
Maison >Périphériques technologiques >IA >A100 implémente une méthode de reconstruction 3D sans convolution 3D et ne prend que 70 ms pour chaque reconstruction d'image
A100 implémente une méthode de reconstruction 3D sans convolution 3D et ne prend que 70 ms pour chaque reconstruction d'image

- PHPzavant
- 2023-05-07 10:43:081682parcourir
La reconstruction de scènes d'intérieur 3D à partir d'images de pose est généralement divisée en deux étapes : l'estimation de la profondeur de l'image, suivie par la fusion de la profondeur et la reconstruction de la surface. Récemment, plusieurs études ont proposé une série de méthodes permettant d'effectuer une reconstruction directement dans l'espace final des caractéristiques volumétriques 3D. Bien que ces méthodes aient obtenu des résultats de reconstruction impressionnants, elles reposent sur des couches convolutives 3D coûteuses, limitant leur application dans des environnements aux ressources limitées.
Aujourd'hui, des chercheurs d'institutions telles que Niantic et UCL tentent de réutiliser les méthodes traditionnelles et de se concentrer sur la prédiction de profondeur multi-vues de haute qualité, réalisant enfin une reconstruction 3D de haute précision à l'aide de méthodes de fusion de profondeur simples et disponibles dans le commerce. .

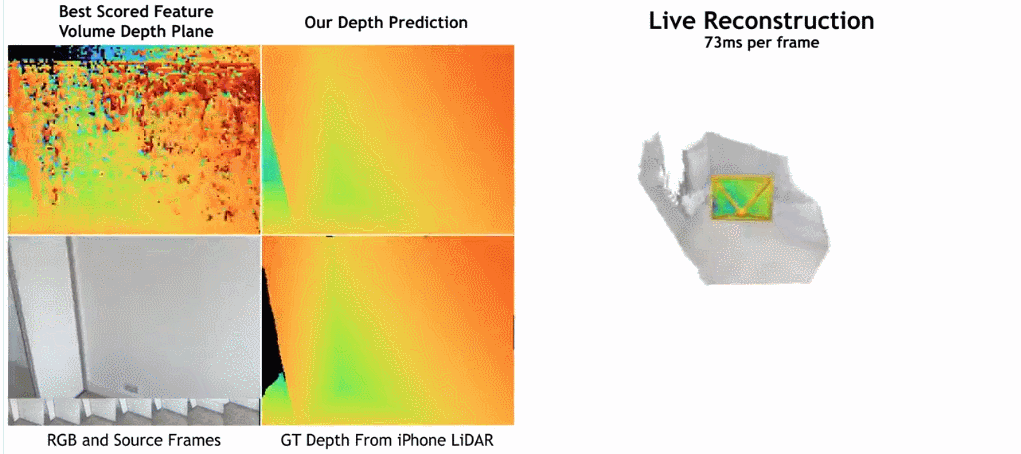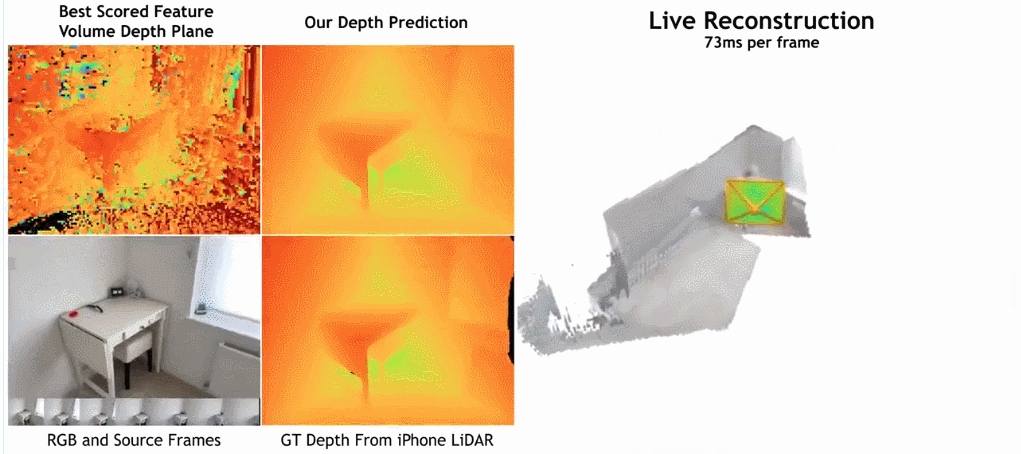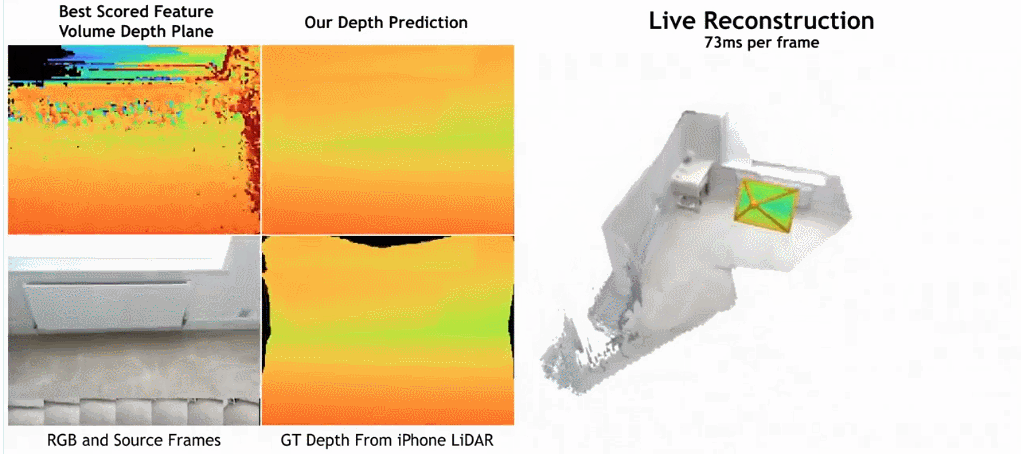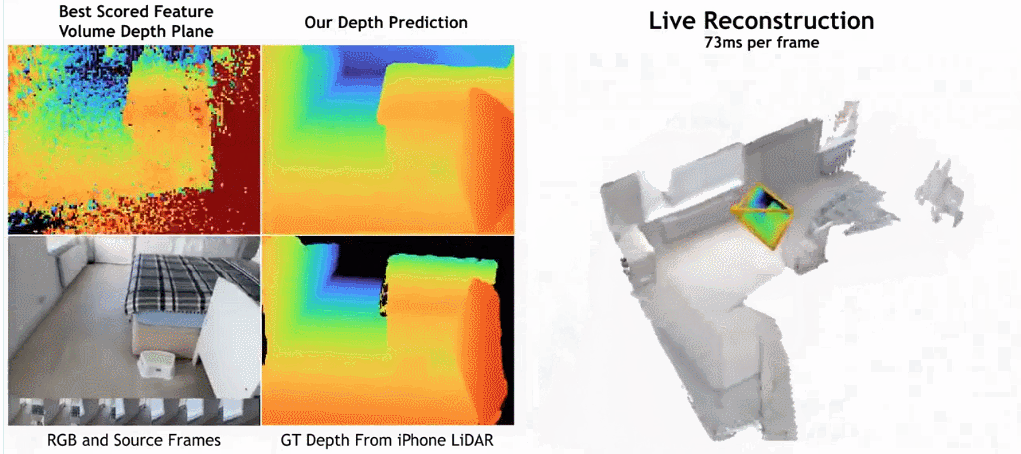
paper Adresse: https://nianticlabs.github.io/simplerecon/resources/simplerecon.pdf

 github Adresse: https://github.com /nianticlabs/simplerecon
github Adresse: https://github.com /nianticlabs/simplerecon
Page d'accueil du papier : https://nianticlabs.github.io/simplerecon/
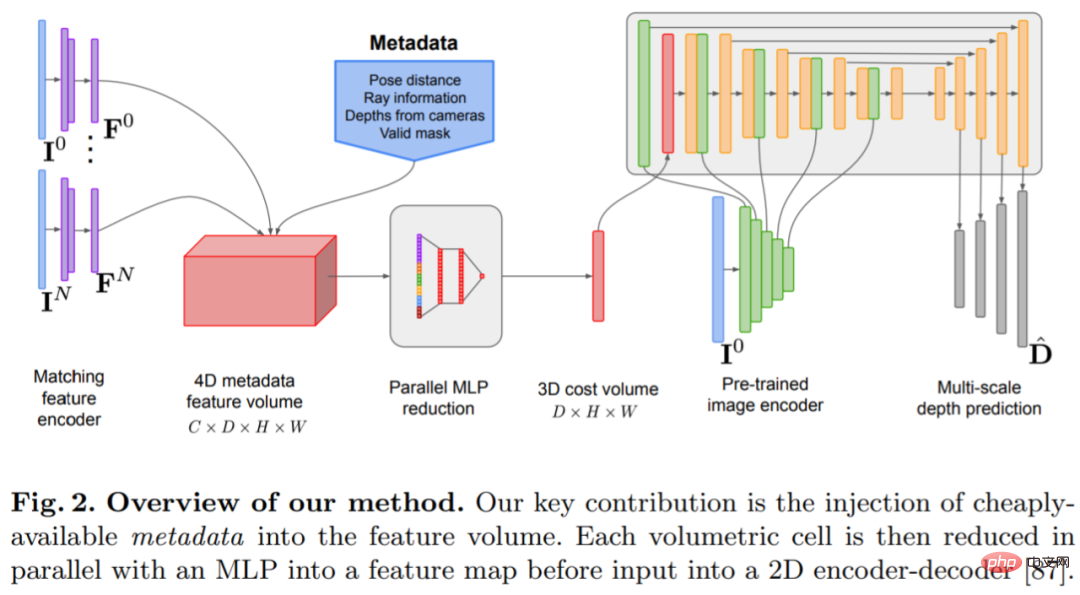
Cette étude utilise des images a priori puissantes ainsi que des quantités de caractéristiques de balayage plan et des pertes géométriques, et est soigneusement conçu un CNN 2D. La méthode proposée, SimpleRecon, obtient des résultats nettement supérieurs en matière d'estimation de la profondeur et permet une reconstruction en ligne et en temps réel avec une faible mémoire.
 Comme le montre la figure ci-dessous, la vitesse de reconstruction de SimpleRecon est très rapide, ne prenant qu'environ 70 ms par image. Les résultats de la comparaison entre
Comme le montre la figure ci-dessous, la vitesse de reconstruction de SimpleRecon est très rapide, ne prenant qu'environ 70 ms par image. Les résultats de la comparaison entre
SimpleRecon et d'autres méthodes sont les suivants :
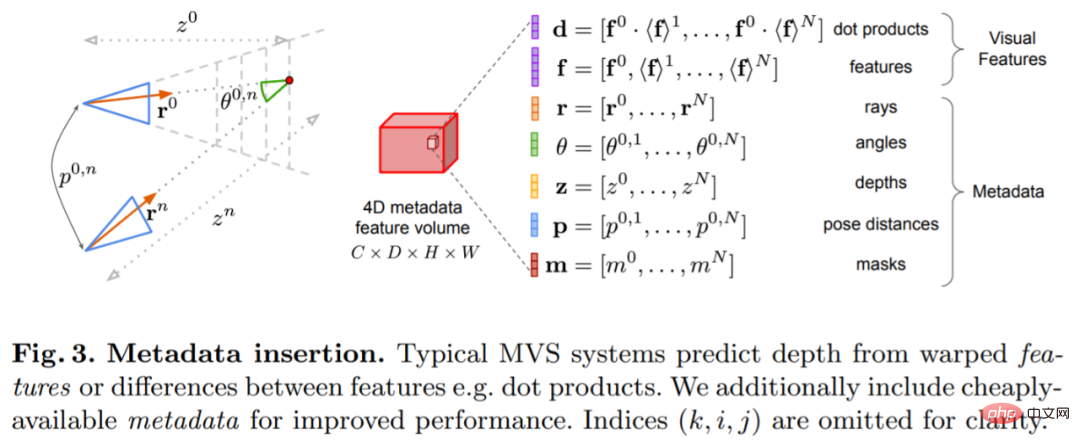
🎜méthode🎜🎜🎜Le modèle d'estimation de profondeur est situé à l'intersection de l'estimation de profondeur monoculaire et du MVS à balayage planaire. Le chercheur utilise le volume de coût ( volume de coût) pour augmenter l'architecture codeur-décodeur de prédiction de profondeur, comme le montre la figure 2. L'encodeur d'image extrait les caractéristiques correspondantes des images de référence et source comme entrée dans le volume de coût. Un réseau de codeurs-décodeurs convolutifs 2D est utilisé pour traiter la sortie du volume de coûts, qui est augmentée par des caractéristiques au niveau de l'image extraites par un encodeur d'image pré-entraîné distinct. 🎜🎜🎜🎜🎜🎜🎜La clé de cette recherche est d'injecter des métadonnées existantes dans le volume de coûts ainsi que des fonctionnalités d'image de profondeur typiques pour permettre au réseau d'accéder à des informations utiles telles que la géométrie et les informations relatives à la pose de la caméra. La figure 3 montre en détail la construction du volume de fonctionnalités. En intégrant ces informations jusqu'alors inexploitées, notre modèle est capable de surpasser considérablement les méthodes précédentes en matière de prédiction en profondeur sans volumes de coûts 4D coûteux, fusion temporelle complexe et processus gaussiens. 🎜🎜🎜🎜🎜🎜🎜L'étude a été implémentée à l'aide de PyTorch et a utilisé EfficientNetV2 S comme épine dorsale, qui possède un décodeur similaire à UNet++. De plus, ils ont également utilisé les 2 premiers blocs de ResNet18 pour l'extraction de fonctionnalités correspondantes, et l'optimiseur a été. AdamW, qui a duré 36 heures sur deux GPU A100 de 40 Go. 🎜🎜🎜Conception de l'architecture du réseau🎜🎜🎜Le réseau est implémenté sur la base de l'architecture d'encodeur-décodeur convolutif 2D. Lors de la construction d'un tel réseau, la recherche a montré qu'il existe des choix de conception importants qui peuvent améliorer considérablement la précision des prévisions de profondeur, notamment : 🎜🎜🎜🎜Fusion du volume et du coût de base : bien que les méthodes de fusion temporelle basées sur RNN soient souvent utilisées, elles augmentent considérablement la complexité du système. Au lieu de cela, l'étude simplifie au maximum la fusion des volumes de coûts et révèle que le simple fait d'ajouter les coûts de correspondance des produits scalaires entre la vue de référence et chaque vue source peut donner des résultats compétitifs avec l'estimation de la profondeur SOTA. 🎜🎜
Encodeur d'image et encodeur de correspondance de fonctionnalités : des recherches antérieures ont montré que l'encodeur d'image est très important pour l'estimation de la profondeur, à la fois dans l'estimation monoculaire et multi-vues. Par exemple, DeepVideoMVS utilise MnasNet comme encodeur d'image, qui a une latence relativement faible. L'étude recommande d'utiliser un encodeur EfficientNetv2 S petit mais plus puissant, qui améliore considérablement la précision de l'estimation de la profondeur, bien que cela se fasse au prix d'un nombre accru de paramètres et d'une réduction de 10 % de la vitesse d'exécution.
Fusion des fonctionnalités d'image multi-échelles dans un encodeur de volume de coût : dans la stéréo de profondeur 2D basée sur CNN et la stéréo multi-vues, les caractéristiques d'image sont généralement combinées avec une sortie de volume de coût à une seule échelle. Récemment, DeepVideoMVS propose d'assembler des fonctionnalités d'image profondes à plusieurs échelles, en ajoutant des connexions sautées entre les encodeurs d'image et les encodeurs de volume de coût à toutes les résolutions. Ceci est utile pour les réseaux de fusion basés sur LSTM, et l’étude a révélé que cela est également important pour leur architecture.
Expériences
Cette étude a entraîné et évalué la méthode proposée sur l'ensemble de données de reconstruction de scène 3D ScanNetv2. Le tableau 1 ci-dessous utilise les métriques proposées par Eigen et al. (2014) pour évaluer les performances de prédiction de profondeur de plusieurs modèles de réseau.
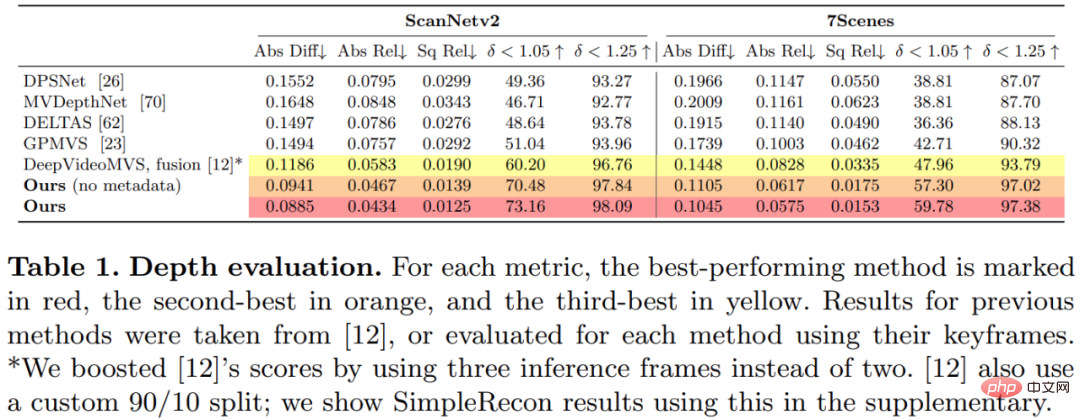
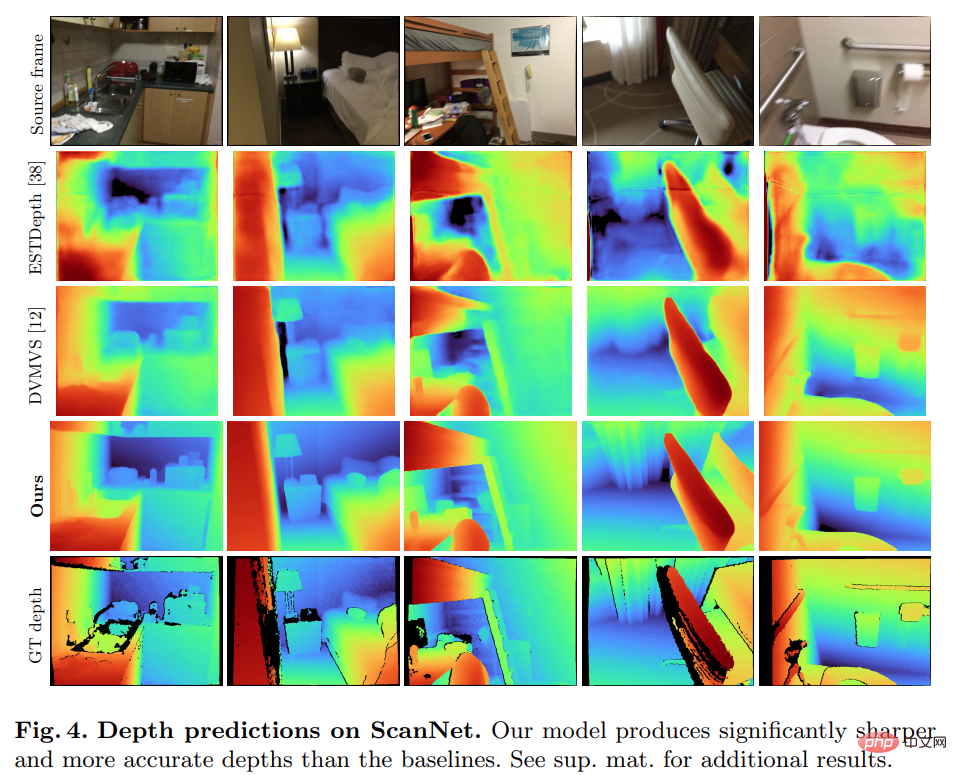
Étonnamment, le modèle proposé dans cette étude n'utilise pas de convolution 3D, mais surpasse tous les modèles de base en termes d'indicateurs de prédiction de profondeur. De plus, les modèles de base qui n’utilisent pas le codage de métadonnées fonctionnent également mieux que les méthodes précédentes, ce qui indique qu’un réseau 2D bien conçu et entraîné est suffisant pour une estimation de profondeur de haute qualité. Les figures 4 et 5 ci-dessous montrent des résultats qualitatifs pour la profondeur et la normale.

Cette étude a utilisé le protocole standard établi par TransformerFusion pour l'évaluation de la reconstruction 3D, et les résultats sont présentés dans le tableau 2 ci-dessous.
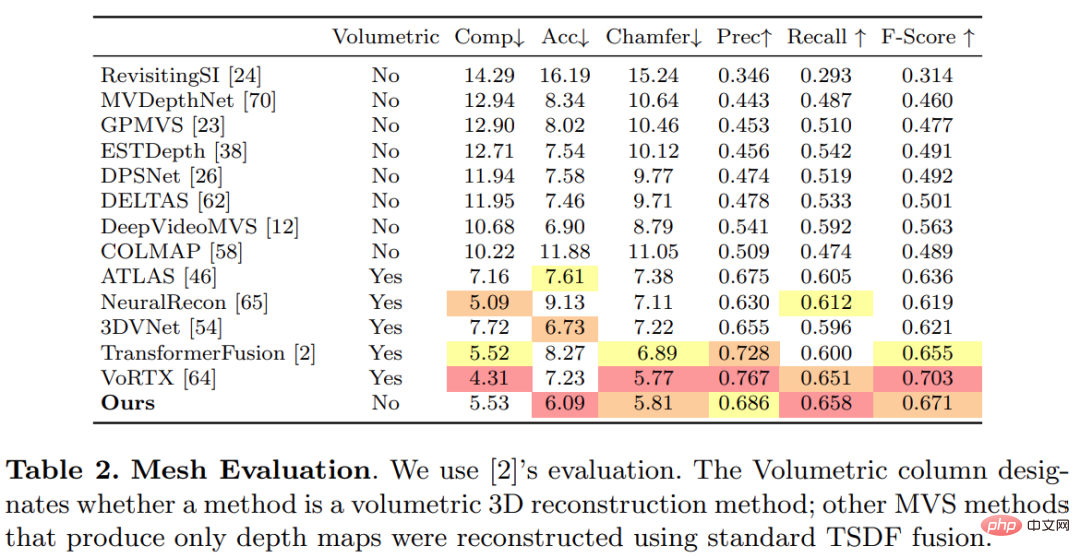
Pour les applications de reconstruction 3D en ligne et interactives, la réduction de la latence du capteur est cruciale. Le tableau 3 ci-dessous montre le temps de calcul d'ensemble par image pour chaque modèle étant donné une nouvelle image RVB.

Afin de vérifier l'efficacité de chaque composant de la méthode proposée dans cette étude, le chercheur a mené une expérience d'ablation, et les résultats sont présentés dans le tableau 4 ci-dessous.
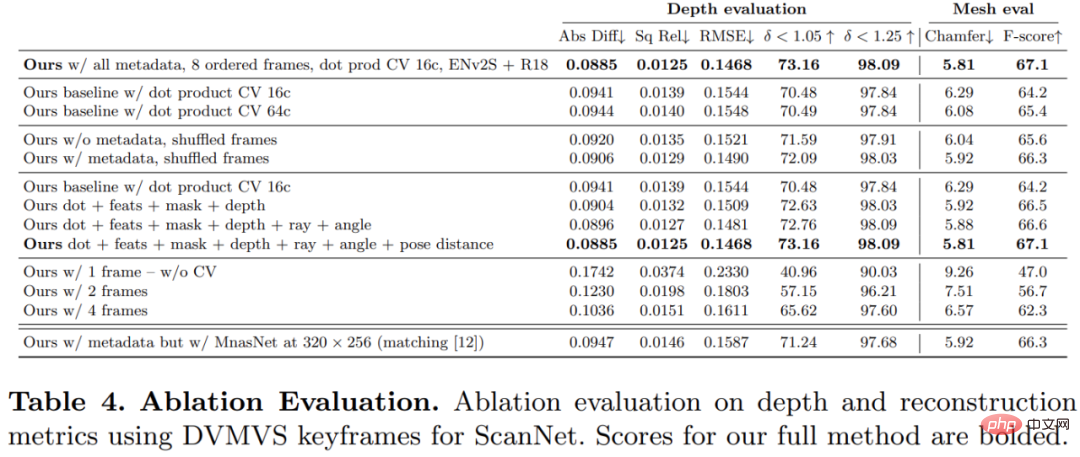
Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur les détails de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI