
Maison >Périphériques technologiques >IA >L'idéal et la réalité de la conduite autonome en boucle fermée
L'idéal et la réalité de la conduite autonome en boucle fermée

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-29 19:25:121355parcourir
Ces dernières années, les données en boucle fermée sont devenues un sujet brûlant dans le secteur de la conduite autonome, et de nombreuses entreprises de conduite autonome tentent de créer leurs propres systèmes de données en boucle fermée.
En fait, la boucle fermée des données n'est pas un concept nouveau. Dans le domaine du génie logiciel traditionnel, la fermeture des données est utilisée comme un moyen important d’améliorer l’expérience utilisateur. Je pense que tout le monde a vécu cette expérience. Lors de l'utilisation d'un logiciel, une fenêtre contextuelle apparaît à l'écran, vous demandant « Autorisez-vous ce logiciel à collecter vos données ? Si vous acceptez les réglementations en vigueur, les données seront alors supprimées. utilisé pour améliorer l’expérience utilisateur.
Lorsque le logiciel client capture un problème, l'arrière-plan peut capturer les données correspondantes, puis l'équipe de développement analyse le problème et répare et améliore le logiciel. La nouvelle version du logiciel est testée par l'équipe de test, puis. la nouvelle version sera publiée. La version du logiciel est placée dans le cloud et mise à jour sur le terminal par l'utilisateur. Il s'agit d'un processus de données en boucle fermée en génie logiciel.
Dans les scénarios de conduite autonome, les données sur les problèmes sont généralement collectées sur des véhicules d'essai, et très peu de véhicules peuvent être collectés sur des véhicules produits en série. Après la collecte, les données doivent être annotées, puis les ingénieurs utilisent les nouvelles données pour entraîner le modèle de réseau neuronal dans le cloud. Le modèle recyclé est généralement déployé sur le véhicule via OTA.
Une boucle fermée complète de données comprend généralement la collecte de données, la redistribution des données, le traitement des données, l'annotation des données, la formation du modèle, ainsi que les tests et la vérification.
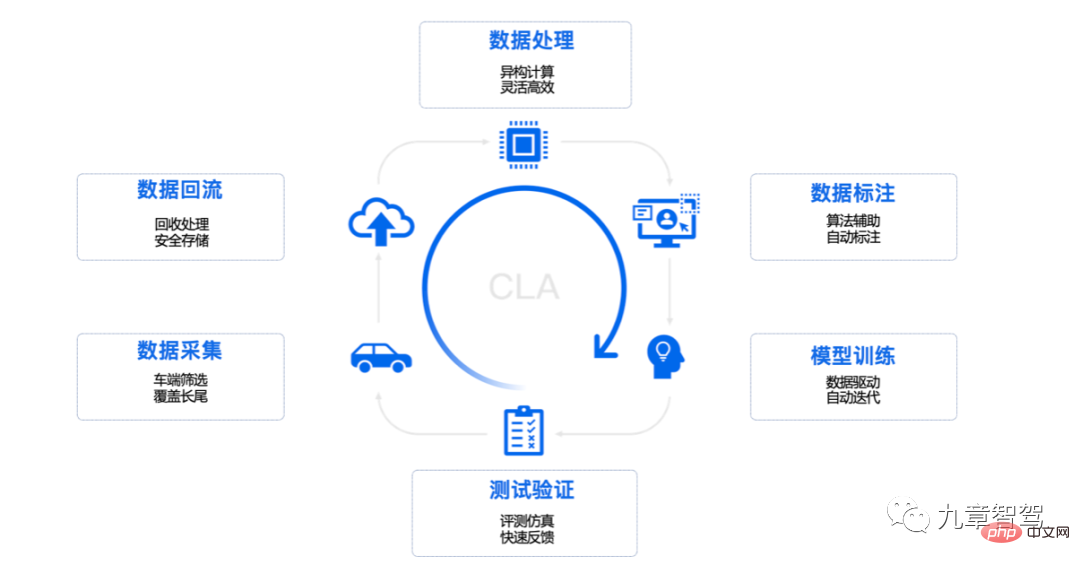
Diagramme de processus en boucle fermée des données Momenta
En prenant Tesla comme exemple, une flotte équipée d'un matériel de conduite autonome collecte des données filtrées par des règles et des déclencheurs en mode ombre, et passe par la sémantique Les données filtrées sont renvoyées vers le cloud. Après cela, les ingénieurs utilisent des outils dans le cloud pour effectuer un traitement sur les données, puis placent les données traitées dans le cluster de données, puis utilisent ces données efficaces pour entraîner le modèle. Une fois le modèle formé, les ingénieurs déploieront le modèle formé sur le terminal du véhicule pour une série de tests d'indicateurs. Le nouveau modèle vérifié sera déployé sur le terminal du véhicule pour être utilisé par le conducteur.
Dans ce modèle, de nouvelles données seront continuellement déclenchées pour être renvoyées, formant ainsi un cycle. À ce stade, un cycle complet de développement itératif basé sur les données est formé.
Actuellement, l'utilisation de données en boucle fermée pour piloter l'itération d'algorithmes a presque été reconnue comme le seul moyen d'améliorer les capacités de conduite autonome. De nombreux équipementiers et constructeurs de conduite autonome de niveau 1 construisent leurs propres systèmes de données en boucle fermée et disposent même d'un poste dédié d'architecte de données en boucle fermée.
Quelle est la signification de la boucle fermée de données ? Quel est le contexte de la mise en œuvre d’une boucle fermée de données dans les voitures produites en série ? Quels sont les problèmes liés à la mise en œuvre de la boucle fermée de données dans les véhicules de production de masse et comment les résoudre ?
Ensuite, cet article abordera ces sujets un par un.
01 L'importance de la boucle fermée des données
Selon l'introduction de MAXIEYE, une technologie de conduite intelligente, « La boucle fermée des données ne consiste pas seulement à améliorer les performances d'une certaine fonction, mais également à vérifier de nouvelles fonctions dans le forme de mode ombre. En même temps, selon le type de déclenchement des données, il peut également aider à optimiser d'autres aspects du système, tels que la détection de blocage radar/caméra, et le seuil peut être optimisé en fonction des données de retour. le niveau de performance, le retour de données peut fondamentalement optimiser toutes les performances, telles que AEB, LKA, ELK, ACC, TJA, NOA, etc. MAXIEYE a continuellement mis à niveau AEB, ACC, TJA et d'autres fonctions du système via le retour de données OTA, et a pré -intégré le mode fantôme de nouvelles fonctions. "
Aujourd'hui, diverses entreprises. Ils ont construit leurs propres systèmes de données en boucle fermée. Les principaux effets qu'ils espèrent obtenir incluent l'amélioration de l'efficacité de la collecte de données de cas d'angle, l'amélioration de la généralisation. capacité du modèle et piloter l’itération de l’algorithme.
1.1 Collecter les données des cas d'angle
Tant qu'il s'agit d'un produit L2 et supérieur, il doit avoir la capacité de continuer à évoluer. Pour que le système de conduite autonome continue d’évoluer, il est nécessaire d’obtenir en permanence des données sur les cas d’urgence. À mesure que de plus en plus de cas d'angle passent de « inconnu » à « connu », il devient de plus en plus difficile d'excaver de nouveaux cas d'angle à travers un nombre limité de véhicules d'essai avec des itinéraires de forme limités.
En déployant un système de collecte de données sur des véhicules produits en série avec une couverture de scène plus large, c'est un moyen de déclencher le transfert de données lorsque l'on rencontre des situations que le système de conduite autonome actuel ne peut pas gérer suffisamment bien. récupérez le boîtier d'angle.
Par exemple, le système AEB peut être déployé sur un véhicule de série équipé de la conduite assistée L2, puis collecter les données du conducteur qui appuie sur les freins, claquement sur l'accélérateur, claquement sur le volant et claquement sur le volant Tournez le volant et d'autres données pour analyser pourquoi le système AEB ne répond pas lorsque le conducteur effectue ces opérations. Des améliorations correspondantes devraient être apportées pour résoudre le problème selon lequel le système AEB ne répond pas suffisamment bien pour améliorer les capacités du système AEB.
1.2 Améliorer la capacité de généralisation du modèle
#🎜 🎜 #Actuellement, la conduite assistée de haut niveau se déplace des autoroutes vers les villes. Pour résoudre des scénarios relativement simples tels que la grande vitesse, il suffit en principe d'entraîner le modèle uniquement avec les données collectées par la voiture d'essai, au lieu de devoir renvoyer les données de la voiture de série. Cependant, la complexité des scènes urbaines a été grandement améliorée ; augmenté, et Il existe également de nombreuses différences dans les conditions routières selon les villes. Par exemple, à Guangzhou, vous pouvez voir partout des tricycles tirant des marchandises à grande vitesse sur la route, mais c'est rarement le cas à Shanghai.
Par conséquent, de nombreux constructeurs automobiles et de niveau 1 de conduite autonome ont une forte demande d'intégration de scène - c'est-à-dire que le système de conduite assistée du véhicule peut gérer correctement diverses conditions routières dans le grand public villes . Étant donné que les constructeurs automobiles ne peuvent pas limiter l'autonomie des utilisateurs, si la fonction de conduite assistée n'est fournie que pour une petite zone, cela réduira considérablement le champ d'application de la base d'utilisateurs. Ce n'est évidemment pas ce que les constructeurs automobiles souhaitent voir.
Pour atteindre l'objectif d'ouverture des scénarios, la capacité de généralisation du modèle doit être grandement améliorée. Pour améliorer considérablement la capacité de généralisation du modèle, il est nécessaire de collecter autant que possible des données correspondant à divers scénarios. Seule la conduite assistée par les voitures particulières, basée sur des données de conduite humaine réelles à grande échelle, a la capacité d'accumuler des données d'une échelle et d'une variété suffisantes. # 🎜🎜 ##### 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # 1.3 itération de l'algorithme de lecteur # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜 🎜 # comme mentionné précédemment , le développement d’algorithmes d’intelligence artificielle basés sur le deep learning a dépassé dix ans. Durant cette période, avec l’évolution des modèles et le développement de la puissance de calcul, il est devenu possible pour le système de conduite autonome de digérer le big data. De plus, si le système de conduite autonome doit être mis à niveau, les capacités de perception, de planification et d'autres aspects doivent être améliorées en conséquence. L'utilisation de données pour faire évoluer l'algorithme en permanence est un moyen efficace d'améliorer les capacités de perception, de planification et d'amélioration. d'autres aspects.
Urban NOA - c'est-à-dire que la fonction d'assistance à la navigation point à point dans la ville est le prochain objectif de nombreux constructeurs OEM et de conduite autonome de niveau 1 pour atteindre le point à Les fonctions de conduite d'assistance à la navigation par points, la reconnaissance sémantique, la reconnaissance des obstacles et la reconnaissance de la zone roulable du système de perception doivent toutes avoir un certain degré de précision. Cependant, cette norme n'a pas encore été atteinte. L'architecture réseau actuelle du système de perception grand public est basée sur le modèle BEV+Transformer, qui s'appuie uniquement sur des ingénieurs logiciels ou des architectes d'algorithmes pour l'optimiser. amélioration du modèle. L'architecture de BEV+Transformer peut accueillir une grande quantité de données, ce qui devrait améliorer l'effet du modèle.
Au niveau de la planification, le data drive peut également jouer un rôle. Tesla avait auparavant utilisé la solution optimale sous contraintes partielles comme valeur initiale, puis utilisé une approche incrémentale pour ajouter continuellement de nouvelles contraintes, puis résolu le problème d'optimisation après avoir ajouté des contraintes, et a finalement obtenu la solution optimale pour le problème de planification. Les ingénieurs de Tesla ont effectué de nombreuses pré-générations hors ligne pour cette méthode et ont effectué une optimisation parallèle en ligne, de sorte que le temps de calcul de chaque chemin candidat reste toujours de 1 à 5 ms. Selon ce que Tesla a révélé lors de sa journée de l'IA du 30 septembre 2022, les ingénieurs de Tesla utilisent désormais un ensemble de modèles de génération d'arbres de décision basés sur les données pour aider le système de conduite autonome à générer rapidement des chemins planifiés. Ce modèle de génération d'arbre de décision basé sur les données utilise les données de conduite des conducteurs humains de la flotte Tesla et le chemin optimal sans contraintes de temps comme véritable valeur pour la formation. Il peut générer un chemin de planification candidat dans un délai de 100 us, ce qui réduit considérablement le temps de génération. les plans des candidats.
Il ressort de ce qui précède que la construction d'un bon système de données en boucle fermée est un moyen important d'améliorer les capacités du système de conduite autonome.
02 Fond de données en boucle fermée
Actuellement, de nombreux véhicules produits en série sont équipés d'une conduite assistée systèmes , les gens peuvent collecter des données sur les véhicules produits en série, et il n'est pas difficile que le kilométrage d'essai routier du système de conduite autonome dépasse 100 millions de kilomètres. En outre, la puissance de calcul de la puce a été encore améliorée : par exemple, la puce OrinX de NVIDIA a une puissance de calcul allant jusqu'à 254TOPS, de sorte que de grands modèles commencent à être appliqués aux systèmes de perception, permettant ainsi aux systèmes de conduite autonomes de digérer le Big Data. D’un autre côté, la technologie cloud est relativement mature et la conduite autonome commence lentement à entrer dans l’ère des données. L'explication de la société MAXIEYE est la suivante : « Pour être précis, ce n'est pas seulement basé sur les données, mais l'algorithme d'IA et les données sont pilotés ensemble pour résoudre le problème de l'efficacité de l'apprentissage, et les données résolvent le problème de l'apprentissage du contenu. dans une relation symbiotique. "
" Le développement d'algorithmes d'intelligence artificielle basés sur l'apprentissage profond a duré plus de dix ans. Au début de cette décennie, l'apprentissage supervisé était la norme dans le monde universitaire et l'industrie, et l'apprentissage supervisé était le courant dominant. Dans le monde universitaire et industriel, il existe un défaut fatal, à savoir qu’il nécessite beaucoup d’annotations manuelles, ce qui limite considérablement la marge de progrès de l’IA. Cependant, ces dernières années, des algorithmes d’apprentissage non supervisés et semi-supervisés ont lentement commencé à émerger. , et les ordinateurs peuvent apprendre en permanence grâce à l'auto-apprentissage. Par conséquent, les conditions pour développer une technologie de conduite autonome grâce à une approche basée sur les données sont réunies. " Yang Jifeng, directeur du Great Wall Salon Intelligent Center, a déclaré dans un discours : " From From la perspective de l'ensemble du véhicule, l'architecture en boucle fermée et les données en boucle fermée de L2 à L4 seront achevées en 2022, et l'architecture côté véhicule et l'architecture cloud seront encore unifiées. Le prochain concours est l'exploration de données, l'utilisation efficace. des données et la compréhension des données par l'ensemble de la pile technologique. Et comment équilibrer toute l'efficacité informatique sur une infrastructure à grande échelle »
03 Points faibles et contre-mesures pour la mise en œuvre de la boucle fermée des données
At. À l’heure actuelle, tout le monde est parvenu à un consensus sur l’importance de la boucle fermée de données pour les systèmes de conduite autonome. Le moment est fondamentalement mûr pour une mise en œuvre sur des véhicules produits en série. Alors, comment se déroule la mise en œuvre concrète de la boucle fermée des données de chaque entreprise ? Comment juger de l’efficacité du système de données en boucle fermée d’une entreprise ?
L'auteur a appris de la technologie de conduite intelligente MAXIEYE que pour la conduite autonome de niveau 1, la réalisation technique d'une boucle fermée de données n'est pas un problème. Essentiellement, ce qui compte, c'est la force du produit de niveau 1 - s'il peut responsabiliser les constructeurs automobiles. boucle fermée de données. Deuxièmement, l'effet de la boucle fermée de données dépend également de la question de savoir si l'itération du produit est pilotée par une boucle fermée de données, si le logiciel et l'algorithme peuvent être optimisés sur la base des données renvoyées et déployés régulièrement sur le terminal via OTA.
Actuellement, selon le niveau de capacités des données en boucle fermée, la conduite autonome de niveau 1 peut être divisée en trois catégories : la première est celle des données en boucle fermée qui ont atteint une production de masse à grande échelle, la seconde est celle des données en boucle fermée. via des véhicules de collecte, et le troisième C'est parce que nous n'avons pas encore atteint la capacité de boucler la boucle des données. À l’heure actuelle, le premier type est encore minoritaire.
Selon les informations échangées entre l'auteur et les initiés de l'industrie, la plupart des entreprises utilisent actuellement des véhicules de collecte comme source de données. En raison de divers facteurs tels que la confidentialité des utilisateurs, l'infrastructure et le coût, la collecte de données à grande échelle sur les véhicules produits en série pour les mises à niveau itératives des systèmes de conduite autonome n'a pas encore été réalisée. Certaines entreprises n'ont pas encore mis en place un processus de collecte de données sur les véhicules produits en série pour une utilisation des données en boucle fermée. Bien que certaines entreprises aient mis en place un processus et collecté certaines données, elles n'ont pas encore utilisé ces données à bon escient.
Il est rapporté que quelques entreprises collecteront des données sur des véhicules produits en série, mais les initiés de l'industrie rapportent que les données actuellement collectées sont principalement utilisées pour diagnostiquer des défauts dans le système de conduite autonome actuel, plutôt que pour l'itération de profondes modèles d'apprentissage.
En d'autres termes, peu d'entreprises ont véritablement réalisé la boucle fermée des données de la production de masse à grande échelle, c'est-à-dire faire bon usage des données collectées à partir de véhicules produits en série à grande échelle pour améliorer les capacités des systèmes de conduite autonomes. Alors, quels sont les problèmes liés à la production de masse de données en boucle fermée ? Quelles sont les stratégies pour faire face à ces points douloureux ?
Les questions qui doivent être prises en compte dans la pratique de la production de masse comprennent, sans toutefois s'y limiter : comment garantir la conformité de la collecte et de l'utilisation des données, comment résoudre le problème de la validation des données, comment la fonction de collecte de données coexiste avec le système de conduite autonome et la difficulté du traitement des données. Les grands systèmes logiciels basés sur les données sont très complexes et la formation de modèles est difficile. 3.1 Problèmes de conformité dans la collecte et l'utilisation des données conformité de la collecte des données relatives à la confidentialité des utilisateurs.
En termes de conformité en matière d'arpentage et de cartographie, ces dernières années, le pays a renforcé sa gestion de la sécurité des données et introduit des lois et réglementations pertinentes pour limiter la portée des données renvoyées. Après les « 830 nouvelles réglementations » en 2022, les données collectées par les véhicules sur la route appartiennent aux données d'arpentage et de cartographie. Si une entreprise souhaite utiliser des données d'arpentage et de cartographie, le cryptage et la conformité ultérieurs des données sont essentiels.
Tout d'abord, lors de la collecte de données sur la route, les entreprises doivent posséder des qualifications nationales en matière d'arpentage et de cartographie et effectuer les déclarations correspondantes, sinon le processus de collecte sera bloqué par la sécurité nationale et d'autres départements. À l'heure actuelle, il existe en Chine environ 30 institutions possédant les qualifications requises. Certaines entreprises possèdent des qualifications nationales de classe A en matière de navigation électronique, qui ont un large éventail d'applications et peuvent être collectées dans de nombreuses villes du pays. Certaines entreprises ont des qualifications de classe B. les qualifications, qui ont un large éventail d’applications, seront plus petites et ne pourront être collectées que dans des villes spécifiques. Étant donné que les qualifications en matière d'arpentage et de cartographie sont difficiles à obtenir, une accumulation d'affaires à long terme est nécessaire. De plus, pour maintenir les qualifications en matière d'arpentage et de cartographie, les entreprises doivent disposer des services d'arpentage et de cartographie correspondants. Par conséquent, les équipementiers et la conduite autonome de niveau 1 font généralement confiance à des fournisseurs ou à des unités qualifiés. Par exemple, certains fournisseurs de cloud aident désormais les clients à concevoir un plan de conformité autour de l'acquisition, du traitement et de l'utilisation des données. Une fois les données collectées, elles doivent être désensibilisées et chiffrées côté voiture. Après leur téléchargement sur le cloud (en général, il s'agit d'un cloud privé), un travail de mise en conformité doit être effectué. sera effectué par des fournisseurs ou des unités qualifiés. Venez aider à la conformité des levés et de la cartographie. Pour certaines données très sensibles, elles doivent être collectées par le revendeur d'images, et les données doivent être désensibilisées et stockées sur le serveur supervisé par le revendeur d'images. De plus, les données d'arpentage et de cartographie ne doivent pas être divulguées, en particulier les données ne doivent pas être déplacées à l'étranger. Les ressortissants non chinois ne peuvent ni obtenir de données d'arpentage et de cartographie ni exploiter des données d'arpentage et de cartographie au sein de l'entreprise. De manière générale, les constructeurs OEM et la conduite autonome Tier1 établiront leurs propres centres de données. Pour des raisons de sécurité, ces centres de données sont relativement fermés. Lorsque les équipementiers et les véhicules autonomes de niveau 1 doivent utiliser les données stockées dans ces centres de données pour effectuer des formations, des simulations, etc., en fonction des exigences de conformité, les modèles pertinents doivent être déployés dans le centre de données pour être utilisés. Certains experts du secteur ont déclaré : « Le processus de conformité pour l'arpentage et la cartographie est trop compliqué et les qualifications sont difficiles à obtenir. Tout le monde espère réduire autant que possible la dépendance à l'égard des cartes de haute précision. L'accent est mis sur la solution de perception et de carte lumineuse dans l'industrie. Mais en fait, les cartes lumineuses ne sont pas nécessairement « meilleures », car l'effet d'avoir des données cartographiques est nettement meilleur que de ne pas les avoir. forme, et ce n'est pas nécessairement le meilleur, c'est exactement ce que tout le monde espère faire. C'est plus simple. Comme pour l’utilisation de WeChat, les entreprises exigent que les utilisateurs signent au début un accord d’autorisation et informent les utilisateurs des données qui seront collectées et des comportements d’utilisation qui seront enregistrés. À l'heure actuelle, en termes de respect de la vie privée, le pays n'a pas encore publié de plan particulièrement spécifique stipulant quelles données peuvent être collectées et lesquelles ne le peuvent pas. Au lieu de cela, il existe seulement une clause relativement large qui stipule que les collecteurs de données « ne doivent pas ». fuite de la vie privée des utilisateurs." En fonctionnement réel, les données liées aux informations de l'utilisateur doivent être désensibilisées, par exemple, le numéro de plaque d'immatriculation doit être masqué, etc. 3.2 Problème de droits sur les données Peut-on collecter sur la voiture les données des caméras, des lasers ou des ondes millimétriques requises par l'industrie de la conduite autonome ? Su Linfei, chef de produit intelligent de Moshi, a déclaré : « Conformément aux dispositions pertinentes de la « loi chinoise sur la protection des informations personnelles », la collecte de données qui n'est pas autorisée par la loi est soumise à la protection de la vie privée. L'Agence de protection a de telles réglementations. Si le conducteur n'est pas la victime, l'enregistrement des visages et des véhicules d'autres conducteurs sans leur consentement constitue une violation de la loi sur la protection des informations personnelles. En d'autres termes, même si le propriétaire de la voiture enregistre les informations d'autrui, cela peut. Cependant, en raison des problèmes liés aux véhicules à énergie nouvelle, le secteur de la conduite autonome est très nouveau et les réglementations juridiques font encore défaut. Nous déduisons donc, sur la base de concepts juridiques de base, que les données collectées par les véhicules produits en série doivent être détenues. par les propriétaires de voitures. " Les données collectées par les propriétaires de voitures utilisant leurs propres véhicules peuvent-elles être autorisées ? Qu'en est-il des autres unités qui les utilisent ? Actuellement, il n'existe aucune réglementation ni restriction légale pertinente. Mais dans d’autres secteurs, comme la téléphonie mobile et Internet, cela est largement autorisé. Qui peut obtenir les données téléchargées par les propriétaires de voitures ? Du point de vue de la division du travail dans la chaîne de l'industrie automobile, deux types d'entités peuvent l'obtenir. La première est une société d'exploitation de flotte sans pilote, comme le taxi sans conducteur de Baidu, et la seconde est un équipementier. Cependant, comme le premier est relativement petit, nous nous concentrons sur le second. Étant donné que l'OEM est le plus proche de l'utilisateur, il est plus simple d'obtenir les données téléchargées par l'utilisateur. À l’échelle mondiale, Tesla est le meilleur équipementier à cet égard. Actuellement, les constructeurs OEM ouvrent rarement les données au monde extérieur. Par conséquent, après que la conduite autonome de niveau 1 ait aidé les constructeurs à mettre en œuvre des fonctions personnalisées, il est difficile de collecter les données des utilisateurs lors de l'utilisation de ces fonctions. à moins que Tier1 ne dispose de ses propres voitures d’essai. Ensuite, il sera difficile pour la conduite autonome de niveau 1 d'effectuer une optimisation ultérieure des fonctions pertinentes sur la base des données de retour des utilisateurs, et il sera difficile de réaliser une boucle fermée de données. Moshi Intelligent Product Manager, Su Linfei, a déclaré à l'auteur : « Après avoir terminé un projet pour l'OEM, si l'OEM n'ouvrait pas l'interface de données, ce serait difficile pour que nous puissions l'obtenir. Après avoir reçu les commentaires des utilisateurs, nous avons réitéré davantage les performances des produits pour ce modèle. En fin de compte, la plupart des fournisseurs de systèmes de conduite autonomes sont devenus des entreprises dont les opérations de projet étaient au cœur et ont été progressivement éliminées à mesure que les performances des produits prenaient du retard 🎜. 🎜# Pour les OEM, s'ils n'ouvrent pas les données aux fournisseurs, ils devraient alors explorer eux-mêmes la valeur des données. Au début, personne ne connaissait la valeur spécifique de ces données. Ce n’est qu’en les utilisant que la valeur a pu être lentement découverte. L'OEM peut d'abord donner les données aux fournisseurs et en conserver une copie pour lui-même. Le fournisseur peut ensuite les restituer à l'OEM après avoir découvert la valeur des données. Désormais, certains constructeurs OEM demanderont à leurs fournisseurs de continuer à les aider à itérer les logiciels après les opérations, et les fournisseurs peuvent également utiliser cela comme une opportunité pour obtenir des données. les fournisseurs peuvent parvenir à une situation gagnant-gagnant. Bien entendu, du point de vue de l’OEM, cette méthode présente encore quelques défauts, car il est difficile pour les fournisseurs de garantir que l’effet s’améliorera après les itérations. Il est également difficile pour les OEM de vérifier les effets des itérations, c'est pourquoi ils demandent souvent aux fournisseurs d'ouvrir des interfaces pour les données sur les résultats intermédiaires (tels que les résultats de reconnaissance des cibles de perception), afin que les OEM puissent vérifier les itérations des fournisseurs au moyen d'indicateurs statistiques de résultats intermédiaires. . Effet. À l'heure actuelle, cela nécessite principalement que les deux parties aient une mentalité de confiance mutuelle et de coopération sincère. L'OEM doit ouvrir le droit d'utiliser les données au fournisseur, puis. le fournisseur peut régulièrement mettre à jour le logiciel et être en mesure de voir les effets correspondants afin que la coopération puisse se poursuivre. C’est juste que ce modèle n’a pas encore été largement accepté parce que tout le monde n’a pas vu d’effets évidents. 3.3 La collecte de données occupera des ressources système En production de masse La collecte de données sur le véhicule occupera certaines ressources du système, telles que l'informatique et le stockage. En théorie, on peut supposer que les ressources informatiques, la bande passante du réseau, etc. ne sont pas limitées. Cependant, dans le processus de mise en œuvre réel, comment garantir que les données collectées n'affectent pas le fonctionnement normal du système de conduite autonome sur les produits de série. les véhicules, par exemple, comment ne pas affecter le retard du système de conduite autonome. Attendez, c'est un problème qui doit être résolu. Bien entendu, certaines entreprises téléchargeront des données lorsque le système de conduite autonome ne fonctionne pas, afin qu'il n'y ait pas de problème d'occupation des ressources. Cependant, certains acteurs du secteur estiment que le téléchargement de données uniquement lorsque le système de conduite autonome ne fonctionne pas limitera la quantité de données collectées. À ce stade, il est toujours nécessaire de collecter autant de données que possible. Ensuite, lors de la conception, il est nécessaire de considérer l’impact de la collecte de données sur le fonctionnement du système de conduite autonome. 3.4 L'étiquetage et le traitement ultérieur des données sont difficiles Selon On estime qu'une fois les données retransmises par le véhicule produit en série, la quantité de données retransmises par le vélo chaque jour est d'environ 100 mégaoctets. Au stade de la recherche et du développement, le nombre total de véhicules peut n’être que de quelques dizaines ou quelques centaines. Mais au stade de la production de masse, le nombre de véhicules peut atteindre des dizaines de milliers, des centaines de milliers, voire plus. Ensuite, au stade de la production de masse, la quantité de données générées chaque jour par l’ensemble de la flotte est énorme. La quantité de données en forte augmentation a posé des défis à la fois en termes d'espace de stockage et de vitesse de traitement des données. Après la production de masse, la latence du traitement des données doit être maintenue au même niveau qu'au stade de la R&D. Mais si l’infrastructure sous-jacente ne peut pas suivre le rythme, les retards de traitement des données augmenteront proportionnellement à mesure que la quantité de données augmente, ce qui ralentira considérablement la progression du processus de recherche et développement. Pour l’itération du système, cette réduction d’efficacité est inacceptable. Un expert de l'industrie a déclaré à l'auteur : « Actuellement, nous n'avons vu aucune entreprise capable de gérer les données à grande échelle renvoyées par les véhicules produits en série. Même une entreprise qui effectue un travail plus de pointe en matière de le niveau des données en boucle fermée Les nouvelles forces de la construction automobile, même si chaque voiture produite en série ne renvoie que 5 minutes de données par jour, elles auront du mal à gérer un tel volume de données, car les dispositifs de stockage actuels, les systèmes de lecture de fichiers, les outils informatiques, etc. ne peuvent pas encore faire face à l'énorme quantité de données. " Pour faire face à la quantité croissante de données, l'infrastructure sous-jacente et la conception de la plate-forme doivent être mises à niveau en conséquence. L'équipe d'ingénierie doit développer un SDK complet d'accès aux données. Étant donné que la taille des fichiers de données visuelles et radar est très volumineuse, les processus d'accès, d'interrogation, de saut et de décodage des données doivent être suffisamment efficaces, sinon les progrès de la recherche et du développement seront considérablement ralentis. Une fois les données côté véhicule retransmises vers le cloud, l'équipe d'ingénierie doit étiqueter une grande quantité de données en temps opportun. L'industrie utilise actuellement des modèles pré-entraînés pour l'annotation auxiliaire, mais lorsque la quantité de données est importante, l'annotation nécessite encore beaucoup de travail. Lors de l'étiquetage des données, vous devez également vous assurer de la cohérence des résultats de l'étiquetage. À l'heure actuelle, l'industrie n'a pas encore mis en œuvre l'annotation entièrement automatique des données et nécessite toujours un travail manuel pour effectuer une partie de la charge de travail. En fonctionnement manuel, garantir la cohérence des résultats d’étiquetage lorsque la quantité de données est énorme constitue également un défi de taille. De plus, les données liées à la conduite autonome sont non seulement volumineuses, mais également de types variés, ce qui rend également le traitement des données plus difficile. Les types de données sont divisés selon la source, y compris les données du véhicule, les données de localisation, les données de détection de l'environnement, les données d'application, les données personnelles, etc., et divisés selon le format, y compris les données structurées et les données non structurées, et les types de services de données incluent les fichiers, les objets, etc. Comment unifier les normes et coordonner les différents types d'interfaces de stockage et d'accès constituent également un gros problème. 3.5 Les systèmes logiciels basés sur les données sont très complexes Le modèle de développement traditionnel en forme de V est difficile à appliquer aux boucles fermées de données. De plus, il n’existe actuellement aucune plate-forme de développement logiciel ni middleware unifié pour la conduite autonome de haut niveau dans l’industrie. Un expert technique du département de conduite autonome d'une entreprise a déclaré à l'auteur : « Le système d'itération des fonctions de conduite autonome piloté par des données et des modèles d'apprentissage profond peut être appelé logiciel 2.0. Dans ce modèle, l'ensemble du système, y compris la constitution d'équipes, Le. Le processus de R&D, les méthodes de test et les chaînes d'outils sont tous construits autour des données. « À l'ère du logiciel 1.0, il est facile d'évaluer le code que chacun soumet et l'effet attendu. Cependant, à l'ère du logiciel 2.0, il est devenu plus difficile de mesurer l'impact de la contribution de chacun sur l'effet global, et il est également difficile de le prédire à l'avance, car ce que tout le monde communique n'est plus du code clairement visible, mais données et communication basée sur les données. Modèle mis à jour. Lorsque la quantité de données est très faible, par exemple lorsque nous travaillions sur l'algorithme de vision IA pour les applications Internet mobiles, en raison de la petite quantité de données, les ingénieurs de modèles visuels impliqués géraient essentiellement leurs propres dossiers sous Windows ou Ubuntu, et les membres de l'équipe utilisent directement divers dossiers renommés pour effectuer des transferts entre eux, ce qui est très inefficace pour l'échange de données ou la coopération. Mais lorsqu'il s'agit de tâches de conduite autonome, nous sommes confrontés à des centaines de milliers d'images, et des centaines de personnes développent conjointement un système. Chaque changement implique des centaines, voire des milliers de modules. Comment évaluer la qualité du code de chaque module et comment vérifier s'il y a des conflits entre les modules sont des tâches relativement complexes. Jusqu’à présent, je pense que ce système est encore médiocre et que la partie ingénierie n’est pas suffisamment mature. Au stade du logiciel 2.0, les questions qui doivent encore être résolues sont : comment mesurer l'impact des nouvelles données sur des scénarios spécifiques et sur la situation globale, et comment éviter que les modèles de recyclage basés sur de nouvelles données échouent dans certains cas. tâches spécifiques. L’effet s’améliore mais globalement l’effet diminue. Pour résoudre ces problèmes, nous devons effectuer des tests unitaires pour vérifier si l'ajout de certaines données aidera les scénarios segmentés que nous voulons résoudre et si cela améliorera la situation globale. Par exemple, si pour une tâche spécifique, l'ensemble de données d'origine contient 20 millions d'images, puis que 500 images supplémentaires sont ajoutées, la capacité à résoudre cette tâche spécifique s'est améliorée, mais parfois cela signifie également que le score du modèle a été réduit lors du traitement. avec des tâches globales. De plus, pour les tâches visuelles, en plus de juger de l'impact des nouvelles données sur le modèle à partir d'indicateurs, il faut aussi voir réellement quel est l'impact spécifique, afin de savoir si l'optimisation répond aux attentes. Le simple examen des indicateurs peut conduire à des situations dans lesquelles, même si les indicateurs se sont améliorés, les résultats réels ne répondent toujours pas aux attentes. Nous avons également besoin d'un ensemble d'infrastructures pour garantir que chaque mise à jour soit globalement optimale. Cette infrastructure impliquera la gestion des données, l'évaluation des formations, etc. Tesla est à l'avant-garde du secteur à cet égard. L'ensemble de son lien basé sur les données a été conçu pour diriger le secteur dès le début, et de 2019 à 2022, il n'aura pas besoin de beaucoup de changements pour soutenir ses produits. 3.6 La difficulté de la formation du modèle augmente Après avoir résolu les problèmes de collecte de données, de stockage, d'étiquetage, etc., la formation ultérieure du modèle et l'itération des fonctions restent des défis. La formation à la grande quantité de données renvoyées par les véhicules de production nécessite un système de transfert de fichiers efficace pour garantir que la formation n'est pas "bloquée" par les E/S. En même temps, vous devez disposer d'une puissance de calcul suffisante. La manière d'améliorer la puissance de calcul consiste généralement à créer un cluster parallèle multi-cartes. Ensuite, comment maintenir une communication efficace entre les cartes pendant la formation afin de réduire les délais de transmission des données et d'utiliser pleinement et efficacement la puissance de calcul de chaque carte est également un problème. doit être pris en compte. Afin de faire face à la demande de puissance de calcul dans la formation de modèles, certains constructeurs OEM ont spécialement construit leurs propres centres de calcul intelligents. Cependant, le coût de construction d’un centre informatique intelligent est très élevé et cela est presque impossible pour les petites et moyennes entreprises. Bien qu'il existe encore de nombreux points douloureux actuellement, nous pouvons toujours nous attendre à ce qu'avec le temps, les problèmes actuels soient résolus un par un. D'ici là, les données en boucle fermée pourront être véritablement mises en œuvre sur des véhicules produits en série, et les données collectées après avoir été mises en œuvre sur des véhicules produits en série renverront le système de données en boucle fermée et pousseront le système de conduite autonome à un niveau supérieur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI