
Maison >Périphériques technologiques >IA >Soft Diffusion : le nouveau framework de Google planifie, apprend et échantillonne correctement à partir d'un processus de diffusion universel
Soft Diffusion : le nouveau framework de Google planifie, apprend et échantillonne correctement à partir d'un processus de diffusion universel

- 王林avant
- 2023-04-30 13:22:061462parcourir
Nous savons que les modèles basés sur les scores et les modèles probabilistes de diffusion avec débruitage (DDPM) sont deux types puissants de modèles génératifs qui génèrent des échantillons en inversant le processus de diffusion. Ces deux types de modèles ont été unifiés en un seul cadre dans l'article « Modélisation générative basée sur les scores à travers des équations différentielles stochastiques » de Yang Song et d'autres chercheurs, et sont largement connus sous le nom de modèles de diffusion.
Actuellement, le modèle de diffusion a connu un grand succès dans une série d'applications comprenant la génération d'images, d'audio, de vidéo et la résolution de problèmes inverses. Dans l'article « Elucidating the design space of diffusionbased generative models », des chercheurs tels que Tero Karras ont analysé l'espace de conception du modèle de diffusion et identifié trois étapes, à savoir i) la sélection de l'ordonnancement du niveau de bruit, ii) la sélection des paramètres du réseau. isation (chaque paramétrage génère une fonction de perte différente), iii) concevoir l'algorithme d'échantillonnage.
Récemment, dans un article arXiv « Soft Diffusion : Score Matching for General Corruptions » mené conjointement par Google Research et UT-Austin, plusieurs chercheurs estiment que le modèle de diffusion comporte encore une étape importante : la corruption. D'une manière générale, la corruption est un processus d'ajout de bruit de différentes amplitudes et, pour DDMP, nécessite également une mise à l'échelle. Bien qu'il y ait eu des tentatives pour utiliser différentes distributions pour la diffusion, il manque encore un cadre général. Par conséquent, les chercheurs ont proposé un cadre de conception de modèles de diffusion pour un processus de dommages plus général.
Plus précisément, ils ont proposé un nouvel objectif d'entraînement appelé Soft Score Matching et une nouvelle méthode d'échantillonnage Momentum Sampler. Les résultats théoriques montrent que pour les processus de dommages qui satisfont aux conditions de régularité, Soft Score MatchIng est capable d'apprendre leurs scores (c'est-à-dire les gradients de vraisemblance) que la diffusion doit transformer n'importe quelle image en n'importe quelle image avec une vraisemblance non nulle.
Dans la partie expérimentale, les chercheurs ont formé le modèle sur CelebA et CIFAR-10. Le modèle formé sur CelebA a atteint le score SOTA FID du modèle de diffusion linéaire - 1,85. Dans le même temps, le modèle formé par les chercheurs est nettement plus rapide que le modèle formé à l’aide de la diffusion de débruitage gaussienne originale.

Adresse papier : https://arxiv.org/pdf/2209.05442.pdf
Aperçu de la méthode
De manière générale, les modèles de diffusion sont générés en inversant le processus de dommage qui augmente progressivement image de bruit. Les chercheurs montrent comment apprendre à inverser la diffusion impliquant une dégradation déterministe linéaire et un bruit additif stochastique.

Plus précisément, les chercheurs ont démontré un cadre pour entraîner un modèle de diffusion à l'aide d'un modèle de dommage plus général, composé de trois parties, à savoir la nouvelle cible d'entraînement Soft Score Matching, la nouvelle méthode d'échantillonnage Momentum Sampler et la planification. du mécanisme de dommages.
Regardons d'abord l'objectif d'entraînement Soft Score Matching. Le nom est inspiré du filtrage doux, qui est un terme photographique qui fait référence à un filtre qui supprime les détails fins. Il apprend de manière prouvable la fraction d'un processus de dommage linéaire conventionnel, intègre également un processus de filtrage dans le réseau et entraîne le modèle à prédire les images après dommage qui correspondent aux observations de diffusion.
Cet objectif de formation peut prouver que la partition est apprise tant que la diffusion attribue une probabilité non nulle à toute paire d'images propres et corrompues. De plus, cette condition est toujours satisfaite lorsqu’un bruit additif est présent dans le dommage.
Plus précisément, les chercheurs ont exploré le processus de dommage sous les formes suivantes.

Au cours de ce processus, les chercheurs ont découvert que le bruit est important à la fois empiriquement (c'est-à-dire pour de meilleurs résultats) et théorique (c'est-à-dire pour l'apprentissage des fractions). Cela devient également une différence clé avec Cold Diffusion, un travail parallèle qui renverse la corruption déterministe.
La seconde est la méthode d'échantillonnage Momentum Sampling. Les chercheurs ont démontré que le choix de l’échantillonneur a un impact significatif sur la qualité des échantillons générés. Ils ont proposé Momentum Sampler pour inverser un processus de dommage linéaire universel. L'échantillonneur utilise une combinaison convexe de corruptions avec différents niveaux de diffusion et s'inspire des méthodes d'optimisation du moment.
Cette méthode d'échantillonnage s'inspire de la formulation continue du modèle de diffusion proposée dans l'article de Yang Song et al ci-dessus. L’algorithme de Momentum Sampler est présenté ci-dessous.

La figure suivante montre visuellement l'impact des différentes méthodes d'échantillonnage sur la qualité des échantillons générés. L'image échantillonnée avec Naive Sampler à gauche semble répétitive et manque de détails, tandis que le Momentum Sampler à droite améliore considérablement la qualité d'échantillonnage et le score FID.

Enfin, la planification. Même si le type de dégradation est prédéfini (comme le flou), décider de l’ampleur des dommages à chaque étape de diffusion n’est pas anodin. Les chercheurs proposent un outil fondé sur des principes pour guider la conception des processus de dommages. Pour trouver l'horaire, ils minimisent la distance de Wasserstein entre les distributions le long du trajet. Intuitivement, les chercheurs souhaitent une transition en douceur d’une distribution complètement corrompue à une distribution propre.
Résultats expérimentaux
Les chercheurs ont évalué la méthode proposée sur CelebA-64 et CIFAR-10, deux ensembles de données de base standard pour la génération d'images. L’objectif principal de l’expérience est de comprendre le rôle du type de dommage.
Les chercheurs ont d'abord essayé d'utiliser le flou et le bruit de faible amplitude pour provoquer des dommages. Les résultats montrent que le modèle proposé atteint les résultats SOTA sur CelebA, c'est-à-dire un score FID de 1,85, surpassant toutes les autres méthodes qui ne font qu'ajouter du bruit et éventuellement redimensionner l'image. De plus, le score FID obtenu sur CIFAR-10 est de 4,64, ce qui est compétitif même s'il n'atteint pas SOTA.

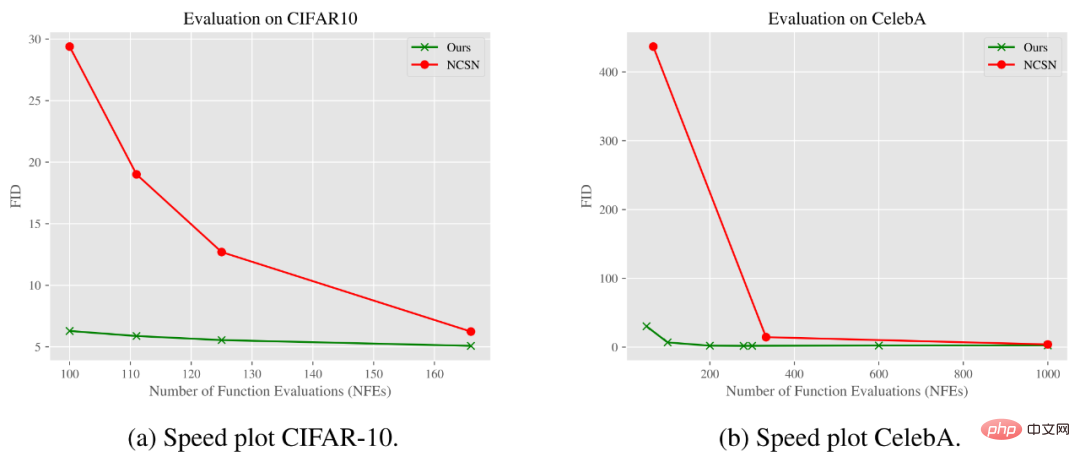
De plus, sur les ensembles de données CIFAR-10 et CelebA, la méthode du chercheur échantillonne un autre indicateur. Elle effectue également mieux avec le temps. Un autre avantage supplémentaire réside dans les avantages informatiques importants. La suppression du flou (presque pas de bruit) semble être une manipulation plus efficace que les méthodes de débruitage par génération d'images.
Le graphique ci-dessous montre comment le score FID évolue avec le nombre d'évaluations fonctionnelles (NFE). Comme le montrent les résultats, notre modèle peut atteindre une qualité identique ou supérieure à celle du modèle de diffusion de débruitage gaussien standard en utilisant beaucoup moins d'étapes sur les ensembles de données CIFAR-10 et CelebA.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI