
Maison >développement back-end >Tutoriel Python >Plein d'informations utiles ! Une introduction complète à la façon dont les coroutines de Python sont implémentées ! Si vous le comprenez, vous êtes génial !
Plein d'informations utiles ! Une introduction complète à la façon dont les coroutines de Python sont implémentées ! Si vous le comprenez, vous êtes génial !

- PHPzavant
- 2023-05-02 10:34:061215parcourir

Si vous devez accéder à plusieurs services pour terminer le traitement d'une demande, par exemple lors de la mise en œuvre de la fonction de téléchargement de fichiers, accédez d'abord au cache Redis, vérifiez si l'utilisateur est connecté, puis recevez le corps dans le message HTTP et enregistrez-le sur le disque, et enfin Que feriez-vous si vous écriviez le chemin du fichier et d'autres informations dans la base de données MySQL ?
Tout d'abord, vous pouvez utiliser l'API de blocage pour écrire du code de synchronisation et simplement le sérialiser étape par étape, mais évidemment à l'heure actuelle, un thread ne peut traiter qu'une seule requête à la fois. Nous savons que le nombre de threads est limité.Le nombre limité de threads rend impossible la réalisation de dizaines de milliers de connexions simultanées.Un changement excessif de thread enlève également du temps CPU, réduisant ainsi le nombre de requêtes pouvant être traitées par seconde.
Ainsi, afin d'obtenir une concurrence élevée, vous pouvez choisir un cadre asynchrone, utiliser des API non bloquantes pour perturber la logique métier en plusieurs fonctions de rappel et atteindre une concurrence élevée grâce au multiplexage. Mais à l'heure actuelle, le code métier doit prêter trop d'attention aux détails de la concurrence et doit maintenir de nombreux états intermédiaires. Une fois qu'une erreur se produit dans la logique du code, il tombera dans l'enfer des rappels.
Donc, si vous faites cela, non seulement le taux de bugs sera très élevé, mais la vitesse de développement du projet sera également ralentie, et il y aura des risques à lancer le produit à temps. Si vous souhaitez prendre en compte l’efficacité du développement tout en garantissant une concurrence élevée, les coroutines sont le meilleur choix. Il peut écrire du code de manière synchrone tout en conservant un mécanisme de fonctionnement asynchrone. Cela permet non seulement d'obtenir une concurrence élevée, mais de raccourcir également le cycle de développement. C'est l'orientation future du développement des services hautes performances.
Ici, il faut souligner qu'en termes de concurrence, la méthode "coroutine" n'est pas meilleure que la méthode "non bloquante + rappel", et la raison pour laquelle nous choisissons la coroutine est que son modèle de programmation est plus simple, similaire à For synchronisation, cela nous permet d'écrire du code asynchrone de manière synchrone. La méthode "non bloquante + rappel" est un excellent test des compétences en programmation. Une fois qu'une erreur se produit, il est difficile de localiser le problème et il est facile de tomber dans des problèmes tels que l'enfer des rappels et le déchirement de la pile.
Vous constaterez donc que la technologie permettant de résoudre les problèmes de haute concurrence évolue constamment, du multi-processus et du multi-thread à l'asynchrone et à la coroutine. Face à différents scénarios, ils résolvent tous les problèmes de différentes manières. Examinons comment les solutions à haute concurrence ont évolué, quels problèmes les coroutines résolvent et comment elles doivent être appliquées.
Non bloquant + rappel + multiplexage IO
Nous savons qu'un hôte dispose de ressources limitées, d'un processeur, d'un disque et d'une carte réseau. Comment peut-il répondre à des centaines de requêtes en même temps ? Le mode multi-processus était la solution originale. Le noyau divise le temps d'exécution du processeur en plusieurs tranches de temps (tranches de temps). Par exemple, 1 seconde peut être divisée en 100 tranches de temps de 10 millisecondes. Chaque tranche de temps est ensuite distribuée à différents processus. Habituellement, chaque processus nécessite plusieurs temps. slice pour compléter une demande.
De cette façon, même si d'un point de vue micro, par exemple, le CPU ne peut exécuter qu'un seul processus pendant ces 10 millisecondes, d'un point de vue macro, 100 tranches de temps sont exécutées en 1 seconde, donc les requêtes du processus auxquelles chacune les tranches de temps appartenant sont également exécutées. Cela permet une exécution simultanée des requêtes.
Cependant, l'espace mémoire de chaque processus est indépendant, donc l'utilisation de plusieurs processus pour obtenir la concurrence présente deux inconvénients : premièrement, le coût de gestion du noyau est élevé, et deuxièmement, les données ne peuvent pas être simplement synchronisées via la mémoire, ce qui est très gênant. . En conséquence, le mode multithread est apparu. Le mode multithread a résolu ces deux problèmes en partageant l'espace d'adressage mémoire.
Cependant, bien qu'un espace d'adressage partagé puisse facilement partager des objets, cela entraîne également un problème : lorsqu'un thread commet une erreur, tous les threads du processus se bloquent ensemble. C'est pourquoi des services tels que Nginx, qui mettent l'accent sur la stabilité, insistent sur l'utilisation du mode multi-processus.
Mais en fait, qu'il soit basé sur le multi-processus ou le multi-threading, il est difficile d'atteindre une concurrence élevée, principalement pour les deux raisons suivantes.
- Tout d'abord, un seul thread consomme trop de mémoire. Par exemple, Linux 64 bits alloue 8 Mo de mémoire pour la pile de chaque thread. De plus, afin d'améliorer les performances d'allocation de mémoire ultérieure, 64 Mo de mémoire. est pré-alloué pour chaque thread en tant que pool de mémoire tas (Zone de Thread). Par conséquent, nous n’avons pas assez de mémoire pour ouvrir des dizaines de milliers de threads afin d’obtenir la concurrence.
- Deuxièmement, la demande de changement est implémentée par le noyau en changeant de thread. Quand le thread sera-t-il commuté ? Non seulement la tranche de temps s'épuise, mais lorsqu'une méthode de blocage est appelée, le noyau passe également à d'autres threads pour l'exécution afin de permettre au processeur de fonctionner pleinement. Le coût d'un changement de contexte varie de quelques dizaines de nanosecondes à plusieurs microsecondes. Lorsque les threads sont occupés et qu'il y a un grand nombre de threads, ces commutateurs consommeront l'essentiel de la puissance de calcul du CPU.
La figure suivante prend le disque IO comme exemple pour décrire la méthode de commutation entre deux threads en utilisant la méthode de blocage pour lire le disque en multi-threads.
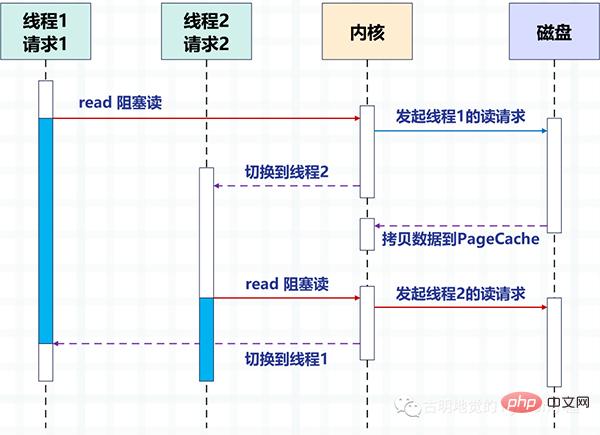
Grâce au multithreading, un thread traite une requête pour obtenir la concurrence. Mais il est évident que le nombre de threads que le système d'exploitation peut créer est limité, car plus il y a de threads, plus les ressources sont occupées, et le coût de commutation entre les threads est également relativement élevé, car cela implique de basculer entre le mode noyau et le mode utilisateur. mode.
La question est alors : comment pouvons-nous atteindre une simultanéité élevée ? La réponse est "Laissez simplement le travail de commutation de requête implémenté par le noyau dans la figure ci-dessus au code du mode utilisateur." La programmation asynchrone implémente la commutation de requêtes via le code de la couche application, réduisant ainsi les coûts de commutation et l'empreinte mémoire.
L'asynchronisation repose sur le mécanisme de multiplexage des E/S, tel que l'epoll de Linux. Dans le même temps, la méthode de blocage doit être remplacée par une méthode non bloquante pour éviter l'énorme consommation causée par le changement de noyau. Les services hautes performances tels que Nginx et Redis s'appuient sur l'asynchronisation pour atteindre des millions de niveaux de concurrence.
La figure suivante décrit comment la requête est commutée après que la lecture non bloquante des E/S asynchrones soit combinée avec le framework asynchrone.
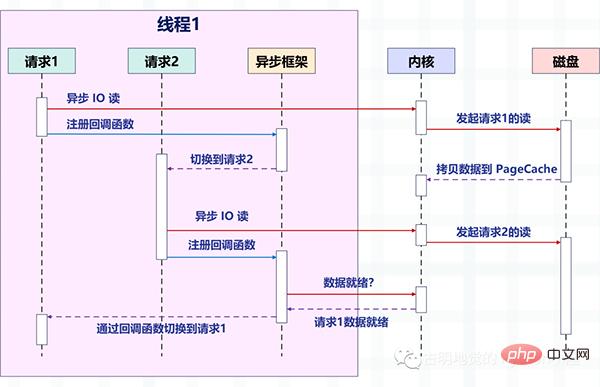
Faites attention aux changements dans l'image. Avant, un thread traitait une requête, mais maintenant un thread traite plusieurs requêtes. Il s'agit de la méthode "non bloquante + rappel" que nous avons mentionnée précédemment. Il s'appuie sur le multiplexage d'E/S fourni par le système d'exploitation, comme epoll de Linux et kqueue de BSD.
Les opérations de lecture et d'écriture à ce moment sont équivalentes à un événement, et une fonction de rappel correspondante est enregistrée pour chaque événement. Ensuite, le thread ne bloquera pas (car les opérations de lecture et d'écriture ne sont pas bloquantes à ce moment), mais peut faire autre chose, ces événements sont ensuite gérés de manière uniforme par epoll.
Une fois l'événement survenu (lorsqu'il est lisible et inscriptible), epoll en informera le thread, puis le thread exécutera la fonction de rappel enregistrée pour l'événement.
Pour une meilleure compréhension, prenons Redis comme exemple pour introduire le multiplexage IO et IO non bloquant.
127.0.0.1:6379> get name "satori"
Tout d'abord, nous pouvons utiliser la commande get pour obtenir la valeur correspondant à une clé. Ensuite, la question est : qu'est-il arrivé au serveur Redis ci-dessus ?
Le serveur doit d'abord écouter la demande du client (bind/listen), puis établir une connexion avec le client à son arrivée (accepter), lire la demande du client depuis le socket (recv) et analyser la demande (parse). Le type de requête analysé ici est get, la clé est "nom", puis la valeur correspondante est obtenue en fonction de la clé, et finalement renvoyée au client, c'est-à-dire l'écriture des données sur le socket (envoi).
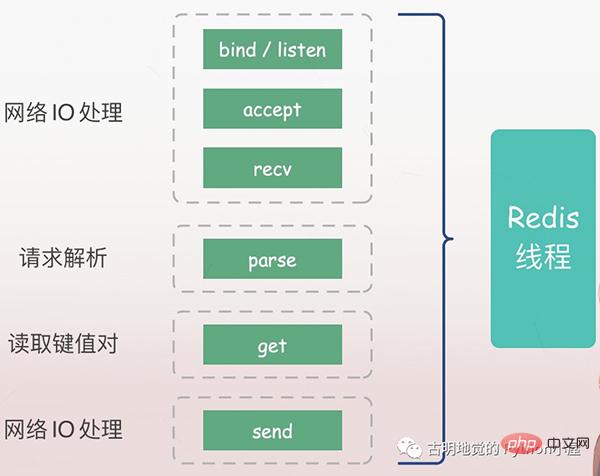
Toutes les opérations ci-dessus sont exécutées séquentiellement par le thread principal Redis, mais il existe des points de blocage potentiels, à savoir accept et recv.
S'il bloque IO, lorsque Redis détecte une demande de connexion d'un client mais ne parvient pas à établir une connexion, le thread principal sera toujours bloqué dans la fonction d'acceptation, empêchant les autres clients d'établir des connexions avec Redis. De même, lorsque Redis lit les données du client via recv, si les données ne sont pas arrivées, le thread principal de Redis sera toujours bloqué lors de l'étape de réception, ce qui entraînera une faible efficacité de Redis.
IO non bloquantes
Mais évidemment, Redis ne permettra pas que cela se produise, car ce qui précède sont toutes des situations auxquelles le blocage des IO sera confronté, et Redis utilise des IO non bloquantes, ce qui signifie définir le socket en mode non bloquant. Tout d'abord, dans le modèle socket, l'appel de la méthode socket() renverra la socket active ; l'appel de la méthode bind() pour lier l'IP et le port, puis l'appel de la méthode Listen() pour convertir la socket active en socket d'écoute ; enfin, le socket d'écoute Le socket appelle la méthode accept() pour attendre l'arrivée de la connexion client. Lorsque la connexion est établie avec le client, il renvoie le socket connecté, puis utilise le socket connecté pour recevoir et envoyer des données. le client.
Mais remarque : nous avons dit qu'à l'étape Listen(), la socket active sera convertie en socket d'écoute, et le type de socket d'écoute à ce moment est bloquant. Le type bloquant de socket d'écoute appelle la méthode accept(). , s'il n'y a pas de client à connecter, il sera toujours bloqué et le thread principal ne pourra pas faire autre chose pour le moment. Par conséquent, vous pouvez le définir sur non bloquant lors de l'écoute (). Lorsque le socket d'écoute non bloquant appelle accept (), si aucune demande de connexion client n'arrive, le thread principal n'attendra pas bêtement, mais reviendra directement puis le fera. d'autres choses.
De même, lorsque nous créons une socket connectée, nous pouvons également définir son type sur non bloquant, car une socket connectée de type bloquant sera également dans un état bloquant lors de l'appel de send() / recv() , par exemple, lorsque le client n'envoie jamais de données, la socket connectée sera toujours bloquée à l'étape rev(). S'il s'agit d'un type de socket connecté non bloquant, alors lorsque recv() est appelé mais qu'aucune donnée n'est reçue, il n'est pas nécessaire d'être dans un état bloquant et vous pouvez également revenir directement pour faire autre chose.
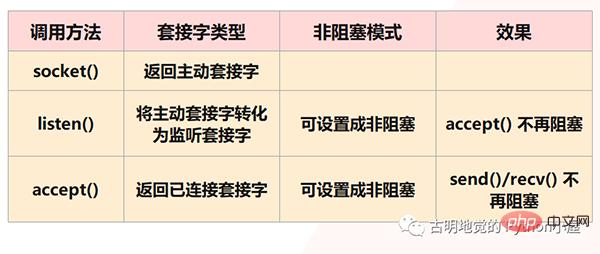
Mais il y a deux points à noter :
1) Bien que accept() ne soit plus bloqué, le thread principal de Redis peut faire autre chose lorsqu'il n'y a pas de connexion client, mais qu'arrivera-t-il à Redis si un client se connecte plus tard ? Le saviez-vous ? Par conséquent, il doit exister un mécanisme capable de continuer à attendre les demandes de connexion ultérieures sur le socket d'écoute et d'avertir Redis lorsque la demande arrive.
2) send() / recv() n'est plus bloqué. Le processus de lecture et d'écriture équivalent à IO n'est plus bloqué. Les méthodes de lecture et d'écriture seront terminées instantanément et reviendront, c'est-à-dire qu'elles liront autant que possible. il peut lire et écrire autant de stratégies que vous le souhaitez pour effectuer des opérations d'E/S, ce qui est évidemment plus conforme à notre recherche de performance. Mais cela sera également confronté à un problème, c'est-à-dire que lorsque nous effectuons une opération de lecture, il est possible que seule une partie des données ait été lue et que les données restantes n'aient pas été envoyées par le client. Alors, quand ces données le seront-elles. lisible? Il en va de même pour l'écriture de données. Lorsque le tampon est plein et que nos données n'ont pas encore été écrites, quand les données restantes peuvent-elles être écrites ? Par conséquent, il doit également exister un mécanisme capable de continuer à surveiller le socket connecté pendant que le thread principal Redis fait autre chose, et d'avertir Redis lorsqu'il y a des données à lire et à écrire.
Cela peut garantir que le thread Redis n'attendra pas au point de blocage comme dans le modèle IO de base, ni ne sera incapable de traiter la demande de connexion client réelle et les données lisibles et inscriptibles. Le mécanisme mentionné ci-dessus est le multiplexage IO.
Multiplexage IO
Le mécanisme de multiplexage d'E/S fait référence à un thread traitant plusieurs flux d'E/S, qui est le select/poll/epoll que nous entendons souvent. Nous ne parlerons pas des différences entre ces trois éléments. Ils font tous la même chose, mais il existe des différences en termes de performances et de principes de mise en œuvre. select est pris en charge par tous les systèmes, tandis qu'epoll n'est pris en charge que par Linux.
En termes simples, lorsque Redis n'exécute qu'un seul thread, ce mécanisme permet à plusieurs sockets d'écoute et sockets connectés d'exister dans le noyau en même temps. Le noyau surveillera toujours les demandes de connexion ou les demandes de données sur ces sockets. Une fois qu'une demande arrive, elle sera transmise au thread Redis pour traitement, obtenant ainsi l'effet d'un thread Redis traitant plusieurs flux d'E/S.
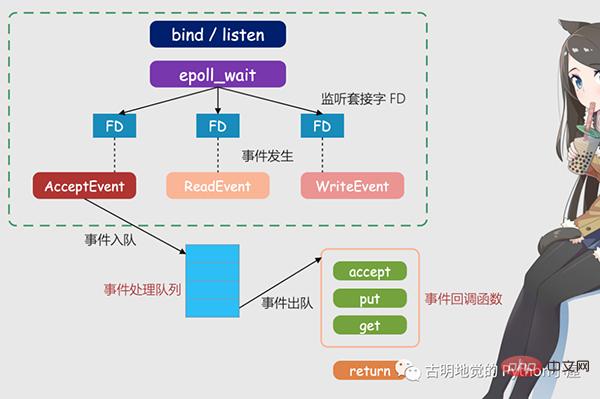
L'image ci-dessus est le modèle Redis IO basé sur le multiplexage. Le FD sur l'image est le socket, qui peut être un socket d'écoute ou un socket connecté. Redis utilisera le mécanisme epoll pour les écouter. prises. À ce stade, le thread Redis ou le thread principal ne sera pas bloqué sur un socket spécifique, ce qui signifie qu'il ne sera pas bloqué sur un traitement de demande client spécifique. Par conséquent, Redis peut se connecter à plusieurs clients en même temps et traiter les demandes, améliorant ainsi la simultanéité.
Mais afin de notifier le thread Redis lorsqu'une requête arrive, epoll fournit un mécanisme de rappel basé sur les événements, c'est-à-dire qu'il appelle la fonction de traitement correspondante pour l'occurrence de différents événements.
Alors, comment fonctionne le mécanisme de rappel ? En prenant la figure ci-dessus comme exemple, epoll déclenchera d'abord l'événement correspondant une fois qu'il détectera qu'une requête arrive sur FD. Ces événements seront placés dans une file d'attente et le thread principal Redis traitera en continu la file d'attente des événements. De cette façon, Redis n'a pas besoin de continuer à interroger s'il y a une demande, évitant ainsi le gaspillage de ressources.
Dans le même temps, lorsque Redis traite les événements dans la file d'attente des événements, il appelle la fonction de traitement correspondante, qui implémente les rappels basés sur les événements. Étant donné que Redis traite la file d'attente des événements, il peut répondre aux demandes des clients en temps opportun et améliorer les performances de réponse de Redis.
Prenons comme exemple la demande de connexion réelle et la demande de lecture de données et expliquons-la à nouveau. Les demandes de connexion et les demandes de lecture de données correspondent respectivement aux événements Accept et Read. Les registres Redis acceptent et obtiennent respectivement les fonctions de rappel pour ces deux événements. Lorsque le noyau Linux surveille une demande de connexion ou une demande de lecture de données, il déclenche l'événement Accept ou Read. , puis informez le thread principal et rappelez la fonction d'acceptation enregistrée ou la fonction get.
Tout comme un patient se rendant à l'hôpital pour consulter un médecin, chaque patient (semblable à une demande) doit être trié, mesuré, enregistré, etc. avant que le médecin ne pose réellement un diagnostic. Si toutes ces tâches sont effectuées par des médecins, leur efficacité au travail sera très faible. Par conséquent, l'hôpital a mis en place une station de triage. La station de triage gérera toujours ces tâches de pré-diagnostic (similaires à la demande d'écoute du noyau Linux), puis les transférera au médecin pour un diagnostic réel. (équivalent au thread principal de Redis) peut être très efficace.
这里需要再补充一下:我们上面提到的异步 IO 不是真正意义上的异步 IO,而是基于 IO 多路复用实现的异步化。但 IO 多路复用本质上是同步 IO,只是它可以同时监听多个文件描述符,一旦某个描述符的读写操作就绪,就能够通知应用程序进行相应的读写操作。至于真正意义的异步 IO,操作系统也是支持的,但支持的不太理想,所以现在使用的都是 IO 多用复用,并代指异步 IO。
为什么不推荐这种编程模式?
必须要承认的是,编写这种异步化代码能够带来很高的性能收益,Redis、Nginx 已经证明了这一点。
但是这种编程模式,在实际工作中很容易出错,因为所有阻塞函数,都需要通过非阻塞的系统调用加上回调注册的方式拆分成两个函数。说白了就是我们的逻辑不能够直接执行,必须把它们放在一个单独的函数里面,然后这个函数以回调的方式注册给 IO 多路复用。
这种编程模式违反了软件工程的内聚性原则,函数之间同步数据也更复杂。特别是条件分支众多、涉及大量系统调用时,异步化的改造工作会非常困难,尽管它的性能很高。
下面我们用 Python 编写一段代码,实际体验一下这种编程模式,看看它复杂在哪里。
from urllib.parse import urlparse
import socket
from io import BytesIO
# selectors 里面提供了多种"多路复用器"
# 除了 select、poll、epoll 之外
# 还有 kqueue,这个是针对 BSD 平台的
try:
from selectors import (
SelectSelector,
PollSelector,
EpollSelector,
KqueueSelector
)
except ImportError:
pass
# 由于种类比较多,所以提供了DefaultSelector
# 会根据当前的系统种类,自动选择一个合适的多路复用器
from selectors import (
DefaultSelector,
EVENT_READ,# 读事件
EVENT_WRITE,# 写事件
)
class RequestHandler:
"""
向指定的 url 发请求
获取返回的内容
"""
selector = DefaultSelector()
tasks = {"unfinished": 0}
def __init__(self, url):
"""
:param url: http://localhost:9999/v1/index
"""
self.tasks["unfinished"] += 1
url = urlparse(url)
# 根据 url 解析出 域名、端口、查询路径
self.netloc = url.netloc# 域名:端口
self.path = url.path or "/"# 查询路径
# 创建 socket
self.client = socket.socket()
# 设置成非阻塞
self.client.setblocking(False)
# 用于接收数据的缓存
self.buffer = BytesIO()
def get_result(self):
"""
发送请求,进行下载
:return:
"""
# 连接到指定的服务器
# 如果没有 : 说明只有域名没有端口
# 那么默认访问 80 端口
if ":" not in self.netloc:
host, port = self.netloc, 80
else:
host, port = self.netloc.split(":")
# 由于 socket 非阻塞,所以连接可能尚未建立好
try:
self.client.connect((host, int(port)))
except BlockingIOError:
pass
# 我们上面是建立连接,连接建立好就该发请求了
# 但是连接什么时候建立好我们并不知道,只能交给操作系统
# 所以我们需要通过 register 给 socket 注册一个回调函数
# 参数一:socket 的文件描述符
# 参数二:事件
# 参数三:当事件发生时执行的回调函数
self.selector.register(self.client.fileno(),
EVENT_WRITE,
self.send)
# 表示当 self.client 这个 socket 满足可写时
# 就去执行 self.send
# 翻译过来就是连接建立好了,就去发请求
# 可以看到,一个阻塞调用,我们必须拆成两个函数去写
def send(self, key):
"""
连接建立好之后,执行的回调函数
回调需要接收一个参数,这是一个 namedtuple
内部有如下字段:'fileobj', 'fd', 'events', 'data'
key.fd 就是 socket 的文件描述符
key.data 就是给 socket 绑定的回调
:param key:
:return:
"""
payload = (f"GET {self.path} HTTP/1.1rn"
f"Host: {self.netloc}rn"
"Connection: closernrn")
# 执行此函数,说明事件已经触发
# 我们要将绑定的回调函数取消
self.selector.unregister(key.fd)
# 发送请求
self.client.send(payload.encode("utf-8"))
# 请求发送之后就要接收了,但是啥时候能接收呢?
# 还是要交给操作系统,所以仍然需要注册回调
self.selector.register(self.client.fileno(),
EVENT_READ,
self.recv)
# 表示当 self.client 这个 socket 满足可读时
# 就去执行 self.recv
# 翻译过来就是数据返回了,就去接收数据
def recv(self, key):
"""
数据返回时执行的回调函数
:param key:
:return:
"""
# 接收数据,但是只收了 1024 个字节
# 如果实际返回的数据超过了 1024 个字节怎么办?
data = self.client.recv(1024)
# 很简单,只要数据没收完,那么数据到来时就会可读
# 那么会再次调用此函数,直到数据接收完为止
# 注意:此时是非阻塞的,数据有多少就收多少
# 没有接收的数据,会等到下一次再接收
# 所以这里不能写 while True
if data:
# 如果有数据,那么写入到 buffer 中
self.buffer.write(data)
else:
# 否则说明数据读完了,那么将注册的回调取消
self.selector.unregister(key.fd)
# 此时就拿到了所有的数据
all_data = self.buffer.getvalue()
# 按照 rnrn 进行分隔得到列表
# 第一个元素是响应头,第二个元素是响应体
result = all_data.split(b"rnrn")[1]
print(f"result: {result.decode('utf-8')}")
self.client.close()
self.tasks["unfinished"] -= 1
@classmethod
def run_until_complete(cls):
# 基于 IO 多路复用创建事件循环
# 驱动内核不断轮询 socket,检测事件是否发生
# 当事件发生时,调用相应的回调函数
while cls.tasks["unfinished"]:
# 轮询,返回事件已经就绪的 socket
ready = cls.selector.select()
# 这个 key 就是回调里面的 key
for key, mask in ready:
# 拿到回调函数并调用,这一步需要我们手动完成
callback = key.data
callback(key)
# 因此当事件发生时,调用绑定的回调,就是这么实现的
# 整个过程就是给 socket 绑定一个事件 + 回调
# 事件循环不停地轮询检测,一旦事件发生就会告知我们
# 但是调用回调不是内核自动完成的,而是由我们手动完成的
# "非阻塞 + 回调 + 基于 IO 多路复用的事件循环"
# 所有框架基本都是这个套路一个简单的 url 获取,居然要写这么多代码,而它的好处就是性能高,因为不用把时间浪费在建立连接、等待数据上面。只要有事件发生,就会执行相应的回调,极大地提高了 CPU 利用率。而且这是单线程,也没有线程切换带来的开销。
那么下面测试一下吧。
import time
start = time.perf_counter()
for _ in range(10):
# 这里面只是注册了回调,但还没有真正执行
RequestHandler(url="https://localhost:9999/index").get_result()
# 创建事件循环,驱动执行
RequestHandler.run_until_complete()
end = time.perf_counter()
print(f"总耗时: {end - start}")我用 FastAPI 编写了一个服务,为了更好地看到现象,服务里面刻意 sleep 了 1 秒。然后发送十次请求,看看效果如何。
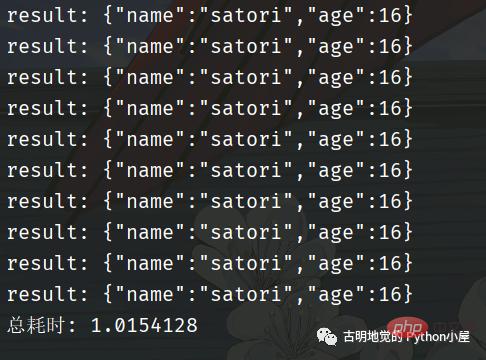
总共耗时 1 秒钟,我们再采用同步的方式进行编写,看看效果如何。
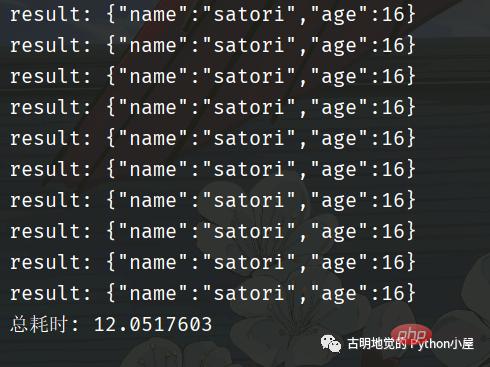
可以看到回调的这种写法性能非常高,但是它和我们传统的同步代码的写法大相径庭。如果是同步代码,那么会先建立连接、然后发送数据、再接收数据,这显然更符合我们人类的思维,逻辑自上而下,非常自然。
但是回调的方式,就让人很不适应,我们在建立完连接之后,不能直接发送数据,必须将发送数据的逻辑放在一个单独的函数(方法)中,然后再将这个函数以回调的方式注册进去。
同理,在发送完数据之后,也不能立刻接收。同样要将接收数据的逻辑放在一个单独的函数中,然后再以回调的方式注册进去。
所以好端端的自上而下的逻辑,因为回调而被分割的四分五裂,这种代码在编写和维护的时候是非常痛苦的。
比如回调可能会层层嵌套,容易陷入回调地狱,如果某一个回调执行出错了怎么办?代码的可读性差导致不好排查,即便排查到了也难处理。
另外,如果多个回调需要共享一个变量该怎么办?因为回调是通过事件循环调用的,在注册回调的时候很难把变量传过去。简单的做法是把该变量设置为全局变量,或者说多个回调都是某个类的成员函数,然后把共享的变量作为一个属性绑定在 self 上面。但当逻辑复杂时,就很容易导致全局变量满天飞的问题。
所以这种模式就使得开发人员在编写业务逻辑的同时,还要关注并发细节。
因此使用回调的方式编写异步化代码,虽然并发量能上去,但是对开发者很不友好;而使用同步的方式编写同步代码,虽然很容易理解,可并发量却又上不去。那么问题来了,有没有一种办法,能够让我们在享受异步化带来的高并发的同时,又能以同步的方式去编写代码呢?也就是我们能不能以同步的方式去编写异步化的代码呢?
答案是可以的,使用「协程」便可以办到。协程在异步化之上包了一层外衣,兼顾了开发效率与运行效率。
协程是如何实现高并发的?
协程与异步编程相似的地方在于,它们必须使用非阻塞的系统调用与内核交互,把切换请求的权力牢牢掌握在用户态的代码中。但不同的地方在于,协程把异步化中的两段函数,封装为一个阻塞的协程函数。
这个函数执行时,会使调用它的协程无感知地放弃执行权,由协程框架切换到其他就绪的协程继续执行。当这个函数的结果满足后,协程框架再选择合适的时机,切换回它所在的协程继续执行。我们还是以读取磁盘文件为例,看一张协程的示意图:
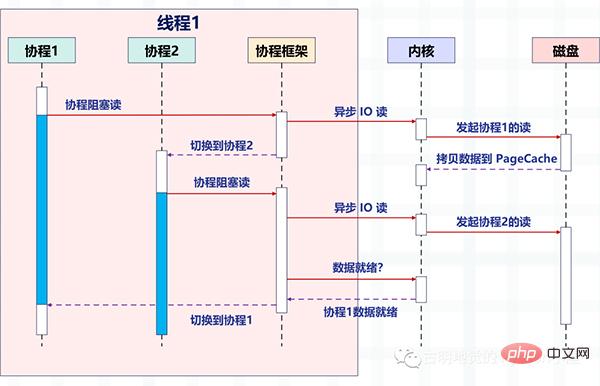
看起来非常棒,所以异步化是通过回调函数来完成请求切换的,业务逻辑与并发实现关联在一起,很容易出错。而协程不需要什么「回调函数」,它允许用户调用「阻塞的」协程方法,用同步编程方式写业务逻辑。
再回到之前的那个 socket 发请求的例子,我们用协程的方式重写一遍,看看它和基于回调的异步化编程有什么区别?
import time
from urllib.parse import urlparse
import asyncio
async def download(url):
url = urlparse(url)
# 域名:端口
netloc = url.netloc
if ":" not in netloc:
host, port = netloc, 80
else:
host, port = netloc.split(":")
path = url.path or "/"
# 创建连接
reader, writer = await asyncio.open_connection(host, port)
# 发送数据
payload = (f"GET {path} HTTP/1.1rn"
f"Host: {netloc}rn"
"Connection: closernrn")
writer.write(payload.encode("utf-8"))
await writer.drain()
# 接收数据
result = (await reader.read()).split(b"rnrn")[1]
writer.close()
print(f"result: {result.decode('utf-8')}")
# 以上就是发送请求相关的逻辑
# 我们看到代码是自上而下的,没有涉及到任何的回调
# 完全就像写同步代码一样
async def main():
# 发送 10 个请求
await asyncio.gather(
*[download("http://localhost:9999/index")
for _ in range(10)]
)
start = time.perf_counter()
# 同样需要创建基于 IO 多路复用的事件循环
# 协程会被丢进事件循环中,依靠事件循环驱动执行
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
end = time.perf_counter()
print(f"总耗时: {end - start}")代码逻辑很好理解,和我们平时编写的同步代码没有太大的区别,那么它的效率如何呢?
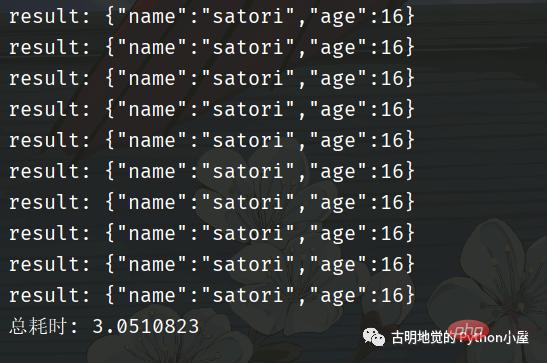
我们看到用了 3 秒钟,比同步的方式快,但是比异步化的方式要慢。因为一开始就说过,协程并不比异步化的方式快,但我们之所以选择它,是因为它的编程模型更简单,能够让我们以同步的方式编写异步的代码。如果是基于回调方式的异步化,虽然性能很高(比如 Redis、Nginx),但对开发者是一个挑战。
回到上面那个协程的例子中,我们一共发了 10 个请求,并在可能阻塞的地方加上了 await。意思就是,在执行某个协程 await 后面的代码时如果阻塞了,那么该协程会主动将执行权交给事件循环,然后事件循环再选择其它的协程执行。并且协程本质上也是个单线程,虽然协程可以有多个,但是背后的线程只有一个。
协程是如何切换的?
那么问题来了,协程的切换是如何完成的呢?
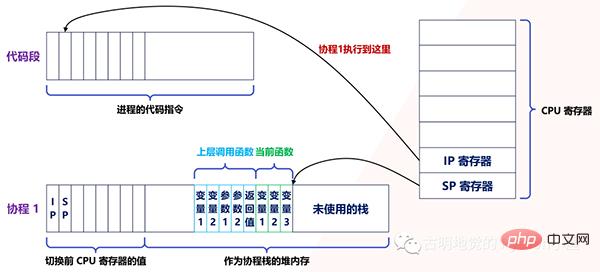
实际上,用户态的代码切换协程,与内核切换线程的原理是一样的。内核通过管理 CPU 的寄存器来切换线程,我们以最重要的栈寄存器和指令寄存器为例,看看协程切换时如何切换程序指令与内存。
每个线程有独立的栈,而栈既保留了变量的值,也保留了函数的调用关系、参数和返回值,CPU 中的栈寄存器 SP 指向了当前线程的栈,而指令寄存器 IP 保存着下一条要执行的指令地址。
因此,从线程 1 切换到线程 2 时,首先要把 SP、IP 寄存器的值为线程 1 保存下来,再从内存中找出线程 2 上一次切换前保存好的寄存器的值,并写入 CPU 的寄存器,这样就完成了线程切换(其他寄存器也需要管理、替换,原理与此相同,不再赘述)。
协程的切换与此相同,只是把内核的工作转移到协程框架来实现而已,下图是协程切换前的状态:
当遇到阻塞时会进行协程切换,从协程 1 切换到协程 2 后的状态如下图所示:
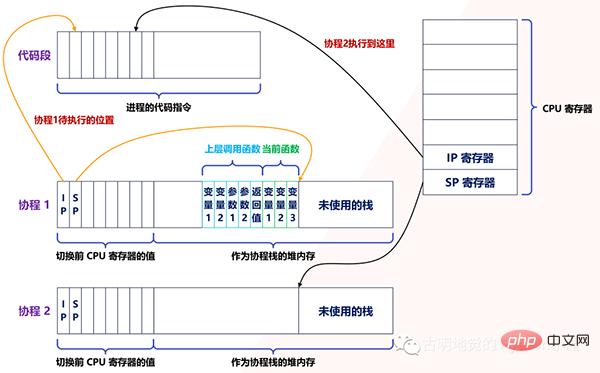
创建协程时,会从进程的堆中分配一段内存作为协程的栈。线程的栈有 8MB,而协程栈的大小通常只有几十 KB。而且,C 库内存池也不会为协程预分配内存,它感知不到协程的存在。这样,更低的内存占用空间为高并发提供了保证,毕竟十万并发请求,就意味着 10 万个协程。
另外栈缩小后,就尽量不要使用递归函数,也不能在栈中申请过多的内存,这是实现高并发必须付出的代价。当然啦,如果能像 Go 一样,协程栈可以自由伸缩的话,就不用担心了。
由此可见,协程就是用户态的线程。然而,为了保证所有切换都在用户态进行,协程必须重新封装所有的阻塞系统调用,否则一旦协程触发了线程切换,会导致这个线程进入休眠状态,进而其上的所有协程都得不到执行。
Par exemple, la fonction sleep ordinaire fera dormir le thread actuel et le noyau réveillera le thread après la transformation de la coroutine, sleep fera uniquement dormir la coroutine actuelle et le framework de coroutine réveillera la coroutine après un délai spécifié. time, donc en Python Nous ne pouvons pas écrire time.sleep dans la coroutine, mais devrions écrire asyncio.sleep. Pour un autre exemple, les verrous mutex entre les threads sont implémentés à l'aide de sémaphores, et les sémaphores peuvent également provoquer la mise en veille des threads. Une fois les verrous mutex transformés en coroutines, le framework coordonnera et synchronisera également l'exécution de chaque coroutine.
La haute performance des coroutines repose donc sur le fait que la commutation doit être effectuée par du code en mode utilisateur. Cela nécessite que l'écosystème de coroutines soit complet et couvre autant que possible les composants communs.
Prenons Python comme exemple. Je vois souvent des gens écrire des requêtes.get en async def pour envoyer des requêtes. L'appel sous-jacent à request.get est un socket bloqué de manière synchrone, ce qui entraînera le blocage du thread une fois le thread bloqué, toutes les coroutines se bloqueront, ce qui équivaut à la sérialisation. Il ne sert donc à rien de le mettre dans async def, la bonne méthode est d'utiliser aiohttp ou httpx. Par conséquent, si vous souhaitez utiliser des coroutines, vous devez réencapsuler les appels système sous-jacents. S'il n'y a pas d'autre moyen, jetez-les dans le pool de threads pour les exécuter.
Un autre exemple est le SDK client officiellement fourni par MySQL. Il utilise des sockets bloquants pour l'accès au réseau, ce qui entraînera la mise en veille des threads. Vous devez utiliser des sockets non bloquants pour transformer le SDK en fonctions coroutines avant de pouvoir les utiliser dans les coroutines.
Bien sûr, toutes les fonctions ne peuvent pas être transformées avec des coroutines, comme la lecture asynchrone des E/S à partir des disques. Bien qu'il ne soit pas bloquant, il ne peut pas utiliser PageCache, ce qui réduit le débit du système. Si vous utilisez les E/S mises en cache pour lire des fichiers, un blocage peut se produire lorsque PageCache n'est pas atteint. À l'heure actuelle, si vous avez des exigences de performances plus élevées, vous devez combiner des threads avec des coroutines, lancer des opérations potentiellement bloquantes dans le pool de threads pour exécution et travailler avec des coroutines via le modèle producteur/consommateur.
En fait, face aux systèmes multicœurs, les coroutines et les threads doivent également fonctionner ensemble. Étant donné que le support des coroutines est constitué de threads et qu'un thread ne peut utiliser qu'un seul processeur à la fois, en ouvrant plus de threads et en répartissant toutes les coroutines entre ces threads, les ressources du processeur peuvent être pleinement utilisées. Si vous avez de l’expérience dans l’utilisation du langage Go, vous devez très bien le savoir.
De plus, afin de permettre à la coroutine d'obtenir plus de temps CPU, vous pouvez également définir la priorité du thread. Par exemple, sous Linux, définissez la priorité du thread sur -20, et vous pouvez obtenir un temps plus long à chaque fois. . morceau. De plus, le cache du processeur a également un impact sur les performances du programme. Afin de réduire la proportion de défaillances du cache du processeur, les threads peuvent également être liés à un processeur pour augmenter la probabilité d'atteindre le cache du processeur lors de l'exécution de la coroutine.
Bien qu'il ait été dit ici que le framework de coroutine planifie les coroutines, vous constaterez que de nombreuses bibliothèques de coroutines ne fournissent que des méthodes de base telles que la création, la suspension et la reprise de l'exécution. Il n'y a pas de framework de coroutine et le code métier doit l'être. programmé par lui-même. En effet, ces bibliothèques de coroutines générales (telles que asyncio) ne sont pas spécifiquement conçues pour les serveurs. L'établissement d'une connexion réseau client sur le serveur peut entraîner la création de coroutines et se terminer à la fin de la requête.
Lorsque les conditions d'exécution de la coroutine ne sont pas remplies, le framework de multiplexage la suspendra et sélectionnera une autre coroutine à exécuter en fonction de la politique de priorité. Par conséquent, lorsque vous utilisez des coroutines pour implémenter des services à haute concurrence côté serveur, vous choisissez non seulement une bibliothèque de coroutines, mais vous trouvez également un framework de coroutines (tel que Tornado) qui combine le multiplexage d'E/S de son écosystème, ce qui peut accélérer le développement.
Résumé des coroutines en une phrase
D'une manière générale, les coroutines sont un modèle de concurrence léger, de niveau relativement élevé. Mais au sens étroit, une coroutine consiste à appeler une fonction qui peut être mise en pause et commutée. Par exemple, ce que nous utilisons async def pour définir est une fonction coroutine, qui est essentiellement une fonction. Lorsque nous appelons la fonction coroutine, nous obtiendrons une coroutine.
Jetez la coroutine dans la boucle d'événements et la boucle d'événements pilote l'exécution. Une fois bloquée, le droit d'exécution est activement transmis à la boucle d'événements et la boucle d'événements entraîne l'exécution d'autres coroutines. Il n'y a donc qu'un seul thread du début à la fin, et la coroutine est juste simulée en mode utilisateur en se référant à la structure du thread.
Ainsi, lorsqu'une fonction normale est appelée, toute la logique du code interne sera exécutée jusqu'à ce que tout soit terminé ; lorsqu'une fonction coroutine est appelée et qu'un blocage interne se produit, elle sera basculée vers d'autres coroutines.
Mais il existe une condition préalable importante pour pouvoir basculer lorsqu'une coroutine est bloquée, c'est-à-dire que ce blocage ne peut impliquer aucun appel système, tel que time.sleep, sockets synchrones, etc. Tout cela nécessite la participation du noyau, et une fois que le noyau participe, le blocage provoqué n'est pas aussi simple que le blocage d'une certaine coroutine (le système d'exploitation n'a pas connaissance de la coroutine), mais entraînera le blocage du thread. Une fois qu'un thread est bloqué, toutes les coroutines au-dessus de lui seront bloquées. Puisque les coroutines utilisent des threads comme supports, l'exécution réelle doit être des threads. Si chaque coroutine bloque le thread, cela n'est pas équivalent à une chaîne.
Donc, si vous souhaitez utiliser des coroutines, vous devez ré-encapsuler les appels système bloqués. Donnons-nous une châtaigne :
.@app.get(r"/index1") async def index1(): time.sleep(30) return "index1" @app.get(r"/index2") async def index2(): return "index2"
这是一个基于 FastAPI 编写的服务,我们只看视图函数。如果我们先访问 /index1,然后访问 /index2,那么必须等到 30 秒之后,/index2 才会响应。因为这是一个单线程,/index1 里面的 time.sleep 会触发系统调用,使得整个线程都进入阻塞,线程一旦阻塞了,所有的协程就都别想执行了。
如果将上面的例子改一下:
@app.get(r"/index1") async def index(): await asyncio.sleep(30) return "index1" @app.get(r"/index2") async def index(): return "index2"
访问 /index1 依旧会进行 30 秒的休眠,但此时再访问 /index2 的话则是立刻返回。原因是 asyncio.sleep(30) 重新封装了阻塞的系统调用,此时的休眠是在用户态完成的,没有经过内核。换句话说,此时只会导致协程休眠,不会导致线程休眠,那么当访问 /index2 的时候,对应的协程会立刻执行,然后返回结果。
同理我们在发网络请求的时候,也不能使用 requests.get,因为它会导致线程阻塞。当然,还有一些数据库的驱动,例如 pymysql, psycopg2 等等,这些阻塞的都是线程。为此,在开发协程项目时,我们应该使用 aiohttp, asyncmy, asyncpg 等等。
为什么早期 Python 的协程都没有人用,原因就是协程想要运行,必须基于协程库 asyncio,但问题是 asyncio 只支持发送 TCP 请求(对于协程库而言足够了)。如果你想通过网络连接到某个组件(比如数据库、Redis),只能手动发 TCP 请求,而且这些组件对发送的数据还有格式要求,返回的数据也要手动解析,可以想象这是多么麻烦的事情。
如果想解决这一点,那么必须基于 asyncio 重新封装一个 SDK。所以同步 SDK 和协程 SDK 最大的区别就是,一个是基于同步阻塞的 socket,一个是基于 asyncio。比如 redis 和 aioredis,连接的都是 Redis,只是在 TCP 层面发送数据的方式不同,至于其它方面则是类似的。
而早期,还没有出现这些协程 SDK,自己封装的话又是一个庞大的工程,所以 Python 的协程用起来就很艰难,因为达不到期望的效果。不像 Go 在语言层面上就支持协程,一个 go 关键字就搞定了。而且 Python 里面一处异步、处处异步,如果某处的阻塞切换不了,那么协程也就没有意义了。
但现在 Python 已经进化到 3.10 了,协程相关的生态也越来越完善,感谢这些开源的作者们。发送网络请求、连接数据库、编写 web 服务等等,都有协程化的 SDK 和框架,现在完全可以开发以协程为主导的项目了。
小结
本次我们从高并发的应用场景入手,分析了协程出现的背景和实现原理,以及它的应用范围。你会发现,协程融合了多线程与异步化编程的优点,既保证了开发效率,也提升了运行效率。有限的硬件资源下,多线程通过微观上时间片的切换,实现了同时服务上百个用户的能力。多线程的开发成本虽然低,但内存消耗大,切换次数过多,无法实现高并发。
异步编程方式通过非阻塞系统调用和多路复用,把原本属于内核的请求切换能力,放在用户态的代码中执行。这样,不仅减少了每个请求的内存消耗,也降低了切换请求的成本,最终实现了高并发。然而,异步编程违反了代码的内聚性,还需要业务代码关注并发细节,开发成本很高。
协程参考内核通过 CPU 寄存器切换线程的方法,在用户态代码中实现了协程的切换,既降低了切换请求的成本,也使得协程中的业务代码不用关注自己何时被挂起,何时被执行。相比异步编程中要维护一堆数据结构表示中间状态,协程直接用代码表示状态,大大提升了开发效率。但是在协程中调用的所有 API,都需要做非阻塞的协程化改造。优秀的协程生态下,常用服务都有对应的协程 SDK,方便业务代码使用。开发高并发服务时,与 IO 多路复用结合的协程框架可以与这些 SDK 配合,自动挂起、切换协程,进一步提升开发效率。
最后,协程并不是完全与线程无关。因为线程可以帮助协程充分使用多核 CPU 的计算力(Python 除外),而且遇到无法协程化、会导致内核切换的阻塞函数,或者计算太密集从而长时间占用 CPU 的任务,还是要放在独立的线程中,以防止它影响别的协程执行。
Ainsi, lors de l'utilisation de coroutines, il est préférable d'utiliser un pool de threads. Si un blocage doit passer par le noyau et qu'il est vraiment impossible de le coroutiner, jetez-le dans le pool de threads et complétez-le au niveau du commutateur. . Bien que le démarrage de plusieurs threads occupera des ressources et que le changement de thread entraînera une surcharge, afin de passer par le blocage du noyau, cela est inévitable, et nous ne pouvons bien sûr placer nos espoirs dans les threads que pour les tâches trop gourmandes en CPU ; intensif, vous pouvez également envisager de le jeter dans le pool de threads. Certaines personnes peuvent être curieuses, si vous pouvez profiter de plusieurs cœurs, alors il est raisonnable de les jeter dans le pool de threads, mais le multithread de Python ne peut pas utiliser plusieurs cœurs, pourquoi faites-vous cela ? La raison est simple. S'il n'y a qu'un seul thread, une telle tâche trop gourmande en CPU occupera les ressources du CPU pendant une longue période, empêchant l'exécution d'autres tâches. Lorsque le multithreading est activé, bien qu'il n'y ait toujours qu'un seul noyau, le GIL provoquera un changement de thread, il n'y aura donc pas de situation comme "le roi de Chu a une taille fine et le harem est mort de faim". Le processeur peut être réparti uniformément, permettant à toutes les tâches d'être exécutées.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!