
Maison >Périphériques technologiques >IA >Un GPU grand public exécute avec succès un grand modèle avec 176 milliards de paramètres
Un GPU grand public exécute avec succès un grand modèle avec 176 milliards de paramètres

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-28 12:19:061285parcourir
Exécuter des modèles à grande échelle sur des GPU grand public est un défi auquel est confrontée la communauté du machine learning.
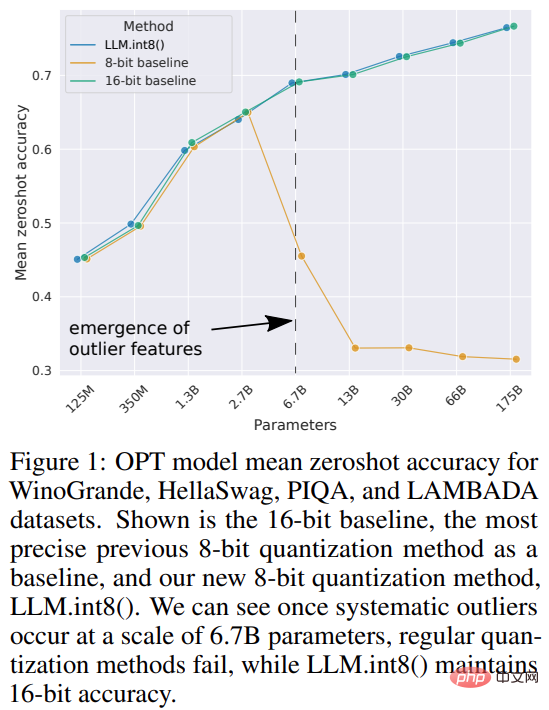
La taille des modèles de langage est devenue plus grande. PaLM a 540B de paramètres, OPT, GPT-3 et BLOOM ont environ 176B de paramètres. Le modèle continue de se développer dans une direction plus large.

Ces modèles sont difficiles à exécuter sur des appareils facilement accessibles. Par exemple, le BLOOM-176B doit fonctionner sur huit GPU A100 de 80 Go (~ 15 000 $ chacun) pour terminer la tâche d'inférence, tandis que le réglage fin du BLOOM-176B nécessite 72 de ces GPU. Les modèles plus grands tels que PaLM nécessiteront plus de ressources.
Nous devons trouver des moyens de réduire les besoins en ressources de ces modèles tout en maintenant leurs performances. Diverses techniques ont été développées dans le domaine pour tenter de réduire la taille du modèle, telles que la quantification et la distillation.
BLOOM a été créé l'année dernière par plus de 1 000 chercheurs bénévoles dans le cadre d'un projet appelé "BigScience". Le projet est géré par la startup d'intelligence artificielle Hugging Face grâce à des fonds du gouvernement français. Le modèle BLOOM a été officiellement lancé le 12 juillet de cette année. .
L'utilisation de l'inférence Int8 réduira considérablement l'empreinte mémoire du modèle, mais ne réduira pas les performances de prédiction du modèle. Sur cette base, des chercheurs de l'Université de Washington, du Meta AI Research Institute (anciennement Facebook AI Research) et d'autres institutions ont mené conjointement une étude avec HuggingFace, essayant de faire fonctionner le BLOOM-176B formé sur moins de GPU, et la méthode proposée est entièrement intégrée. dans les transformateurs HuggingFace.

- Adresse papier : https://arxiv.org/pdf/2208.07339.pdf
- Adresse Github : https://github.com/timdettmers/bitsandbytes
Cette recherche est transformatrice Proposition du premier processus de quantification Int8 à l'échelle d'un milliard qui n'affecte pas les performances d'inférence du modèle. Il peut charger un transformateur de paramètres 175B avec des poids de 16 ou 32 bits et convertir les couches de projection d'anticipation et d'attention en 8 bits. Il réduit de moitié la mémoire requise pour l’inférence tout en conservant des performances de précision totale.
L'étude a nommé la combinaison de la quantification vectorielle et de la décomposition de précision mixte LLM.int8(). Les expériences montrent qu'en utilisant LLM.int8(), il est possible d'effectuer une inférence avec un LLM comportant jusqu'à 175 B de paramètres sur un GPU grand public sans dégradation des performances. Cette approche apporte non seulement un nouvel éclairage sur l'impact des valeurs aberrantes sur les performances des modèles, mais permet également pour la première fois d'utiliser de très grands modèles, tels que l'OPT-175B/BLOOM, sur un seul serveur doté de GPU grand public.
Introduction à la méthode
La taille du modèle d'apprentissage automatique dépend du nombre de paramètres et de leur précision, généralement celle de float32, float16 ou bfloat16. float32 (FP32) signifie représentation à virgule flottante standardisée IEEE 32 bits, et une large gamme de nombres à virgule flottante peut être représentée à l'aide de ce type de données. FP32 réserve 8 bits pour "l'exposant", 23 bits pour la "mantisse" et 1 bit pour le signe du nombre. De plus, la plupart du matériel prend en charge les opérations et instructions FP32.
Et float16 (FP16) réserve 5 bits pour l'exposant et 10 bits pour la mantisse. Cela rend la plage représentable des nombres FP16 bien inférieure à celle du FP32, l'exposant au risque de débordement (en essayant de représenter un très grand nombre) et de sous-débordement (représentant un très petit nombre).
En cas de débordement, vous obtiendrez un résultat NaN (pas un nombre), et si vous effectuez des calculs séquentiels comme dans les réseaux de neurones, beaucoup de travail s'effondrera. bfloat16 (BF16) évite ce problème. BF16 réserve 8 bits pour l'exposant et 7 bits pour la décimale, ce qui signifie que BF16 peut conserver la même plage dynamique que le FP32.
Idéalement, l'entraînement et l'inférence devraient être effectués en FP32, mais c'est plus lent que FP16/BF16, utilisez donc une précision mixte pour améliorer la vitesse d'entraînement. Mais en pratique, les poids demi-précision offrent également une qualité similaire à celle du FP32 lors de l’inférence. Cela signifie que nous pouvons utiliser la moitié des poids de précision et la moitié du GPU pour obtenir les mêmes résultats.
Mais et si nous pouvions utiliser différents types de données pour stocker ces poids avec moins de mémoire ? Une méthode appelée quantification a été largement utilisée en apprentissage profond.
Cette étude a d'abord utilisé une demi-précision BF16/FP16 sur 2 octets au lieu d'une précision FP32 sur 4 octets dans l'expérience, obtenant presque les mêmes résultats d'inférence. Le modèle est ainsi réduit de moitié. Mais si vous réduisez encore ce nombre, la précision diminuera et la qualité de l’inférence chutera fortement.
Pour compenser cela, cette étude introduit la quantification 8 bits. Cette méthode utilise un quart de la précision et ne nécessite donc qu'un quart de la taille du modèle, mais cela n'est pas obtenu en supprimant l'autre moitié des bits.
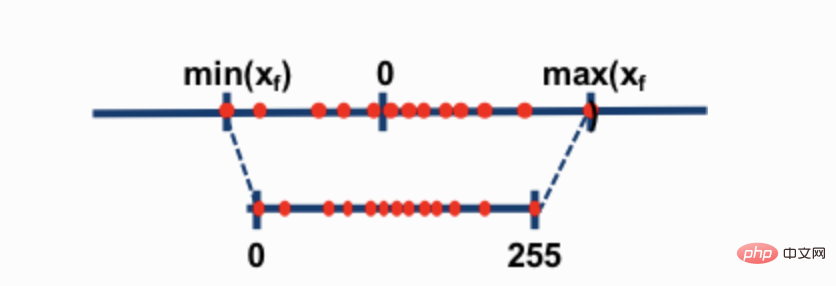
Les deux techniques de quantification 8 bits les plus courantes sont la quantification du point zéro et la quantification absmax (maximum absolu). Les deux méthodes mappent les valeurs à virgule flottante vers des valeurs int8 (1 octet) plus compactes.
Par exemple, dans la quantification du point zéro, si la plage de données est de -1,0 à 1,0 et quantifiée à -127-127, le facteur d'expansion est de 127. À ce facteur d'expansion, par exemple, une valeur de 0,3 sera étendue à 0,3*127 = 38,1. La quantification implique généralement un arrondi, ce qui nous donne 38. Si nous inversons cela, nous obtenons 38/127=0,2992 – une erreur de quantification de 0,008 dans cet exemple. Ces erreurs apparemment minimes ont tendance à s'accumuler et à croître à mesure qu'elles se propagent à travers les couches du modèle et entraînent une dégradation des performances.
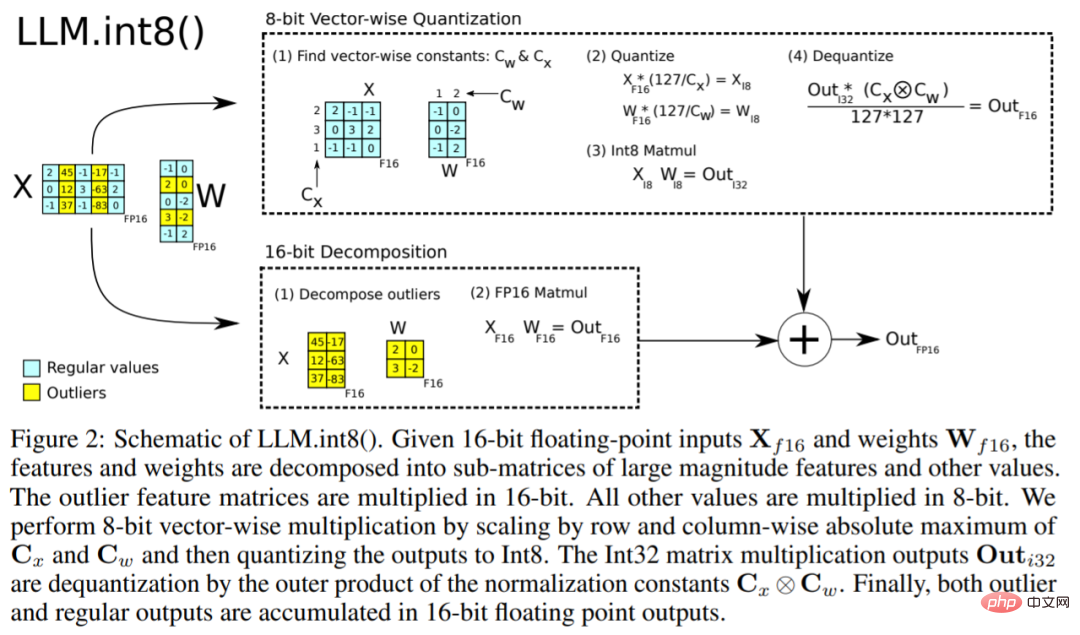
Bien que ces techniques soient capables de quantifier les modèles d'apprentissage profond, elles entraînent souvent une précision réduite des modèles. Mais LLM.int8(), intégré aux bibliothèques Hugging Face Transformers et Accelerate, est la première technique qui ne dégrade pas les performances même pour les grands modèles avec des paramètres 176B (comme BLOOM). L'algorithme
LLM.int8() peut être expliqué comme ceci. Essentiellement, LLM.int8() tente d'effectuer les calculs de multiplication matricielle en trois étapes :
- Extraire les valeurs aberrantes (c'est-à-dire supérieures à une certaine valeur) par colonne du. valeur de seuil d'état caché d'entrée).
- Multiplication matricielle des valeurs aberrantes dans FP16 et des valeurs non aberrantes dans int8.
- Déquantifiez les valeurs non aberrantes dans le FP16 et ajoutez les valeurs aberrantes et non aberrantes pour obtenir le résultat complet.
Ces étapes peuvent être résumées dans l'animation ci-dessous :

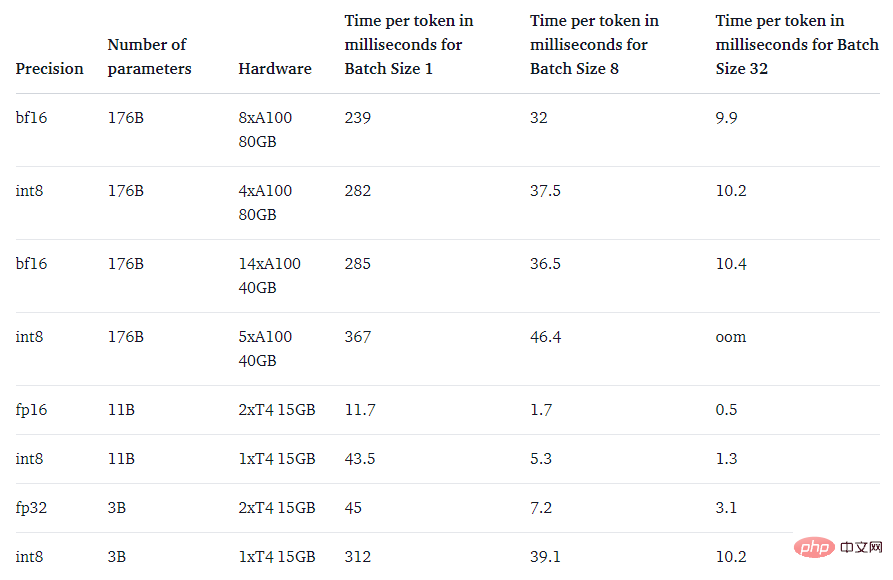
Enfin, l'étude s'est également penchée sur la question : est-il plus rapide que le modèle natif ?
L'objectif principal de la méthode LLM.int8() est de rendre les grands modèles plus accessibles sans dégrader les performances. Cependant, si c'est très lent, ce n'est pas très utile. L'équipe de recherche a comparé la vitesse de génération de plusieurs modèles et a constaté que BLOOM-176B avec LLM.int8() était environ 15 à 23 % plus lent que la version fp16, ce qui est tout à fait acceptable. Et les modèles plus petits, comme le T5-3B et le T5-11B, ont des décélérations encore plus importantes. L’équipe de recherche travaille à améliorer la vitesse de ces petits modèles.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI