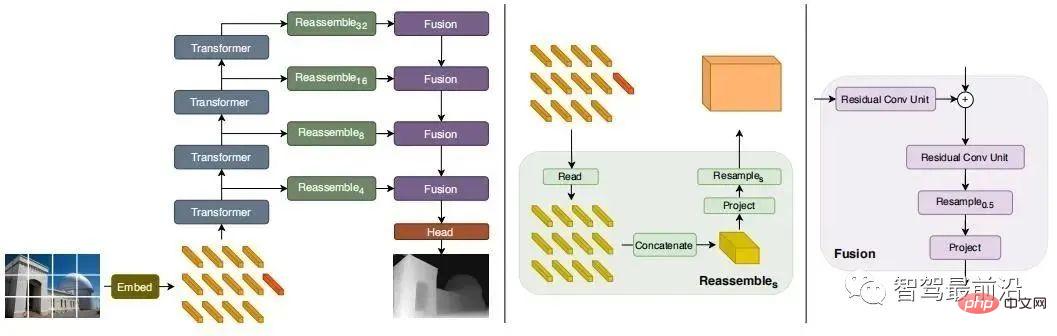
05 Perception binoculaire 3D
La vision binoculaire peut résoudre l'ambiguïté causée par la transformation de perspective, elle peut donc en théorie améliorer la précision de la perception 3D. Cependant, le système binoculaire présente des exigences relativement élevées en termes de matériel et de logiciel. En termes de matériel, deux caméras enregistrées avec précision sont nécessaires et l'exactitude de l'enregistrement doit être assurée pendant le fonctionnement du véhicule. En termes de logiciel, l'algorithme doit traiter les données de deux caméras en même temps. La complexité des calculs est élevée et les performances en temps réel de l'algorithme sont difficiles à garantir. Par rapport au monoculaire, le travail binoculaire est relativement moindre. Ensuite, nous donnerons également une brève introduction des deux aspects de la détection de cibles 3D et de l'estimation de la profondeur.
5.1 Détection de cible 3D
3DOP est une méthode de détection en deux étapes, qui est une extension de la méthode Fast R-CNN dans le domaine 3D. Tout d'abord, les images binoculaires sont utilisées pour générer une carte de profondeur. La carte de profondeur est convertie en un nuage de points puis quantifiée en une structure de données en grille. Celle-ci est ensuite utilisée comme entrée pour générer une image candidate pour la cible 3D. Semblables au pseudo-LiDAR introduit précédemment, les cartes de profondeur denses (à partir de LiDAR monoculaires, binoculaires ou même à faible nombre de lignes) sont converties en nuages de points, puis des algorithmes dans le domaine de la détection de cibles par nuages de points sont appliqués. DSGN utilise la correspondance stéréo pour construire des volumes de numérisation planaires et les convertit en géométrie 3D afin de coder la géométrie 3D et les informations sémantiques. Il s'agit d'un cadre de bout en bout qui peut extraire des fonctionnalités au niveau des pixels pour une correspondance stéréo et des fonctionnalités avancées de reconnaissance d'objets. , et peut simultanément estimer la profondeur de la scène et détecter des objets 3D.
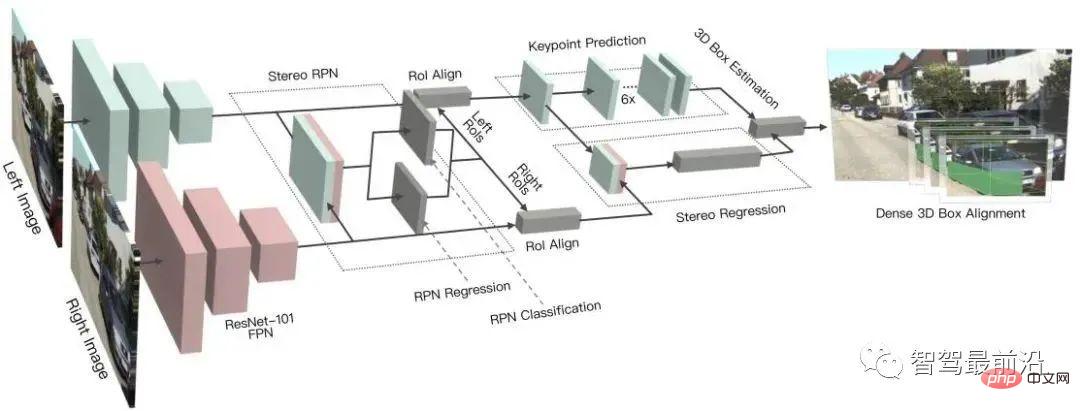
Stereo R-CNN étend Faster R-CNN pour une entrée stéréo afin de détecter et de corréler simultanément les objets dans les vues gauche et droite. Une branche supplémentaire est ajoutée après RPN pour prédire les points clés, les points de vue et les tailles d'objet clairsemés, et combine les cadres de délimitation 2D dans les vues gauche et droite pour calculer un cadre de délimitation d'objet 3D grossier. Ensuite, des cadres de délimitation 3D précis sont récupérés en utilisant un alignement photométrique basé sur la région des régions d'intérêt gauche et droite. La figure ci-dessous représente la structure de son réseau. 5.2 Estimation de la profondeur les deux caméras maintiennent la même hauteur, donc seule la distance dans la direction horizontale), c'est-à-dire la parallaxe, la distance focale f de la caméra et la distance B (longueur de base) entre les deux caméras sont utilisées pour estimer la profondeur du point 3D La formule est la suivante. La profondeur peut être calculée en estimant la parallaxe. Ensuite, tout ce que vous avez à faire est de trouver un point correspondant sur l’autre image pour chaque pixel.
Pour chaque d possible, l'erreur de correspondance à chaque pixel peut être calculée, de sorte qu'un volume de coût de données d'erreur tridimensionnelle est obtenu. Grâce au Cost Volume, nous pouvons facilement obtenir la disparité à chaque pixel (d correspondant à l'erreur de correspondance minimale), et ainsi obtenir la valeur de profondeur. MC-CNN utilise un réseau neuronal convolutif pour prédire le degré de correspondance de deux patchs d'image et l'utilise pour calculer le coût de correspondance stéréo. Les coûts sont affinés grâce à une agrégation des coûts basée sur les intersections et à une correspondance semi-globale, suivies de contrôles de cohérence gauche-droite pour éliminer les erreurs dans les zones masquées. PSMNet propose un cadre d'apprentissage de bout en bout pour la correspondance stéréo qui ne nécessite aucun post-traitement, introduit un module de regroupement pyramidal pour incorporer des informations contextuelles globales dans les caractéristiques de l'image et fournit un CNN 3D en sablier empilé pour améliorer davantage les informations globales. La figure ci-dessous représente la structure de son réseau.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI