
Maison >Périphériques technologiques >IA >Qingbei Microsoft approfondit GPT et comprend l'apprentissage contextuel ! C'est fondamentalement la même chose que le réglage fin, sauf que les paramètres n'ont pas changé.
Qingbei Microsoft approfondit GPT et comprend l'apprentissage contextuel ! C'est fondamentalement la même chose que le réglage fin, sauf que les paramètres n'ont pas changé.

- 王林avant
- 2023-05-10 21:37:041092parcourir
L'une des caractéristiques importantes des modèles linguistiques pré-entraînés à grande échelle est la capacité d'apprentissage en contexte (ICL), c'est-à-dire que, grâce à quelques paires d'étiquettes d'entrée exemplaires, de nouvelles étiquettes d'entrée peuvent être apprises sans mettre à jour les paramètres. Faire des prédictions. .
Bien que les performances se soient améliorées, la question d'où vient la capacité ICL des grands modèles reste une question ouverte.
Pour mieux comprendre le fonctionnement d'ICL, des chercheurs de l'Université Tsinghua, de l'Université de Pékin et de Microsoft ont publié conjointement un article qui interprète les modèles de langage comme des méta-optimiseurs (méta-optimiseur) et comprend ICL comme un réglage fin implicite.

Lien papier : https://arxiv.org/abs/2212.10559
Théoriquement, cet article précise qu'il existe une optimisation basée sur la descente de gradient dans Transformer attention Dual form (double formulaire), et sur cette base, la compréhension de l’ICL est la suivante. GPT génère d'abord des méta-gradients basés sur des instances de démonstration, puis applique ces méta-gradients au GPT d'origine pour créer un modèle ICL.
Au cours d'expériences, les chercheurs ont comparé de manière exhaustive le comportement de l'ICL et les réglages précis explicites basés sur des tâches réelles pour fournir des preuves empiriques étayant cette compréhension.
Les résultats prouvent que l'ICL fonctionne de manière similaire à un réglage précis explicite au niveau de la prédiction, au niveau de la représentation et au niveau du comportement d'attention.
De plus, inspiré par la compréhension de la méta-optimisation, par analogie avec l'algorithme de descente de gradient basé sur l'impulsion, l'article a également conçu une attention basée sur l'impulsion, qui a de meilleures performances que l'attention ordinaire, d'un autre Un aspect confirme encore une fois l’exactitude de cette compréhension et montre également le potentiel de l’utilisation de cette compréhension pour une conception ultérieure du modèle.
Principe de l'ICL
Les chercheurs ont d'abord mené une analyse qualitative du mécanisme d'attention linéaire dans Transformer pour découvrir la double forme entre celui-ci et l'optimisation basée sur la descente de gradient. L'ICL est ensuite comparé à un réglage fin explicite et un lien est établi entre ces deux formes d'optimisation.
L'attention du transformateur est une méta-optimisation
Supposons que X soit la représentation d'entrée de la requête entière, X' est la représentation de l'exemple, q est le vecteur de requête, puis sous le paramètre ICL, l'attention d'une tête dans le modèle Les résultats sont les suivants :
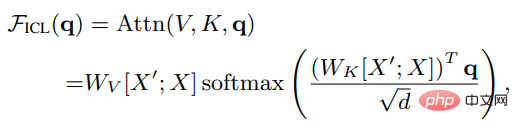
On peut voir qu'après avoir supprimé le facteur d'échelle racine d et softmax, le mécanisme d'attention standard peut être approximé comme :
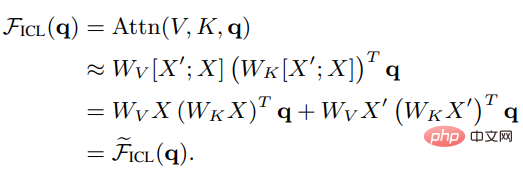
Réglez Wzsl sur Zero-Shot Learning (ZSL), l'attention du Transformer peut être convertie sous la double forme suivante :
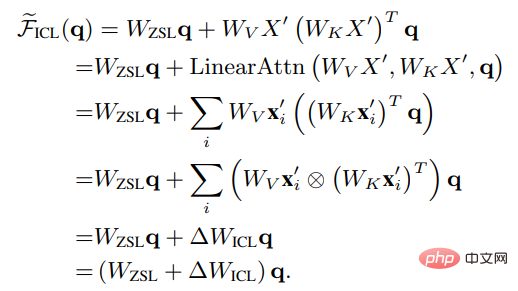
On peut voir qu'ICL peut être interprété comme un processus de méta-optimisation :
1. Utilisez le modèle de langage pré-entraîné basé sur Transformer comme méta-optimiseur ;
2 Calculez le méta-gradient selon l'exemple de démonstration via le calcul direct
3. l'original via le mécanisme d'attention Sur le modèle de langage, construisez un modèle ICL.
Comparaison entre ICL et réglage fin
Afin de comparer la méta-optimisation et l'optimisation explicite d'ICL, les chercheurs ont conçu un paramètre de réglage spécifique spécifique comme base de comparaison : en considérant qu'ICL n'agit que directement sur le clé et valeur d'attention, donc le réglage fin met uniquement à jour les paramètres des projections de clé et de valeur.
Également sous la forme non stricte de l'attention linéaire, le résultat de l'attention fine de la tête peut être exprimé comme suit :
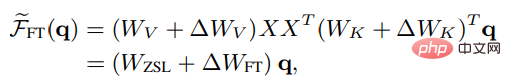 #🎜 🎜 #
#🎜 🎜 #
Afin de faire une comparaison plus juste avec ICL, les limites de réglage fin sont en outre définies dans l'expérience comme suit :
#🎜 🎜#1. Spécifiez les exemples de formation comme exemples de démonstration d'ICL2. l'ordre est le même que l'ordre de démonstration d'ICL ;
3. Formatez chaque exemple de formation avec le modèle utilisé par ICL et affinez-le en utilisant l'objectif de modélisation du langage causal. .
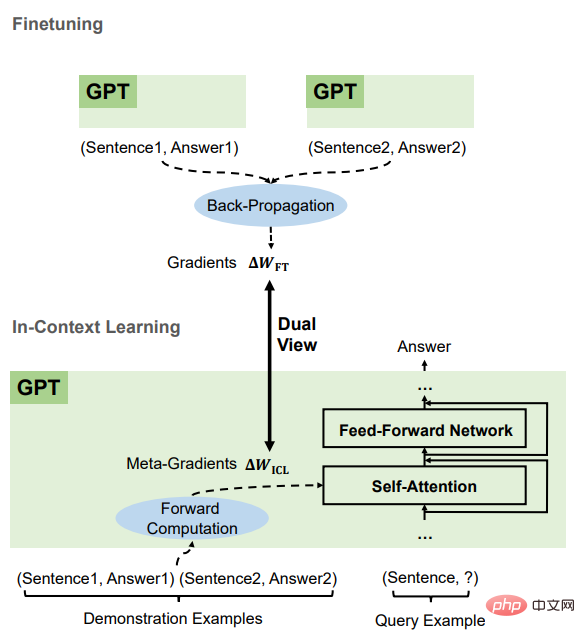
ICL et le réglage fin ont de nombreux attributs communs#🎜 🎜#, Il comprend principalement quatre aspects.
Tout est descente en dégradé#🎜 🎜#On peut constater que l'ICL et le réglage fin mettent à jour Wzsl, c'est-à-dire la descente de gradient. La seule différence est que l'ICL génère des méta-gradients par calcul direct, tandis que le réglage fin obtient le gradient réel par rétro-propagation.
Mêmes informations de formation
#🎜 🎜 #Le méta-gradient d'ICL est obtenu sur la base de l'exemple de démonstration, et le gradient de réglage fin est également obtenu à partir du même échantillon de formation, c'est-à-dire que ICL et le réglage fin partagent la même source d'informations de formation.
L'ordre causal des exemples de formation est le même
#🎜🎜 #ICL et le réglage fin partagent l'ordre causal des exemples de formation. ICL utilise des transformateurs uniquement pour le décodeur, donc les jetons suivants dans l'exemple n'affecteront pas les jetons précédents pour le réglage fin, puisque l'ordre de ; Les exemples de formation sont les mêmes, et une seule époque est formée, on peut donc également garantir que les échantillons suivants n'auront aucun impact sur les échantillons précédents.
tous agissent sur l'attention
# 🎜 🎜#Par rapport à l'apprentissage zéro-shot, l'impact direct de l'ICL et du réglage fin se limite au calcul de la clé et de la valeur de l'attention. Pour ICL, les paramètres du modèle sont inchangés et il code les informations d'exemple en clés et valeurs supplémentaires pour modifier le comportement d'attention. Pour les limitations introduites lors du réglage fin, les informations de formation ne peuvent affecter que la projection des clés d'attention et ; valeurs dans la matrice. Sur la base de ces caractéristiques communes entre l'ICL et le réglage fin, les chercheurs estiment qu'il est raisonnable de comprendre l'ICL comme une sorte de réglage fin implicite. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 # Partie expérimentale # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # Tâches et ensembles de données # 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # # # 🎜🎜#
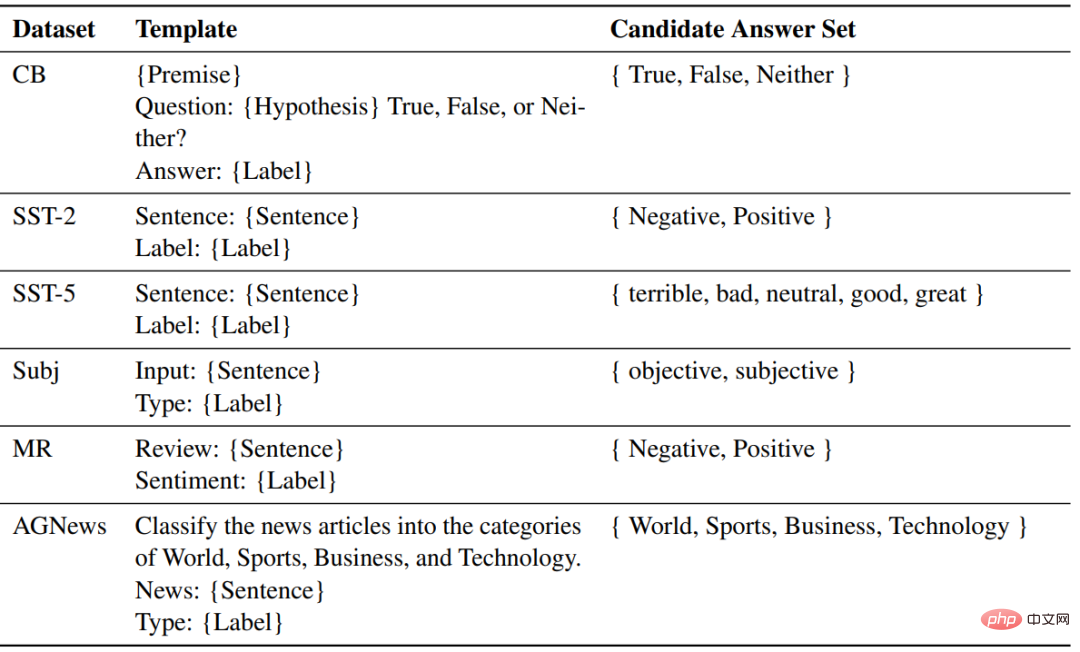
Les chercheurs ont sélectionné six ensembles de données dans trois tâches de classification pour comparer l'ICL et affiner, notamment SST2, SST-5, MR et Subj pour la classification des émotions. AGNews est un sujet. ensemble de données de classification ; CB est utilisé pour le raisonnement en langage naturel.
Configuration expérimentale
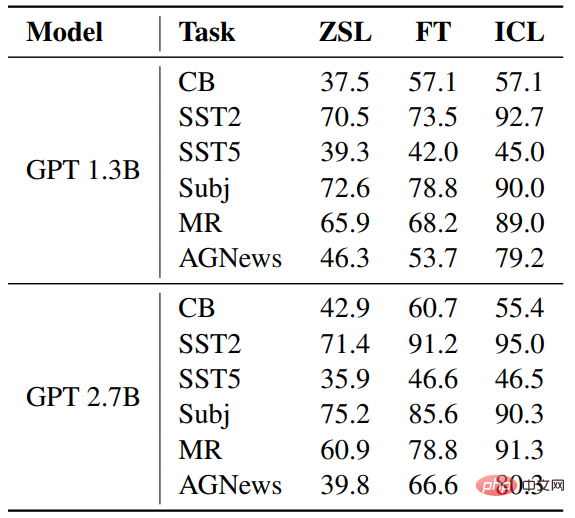
#🎜 🎜# La partie modèle utilise deux modèles de langage pré-entraînés similaires à GPT, publiés par fairseq, avec des tailles de paramètres de 1,3B et 2,7B respectivement. # 🎜🎜#
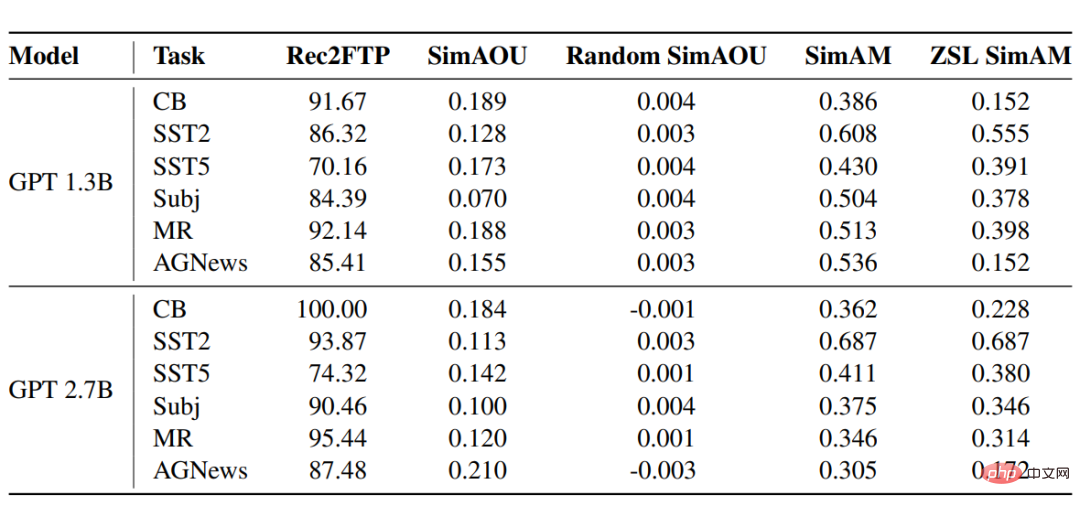
Pour chaque tâche, utilisez le même modèle pour formater les échantillons pour ZSL, ICL et le réglage fin.Résultat #🎜🎜 #Précis Notez L'ICL et le réglage fin ont tous deux réalisé des améliorations considérables par rapport à ZSL, ce qui signifie que leurs optimisations sont toutes deux bonnes pour ces tâches d'aide en aval. De plus, ICL est préférable à un réglage fin dans quelques cas. Rec2FTP(Rappel pour affiner les prédictions)# 🎜 🎜 #
SimAOU (Similarité des mises à jour de sortie d'attention)
SimAM (Similarité de la carte d'attention) De même, au niveau attentionnel et comportemental, les résultats expérimentaux prouvent que l'ICL se comporte de manière similaire au réglage fin.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI