
Maison >interface Web >js tutoriel >Un article pour parler du contrôle de la mémoire dans Node
Un article pour parler du contrôle de la mémoire dans Node

- 青灯夜游avant
- 2023-04-26 17:37:052623parcourir
Le service Node est construit sur une base non bloquante et piloté par les événements. Il présente l'avantage d'une faible consommation de mémoire et est très adapté à la gestion de requêtes réseau massives. Dans le contexte de demandes massives, les questions liées au « contrôle de la mémoire » doivent être prises en compte.

1. Mécanisme de récupération de place et limitations de mémoire de la V8
Js utilise un mécanisme de récupération de place pour effectuer une gestion automatique de la mémoire. Les développeurs n'ont pas besoin de prêter attention à la mémoire pendant le processus d'écriture de code comme les autres langages. (c/c++) problèmes d’allocation et de version. Dans les navigateurs, le mécanisme de garbage collection a peu d'impact sur les performances des applications, mais pour les programmes côté serveur sensibles aux performances, la qualité de la gestion de la mémoire et la qualité du garbage collection auront un impact sur les services. [Recommandations de didacticiels connexes : Tutoriel vidéo Nodejs, Enseignement de la programmation]
1.1 Node et V8
Node est une plate-forme construite sur le runtime Js de Chrome, et V8 est le moteur de script Js de Node
1.2 Limitations de mémoire V8
Dans langages back-end généraux, il n'y a aucune restriction sur l'utilisation de base de la mémoire, mais lors de l'utilisation de la mémoire via Js dans Node, seule une partie de la mémoire peut être utilisée. Sous de telles restrictions, Node ne peut pas exploiter directement des objets de mémoire volumineux.
La principale raison du problème est que Node est construit sur la base de V8 et que les objets Js utilisés dans Node sont essentiellement alloués et gérés via la propre méthode de V8.
1.3 Allocation d'objets V8
Dans la V8, tous les objets Js sont alloués via le tas.
Vérifiez l'utilisation de la mémoire dans la v8
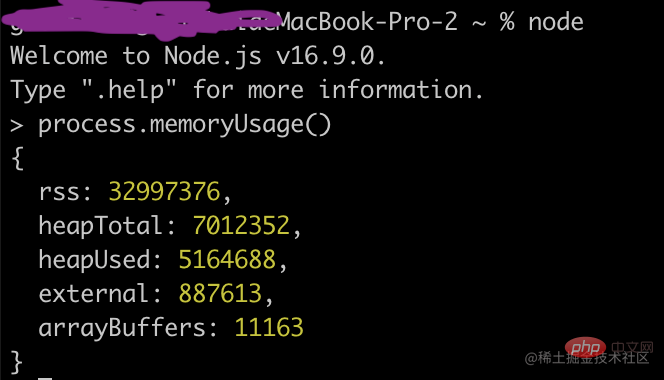
heapTotal et heapUsed sont l'utilisation de la mémoire tas de la V8. Le premier est la mémoire tas qui a été demandée et le second est la quantité actuellement utilisée.
Lorsque vous déclarez une variable dans le code et attribuez une valeur, la mémoire de l'objet utilisé est allouée dans le tas. Si la mémoire libre du tas appliquée n'est pas suffisante pour allouer de nouveaux objets, la mémoire du tas continuera à être appliquée jusqu'à ce que la taille du tas dépasse la limite du V8
Pourquoi le V8 limite-t-il la taille du tas La raison superficielle est que le V8 a été initialement conçu pour ? navigateurs. Il est très probable que vous rencontriez des scénarios qui utilisent beaucoup de mémoire. Pour les pages Web, la valeur limite du V8 est largement suffisante. La raison sous-jacente est la limitation du mécanisme de récupération de place de V8. Selon la déclaration officielle, en prenant comme exemple 1,5 Go de mémoire de tas de garbage collection, la v8 prend plus de 50 millisecondes pour effectuer un petit garbage collection, et prend même plus d'une seconde pour effectuer un garbage collection non incrémentiel. C'est le moment pendant le garbage collection qui provoque la suspension de l'exécution du thread JS, et les performances et la réactivité de l'application chuteront. Limiter directement la mémoire du tas est un bon choix dans les considérations actuelles.
Cette limite peut être assouplie. Lorsque Node démarre, vous pouvez passer --max-old-space-size或--max-new-space-size pour ajuster la taille de la limite de mémoire. Une fois qu'elle prend effet, elle ne peut pas être modifiée dynamiquement. Par exemple :
node --max-old-space-size=1700 test.js // 单位为MB // 或者 node --max-new-space-size=1024 test.js // 单位为KB
1.4 Mécanisme de collecte des déchets de la V8
Divers algorithmes de collecte des déchets utilisés dans la v8
1.4.1 L'algorithme principal de collecte des déchets de la V8
La stratégie de collecte des déchets de la v8 est principalement basée sur le mécanisme de collecte des déchets générationnel.
Dans les applications réelles, le cycle de vie des objets varie. Dans l'algorithme actuel de garbage collection, le garbage collection de mémoire est effectué dans différentes générations en fonction du temps de survie de l'objet, et un algorithme plus efficace est appliqué à la mémoire des différentes générations.
-
Génération mémoire V8
En v8, la mémoire est principalement divisée en deux générations : la nouvelle génération et l'ancienne génération. Les objets de la jeune génération sont des objets avec une durée de survie courte, tandis que les objets de l'ancienne génération sont des objets avec une durée de survie longue ou résident en mémoire.
L'espace mémoire de la nouvelle génération L'espace mémoire de l'ancienne génération La taille globale du tas v8 = l'espace mémoire utilisé par la nouvelle génération + l'espace mémoire de l'ancienne génération
La valeur maximale de la mémoire du tas v8 ne peut utiliser qu'environ 1,4 Go de mémoire sous les systèmes 64 bits et sous 32 Seuls environ 0,7 Go de mémoire peuvent être utilisés sous le système. L'algorithme Scavenge effectue le garbage collection. L'implémentation spécifique de Scavenge utilise principalement l'algorithme de Cheney. L'algorithme de Cheney est un algorithme de garbage collection implémenté par copie. Divisez la mémoire tas en deux parties, et chaque partie de l'espace est appelée semi-espace. Parmi les deux semi-espaces, un seul est utilisé et l’autre est inactif. L'espace semi-espace utilisé est appelé Depuis l'espace, et l'espace en état d'inactivité est appelé Vers l'espace. Lors de l'allocation d'un objet, il est d'abord alloué dans l'espace De. Lorsque le garbage collection commence, les objets survivants dans l'espace From seront vérifiés. Ces objets survivants seront copiés dans l'espace To et l'espace occupé par les objets non survivants sera libéré. Une fois la copie terminée, les rôles de l'espace From et To space sont inversés. En bref, lors du processus de garbage collection, les objets survivants sont copiés entre deux semi-espaces. L'inconvénient de Scavenge est qu'il ne peut utiliser que la moitié de la mémoire tas, qui est déterminée par l'espace de partitionnement et le mécanisme de copie. Cependant, Scavenge a d'excellentes performances en termes d'efficacité temporelle car il ne copie que les objets survivants, et seule une petite partie des objets survivants est utilisée dans des scénarios avec des cycles de vie courts. Puisque Scavenge est un algorithme typique qui sacrifie l’espace au profit du temps, il ne peut pas être appliqué à toutes les collectes de déchets à grande échelle. Mais Scavenge est très approprié pour une application dans la nouvelle génération, car le cycle de vie des objets de la nouvelle génération est court et adapté à cet algorithme.
La mémoire tas réelle utilisée est la somme des deux espaces semi-espaces dans la nouvelle génération et de la taille de la mémoire utilisée dans l'ancienne génération. -
Lorsqu'un objet survit encore après plusieurs copies, il sera considéré comme un objet avec un long cycle de vie et sera déplacé vers l'ancienne génération à l'aide d'un nouvel algorithme. gérer. Le processus de déplacement d'objets de la jeune génération vers l'ancienne génération est appelé promotion.
 Dans le processus simple de Scavenge, les objets survivants dans l'espace From seront copiés dans l'espace To, puis les rôles de l'espace From et de l'espace To seront inversés (inversion). Cependant, dans le cadre d'un garbage collection générationnel, les objets survivants dans l'espace From doivent être vérifiés avant d'être copiés dans l'espace To. Dans certaines conditions, les objets ayant une longue période de survie doivent être déplacés vers l'ancienne génération, c'est-à-dire que la promotion de l'objet est terminée. Il existe deux conditions principales pour la promotion d'un objet. L'une est de savoir si l'objet a subi un recyclage Scavenge, et l'autre est que le taux d'utilisation de la mémoire de l'espace To dépasse la limite.
Dans le processus simple de Scavenge, les objets survivants dans l'espace From seront copiés dans l'espace To, puis les rôles de l'espace From et de l'espace To seront inversés (inversion). Cependant, dans le cadre d'un garbage collection générationnel, les objets survivants dans l'espace From doivent être vérifiés avant d'être copiés dans l'espace To. Dans certaines conditions, les objets ayant une longue période de survie doivent être déplacés vers l'ancienne génération, c'est-à-dire que la promotion de l'objet est terminée. Il existe deux conditions principales pour la promotion d'un objet. L'une est de savoir si l'objet a subi un recyclage Scavenge, et l'autre est que le taux d'utilisation de la mémoire de l'espace To dépasse la limite.
Par défaut, l'allocation d'objets de V8 est principalement concentrée dans l'espace From. Lorsqu'un objet est copié de l'espace From vers l'espace To, son adresse mémoire sera vérifiée pour déterminer si l'objet a subi un recyclage Scavenge. S'il a été expérimenté, l'objet sera copié de l'espace From vers l'espace ancienne génération. Dans le cas contraire, il sera copié vers l'espace To. L'organigramme de la promotion est le suivant :
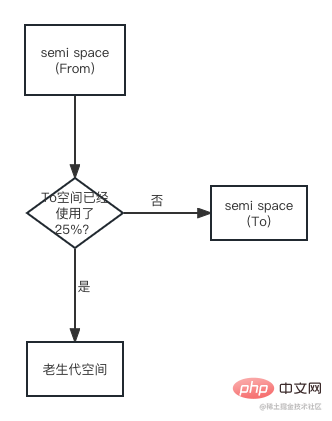
Une autre condition de jugement est le taux d'utilisation de la mémoire de l'espace. Lors de la copie d'un objet de l'espace From vers l'espace To, si l'espace To a été utilisé à 25%, l'objet sera directement promu vers l'espace ancienne génération. L'organigramme de promotion est le suivant :#🎜🎜. #
#🎜 🎜#La raison de la fixation de la limite de 25% : Lorsque ce recyclage Scavenge sera terminé, cet espace Vers deviendra De l'espace, et la prochaine allocation mémoire sera effectuée dans cet espace. Si le ratio est trop élevé, cela affectera l’allocation de mémoire ultérieure. 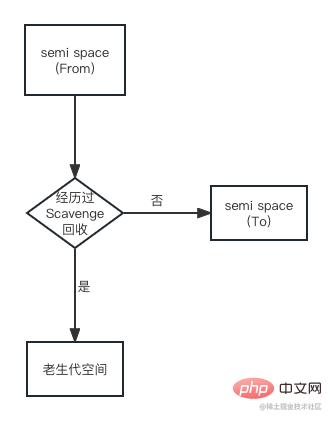
 Mark-Sweep & Mark-Compact
Mark-Sweep & Mark-Compact
Pour les objets de l'ancienne génération, puisque les objets survivants représentent une grande proportion, si Scavenge est Utilisé Il y a deux problèmes avec cette méthode : l'un est qu'il y a de nombreux objets survivants et l'efficacité de la copie des objets survivants sera très faible ; l'autre problème est que la moitié de l'espace est gaspillée. À cette fin, la v8 utilise principalement une combinaison de Mark-Sweep et Mark-Compact pour le garbage collection de l'ancienne génération.
Mark-Sweep signifie nettoyage des marques, qui se divise en deux étapes : le marquage et le nettoyage. Comparé à Scavenge, Mark-Sweep ne divise pas l'espace mémoire en deux moitiés, il n'y a donc pas de comportement de gaspillage de la moitié de l'espace. Contrairement à Scavenge, qui copie les objets vivants, Mark-Sweep parcourt tous les objets du tas pendant la phase de marquage et marque les objets vivants lors de la phase de nettoyage suivante, seuls les objets non marqués sont effacés. On peut constater que Scavenge copie uniquement les objets vivants, tandis que Mark-Sweep nettoie uniquement les objets morts. Les objets vivants ne représentent qu'une plus petite partie de la nouvelle génération, et les objets morts ne représentent qu'une plus petite partie de l'ancienne génération. C'est pourquoi les deux méthodes de recyclage peuvent la gérer efficacement. Le schéma schématique du marquage Mark-Sweep dans l'espace ancienne génération est le suivant La partie noire est marquée comme objet mort
.
Le plus gros problème avec Mark-Sweep est qu'après avoir marqué et vidé l'espace, l'espace mémoire deviendra discontinu. Ce type de fragmentation de la mémoire entraînera des problèmes d'allocation de mémoire ultérieure. Lorsqu'un objet volumineux doit être alloué, tout l'espace fragmenté ne pourra pas terminer l'allocation, et le garbage collection sera déclenché à l'avance, et ce recyclage n'est pas nécessaire.
Mark-Compact vise à résoudre le problème de fragmentation de la mémoire de Mark-Sweep. Mark-Compact signifie compilation de marques, issue de Mark-Sweep. La différence est qu'une fois l'objet marqué comme mort, pendant le processus de nettoyage, les objets vivants sont déplacés vers une extrémité. Une fois le mouvement terminé, la mémoire en dehors de la limite est directement effacée. Diagramme schématique après marquage et déplacement des objets vivants. La grille blanche est l'objet vivant, la grille sombre est l'objet mort et la grille lumineuse est le trou laissé après le déplacement de l'objet vivant.
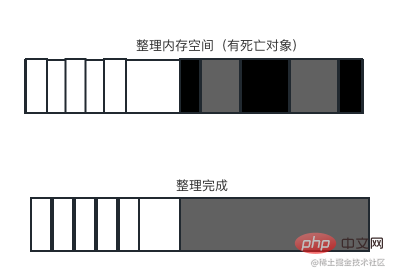
Après avoir terminé le déplacement, vous pouvez directement effacer la zone mémoire derrière l'objet survivant le plus à droite pour terminer le recyclage.
Dans la stratégie de recyclage du V8, Mark-Sweep et Mark-Compact sont utilisés en combinaison.
Une comparaison simple de 3 principaux algorithmes de collecte des déchets
| Algorithme de recyclage | Mark-Sweep | Mark-Compact | Scavenge |
|---|---|---|---|
| Speed | Medium | Le plus lent | le plus rapide |
| Average d'espace | moins (avec fragmentation) | Moins (pas de fragmentation) | Double espace (pas de fragmentation) |
| Que vous deviez déplacer des objets | Non | OUI | OUI |
由于Mark-Compact需要移动对象,所以它的执行速度不可能很快,所以在取舍上,v8主要使用Mark-Sweep,在空间不足以对从新生代中晋升过来的对象进行分配时才使用Mark-Compact
-
Incremental Marking
为了避免出现Js应用逻辑与垃圾回收器看到的不一致情况,垃圾回收的3种基本算法都需要将应用逻辑暂停下来,待执行完垃圾回收后再恢复执行应用逻辑,这种行为称为“全停顿”(stop-the-world).在v8的分代式垃圾回收中,一次小垃圾回收只收集新生代,由于新生代默认配置得较小,且其中存活对象通常较少,所以即便它是全停顿的影响也不大。但v8的老生代通常配置得较大,且存活对象较多,全堆垃圾回收(full垃圾回收)的标记、清理、整理等动作造成的停顿就会比较可怕,需要设法改善
为了降低全堆垃圾回收带来的停顿时间,v8先从标记阶段入手,将原本要一口气停顿完成的动作改为增量标记(incremental marking),也就是拆分为许多小“步进”,每做完一“步进”,就让Js应用逻辑执行一小会儿,垃圾回收与应用逻辑交替执行直到标记阶段完成。下图为:增量标记示意图
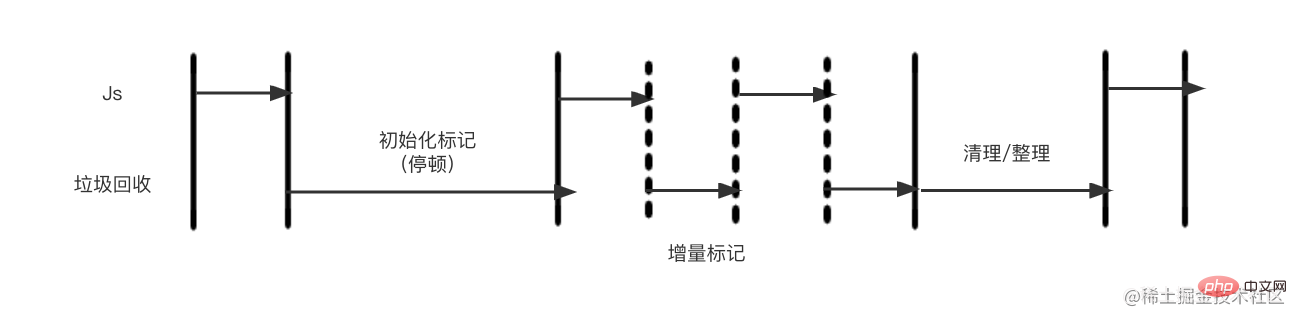
v8在经过增量标记的改进后,垃圾回收的最大停顿时间可以减少到原本的1/6左右。 v8后续还引入了延迟清理(lazy sweeping)与增量式整理(incremental compaction),让清理与整理动作也变成增量式的。同时还计划引入标记与并行清理,进一步利用多核性能降低每次停顿的时间。
1.5 查看垃圾回收的日志
在启动时添加--trace_gc参数。在进行垃圾回收时,将会从标准输出中打印垃圾回收的日志信息。
node --trace_gc -e "var a = [];for (var i = 0; i < 1000000; i++) a.push(new Array(100));" > gc.log

在Node启动时使用--prof参数,可以得到v8执行时的性能分析数据,包含了垃圾回收执行时占用的时间。以下面的代码为例
// test.js
for (var i = 0; i < 1000000; i++) {
var a = {};
}
node --prof test.js会生成一个v8.log日志文件
2. 高效使用内存
如何让垃圾回收机制更高效地工作
2.1 作用域(scope)
在js中能形成作用域的有函数调用、with以及全局作用域
如下代码:
var foo = function(){
var local = {};
}foo()函数在每次被调用时会创建对应的作用域,函数执行结束后,该作用域会被销毁。同时作用域中声明的局部变量分配在该作用域上,随作用域的销毁而销毁。只被局部变量引用的对象存活周期较短。在这个示例中,由于对象非常小,将会被分配在新生代中的From空间中。在作用域释放后,局部变量local失效,其引用的对象将会在下次垃圾回收时被释放
2.1.1 标识符查找
标识符,可以理解为变量名。下面的代码,执行bar()函数时,将会遇到local变量
var bar = function(){
console.log(local);
}js执行时会查找该变量定义在哪里。先查找的是当前作用域,如果在当前作用域无法找到该变量的声明,会向上级的作用域里查找,直到查到为止。
2.1.2作用域链
在下面的代码中
var foo = function(){
var local = 'local var';
var bar = function(){
var local = 'another var';
var baz = function(){
console.log(local)
};
baz()
}
bar()
}
foo()baz()函数中访问local变量时,由于作用域中的变量列表中没有local,所以会向上一个作用域中查找,接着会在bar()函数执行得到的变量列表中找到了一个local变量的定义,于是使用它。尽管在再上一层的作用域中也存在local的定义,但是不会继续查找了。如果查找一个不存在的变量,将会一直沿着作用域链查找到全局作用域,最后抛出未定义错误。
2.1.3 变量的主动释放
如果变量是全局变量(不通过var声明或定义在global变量上),由于全局作用域需要直到进程退出才能释放,此时将导致引用的对象常驻内存(常驻在老生代中)。如果需要释放常驻内存的对象,可以通过delete操作来删除引用关系。或者将变量重新赋值,让旧的对象脱离引用关系。在接下来的老生代内存清除和整理的过程中,会被回收释放。示例代码如下:
global.foo = "I am global object" console.log(global.foo);// => "I am global object" delete global.foo; // 或者重新赋值 global.foo = undefined; console.log(global.foo); // => undefined
虽然delete操作和重新赋值具有相同的效果,但是在V8中通过delete删除对象的属性有可能干扰v8的优化,所以通过赋值方式解除引用更好。
2.2 闭包
作用域链上的对象访问只能向上,外部无法向内部访问。
js实现外部作用域访问内部作用域中变量的方法叫做闭包。得益于高阶函数的特性:函数可以作为参数或者返回值。
var foo = function(){
var bar = function(){
var local = "局部变量";
return function(){
return local;
}
}
var baz = bar()
console.log(baz())
}在bar()函数执行完成后,局部变量local将会随着作用域的销毁而被回收。但是这里返回值是一个匿名函数,且这个函数中具备了访问local的条件。虽然在后续的执行中,在外部作用域中还是无法直接访问local,但是若要访问它,只要通过这个中间函数稍作周转即可。
闭包是js的高级特性,利用它可以产生很多巧妙的效果。它的问题在于,一旦有变量引用这个中间函数,这个中间函数将不会释放,同时也会使原始的作用域不会得到释放,作用域中产生的内存占用也不会得到释放。
无法立即回收的内存有闭包和全局变量引用这两种情况。由于v8的内存限制,要注意此变量是否无限制地增加,会导致老生代中的对象增多。
3.内存指标
会存在一些认为会回收但是却没有被回收的对象,会导致内存占用无限增长。一旦增长达到v8的内存限制,将会得到内存溢出错误,进而导致进程退出。
3.1 查看内存使用情况
process.memoryUsage()可以查看内存使用情况。除此之外,os模块中的totalmem()和freemem()方法也可以查看内存使用情况
3.1.1 查看进程的内存使用
调用process.memoryUsage()可以看到Node进程的内存占用情况
rss是resident set size的缩写,即进程的常驻内存部分。进程的内存总共有几部分,一部分是rss,其余部分在交换区(swap)或者文件系统(filesystem)中。
除了rss外,heapTotal和heapUsed对应的是v8的堆内存信息。heapTotal是堆中总共申请的内存量,heapUsed表示目前堆中使用中的内存量。单位都是字节。示例如下:
var showMem = function () {
var mem = process.memoryUsage()
var format = function (bytes) {
return (bytes / 1024 / 1024).toFixed(2) + 'MB';
}
console.log('Process: heapTotal ' + format(mem.heapTotal) +
' heapUsed ' + format(mem.heapUsed) + ' rss ' + format(mem.rss))
console.log('---------------------')
}
var useMem = function () {
var size = 50 * 1024 * 1024;
var arr = new Array(size);
for (var i = 0; i < size; i++) {
arr[i] = 0
}
return arr
}
var total = []
for (var j = 0; j < 15; j++) {
showMem();
total.push(useMem())
}
showMem();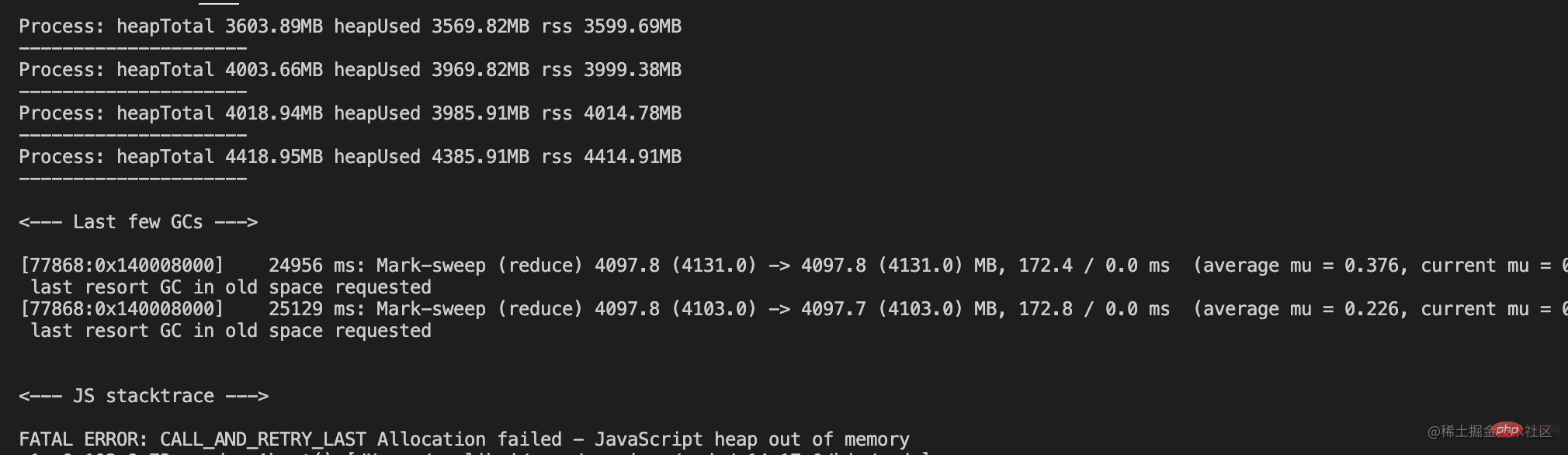
在内存达到最大限制值的时候,无法继续分配内存,然后进程内存溢出了。
3.1.2 查看系统的内存占用
os模块中的totalmem()和freemem()这两个方法用于查看操作系统的内存使用情况,分别返回系统的总内存和闲置内存,以字节为单位

3.2 堆外内存
通过process.memoryUsage()的结果可以看到,堆中的内存用量总是小于进程的常驻内存用量,意味着Node中的内存使用并非都是通过v8进行分配的。将那些不是通过v8分配的内存称为堆外内存
将上面的代码里的Array变为Buffer,将size变大
var useMem = function () {
var size = 200 * 1024 * 1024;
var buffer = Buffer.alloc(size); // new Buffer(size)是旧语法
for (var i = 0; i < size; i++) {
buffer[i] = 0
}
return buffer
}输出结果如下:
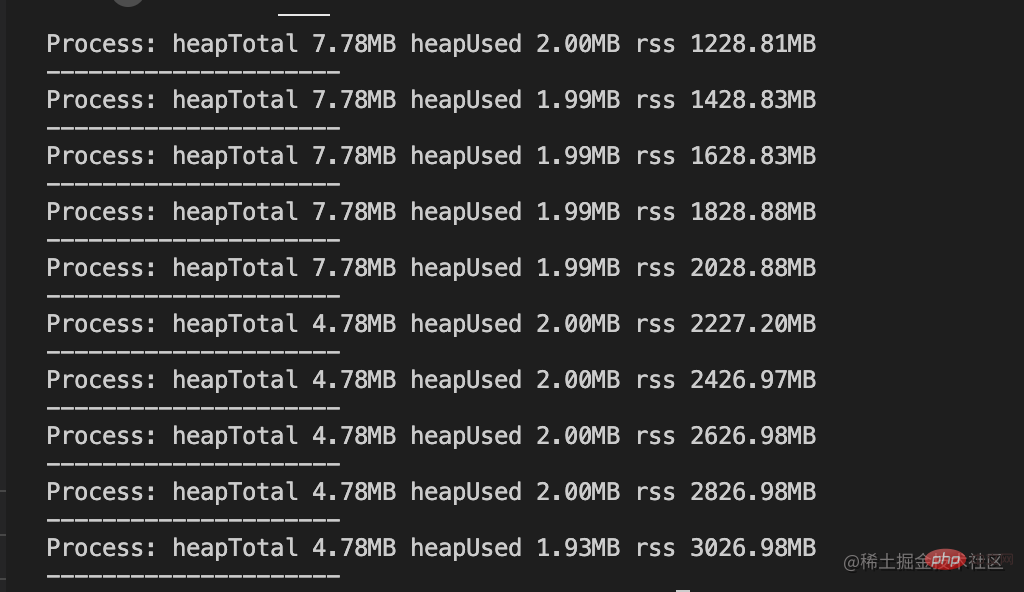
内存没有溢出,改造后的输出结果中,heapTotal与heapUsed的变化极小,唯一变化的是rss的值,并且该值已经远远超过v8的限制值。原因是Buffer对象不同于其它对象,它不经过v8的内存分配机制,所以也不会有堆内存的大小限制。意味着利用堆外内存可以突破内存限制的问题
Node的内存主要由通过v8进行分配的部分和Node自行分配的部分构成。受v8的垃圾回收限制的只要是v8的堆内存。
4. 内存泄漏
Node对内存泄漏十分敏感,内存泄漏造成的堆积,垃圾回收过程中会耗费更多的时间进行对象扫描,应用响应缓慢,直到进程内存溢出,应用崩溃。
在v8的垃圾回收机制下,大部分情况是不会出现内存泄漏的,但是内存泄漏通常产生于无意间,排查困难。内存泄漏的情况不尽相同,但本质只有一个,那就是应当回收的对象出现意外而没有被回收,变成了常驻在老生代中的对象。通常原因有如下几个:
- 缓存
- 队列消费不及时
- 作用域未释放
4.1 慎将内存当缓存用
缓存在应用中的作用十分重要,可以十分有效地节省资源。因为它的访问效率要比 I/O 的效率高,一旦命中缓存,就可以节省一次 I/O时间。
对象被当作缓存来使用,意味着将会常驻在老生代中。缓存中存储的键越多,长期存活的对象也就越多,导致垃圾回收在进行扫描和整理时,对这些对象做无用功。
Js开发者喜欢用对象的键值对来缓存东西,但这与严格意义上的缓存又有着区别,严格意义的缓存有着完善的过期策略,而普通对象的键值对并没有。是一种以内存空间换CPU执行时间。示例代码如下:
var cache = {};
var get = function (key) {
if (cache[key]) {
return cache[key];
} else {
// get from otherwise
}
};
var set = function (key, value) {
cache[key] = value;
};所以在Node中,拿内存当缓存的行为应当被限制。当然,这种限制并不是不允许使用,而是要小心为之。
4.1.1 缓存限制策略
为了解决缓存中的对象永远无法释放的问题,需要加入一种策略来限制缓存的无限增长。可以实现对键值数量的限制。下面是其实现:
var LimitableMap = function (limit) {
this.limit = limit || 10;
this.map = {};
this.keys = [];
};
var hasOwnProperty = Object.prototype.hasOwnProperty;
LimitableMap.prototype.set = function (key, value) {
var map = this.map;
var keys = this.keys;
if (!hasOwnProperty.call(map, key)) {
if (keys.length === this.limit) {
var firstKey = keys.shift();
delete map[firstKey];
}
keys.push(key);
}
map[key] = value;
};
LimitableMap.prototype.get = function (key) {
return this.map[key];
};
module.exports = LimitableMap;记录键在数组中,一旦超过数量,就以先进先出的方式进行淘汰。
4.1.2 缓存的解决方案
直接将内存作为缓存的方案要十分慎重。除了限制缓存的大小外,另外要考虑的事情是,进程之间无法共享内存。如果在进程内使用缓存,这些缓存不可避免地有重复,对物理内存的使用是一种浪费。
如何使用大量缓存,目前比较好的解决方案是采用进程外的缓存,进程自身不存储状态。外部的缓存软件有着良好的缓存过期淘汰策略以及自有的内存管理,不影响Node进程的性能。它的好处多多,在Node中主要可以解决以下两个问题。
- 将缓存转移到外部,减少常驻内存的对象的数量,让垃圾回收更高效。
- 进程之间可以共享缓存。
目前,市面上较好的缓存有Redis和Memcached。
4.2 关注队列状态
队列在消费者-生产者模型中经常充当中间产物。这是一个容易忽略的情况,因为在大多数应用场景下,消费的速度远远大于生产的速度,内存泄漏不易产生。但是一旦消费速度低于生产速度,将会形成堆积, 导致Js中相关的作用域不会得到释放,内存占用不会回落,从而出现内存泄漏。
解决方案应该是监控队列的长度,一旦堆积,应当通过监控系统产生报警并通知相关人员。另一个解决方案是任意异步调用都应该包含超时机制,一旦在限定的时间内未完成响应,通过回调函数传递超时异常,使得任意异步调用的回调都具备可控的响应时间,给消费速度一个下限值。
5. 内存泄漏排查
常见的工具
- v8-profiler: 可以用于对V8堆内存抓取快照和对CPU进行分析
- node-heapdump: 允许对V8堆内存抓取快照,用于事后分析
- node-mtrace: 使用了GCC的mtrace工具来分析堆的使用
- dtrace:有完善的dtrace工具用来分析内存泄漏
- node-memwatch
6. 大内存应用
由于Node的内存限制,操作大文件也需要小心,好在Node提供了stream模块用于处理大文件。
stream模块是Node的原生模块,直接引用即可。stream继承自EventEmitter,具备基本的自定义事件功能,同时抽象出标准的事件和方法。它分可读和可写两种。Node中的大多数模块都有stream的应用,比如fs的createReadStream()和createWriteStream()方法可以分别用于创建文件的可读流和可写流,process模块中的stdin和stdout则分别是可读流和可写流的示例。
由于V8的内存限制,我们无法通过fs.readFile()和fs.writeFile()直接进行大文件的操作,而改用fs.createReadStream()和fs.createWriteStream()方法通过流的方式实现对大文件的操作。下面的代码展示了如何读取一个文件,然后将数据写入到另一个文件的过程:
var reader = fs.createReadStream('in.txt');
var writer = fs.createWriteStream('out.txt');
reader.on('data', function (chunk) {
writer.write(chunk);
});
reader.on('end', function () {
writer.end();
});
// 简洁的方式
var reader = fs.createReadStream('in.txt');
var writer = fs.createWriteStream('out.txt');
reader.pipe(writer);可读流提供了管道方法pipe(),封装了data事件和写入操作。通过流的方式,上述代码不会受到V8内存限制的影响,有效地提高了程序的健壮性。
如果不需要进行字符串层面的操作,则不需要借助V8来处理,可以尝试进行纯粹的Buffer操作,这不会受到V8堆内存的限制。但是这种大片使用内存的情况依然要小心,即使V8不限制堆内存的大小,物理内存依然有限制。
更多node相关知识,请访问:nodejs 教程!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
Articles Liés
Voir plus- Comment créer une boîte aux lettres dans nodejs
- miam Comment installer nodejs
- Comment définir le port nodejs
- Comment lire le fichier nodejs après le téléchargement
- Comment faire en sorte que Node.js prenne en charge ES6
- Quel est le meilleur, maîtriser le C ou apprendre nodejs ?
- Comment créer un serveur Web simple à l'aide de Node.js
- Comment résoudre l'erreur nodejs const