
Maison >Périphériques technologiques >IA >MiniGPT-4 examine les images, les discussions et peut également dessiner et créer des sites Web ; la version vidéo de Stable Diffusion est ici ;
MiniGPT-4 examine les images, les discussions et peut également dessiner et créer des sites Web ; la version vidéo de Stable Diffusion est ici ;

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBavant
- 2023-04-28 12:10:181339parcourir
目录
- #🎜 🎜#Aligner vos latents : synthèse vidéo haute résolution avec des modèles de diffusion latente
- MiniGPT-4 : amélioration de la compréhension vision-langage grâce à de grands modèles de langage avancés
- OpenAssistant Conversations - Démocratiser l'alignement des grands modèles de langage
- Inpaint Anything : segmenter tout ce qui rencontre l'image Inpainting#🎜 🎜# Segmentation sémantique de vocabulaire ouvert avec CLIP adapté au masque
- Plan4MC : apprentissage et planification par renforcement des compétences pour les tâches Minecraft en monde ouvert
- # 🎜🎜#T2Ranking : une référence chinoise à grande échelle pour le classement des passages
- ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
作者:Andreas Blattmann 、 Robin Rombach 等
- # 🎜 🎜#论文地址:https://arxiv.org/pdf/2304.08818.pdf
- Modèle de diffusion latente, LDM辨率的长视频合成。
# 🎜🎜#在论文中,研究者将视频模型应用于真实世界问题并生成了高分辨率的长视频。他们关泳两个关的视频生成问题,一是高分辨率真实世界驾驶数据的视频合成,二是文本指导视频生成,用于创意内容生成。为此,研究者提出了视频Vidéo LDM), et LDM vidéo Vidéo LDM (或者使用可用的预训练)图像 LDM),从而允许利用大规模图像数据集。
接着将时间维度引入潜在空间 DM、并在编码图像序列(即视频)上仅训练这些时间层的同时固定预训练空间层,从而将 LDM 图像生成器转换为视频生成器(下图左)。最后以类似方式微调 LDM 的解码器以实现像素空间中的时间一致性(下图右)。
推荐:
视频版 Diffusion stable:英伟达做到最高 1280×2048、最4,7 秒。
论文 2:MiniGPT-4 : Améliorer la compréhension du langage visuel avec des modèles de langage étendus avancés
# 🎜🎜#作者:朱德尧、陈军、沈晓倩、李祥、Mohamed H. Elhoseiny
# 🎜🎜##🎜 🎜#论文地址:https://minigpt-4.github.io/- 摘要:#🎜🎜 #来自阿卜杜拉国王科技大学(KAUST)的团队上手开发了一个 GPT-4 的类似产品 ——MiniGPT-4。MiniGPT-4 展示了许Pour les applications GPT-4, les applications GPT-4 Le MiniGPT-4 est également utilisé pour le MiniGPT-4.事和诗歌,提供解决图像中显示的问题的解决方案,根据食品照片教用户如何烹饪等。
- MiniGPT-4 使用一个投影层将一个冻结的视觉编码器和一个冻结Le LLM(Vicuna)对齐。MiniGPT-4 est utilisé. ViT et Q-Former.练线性层,用来将视觉特征与 Vicuna 对齐。#🎜🎜 #
Exemple de démonstration : création d'un site Web à partir d'un croquis.

Recommandation : Près de 10 000 étoiles en 3 jours, découvrez la capacité de reconnaissance d'image GPT-4 sans aucune différence, le chat avec image MiniGPT-4 et le dessin pour créer un site Web.
Papier 3: Conversations openassistantes - Democratizer l'alignement du modèle grand langage
- auteur: Andreas Köpf, Yannic Kilcher, etc.
- Adresse de papier: https://drive.google. com/ file/d/10iR5hKwFqAKhL3umx8muOWSRm7hs5FqX/view
Résumé : Pour démocratiser la recherche sur l'alignement à grande échelle, des chercheurs d'institutions telles que LAION AI (qui fournit les données open source utilisées par Stable diffusion.) ont collecté les une grande quantité de saisies et de commentaires textuels crée OpenAssistant Conversations, un ensemble de données diversifié et unique spécialement conçu pour former des modèles de langage ou d'autres applications d'IA.
Cet ensemble de données est un corpus de conversation de type assistant généré et annoté par l'homme, couvrant un large éventail de sujets et de styles d'écriture, composé de 161 443 messages répartis dans 66 497 arbres de conversation, dans 35 langues différentes. Le corpus est le produit d’un effort mondial de crowdsourcing impliquant plus de 13 500 bénévoles. Il s'agit d'un outil inestimable pour tout développeur cherchant à créer des modèles d'instructions SOTA. Et l’ensemble des données est librement accessible à tous.
De plus, pour prouver l'efficacité de l'ensemble de données OpenAssistant Conversations, l'étude propose également un assistant basé sur le chat, OpenAssistant, qui peut comprendre les tâches, interagir avec des systèmes tiers et récupérer dynamiquement des informations. Il s’agit sans doute du premier modèle de réglage fin d’instructions à grande échelle entièrement open source et formé sur des données humaines.
Les résultats montrent que les réponses d'OpenAssistant sont plus populaires que celles de GPT-3.5-turbo (ChatGPT).
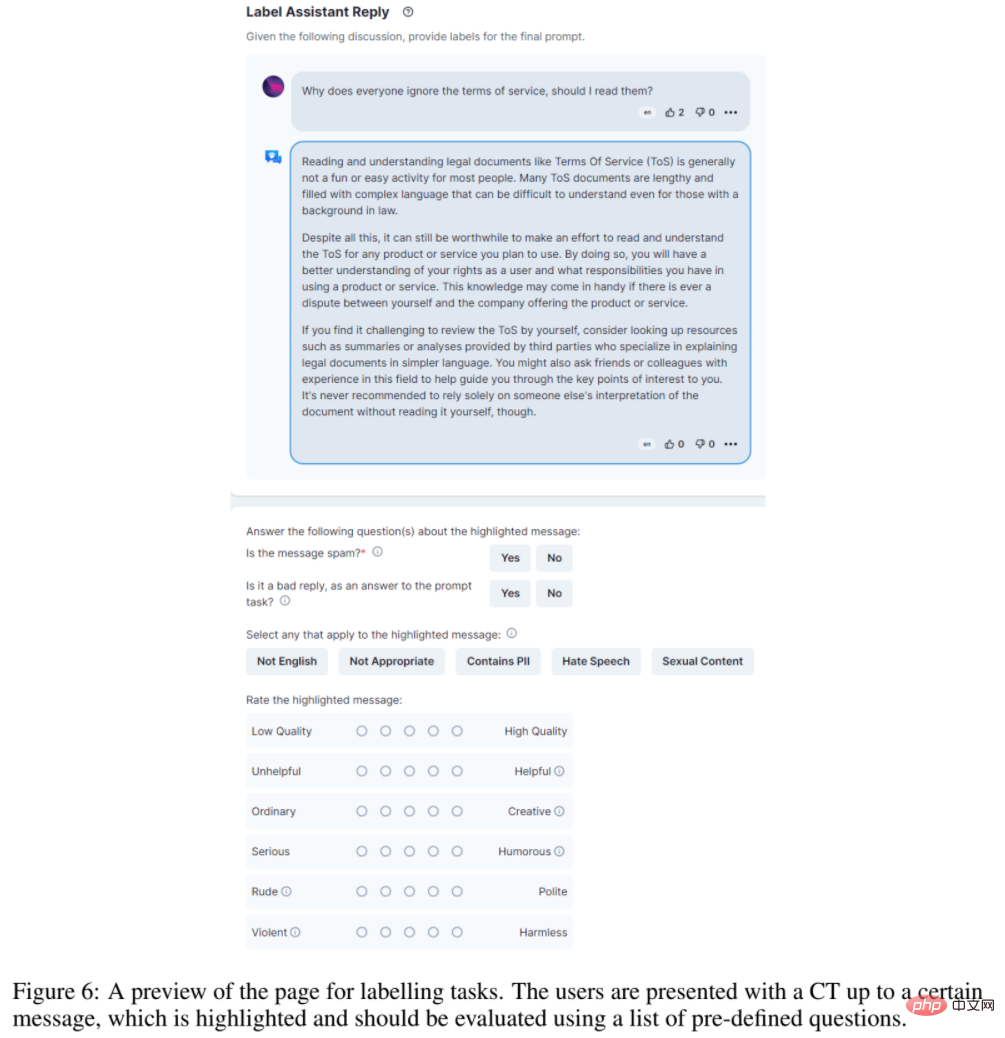
Les données des conversations OpenAssistant sont collectées à l'aide de l'interface de l'application Web et comprennent 5 étapes : inviter, marquer l'invite, ajouter un message de réponse comme prompteur ou assistant, marquer la réponse et classer la réponse de l'assistant.
Recommandé : ChatGPT, la plus grande alternative open source au monde.
Papier 4 : Inpaint Anything : Segment Anything rencontre Image Inpainting
- Auteurs : Tao Yu, Runseng Feng, etc.
- Adresse papier : http://arxiv.org/ abs/ 2304.06790
Résumé : L'équipe de recherche de l'Université des sciences et technologies de Chine et de l'Institut oriental de technologie a proposé le modèle « Inpaint Anything » (IA) basé sur SAM (Segment Anything Model). Différent des modèles de réparation d'images traditionnels, le modèle IA ne nécessite pas d'opérations détaillées pour générer des masques et prend en charge le marquage des objets sélectionnés en un seul clic. IA peut tout supprimer (Supprimer n'importe quoi), tout remplir (Remplir n'importe quoi) et tout remplacer (Remplacer). Anything) couvre une variété de scénarios d'application typiques de réparation d'images, notamment la suppression de cible, le remplissage de cible, le remplacement d'arrière-plan, etc.
IA a trois fonctions principales : (i) Supprimer n'importe quoi : les utilisateurs n'ont qu'à cliquer sur l'objet qu'ils souhaitent supprimer, et IA supprimera l'objet sans laisser de trace, obtenant ainsi une "élimination magique" efficace (ii) Remplir n'importe quoi ; : Dans le même temps, l'utilisateur peut en outre indiquer à IA ce qu'il souhaite remplir dans l'objet via des invites de texte (Text Prompt), et IA pilotera ensuite le modèle AIGC (AI-Generated Content) intégré (tel que Stable Diffusion [2 ]) génère les objets remplis de contenu correspondants pour réaliser la « création de contenu » à volonté ; (iii) Remplacer n'importe quoi : l'utilisateur peut également cliquer pour sélectionner les objets qui doivent être conservés et utiliser des invites textuelles pour indiquer à IA qu'il souhaite les remplacer. les objets Vous pouvez remplacer l'arrière-plan de l'objet par le contenu spécifié pour obtenir une "transformation d'environnement" vivante. Le cadre global de l'IA est présenté dans la figure ci-dessous :
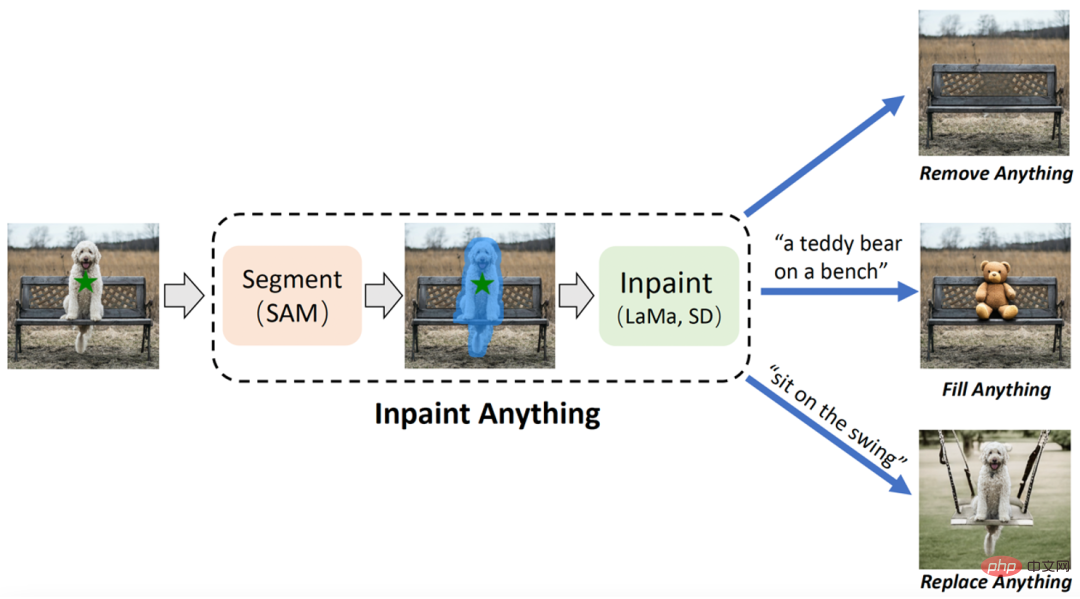
Recommandation : Pas besoin de marquage fin, cliquez sur l'objet pour réaliser la suppression de l'objet, le remplissage du contenu et le remplacement de la scène.
Papier 5 : Segmentation sémantique à vocabulaire ouvert avec CLIP adapté au masque
- Auteurs : Feng Liang, Bichen Wu, etc.
- Adresse du papier : https://arxiv. org/ pdf/2210.04150.pdf
Résumé : Meta et UTAustin ont proposé conjointement un nouveau modèle de style de langage ouvert (segmentation à vocabulaire ouvert, OVSeg), qui permet au modèle Segment Anything de connaître les catégories à séparer .
Du point de vue des effets, OVSeg peut être combiné avec Segment Anything pour compléter une segmentation fine du langage ouvert. Par exemple, dans la figure 1 ci-dessous, identifiez les types de fleurs : tournesols, roses blanches, chrysanthèmes, œillets, dianthus vert.

Recommandé : Meta/UTAustin propose un nouveau modèle de segmentation de classe ouverte.
Papier 6 : Plan4MC : Apprentissage par renforcement des compétences et planification pour les tâches Minecraft en monde ouvert
- Auteurs : Haoqi Yuan, Chi Zhang, etc.
- Adresse papier : https:// /arxiv .org/abs/2303.16563
Résumé : Une équipe de l'Université de Pékin et de l'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin a proposé Plan4MC, une méthode pour résoudre efficacement le multitâche de Minecraft sans données d'experts. L'auteur combine des méthodes d'apprentissage par renforcement et de planification pour décomposer la résolution de tâches complexes en deux parties : l'apprentissage des compétences de base et la planification des compétences. Les auteurs utilisent des méthodes d’apprentissage par renforcement par récompense intrinsèque pour former trois types de compétences de base fines. L'agent utilise un grand modèle de langage pour créer un graphique de relations de compétences et obtient une planification des tâches grâce à une recherche sur le graphique. Dans la partie expérimentale, Plan4MC peut actuellement effectuer 24 tâches complexes et diverses, et le taux de réussite a été considérablement amélioré par rapport à toutes les méthodes de base.

Recommandé : Utilisez ChatGPT et l'apprentissage par renforcement pour jouer à "Minecraft", Plan4MC surmonte 24 tâches complexes.
Article 7 : T2Ranking : Une référence chinoise à grande échelle pour le classement des passages
- Auteurs : Xiaohui Xie, Qian Dong, etc. un très important problème dans le domaine de la recherche d'informations Il s'agit d'un sujet important et stimulant qui a reçu une large attention de la part du monde universitaire et de l'industrie. L'efficacité du modèle de classement des paragraphes peut améliorer la satisfaction des utilisateurs des moteurs de recherche et aider les applications liées à la recherche d'informations telles que les systèmes de questions et réponses, la compréhension écrite, etc. Dans ce contexte, certains ensembles de données de référence tels que MS-MARCO, DuReader_retrieval, etc. ont été construits pour soutenir les travaux de recherche connexes sur le tri des paragraphes. Cependant, la plupart des ensembles de données couramment utilisés se concentrent sur les scènes anglaises. Pour les scènes chinoises, les ensembles de données existants présentent des limites en termes d'échelle de données, d'annotation fine par l'utilisateur et de solution au problème des exemples faux négatifs. Dans ce contexte, cette étude a construit un nouvel ensemble de données de référence pour le classement des paragraphes chinois, basé sur des journaux de recherche réels : T2Ranking.
- T2Ranking se compose de plus de 300 000 requêtes réelles et de 2 millions de paragraphes Internet, et contient des annotations de pertinence fines à 4 niveaux fournies par des annotateurs professionnels. Les données actuelles et certains modèles de base ont été publiés sur Github, et les travaux de recherche pertinents ont été acceptés par SIGIR 2023 en tant que document ressource. Recommandé :
ArXiv Weekly Radiostation
Heart of Machine coopère avec ArXiv Weekly Radiostation initiée par Chu Hang, Luo Ruotian et Mei Hongyuan, et sélectionne des articles plus importants cette semaine sur la base de 7 articles, dont NLP, CV, ML 10 articles sélectionnés dans chaque domaine, et des introductions abstraites des articles sous forme audio sont fournies. Les détails sont les suivants :
Les 10 articles PNL sélectionnés cette semaine sont :
1. par HLTPR@RWTH pour DSTC9 et DSTC10 (de Hermann Ney)2 Explorer les compromis : modèles de langage étendus unifiés et modèles locaux affinés pour la tâche NLI de radiologie hautement spécifique (de Wei Liu, Dinggang. Shen )
3. Sur la robustesse de l'analyse des sentiments basée sur les aspects : repenser le modèle, les données et la formation (de Tat-Seng Chua)
4. Affiner et difficile à détecter avec d'autres LLM (de Rachid Guerraoui)5. Chameleon : Raisonnement compositionnel Plug-and-Play avec de grands modèles de langage (de Kai-Wei Chang, Song-Chun Zhu, Jianfeng Gao. )
6. MER 2023 : Apprentissage multi-étiquettes, robustesse des modalités et apprentissage semi-supervisé (de Meng Wang, Erik Cambria, Guoying Zhao)
7. API Web. (de Zhiyong Lu)
8. Une enquête sur la synthèse de textes biomédicaux avec un modèle de langage pré-entraîné (de Sophia Ananiadou)
10. Lakes. (de Christopher Ré)
Les 10 articles sélectionnés par CV de cette semaine sont :
1. NeuralField-LDM : Génération de scènes avec des modèles de diffusion latente hiérarchique (d'Antonio Torralba)
2. Align-DETR : Amélioration du DETR avec une perte de BCE simple prenant en compte l'IoU (de Xiangyu Zhang)
3. Exploration du transfert de connaissances incompatible dans la génération d'images à quelques prises de vue. 4. Hyper-graphiques de situation d’apprentissage pour la réponse aux questions vidéo. (de Moubarak Shah) 5. Génération vidéo au-delà d’un seul clip. (de Ming-Hsuan Yang) 6. Une solution centrée sur les données pour le désembuage non homogène via Vision Transformer. (de Huan Liu) 7. Flux optique neuromorphique et mise en œuvre en temps réel avec des caméras événementielles. (de Luca Benini, Davide Scaramuzza) 8. Infiltration locale guidée par le langage pour la récupération d'images interactives. (de Lei Zhang) 9. LipsFormer : Présentation de la continuité Lipschitz aux transformateurs de vision. (de Lei Zhang) 10. UVA : Vers un avatar volumétrique unifié pour la synthèse de vues, le rendu de pose, l'édition de géométrie et de texture. (de Dacheng Tao) 本周 10 篇 ML 精选论文是: 1. Relier la théorie et la pratique du RL avec l'horizon efficace. (de Stuart Russell) 2. Vers des modèles de courbes de puissance des éoliennes transparents et robustes basés sur des données. (de Klaus-Robert Müller) 3. Apprentissage continu en monde ouvert : unifier la détection des nouveautés et l'apprentissage continu. (de Bing Liu) 4. L'apprentissage dans les espaces latents améliore la précision prédictive des opérateurs neuronaux profonds. (de George Em Karniadakis) 5. Découpler les réseaux de neurones graphiques : former plusieurs GNN simples simultanément au lieu d'un. (de Xuelong Li) 6. Limites d'erreur de généralisation et d'estimation pour les réseaux de neurones basés sur un modèle. (de Yonina C. Eldar) 7. RAFT : récompense le FineTuning classé pour l'alignement du modèle de base génératif. (de Tong Zhang) 8. Méthode d'optimisation adaptative du consensus pour les GAN. (de Pawan Kumar) 9. Taux d'apprentissage dynamique basé sur l'angle pour la descente de gradient. (de Pawan Kumar) 10. AGNN : réseaux de neurones alternés à régularisation graphique pour atténuer le lissage excessif. (de Wenzhong Guo)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Tendances technologiques à surveiller en 2023
- Comment l'intelligence artificielle apporte un nouveau travail quotidien aux équipes des centres de données
- L'intelligence artificielle ou l'automatisation peuvent-elles résoudre le problème de la faible efficacité énergétique des bâtiments ?
- Co-fondateur d'OpenAI interviewé par Huang Renxun : les capacités de raisonnement de GPT-4 n'ont pas encore atteint les attentes
- Bing de Microsoft surpasse Google en termes de trafic de recherche grâce à la technologie OpenAI