
Maison >développement back-end >Tutoriel Python >Comment utiliser CountVectorizer dans le sklearn de Python ?
Comment utiliser CountVectorizer dans le sklearn de Python ?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-05-07 23:58:062103parcourir
Introduction
Documentation officielle de CountVectorizer.
Vectorisez une collection de documents dans une matrice de comptage.
Si vous ne fournissez pas de dictionnaire a priori et n'utilisez pas d'analyseur pour effectuer une sorte de sélection de fonctionnalités, alors le nombre de fonctionnalités sera égal au vocabulaire découvert en analysant les données.
Prétraitement des données
Deux méthodes : 1. Vous pouvez les insérer directement dans le modèle sans segmentation de mots ; 2. Vous pouvez d'abord segmenter le texte chinois.
Le vocabulaire produit par les deux méthodes sera très différent. Des démonstrations spécifiques seront données ultérieurement.
import jieba
import re
from sklearn.feature_extraction.text import CountVectorizer
#原始数据
text = ['很少在公众场合手机外放',
'大部分人都还是很认真去学习的',
'他们会用行动来',
'无论你现在有多颓废,振作起来',
'只需要一点点地改变',
'你的外在和内在都能焕然一新']
#提取中文
text = [' '.join(re.findall('[\u4e00-\u9fa5]+',tt,re.S)) for tt in text]
#分词
text = [' '.join(jieba.lcut(tt)) for tt in text]
text
Construire le modèle
Entraîner le modèle
#构建模型 vectorizer = CountVectorizer() #训练模型 X = vectorizer.fit_transform(text)
Tout le vocabulaire : model.get_feature_names()
#所有文档汇集后生成的词汇 feature_names = vectorizer.get_feature_names() print(feature_names)
Vocabulaire généré sans segmentation de mots

Vocabulaire généré après la segmentation de mots

Matrice de comptage : X .toarray()
#每个文档相对词汇量出现次数形成的矩阵 matrix = X.toarray() print(matrix)

#计数矩阵转化为DataFrame df = pd.DataFrame(matrix, columns=feature_names) df
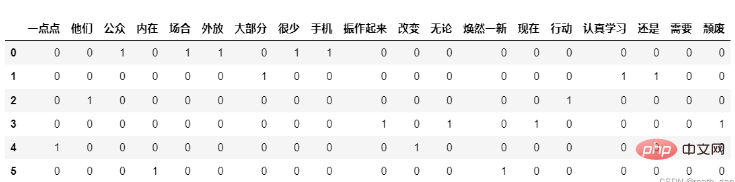
Index de vocabulaire : model.vocabulary_
print(vectorizer.vocabulary_)

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!