
Maison >Périphériques technologiques >IA >La conférence EMNLP 2022 est officiellement terminée, le meilleur article long, le meilleur article court et d'autres récompenses sont annoncées
La conférence EMNLP 2022 est officiellement terminée, le meilleur article long, le meilleur article court et d'autres récompenses sont annoncées

- PHPzavant
- 2023-05-09 14:10:141563parcourir
Récemment, l'EMNLP 2022, la plus grande conférence dans le domaine du traitement du langage naturel, s'est tenue à Abu Dhabi, la capitale des Émirats arabes unis.

Au total, 4190 articles ont été soumis à la conférence de cette année, et 829 articles ont finalement été acceptés (715 articles longs, 114 articles), avec un taux d'acceptation global de 20 %, ce qui n'est pas très différent des précédents. années.
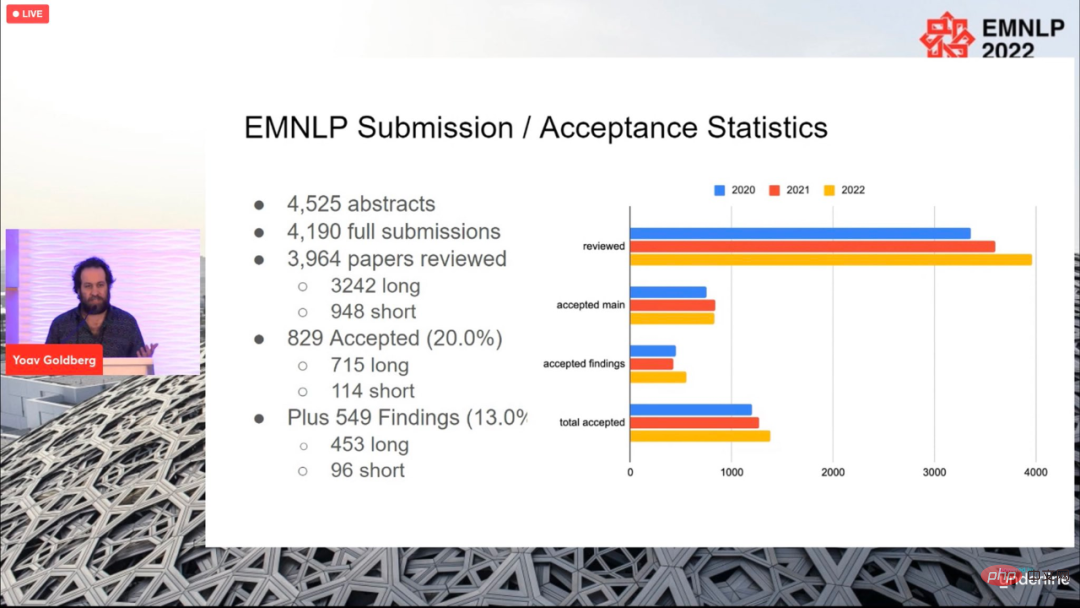
La conférence s'est terminée le 11 décembre, heure locale, et les prix des articles de cette année ont également été annoncés, notamment le meilleur article long (1 pièce), le meilleur article court (1 pièce) et le meilleur article de démonstration (1 article).
Meilleur long article

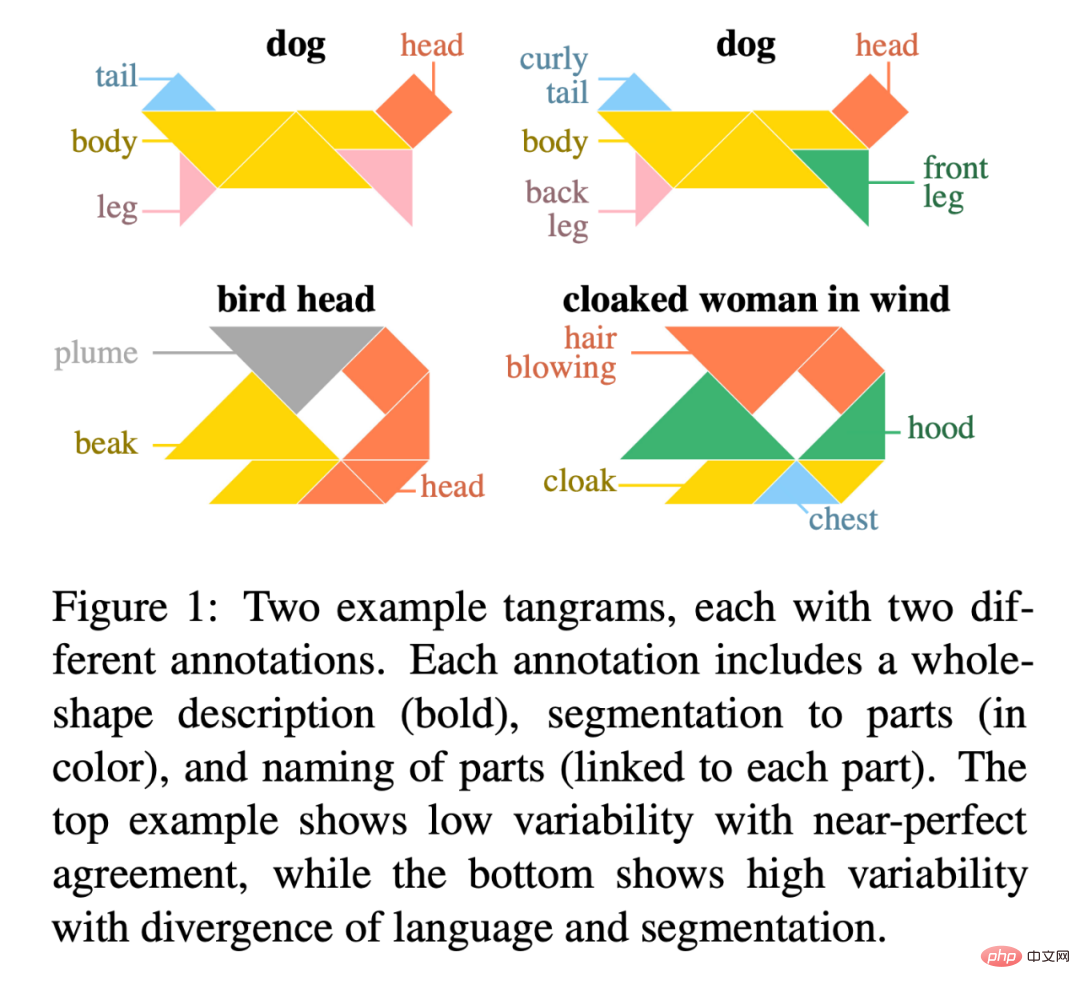
Article : Raisonnement visuel abstrait avec des formes de Tangram
- Auteurs : Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert D. Hawkins, Yoav Artzi
- Institutions : Cornell University, New York University, Allen Institute, Princeton University
- Lien papier : https://arxiv.org/pdf/2211.16492.pdf
Paper résumé : Dans cet article, les chercheurs présentent "KiloGram", une bibliothèque de ressources pour étudier le raisonnement visuel abstrait des humains et des machines. KiloGram améliore considérablement les ressources existantes de deux manières. Tout d’abord, les chercheurs ont conservé et numérisé 1 016 formes, créant ainsi une collection deux fois plus grande que celles utilisées dans les travaux existants. Cette collection augmente considérablement la couverture de toute la gamme des variations de dénomination, offrant une perspective plus complète sur le comportement humain en matière de dénomination. Deuxièmement, la collection traite chaque tangram non pas comme une forme globale unique, mais comme une forme vectorielle composée des pièces du puzzle original. Cette décomposition permet de raisonner sur des formes entières et leurs parties. Les chercheurs ont utilisé cette nouvelle collection de graphiques de puzzles numériques pour collecter une grande quantité de données de description textuelle, reflétant la grande diversité des comportements de dénomination.
Les chercheurs ont exploité le crowdsourcing pour étendre le processus d'annotation, en collectant plusieurs annotations pour chaque forme afin de représenter la distribution des annotations qu'elle a suscitées plutôt qu'un seul échantillon. Au total, 13 404 annotations ont été collectées, chacune décrivant un objet complet et ses parties divisées. Le potentiel de
KiloGram est vaste. Nous avons utilisé cette ressource pour évaluer les capacités de raisonnement visuel abstrait des modèles multimodaux récents et avons observé que les poids pré-entraînés présentaient des capacités de raisonnement abstrait limitées qui s'amélioraient considérablement avec un réglage fin. Ils ont également observé que les descriptions explicites facilitent le raisonnement abstrait à la fois par les humains et les modèles, en particulier lors du codage conjoint du langage et de l'entrée visuelle.
La figure 1 est un exemple de deux tangrams, chacun avec deux annotations différentes. Chaque annotation comprend une description de la forme entière (en gras), une segmentation des parties (en couleur) et un nom pour chaque partie (liée à chaque partie). L'exemple supérieur montre une faible variabilité pour un accord presque parfait, tandis que l'exemple inférieur montre une forte variabilité pour la divergence de langue et de segmentation.
Adresse KiloGram : https://lil.nlp.cornell.edu/kilogram
Les nominations pour les meilleurs articles longs pour cette conférence sont de Kayo Yin et Graham Neubig Obtenu par deux chercheurs.
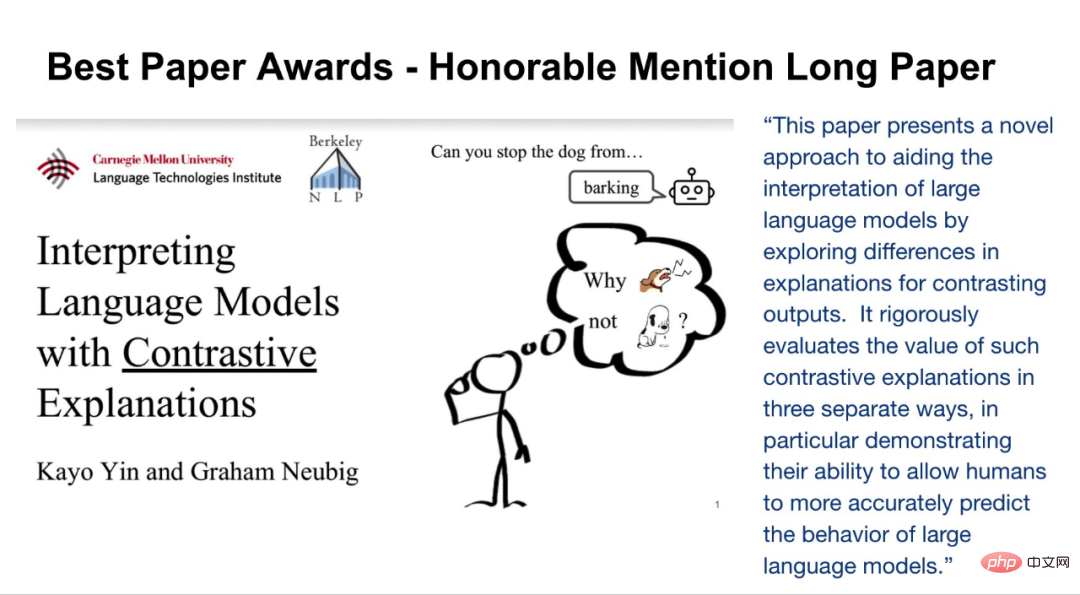
Article : Interprétation des modèles linguistiques avec des explications contrastées
- Auteur : Kayo Yin, Graham Neubig
Résumé de l'article : La méthode d'interprétabilité du modèle est souvent utilisée pour expliquer la PNL Modélisez les décisions sur des tâches telles que la classification de texte, où l'espace de sortie est relativement petit. Cependant, lorsqu’elle est appliquée à la génération de langage, l’espace de sortie est souvent constitué de dizaines de milliers de jetons, et ces méthodes ne peuvent pas fournir d’explications informatives. Les modèles linguistiques doivent prendre en compte diverses caractéristiques pour prédire un jeton, telles que sa partie du discours, son nombre, son temps ou sa sémantique. Étant donné que les méthodes explicatives existantes combinent les preuves de toutes ces caractéristiques en une seule explication, cela est moins interprétable pour la compréhension humaine.
Pour distinguer les différentes décisions en matière de modélisation du langage, les chercheurs explorent des modèles de langage qui se concentrent sur des explications contrastées. Ils recherchent des jetons d'entrée qui se démarquent et expliquent pourquoi le modèle a prédit un jeton mais pas un autre. La recherche démontre que les explications contrastées sont bien meilleures que les explications non contrastées pour valider les phénomènes grammaticaux majeurs et qu'elles améliorent considérablement la simulatabilité du modèle contrastif pour les observateurs humains. Les chercheurs ont également identifié des groupes de décisions contrastées pour lesquels le modèle a utilisé des preuves similaires et ont pu décrire les jetons d'entrée utilisés par le modèle dans diverses décisions de génération de langage.
Adresse du code : https://github.com/kayoyin/interpret-lm
Meilleur article court

Article : Apprentissage de la représentation de la paternité par sujet régularisé
- Auteur : Jitkapat Sawatphol, Nonthakit Chaiwong, Can Udomcharoenchaikit, Sarana Nutanong
- Institution : VISTEC Institute of Science and Technology, Thaïlande
Résumé : Dans cette étude, les chercheurs ont proposé la représentation de la paternité régulière isation, un cadre de distillation qui améliore les performances multi-sujets et peut également gérer des auteurs invisibles. Cette approche peut être appliquée à n’importe quel modèle de représentation de la paternité. Les résultats expérimentaux montrent que dans un contexte multi-sujets, les performances 4/6 sont améliorées. Dans le même temps, l'analyse des chercheurs montre que dans les ensembles de données comportant un grand nombre de sujets, les fragments de formation répartis sur plusieurs sujets présentent des problèmes de fuite d'informations sur les sujets, affaiblissant ainsi leur capacité à évaluer les attributs inter-sujets. "Meilleur article de démonstration" Luccioni et al
Institution : Hugging Face
Lien papier : https://arxiv.org/pdf/2210.01970.pdf
- Résumé papier : L'évaluation est un machine Élément clé de l'apprentissage (ML), cette étude présente Evaluate and Evaluation on Hub - un ensemble d'outils qui aident à évaluer les modèles et les ensembles de données en ML. Evaluate est une bibliothèque permettant de comparer différents modèles et ensembles de données, prenant en charge diverses métriques. La bibliothèque Evaluate est conçue pour prendre en charge la reproductibilité des évaluations, documenter le processus d'évaluation et étendre la portée des évaluations pour couvrir davantage d'aspects des performances du modèle. Il comprend plus de 50 implémentations efficaces de spécifications pour une variété de domaines et de scénarios, une documentation interactive et la possibilité de partager facilement les résultats de mise en œuvre et d'évaluation.
- Adresse du projet : https://github.com/huggingface/evaluate De plus, le chercheur a également lancé Évaluation on the Hub, une plateforme qui permet d'évaluer gratuitement plus de 75 000 modèles sur Hugging Face. Hub et 11 000 ensembles de données pour une évaluation à grande échelle en un seul clic.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI