
Maison >développement back-end >Tutoriel Python >Comment construire un scanner de documents en Python ?
Comment construire un scanner de documents en Python ?

- 王林avant
- 2023-04-26 13:10:111867parcourir
Traducteur | Bugatti
Reviewer | Sun Shujuan
Vous souhaiterez peut-être numériser des documents pour économiser de l'espace physique ou créer des sauvegardes. Dans tous les cas, écrire un programme pour convertir des photos de documents papier dans un quasi-format est exactement ce pour quoi Python est bon.
En utilisant une combinaison de plusieurs bibliothèques appropriées, vous pouvez créer une petite application pour numériser des documents. Votre programme prendra l'image d'un document physique en entrée, lui appliquera plusieurs techniques de traitement d'image et produira une version numérisée de l'entrée.
1. Préparez l'environnement
Tout d'abord, vous devez connaître les bases de Python, et vous devez également savoir utiliser la bibliothèque NumPy Python.
Ouvrez n'importe quel IDE Python et créez deux fichiers Python. Nommez un main.py et l’autre transform.py. Exécutez ensuite la commande suivante sur le terminal pour installer les bibliothèques requises.
pip install OpenCV-Python imutils scikit-image NumPy
Vous utiliserez OpenCV-Python pour prendre une entrée d'image et effectuer un traitement d'image, utiliserez Imutils pour redimensionner les images d'entrée et de sortie, et utiliserez scikit-image pour seuiller les images. NumPy vous aidera avec les tableaux.
Attendez que l'installation soit terminée et que l'EDI mette à jour le backbone du projet. Une fois le contenu du backbone mis à jour, vous pouvez commencer la programmation. Le code source complet peut être trouvé dans le référentiel GitHub.
2. Importez la bibliothèque installée
Ouvrez le fichier main.py et importez la bibliothèque installée. Cela vous permettra d'appeler et d'utiliser leurs fonctions lorsque cela est nécessaire.
import cv2 import imutils from skimage.filters import threshold_local from transform import perspective_transform
Ignorez les erreurs générées par perspective_transform. Une fois que vous aurez fini de traiter le fichier transform.py, l'erreur disparaîtra.
3. Obtenez et redimensionnez l'entrée
Prenez une image claire du document que vous souhaitez numériser. Assurez-vous que les quatre coins du document et son contenu sont visibles. Copiez l'image dans le même dossier où les fichiers du programme sont stockés.

Transmettez le chemin de l'image d'entrée à OpenCV. Faites une copie de l'image originale car vous en aurez besoin lors de la transformation de la perspective. Divisez la hauteur de l'image originale par la hauteur à laquelle vous souhaitez la redimensionner. Cela maintiendra le rapport hauteur/largeur. Enfin, l'image ajustée est sortie.
# Passing the image path
original_img = cv2.imread('sample.jpg')
copy = original_img.copy()
# The resized height in hundreds
ratio = original_img.shape[0] / 500.0
img_resize = imutils.resize(original_img, height=500)
# Displaying output
cv2.imshow('Resized image', img_resize)
# Waiting for the user to press any key
cv2.waitKey(0)
Le résultat du code ci-dessus est le suivant :
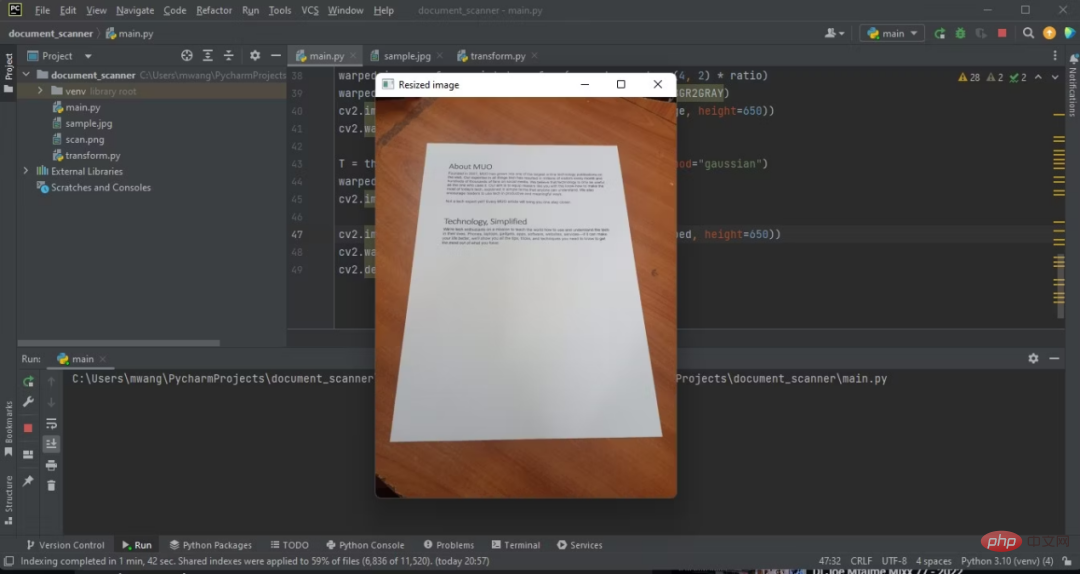
Vous avez maintenant ajusté la hauteur de l'image originale à 500 pixels.
4. Convertissez l'image ajustée en image en niveaux de gris
Convertissez l'image RVB ajustée en image en niveaux de gris. La plupart des bibliothèques de traitement d'images ne gèrent que les images en niveaux de gris car elles sont plus faciles à traiter.
gray_image = cv2.cvtColor(img_resize, cv2.COLOR_BGR2GRAY)
cv2.imshow('Grayed Image', gray_image)
cv2.waitKey(0)
Remarquez la différence entre l'image originale et l'image en niveaux de gris.
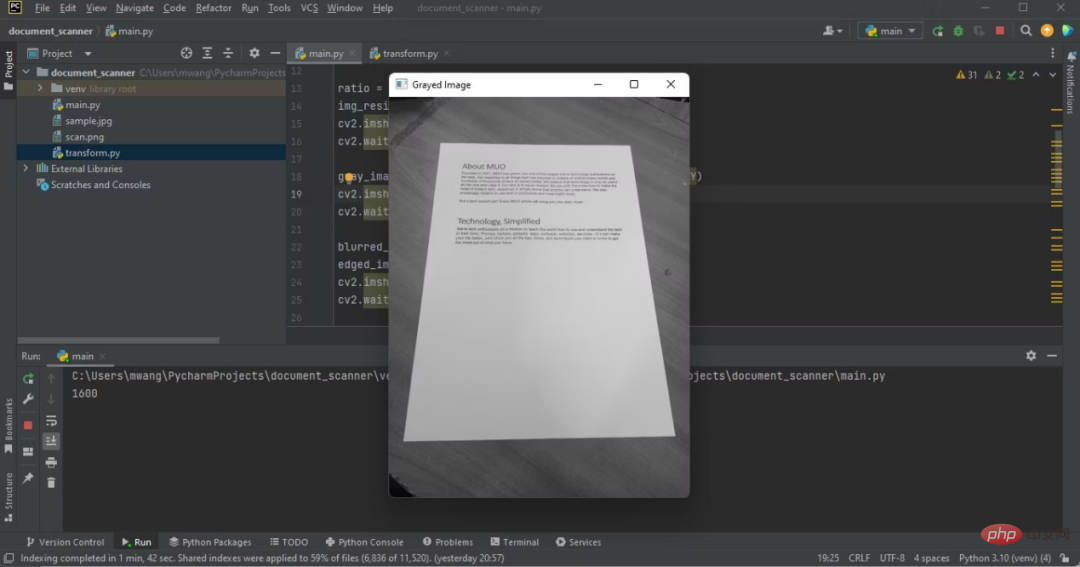
Sortie du programme affichant une image grise sur l'IDE
Table des couleurs transformée en table noir et blanc.
5. Utilisez le détecteur de bord
Appliquez un filtre de flou gaussien à l'image en niveaux de gris pour supprimer le bruit. La fonction astucieuse d'OpenCV est ensuite appelée pour détecter les bords présents dans l'image.
blurred_image = cv2.GaussianBlur(gray_image, (5, 5), 0)
edged_img = cv2.Canny(blurred_image, 75, 200)
cv2.imshow('Image edges', edged_img)
cv2.waitKey(0)
Les bords sont visibles sur la sortie.
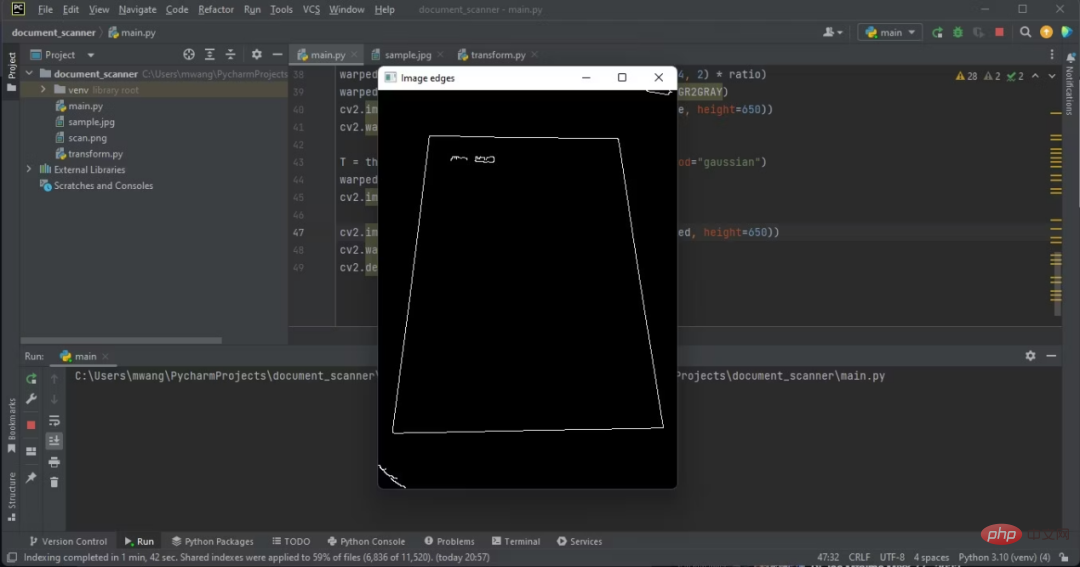
Les bords sur lesquels vous allez travailler sont les bords du document.
6. Trouvez le plus grand contour
Détectez les contours dans les images de bord. Triez par ordre décroissant en ne gardant que les cinq plus grands contours. En triant cycliquement les contours, on obtient approximativement le plus grand contour à quatre côtés.
cnts, _ = cv2.findContours(edged_img, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE) cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:5] for c in cnts: peri = cv2.arcLength(c, True) approx = cv2.approxPolyDP(c, 0.02 * peri, True) if len(approx) == 4: doc = approx break
Une silhouette à quatre côtés est susceptible de contenir un document.
7. Encerclez les quatre coins du contour du document
Encerclez plusieurs coins du contour du document détecté. Cela vous aidera à déterminer si votre programme est capable de détecter le document dans l'image.
p = []
for d in doc:
tuple_point = tuple(d[0])
cv2.circle(img_resize, tuple_point, 3, (0, 0, 255), 4)
p.append(tuple_point)
cv2.imshow('Circled corner points', img_resize)
cv2.waitKey(0)
Encerclez quelques coins de l'image RVB ajustée.
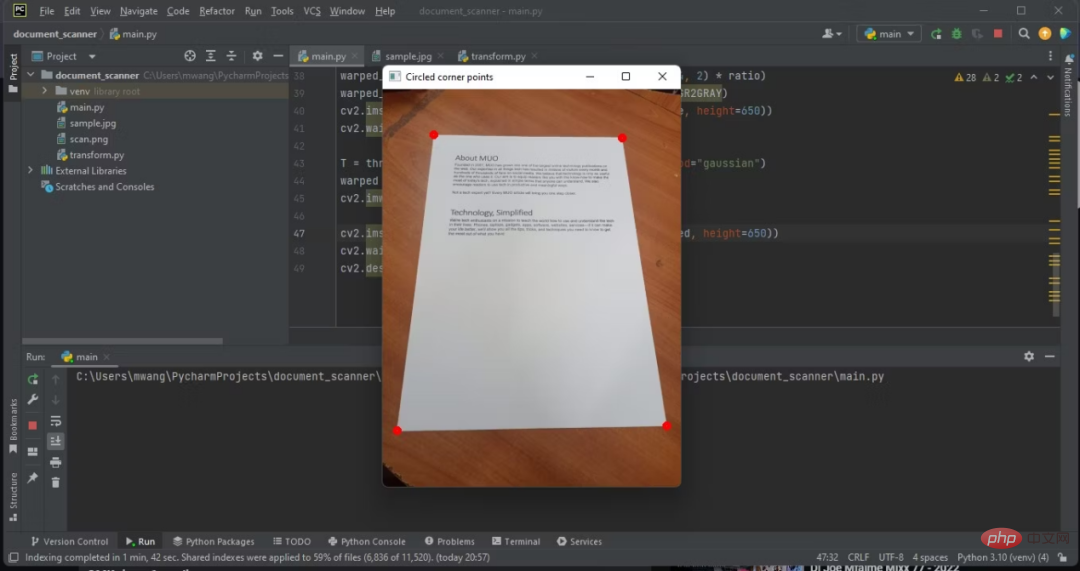
Après avoir détecté le document, vous devez maintenant extraire le document de l'image.
8. Utilisez la perspective déformée pour obtenir l'image souhaitée
La perspective déformée est une technique de vision par ordinateur utilisée pour transformer les images afin de corriger la distorsion. Il transforme l'image en différents plans, vous permettant de visualiser l'image sous différents angles.
warped_image = perspective_transform(copy, doc.reshape(4, 2) * ratio)
warped_image = cv2.cvtColor(warped_image, cv2.COLOR_BGR2GRAY)
cv2.imshow("Warped Image", imutils.resize(warped_image, height=650))
cv2.waitKey(0)
Pour obtenir l'image déformée, vous devez créer un module simple pour effectuer la transformation de perspective.
9.Module de conversion
该模块将对文档角的点进行排序。它还会将文档图像转换成不同的平面,并将相机角度更改为俯拍。
打开之前创建的那个transform.py文件,导入OpenCV库和NumPy库。
import numpy as np import cv2
这个模块将含有两个函数。创建一个对文档角点的坐标进行排序的函数。第一个坐标将是左上角的坐标,第二个将是右上角的坐标,第三个将是右下角的坐标,第四个将是左下角的坐标。
def order_points(pts): # initializing the list of coordinates to be ordered rect = np.zeros((4, 2), dtype = "float32") s = pts.sum(axis = 1) # top-left point will have the smallest sum rect[0] = pts[np.argmin(s)] # bottom-right point will have the largest sum rect[2] = pts[np.argmax(s)] '''computing the difference between the points, the top-right point will have the smallest difference, whereas the bottom-left will have the largest difference''' diff = np.diff(pts, axis = 1) rect[1] = pts[np.argmin(diff)] rect[3] = pts[np.argmax(diff)] # returns ordered coordinates return rect
创建将计算新图像的角坐标,并获得俯拍的第二个函数。然后,它将计算透视变换矩阵,并返回扭曲的图像。
def perspective_transform(image, pts): # unpack the ordered coordinates individually rect = order_points(pts) (tl, tr, br, bl) = rect '''compute the width of the new image, which will be the maximum distance between bottom-right and bottom-left x-coordinates or the top-right and top-left x-coordinates''' widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2)) widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2)) maxWidth = max(int(widthA), int(widthB)) '''compute the height of the new image, which will be the maximum distance between the top-left and bottom-left y-coordinates''' heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2)) heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2)) maxHeight = max(int(heightA), int(heightB)) '''construct the set of destination points to obtain an overhead shot''' dst = np.array([ [0, 0], [maxWidth - 1, 0], [maxWidth - 1, maxHeight - 1], [0, maxHeight - 1]], dtype = "float32") # compute the perspective transform matrix transform_matrix = cv2.getPerspectiveTransform(rect, dst) # Apply the transform matrix warped = cv2.warpPerspective(image, transform_matrix, (maxWidth, maxHeight)) # return the warped image return warped
现在您已创建了转换模块。perspective_transform导入方面的错误现在将消失。
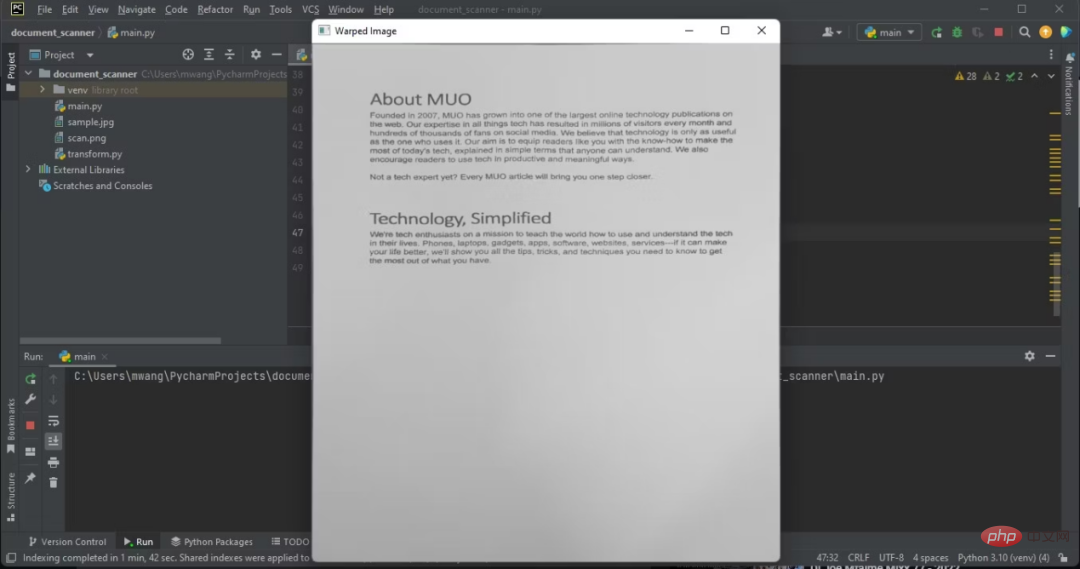
注意,显示的图像有俯拍。
10、运用自适应阈值,保存扫描输出
在main.py文件中,对扭曲的图像运用高斯阈值。这将给扭曲的图像一个扫描后的外观。将扫描后的图像输出保存到含有程序文件的文件夹中。
T = threshold_local(warped_image, 11, offset=10, method="gaussian")
warped = (warped_image > T).astype("uint8") * 255
cv2.imwrite('./'+'scan'+'.png',warped)
以PNG格式保存扫描件可以保持文档质量。
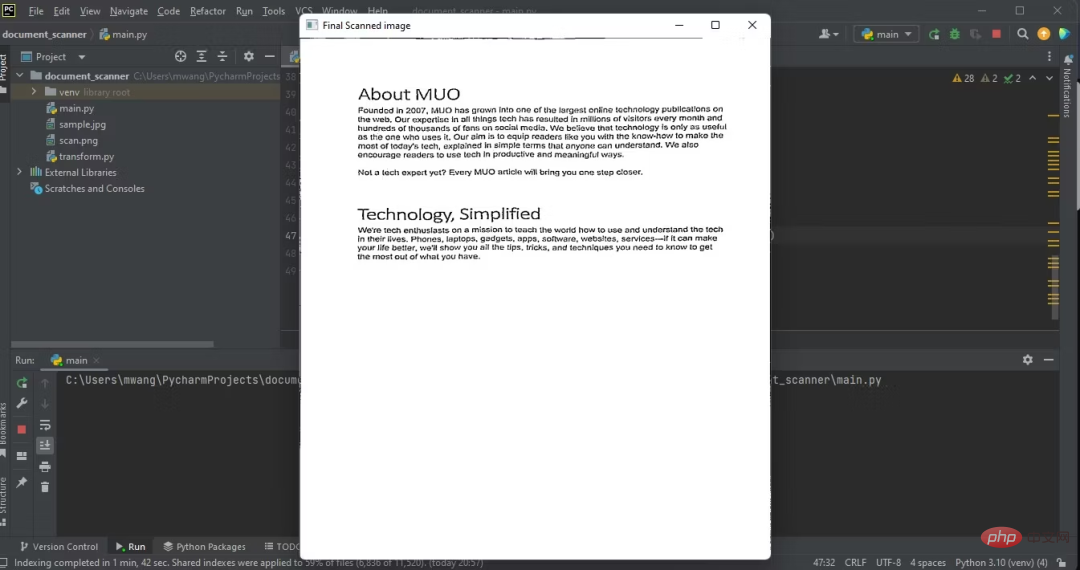
11、显示输出
输出扫描后文档的图像:
cv2.imshow("Final Scanned image", imutils.resize(warped, height=650))
cv2.waitKey(0)
cv2.destroyAllWindows()
下图显示了程序的输出,即扫描后文档的俯拍。
12、计算机视觉在如何进步?
创建文档扫描器涉及计算机视觉的一些核心领域,计算机视觉是一个广泛而复杂的领域。为了在计算机视觉方面取得进步,您应该从事有趣味又有挑战性的项目。
您还应该阅读如何将计算机视觉与当前前技术结合使用方面的更多信息。这让您能了解情况,并为所处理的项目提供新的想法。
原文链接:https://www.makeuseof.com/python-create-document-scanner/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!