
Maison >Périphériques technologiques >IA >La sous-revue Nature de la Hillhouse School of Artificial Intelligence de l'Université Renmin tente d'utiliser des modèles de base multimodaux pour évoluer vers l'intelligence artificielle générale.
La sous-revue Nature de la Hillhouse School of Artificial Intelligence de l'Université Renmin tente d'utiliser des modèles de base multimodaux pour évoluer vers l'intelligence artificielle générale.

- 王林avant
- 2023-05-09 14:34:09783parcourir
Récemment, le professeur Lu Zhiwu, le professeur agrégé permanent Sun Hao et le doyen du professeur Wen Jirong de la Hillhouse School of Artificial Intelligence de l'Université Renmin de Chine ont publié un article en tant qu'auteurs co-correspondants dans la revue internationale complète "Nature Communications" (anglais nom : Nature Communications, dénommé Nat Commun) a publié un article de recherche intitulé « Vers une intelligence générale artificielle via un modèle de fondation multimodal ». Le premier auteur de l'article est le doctorant Fei Nanyi. Ce travail tente d’exploiter les modèles de base multimodaux vers l’intelligence artificielle générale et aura de larges implications pour divers domaines de l’IA+ tels que les neurosciences et les soins de santé. Cet article est une interprétation de cet article. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # 🎜🎜 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # # Lien papier :https://www.nature.com/articles/s41467-022-30761-2

Lien du code : https:/ /github.com/neilfei/brivl-nmi
- L'objectif fondamental de l'intelligence artificielle est d'imiter les principales activités cognitives humaines, telles que perception, mémoire, raisonnement, etc. Bien que de nombreux algorithmes ou modèles d'intelligence artificielle aient connu un grand succès dans divers domaines de recherche, la plupart des recherches sur l'intelligence artificielle sont encore limitées par l'acquisition de grandes quantités de données étiquetées ou par des ressources informatiques insuffisantes pour prendre en charge la formation sur des données à grande échelle. une seule capacité cognitive.
- Pour surmonter ces limitations et faire un pas vers l'intelligence artificielle générale, nous avons développé un modèle de base multi-modalité (langage visuel), également appelé modèle de pré-formation. De plus, pour que le modèle obtienne une forte capacité de généralisation, nous proposons que les images et les textes dans les données d'entraînement suivent l'hypothèse de faible corrélation sémantique (comme le montre la figure 1b), plutôt que la correspondance fine des zones d'images et des mots. (forte corrélation sémantique), en raison de la forte corrélation sémantique. L'hypothèse d'une corrélation sémantique fera perdre au modèle les émotions et les pensées complexes que les gens impliquent lors du sous-titrage des images. Figure 1 : Basé sur le modèle BriVL faible d’hypothèse de relation sémantique. a. Comparaison entre notre modèle BriVL et le cerveau humain dans le traitement des informations du langage visuel. b. Comparaison de la modélisation de données sémantiques faibles et de la modélisation de données sémantiques fortes. En s'entraînant sur des données d'images et de textes à grande échelle explorées sur Internet, le modèle de base multimodal que nous avons obtenu montre une puissante capacité polyvalente et imagination. Nous pensons que nos travaux représentent une étape importante (bien que potentiellement petite) vers l’intelligence artificielle générale et auront de vastes implications pour divers domaines de l’IA+ tels que les neurosciences et les soins de santé.
Method
Nous avons développé un modèle de base multimodal à grande échelle pour mener des formations auto-supervisées sur des données multimodales massives, et Nommez-le BriVL (Bridging-Vision-and-Language).
Tout d'abord, nous utilisons un ensemble de données graphiques et textuelles multi-sources à grande échelle construit à partir d'Internet, appelé Weak Semantic Correlation Dataset (WSCD). WSCD collecte des paires image-texte chinois provenant de plusieurs sources sur le Web, notamment des actualités, des encyclopédies et des médias sociaux. Nous avons uniquement filtré les données pornographiques et sensibles dans WSCD sans aucune forme d'édition ou de modification des données originales afin de maintenir leur distribution naturelle des données. Au total, le WSCD compte environ 650 millions de paires image-texte couvrant de nombreux sujets tels que le sport, la vie quotidienne et les films. 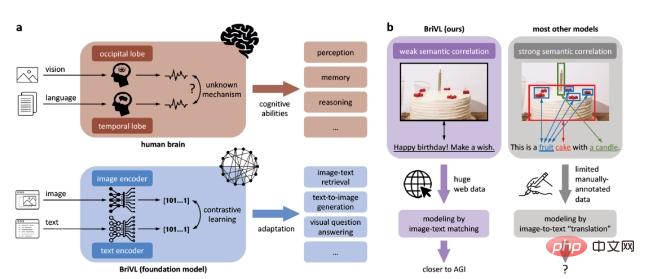

Deuxièmement, pour notre architecture de réseau, puisqu'il n'y a pas nécessairement de correspondance régionale fine de mots entre les images et les textes, nous abandonnons le détecteur d'objets qui prend beaucoup de temps, en adoptant une architecture simple à deux tours, il est capable de coder la saisie d'images et de texte via deux encodeurs indépendants (Figure 2). La structure à deux tours présente des avantages évidents en termes d'efficacité dans le processus d'inférence, car les caractéristiques de l'ensemble candidat peuvent être calculées et indexées avant l'interrogation, répondant ainsi aux exigences en temps réel des applications du monde réel. Troisièmement, avec le développement de technologies de formation distribuées à grande échelle et d’apprentissage auto-supervisé, il est devenu possible de former des modèles avec des données multimodales massives non étiquetées.
Plus précisément, afin de modéliser la faible corrélation des paires image-texte et d'apprendre un espace sémantique unifié, nous avons conçu un algorithme d'apprentissage contrastif multimodal basé sur la méthode d'apprentissage contrastif monomodal MoCo. Comme le montre la figure 2, notre modèle BriVL utilise le mécanisme d'impulsion pour maintenir dynamiquement la file d'attente d'échantillons négatifs dans différents lots d'entraînement. De cette façon, nous disposons d'un nombre relativement grand d'échantillons négatifs (critiques pour l'apprentissage contrastif), tout en utilisant une taille de lot relativement petite pour réduire l'utilisation de la mémoire GPU (c'est-à-dire des économies de ressources GPU).
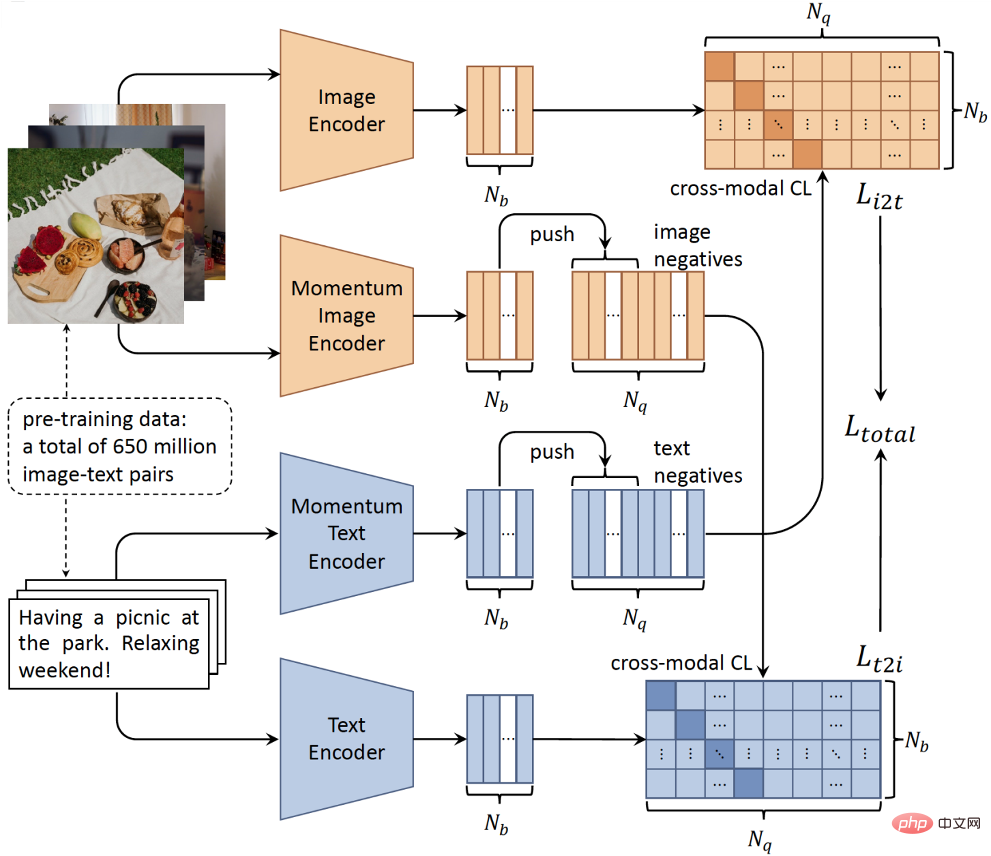
Figure 2 : Diagramme schématique du modèle BriVL pour la pré-formation multimodale à grande échelle.
Principaux résultats
Visualisation du réseau neuronal
Lorsque nous entendons des mots ou des phrases descriptives, certaines scènes nous viennent à l'esprit. Pour notre BriVL, après avoir été pré-entraîné sur un si grand nombre de paires image-texte faiblement corrélées, nous sommes très curieux de savoir ce qu'il imagine lorsqu'on lui donne du texte.
Plus précisément, nous saisissons d'abord un morceau de texte et obtenons son intégration de texte via l'encodeur de texte de BriVL. Ensuite, nous initialisons de manière aléatoire une image bruyante et obtenons l'intégration de ses fonctionnalités via l'encodeur d'image. Étant donné que l’image d’entrée est initialisée de manière aléatoire, ses caractéristiques doivent être incompatibles avec celles du texte d’entrée. Par conséquent, nous définissons l'objectif de faire correspondre deux intégrations de fonctionnalités et mettons à jour l'image d'entrée via la rétropropagation. L'image résultante montre clairement comment BriVL a imaginé le texte saisi. Ici, nous n'utilisons aucun module ou donnée supplémentaire, et le BriVL pré-entraîné est également gelé tout au long du processus de visualisation.
Nous introduisons d'abord la capacité de BriVL à imaginer certains concepts sémantiques de haut niveau (Figure 3). Comme vous pouvez le constater, même si ces concepts sont très abstraits, la visualisation est capable de montrer leur forme concrète (par exemple, « nature » : des plantes ressemblant à de l'herbe ; « temps » : une horloge ; « science » : un visage avec des lunettes et une fiole Erlenmeyer ; "Dreamland" : des nuages, un pont vers la porte et une ambiance onirique). Cette capacité à généraliser des concepts abstraits à une série d'objets concrets démontre l'efficacité de notre pré-formation multimodale utilisant uniquement des données faiblement sémantiquement liées.

Figure 3 : L'imagination des concepts abstraits du modèle BriVL.
Dans la figure 4, nous montrons l'imagination de BriVL pour les phrases. L'imagination de BriVL de "Il y a du soleil derrière les nuages" incarne non seulement littéralement le soleil derrière les nuages, mais semble également montrer des conditions dangereuses en mer (il y a des objets ressemblant à des navires et des vagues sur la gauche), exprimant le sens implicite de ceci phrase . Dans la visualisation « Blooming as Summer Flowers », nous pouvons voir une grappe de fleurs. Les entrées de texte les plus complexes pour les deux scénarios suivants proviennent toutes deux de la poésie chinoise ancienne et leur syntaxe est complètement différente de la grande majorité des textes de l'ensemble de formation. Il semble que BriVL puisse aussi bien les comprendre : pour « Trois ou deux branches de fleurs de pêcher à l'extérieur du bambou », on voit qu'il y a des bambous et des fleurs roses ; pour « Le soleil est sur les montagnes, le fleuve Jaune se jette dans les montagnes ; mer", on peut voir Les arbres sur la montagne couvrent le soleil couchant, et il y a un petit bateau sur la rivière devant. Dans l’ensemble, nous avons constaté que BriVL reste très imaginatif même lorsqu’il est sollicité par des phrases complexes.


Figure 4 : Imagination des phrases chinoises du modèle BriVL.
Dans la figure 5, plusieurs textes similaires sont utilisés pour la visualisation du réseau neuronal de BriVL. Pour les « Montagnes avec forêts », il y a plus de zones vertes dans l'image ; pour les « Montagnes avec des pierres », il y a plus de rochers dans l'image ; pour les « Montagnes avec neige », le sol autour des arbres du milieu est soit blanc, soit bleu ; avec les cascades, on peut voir de l'eau bleue tomber et même de la vapeur d'eau. Ces visualisations démontrent que BriVL peut comprendre et imaginer avec précision les modificateurs de montagne.
Figure 5 : Imagination du modèle BriVL de « montagnes avec… ».
文graphique généré La visualisation du réseau neuronal est très simple, mais peut parfois être difficile à interpréter. Nous avons donc développé une approche alternative de visualisation/interprétabilité afin que le contenu imaginé par BriVL puisse être mieux compris par nous, les humains. Plus précisément, nous exploitons VQGAN pour générer des images sous la direction de BriVL car VQGAN, pré-entraîné sur l'ensemble de données ImageNet, est très efficace pour générer des images réalistes. Nous obtenons d'abord aléatoirement une séquence de jetons et obtenons une image générée à partir d'un VQGAN pré-entraîné. Ensuite, nous introduisons l'image générée dans l'encodeur d'image de BriVL et un morceau de texte dans l'encodeur de texte. Enfin, nous définissons la cible de correspondance entre les incorporations d'images et de texte et mettons à jour la séquence de jetons initiale via la rétropropagation. Comme pour les visualisations de réseaux neuronaux, VQGAN et BriVL sont gelés pendant le processus de génération. À titre de comparaison, nous montrons également des images générées par le modèle CLIP d'OpenAI au lieu de BriVL.
Nous avons d'abord sélectionné quatre entrées de texte, montrant les résultats du graphique de génération de texte de CLIP et de notre BriVL dans la figure 6 et la figure 7 respectivement. CLIP et BriVL comprennent bien le texte, mais nous observons également deux différences majeures. Premièrement, des éléments de style dessin animé apparaîtront dans les images générées par CLIP, tandis que les images générées par BriVL seront plus réalistes et naturelles. Deuxièmement, CLIP a tendance à simplement placer des éléments ensemble, tandis que BriVL produit des images plus globalement unifiées. La première différence peut être due aux différentes données de formation utilisées par CLIP et BriVL. Les images de nos données de formation sont extraites d'Internet (pour la plupart de vraies photos), alors qu'il peut y avoir un certain nombre d'images de dessins animés dans les données de formation de CLIP. La deuxième différence peut être due au fait que CLIP utilise des paires image-texte avec une forte corrélation sémantique (via un filtrage de mots), alors que nous utilisons des données faiblement corrélées. Cela signifie que lors de la pré-formation multimodale, CLIP est plus susceptible d'apprendre les correspondances entre des objets spécifiques et des mots/phrases, tandis que BriVL tente de comprendre chaque image avec le texte donné dans son ensemble. Figure 6 : CLIP (avec ResNet-50x4) Exemple de graphique de génération de texte à l'aide de VQGAN.
 # 🎜🎜#
# 🎜🎜#
Figure 8 : Notre BriVL avec l'aide de VQGAN Une série d'exemples de génération de contenu cohérent.

Dans la figure 9, nous avons sélectionné certains concepts/scénarios que les humains voient rarement (comme « mer brûlante » et « forêt rougeoyante »), même ceux qui n'existent pas dans la vraie vie (comme « ville cyberpunk » et « château dans les nuages »). Cela prouve que les performances supérieures de BriVL ne proviennent pas d'un surajustement des données de pré-entraînement, car les concepts/scénarios saisis ici n'existent même pas dans la vie réelle (bien sûr, ils ne figurent probablement pas dans l'ensemble de données de pré-entraînement). ). De plus, ces exemples générés réaffirment l'avantage de la pré-entraînement de BriVL sur des données faiblement sémantiquement liées (car un alignement de mots régionaux à granularité fine nuirait à la capacité d'imagination de BriVL).

Figure 9 : Plus de résultats de génération de texte BriVL, les concepts/scénarios ne sont pas souvent vus par les humains voire n'existent pas dans la vraie vie.
De plus, nous avons également appliqué BriVL à plusieurs tâches en aval telles que la classification des images de télédétection par tir zéro, la classification par tir zéro des nouvelles chinoises, la réponse visuelle aux questions, etc., et avons obtenu des résultats intéressants. Veuillez consulter l'original. texte de notre article pour plus de détails.
Conclusion et discussion
Nous avons développé un modèle de base multimodal à grande échelle appelé BriVL, qui a été formé sur 650 millions d'images et de textes faiblement sémantiquement liés. Nous démontrons intuitivement l’espace d’intégration image-texte aligné grâce à la visualisation du réseau neuronal et aux graphiques générés par le texte. En outre, des expériences sur d’autres tâches en aval montrent également les capacités d’apprentissage/transfert inter-domaines de BriVL et les avantages de l’apprentissage multimodal par rapport à l’apprentissage monomodal. En particulier, nous avons constaté que BriVL semble avoir acquis une certaine capacité à imaginer et à raisonner. Nous pensons que ces avantages proviennent principalement de l’hypothèse de faible corrélation sémantique suivie par BriVL. Autrement dit, en exploitant des émotions et des pensées humaines complexes dans des paires image-texte faiblement corrélées, notre BriVL devient plus cognitive.
Nous pensons que ce pas que nous franchissons vers l'intelligence artificielle générale aura un large impact non seulement sur le domaine de l'intelligence artificielle lui-même, mais également sur divers domaines de l'IA+. Pour la recherche sur l'intelligence artificielle, basée sur notre cadre de pré-formation multimodal économe en ressources GPU, les chercheurs peuvent facilement étendre BriVL à des ampleurs plus grandes et à davantage de modalités pour obtenir un modèle de base plus général. Avec l’aide de modèles de base multimodaux à grande échelle, il est également plus facile pour les chercheurs d’explorer de nouvelles tâches (en particulier celles ne disposant pas d’échantillons d’annotations humaines suffisants). Pour le domaine de l'IA+, le modèle de base peut s'adapter rapidement à des environnements de travail spécifiques grâce à ses fortes capacités de généralisation. Par exemple, dans le domaine des soins de santé, les modèles de base multimodaux peuvent exploiter pleinement les données multimodales des cas pour améliorer la précision du diagnostic ; dans le domaine des neurosciences, les modèles de base multimodaux peuvent même aider à découvrir comment les informations multimodales sont utilisées dans les mécanismes de fusion ; dans le cerveau humain, car les réseaux neuronaux artificiels sont plus faciles à étudier que les systèmes neuronaux réels du cerveau humain.
Néanmoins, les modèles de base multimodaux sont encore confrontés à certains risques et défis. Le modèle de base peut apprendre des préjugés et des stéréotypes sur certaines choses, et ces problèmes doivent être soigneusement abordés avant la formation du modèle, puis surveillés et traités dans les applications en aval. De plus, à mesure que le modèle de base acquiert de plus en plus de capacités, nous devons veiller à ce qu'il ne soit pas utilisé par des personnes mal intentionnées pour éviter d'avoir un impact négatif sur la société. En outre, les recherches futures sur le modèle de base présentent également certains défis : comment développer des outils d'interprétabilité de modèle plus approfondis, comment créer des ensembles de données de pré-entraînement avec plus de modalités et comment utiliser des techniques de réglage fin plus efficaces pour transformer le modèle de base. modèle appliqué à diverses tâches en aval.
Les auteurs de cet article sont : Fei Nanyi, Lu Zhiwu, Gao Yizhao, Yang Guoxing, Huo Yuqi, Wen Jingyuan, Lu Haoyu, Song Ruihua, Gao Xin, Xiang Tao, Sun Hao, Wen Jirong le co- ; l'auteur correspondant est le professeur Lu Zhiwu du PNJ Gao Ling, le professeur agrégé permanent Sun Hao et le professeur Wen Jirong de l'École d'intelligence artificielle. L'article a été publié dans la revue internationale « Nature Communications » (nom anglais : Nature Communications, appelé Nat Commun). Cet article a été interprété par Fei Nanyi.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI